Photon は、Databricks レイクハウスプラットフォームの次世代エンジンです。データレイク上で直接実行することが可能で、データの取り込み、ETL、ストリーミング、データサイエンス、インタラクティブクエリなど、極めて高速なクエリ性能を低コストで提供します。Photon は Apache Spark™ の API と互換性があ�り、コードの変更やベンダーロックインなしで、電源をオンにするだけですぐに使い始めることができます。
Cheaper and faster
Built from the ground up for the fastest performance at lower cost, Photon provides up to 80% TCO savings while accelerating data and analytics workloads — up to 12x speedups.
Built for all use cases
Photon is the first engine that enables data teams to standardize on one set of APIs for all workloads — ETL, analytics and data science — in batch or streaming.
No code changes
Photon is an ANSI-compliant engine designed to be compatible with modern Apache Spark APIs and just works with your existing code — SQL, Python, R, Scala and Java — no rewrite required.
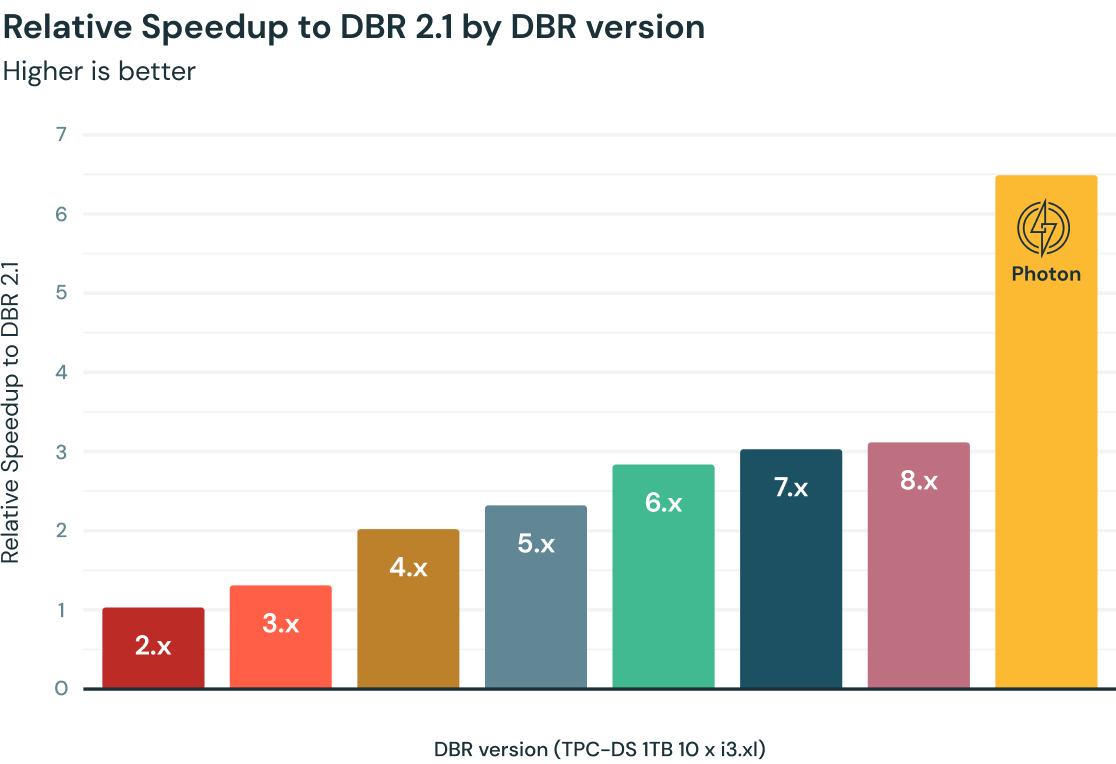
Photon を選ぶ理由
Databricks のクエリ性能は、Apache Spark と Databricks Runtimes(DBR)の一部としてパッケージ化された数千もの最適化機能によって、長年にわたって着実に向上してきました。C++ で記述された新しいネイティブベクトル化エンジンである Photon は、TPC-DS 1TB ベンチマークでさらに 2 倍の高速化を実現し、DBR の最新バージョンと比較して、ワークロードに応じて平均 3 倍から 8 倍の高速化が確認されています。
ユースケース

Production jobs
Accelerate large-scale production jobs on SQL and Spark DataFrames

IoT applications
Faster time-series analysis using Photon compared to Spark and traditional Databricks Runtime

Data privacy and compliance
Query petabyte-scale data sets to identify and delete records without duplicating data with Delta Lake, production jobs and Photon

Loading data into Delta Lake and Parquet
Photon’s vectorized I/O speeds up data loads for Delta Lake and Parquet tables, lowering overall runtime and the cost of data engineering jobs
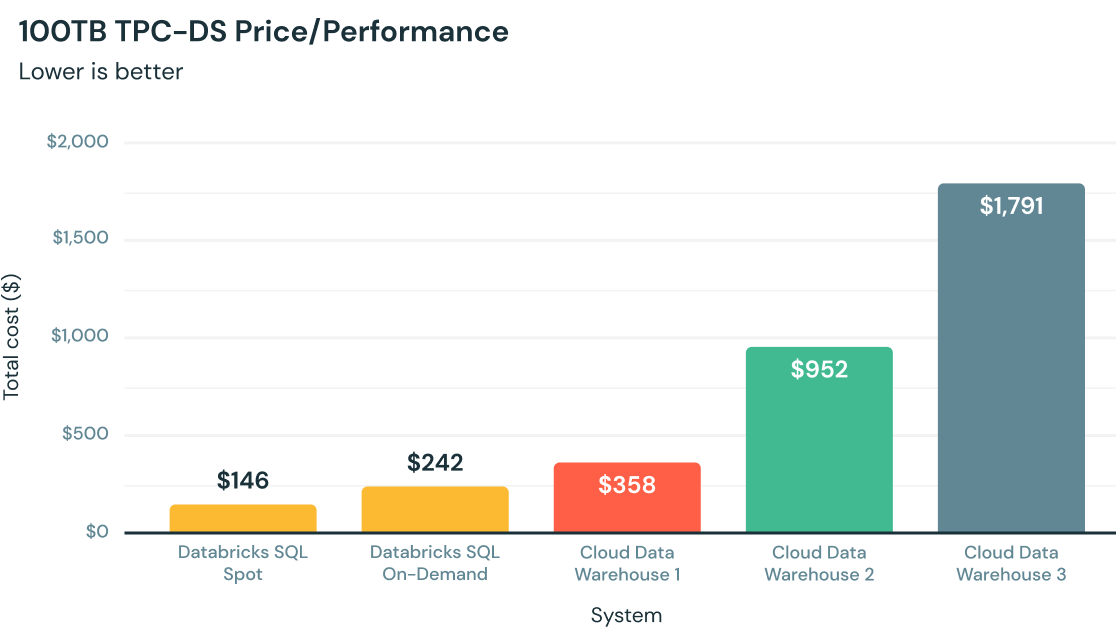
仕組み
クラウドでの分析の価格性能を最大化
C++で一から記述された Photon は、全てデータレイク上でネイティブに動作し、最新のハードウェアを利用してクエリを高速化し、他のクラウドデータウェアハウスと比較して最大 12 倍の価格性能を提供します。
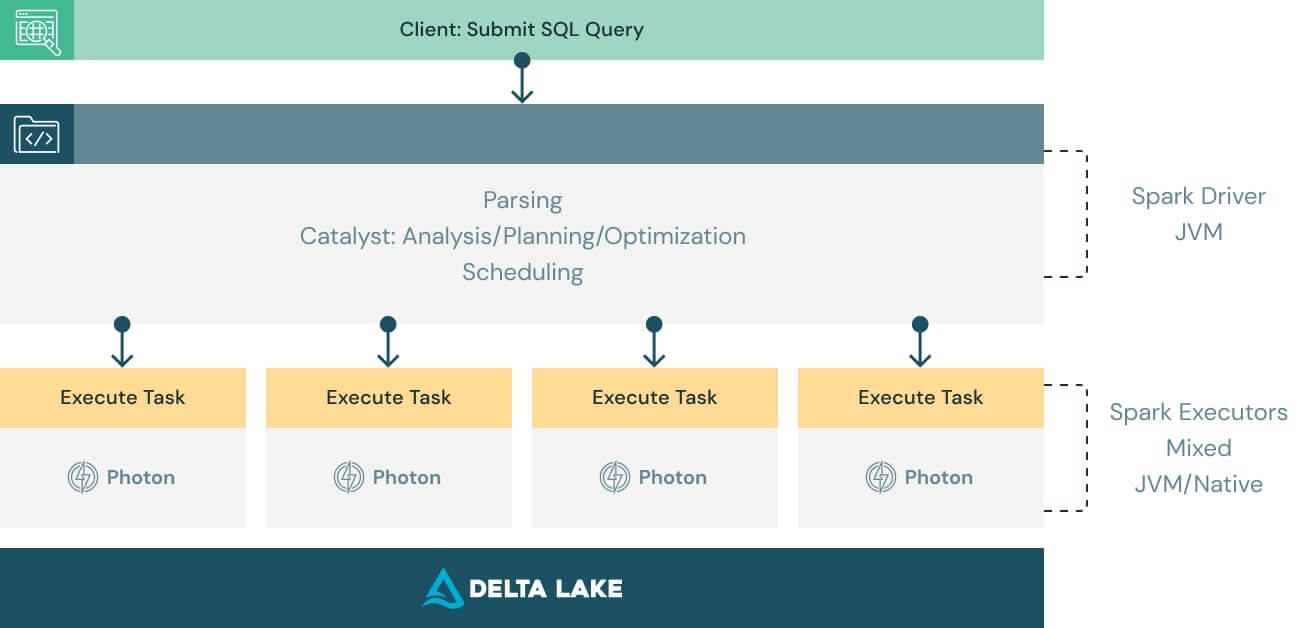
既存のコードで動作してベンダーのロックインを回避
Photon は、Apache Spark DataFrame および SQL API と互換性があるように設計されており、コード変更なしでワークロードをシームレスに実行できます。Photon によるメリットを享受するには、電源をオンにするだけです。Photon は、作業とリソースをシームレスに調整し、SQL と Spark クエリの一部を透過的に高速化します。チューニングやユーザーの介入は必要ありません。

あらゆるデータのユースケースとワークロードに最適化
Photon は、お客さまのデータレイクでワールドクラスのデータウェアハウスのパフォーマンスを提供するために SQL を重点に置いてにスタートしましたが、その後、Photon がサポートする取り込みソース、フォーマット、API、メソッドの範囲を大幅に拡大してきました。その結果、Spark SQL や DataFrame といった最新の Spark ワークロードの全てにおいて、お客さまは Photon でインフラコストの大幅な削減と高速化を実現しています。
関連リソース
関連リソース
リサーチペーパー
イベント
ブログ
無料お試し・その他ご相談を承ります