セキュリティ& トラスト・センター
データ保護は Databricks の最優先事項です

Databricks の責任ある AI へのアプローチ
Databricks は、AI の進歩は、AI の開発と使用における責任あるプラクティスに従うことによって、インテリジェントなアプリケーションに対する信頼を構築することに依存していると考えています。そのためには、AI の開発と展開を通じて包括的なモニタリング、プライバシー管理、ガバナンスを行い、全ての組��織がデータと AI モデルに対するオーナーシップとコントロールを持つ必要があります。
Databricks の責任ある AI テストフレームワーク — 生成 AI モデルのレッドチーミング
AI のレッドチーミング、特に大規模言語モデルのレッドチーミングは、モデルを安全に開発・デプロイするための重要な要素です。Databricks では、社内で開発したモデルやシステムに対して定期的に AI のレッドチーミングを行っています。Databricks の責任ある AI テストフレームワークの概要は以下の図のとおりです。Databricks のモデルをテストするために Databricks 社内の敵対的 ML ラボで使用している技術に加え、ラボで将来使用するために評価中のレッドチーミング技術も含まれています。
注:AI のレッドチーミングは、まだ初期段階にある分野です。技術革新の急速なペースが、機会と課題の両方をもたらしていると認識することが極めて重要です。Databricks は、攻撃や対抗手段のための新しいアプローチを継続的に評価し、適切な場合にはそれらをモデルのテストプロセスに取り入れることを約束します。
以下は、Databricks の生成 AI テストフレームワークを図式化したものです。
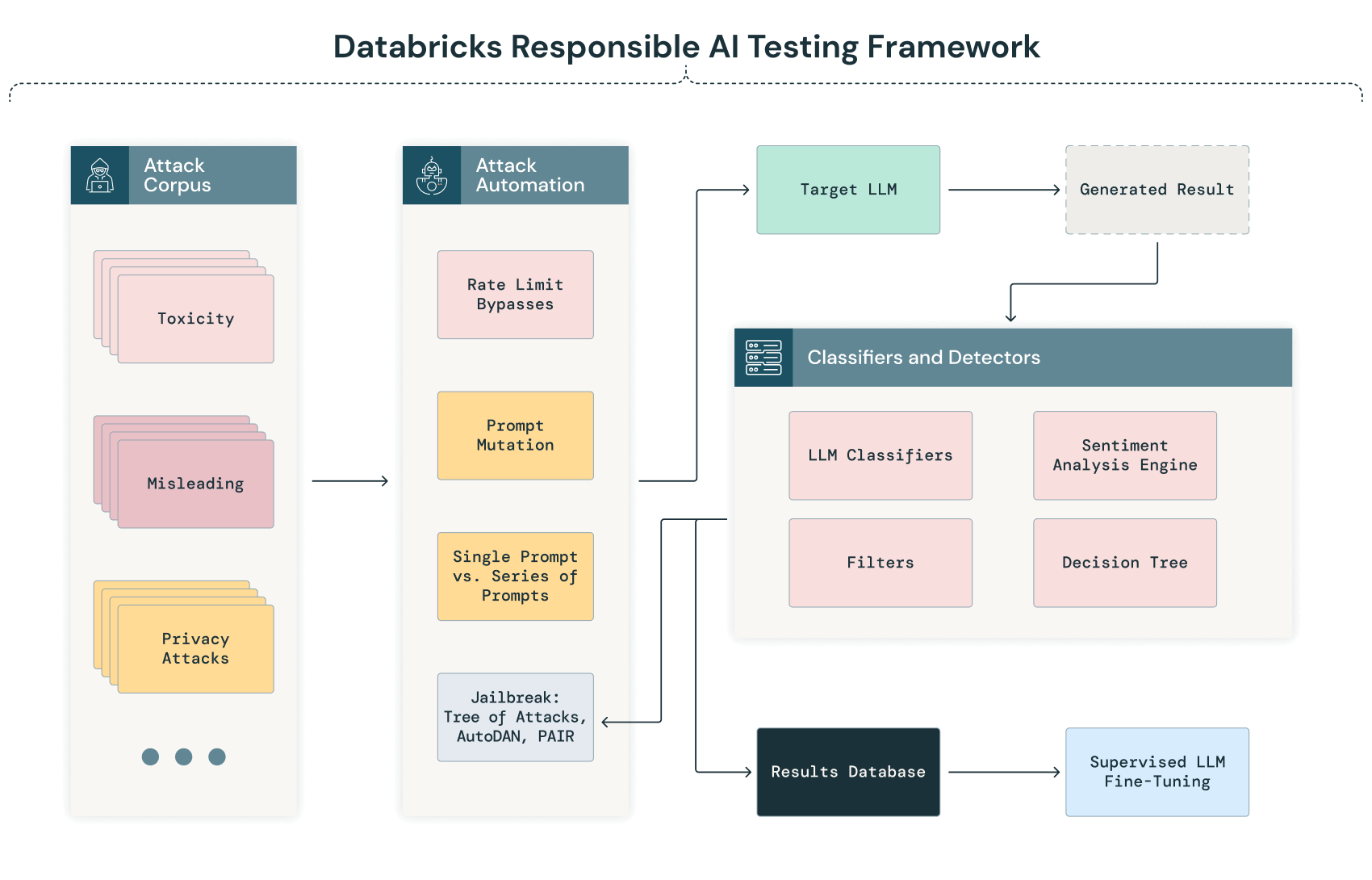
自動化された調査と分類
AI のレッドチーミングプロセスにおける初期フェーズでは、一連の多様なテキストコーパスを系統的にモデルに送る自動化されたプロセスが行われます。このプロセスは、より詳細な手作業による分析が行われる前に、潜在的な脆弱性、バイアス(偏り)、またはプライバシーに関する懸念を自動的に特定し、幅広いシナリオにわたってモデルの応答を調査することを目的としています。
LLM がこれらの入力を処理すると、その出力は自動的にキャプチャされ、事前に定義された基準を使用して分類されます。この分類には、自然言語処理(NLP)技術や、異常、バイアス、期待される性能からの逸脱を検出するためにトレーニングされた他の AI モデルが関与する可能性があります。例えば、出力に潜在的なバイアスや無意味な回答、データ漏洩の兆候があった場合、手動レビューの対象としてフラグが立てられることがあります。
LLM の脱獄(ジェイルブレイク)
Databricks では LLM の脱獄に、次のような複数のテクニックを採用しています。
- 直接指示(DI):攻撃者が有害なコンテンツを要求する直接的なプロンプト
- DAN(Do-Anything-Now)プロンプト:さまざまな攻撃により、モデルが倫理やセキュリティの制限に関係なく、どのようなタスクでも実行できる「今すぐ何でも行う(Do Anything Now)」チャットエージェントになるように促します。
- Riley Goodside スタイルの攻撃: モデルに直接プロンプトを無視するように要求する一連の攻撃。Riley Goodside 氏によって広められました。
- Agency Enterprise PromptInject コーパス:NeurIPS ML Safety Workshop 2022 の最優秀論文賞で紹介された Agency Enterprise Prompt Injection コーパスの再現
- PAIR(Prompt Automatic Iterative Refinement — プロンプト自動反復洗練):攻撃に特化した大規模言語モデルを使用して、脱獄に向けてプロンプトを反復的に洗練させる手法
- TAP(Tree of Attacks With Pruning — 剪定を伴う攻撃の木):PAIR 攻撃と似ていますが、生成されたプロンプトがいつトピックから外れたかを識別し、攻撃ツリーから剪定するために追加の LLM を使用します。
脱獄テストは、トレーニングデータと大きく異なるプロンプトや、保護された情報に別の方法でアクセスするプロンプトに対して、モデルが汎化して応答する能力をさらに理解します。これにより、攻撃が LLM を騙して有害なコンテンツや不要なコンテンツを出力させる方法を特定することも可能です。
この分野は、常に進化しています。脱獄に関する状況の変化にあわせて、追加のテクニックを検討し、評価し続けます。
手作業による検証と分析
自動化フェーズに続く AI のレッドチーミングプロセスでは、フラグが立てられた出力を手動でレビューします。また、全ての重要な問題が特定される可能性を高めるために、フラグが立っていない出力をランダムにレビューし��ます。この手作業による分析により、自動化プロセスで特定された問題の微妙な解釈と検証が可能になります。
AI のレッドチーミングプロセスには、かなりの量の手作業が含まれます。自動スキャンでは懸念事項を示さない結果が生成されるかもしれません。しかし、レッドチームの手作業による評価では、これらのプロンプトを微調整したり連鎖させたりするさまざまな方法を試み、自動スキャンでは特定されなかった弱点を見つけることがあります。
モデルのサプライチェーンにおけるセキュリティ
AI のレッドチーミングの取り組みが進化するにつれて、トレーニングから展開、配布に至るまで、AI モデルのサプライチェーンにおける安全性を評価するためのプロセスも取り入れています。現在の評価領域は、次のとおりです。
- トレーニングデータの改ざん(ラベルの改ざんや悪意のあるデータの注入によるポイズニング)
- GPU、VM といったトレーニングインフラの侵害
- 展開された LLM へのアクセスを取得し、重みやハイパーパラメータを改ざん
- フィルターやその他の展開された防御レイヤーを改ざん
- モデルの配布の妨害 — Hugging Face のような信頼できるサードパーティを介した改ざん
継続的なフィードバックループ
AI のレッドチーミングの取り組みでは、継続的な改善ループのプロセスも追加される予定です。自動スキャンと手作業分析の両方から得られた知見を収集します。継続的な�改善ループの目標は、モデルをさらに進化させ、より強固で最高の性能基準に沿ったものにすることです。
Databricks のレッドチームが利用するテストプローブのカテゴリ
Databricks は、テスト中にモデルに送信される一連の選別されたコーパス(プローブ)を利用します。プローブとは、AI システムにさまざまな方法で挑戦するためにデザインされた特定のテストや実験のことです。違反ではない正常な結果を生成したプローブに対して、レッドチームは同じプローブの他のバリエーションを試すことにより、モデルの応答における不正行為をテストします。LLM の文脈において、Databricks のレッドチームが利用するプローブは、次のように分類できます。
セキュリティのプローブ
- 入力操作:データ処理の脆弱性を特定するために、変更された入力、ノイズの多い入力、または悪意のある入力に対するモデルの応答をテストします。
- 回避技術:モデルのセーフガードやフィルターを迂回して、有害な出力や意図していない出力を誘発します。
- モデルの反転:モデルから機密情報を抽出しようとする試みで、データのプライバシーを侵害します。
倫理とバイアスのプローブ
- バイアスの検出:特定のプロンプトへの応答を分析することにより、人種、性別、年齢などに関連するバイアスがないかモデルを評価します。
- 倫理的ジレンマ:倫理規範や価値観との整合性をテストするシナリオをモデルに提示します。
堅牢性と信頼性のプローブ
- 敵対的攻撃:わずかに変更された入力を導入し、モデルを欺いて誤った出力を生じさせることを意図しています。
- 一貫性のチェック:類似のクエリや繰り返されるクエリに対して、モデルが一貫性のある信頼性の高い応答を提供できるかどうかをテストします。
コンプライアンスと安全性のプローブ
- 規制の遵守:適用される規制に対するモデルの出力とプロセスをテストします。
- 安全シナリオ:危害や危険なアドバイスを回避するため、安全性が重要な懸念事項であるシナリオにおけるモデルの動作を評価します。
- プライバシーのプローブ:GDPR(一般データ保護規則)、HIPAA(医療保険の携行性と責任に関する法律)などのデータプライバシー基準や規制に基づいてモデルを検証します。これらのプローブは、モデルが出力において個人情報や機密情報を不適切に公開していないか、またはデータを抽出するために操作される可能性があるかどうかを評価します。
- 制御性:人間のオペレーターがモデルの出力や動作に介入、または��制御する容易さをテストします。


