Datenverzerrungen mit SHAP und Machine Learning erkennen
Was Machine Learning und SHAP uns über die Beziehung zwischen Entwicklergehältern und dem Gender Pay Gap sagen können

Probieren Sie das Notebook „Detecting Data Bias Using SHAP“ aus, um die unten beschriebenen Schritte zu reproduzieren, und sehen Sie sich unser On-Demand-Webinar an, um mehr zu erfahren.
Die jährliche Entwicklerumfrage von StackOverflow wurde Anfang des Jahres abgeschlossen und die (anonymisierten) Ergebnisse von 2019 wurden freundlicherweise zur Analyse veröffentlicht. Sie bieten einen umfassenden Einblick in die Erfahrungen von Softwareentwicklern auf der ganzen Welt – was ist ihr Lieblingseditor? Wie viele Jahre Erfahrung? Tabs oder Leerzeichen? und ganz entscheidend: das Gehalt. Die Gehälter von Softwareentwicklern sind gut und manchmal sowohl schwindelerregend als auch berichtenswert.
Auch die Tech-Branche ist sich schmerzlich bewusst, dass sie ihren vermeintlichen meritokratischen Idealen nicht immer gerecht wird. Die Bezahlung ist keine reine Funktion der Leistung, und unzählige Geschichten erzählen uns, dass Faktoren wie eine renommierte Schule, Alter, ethnische Zugehörigkeit und Geschlecht einen Einfluss auf Ergebnisse wie das Gehalt haben.
Kann machine learning mehr als nur Dinge vorhersagen? Kann es Gehälter erklären und so Fälle hervorheben, in denen diese Faktoren möglicherweise unerwünschte Gehaltsunterschiede verursachen? Dieses Beispiel skizziert, wie Standardmodelle mit SHAP (SHapley Additive exPlanations) erweitert werden können, um einzelne Instanzen zu erkennen, deren Vorhersagen bedenklich sein könnten, und um dann die spezifischen Gründe, warum die Daten zu diesen Vorhersagen führen, genauer zu untersuchen.
Modell-Bias oder Daten-Bias?
Obwohl dieses Thema oft als Erkennung von „Modell-Bias“ bezeichnet wird, ist ein Modell lediglich ein Spiegelbild der Daten, mit denen es trainiert wurde. Wenn das Modell „verzerrt“ ist, dann hat es das aus den historischen Fakten der Daten gelernt. Modelle sind nicht per se das Problem, sondern eine Gelegenheit, Daten auf Anzeichen von Bias zu analysieren.
Modelle zu erklären ist nicht neu, und die meisten Bibliotheken können die relative Wichtigkeit der Eingaben für ein Modell bewerten. Dies sind aggregierte Ansichten der Auswirkungen von Eingaben. Die Ergebnisse einiger Machine-Learning-Modelle haben jedoch sehr individuelle Auswirkungen: Wird Ihr Kredit genehmigt? Werden Sie eine Finanzhilfe erhalten? Sind Sie ein verdächtiger Reisender?
Tatsächlich bietet StackOverflow einen praktischen Rechner, um das erwartete Gehalt basierend auf seiner Umfrage zu schätzen. Wir können nur darüber spekulieren, wie genau die Vorhersagen insgesamt sind, aber alles, was einen Entwickler besonders interessiert, sind seine oder ihre eigenen Aussichten.
Die richtige Frage lautet vielleicht nicht: Deuten die Daten insgesamt auf einen Bias hin? sondern vielmehr: Zeigen die Daten einzelne Fälle von Bias?
Auswertung der StackOverflow-Umfragedaten
Die Daten von 2019 sind glücklicherweise sauber und frei von Datenproblemen. Er enthält Antworten auf 85 Fragen von etwa 88.000 Entwicklern.
Dieses Beispiel konzentriert sich nur auf Vollzeit-Entwickler. Der Datensatz enthält viele relevante Informationen wie Berufserfahrung, Ausbildung, Rolle und demografische Informationen. Insbesondere enthält dieser Datensatz keine Informationen über Boni und Aktienbeteiligungen, sondern nur das Gehalt.
Es enthält auch Antworten auf weitreichende Fragen zu Einstellungen zu Blockchain, FizzBuzz und zur Umfrage selbst. Diese werden hier ausgeschlossen, da sie vermutlich nicht die Erfahrung und die Fähigkeiten widerspiegeln, die die Vergütung bestimmen sollten. Der Einfachheit halber konzentriert er sich ebenfalls nur auf in den USA ansässige Entwickler.
Die Daten benötigen vor der Modellierung noch etwas mehr Transformation. Mehrere Fragen lassen Mehrfachantworten zu, wie zum Beispiel „Was sind Ihre größten Herausforderungen für die Produktivität als Entwickler?“ Diese Einzelfragen ergeben mehrere Ja/Nein-Antworten und müssen in mehrere Ja/Nein-Features aufgeteilt werden.
Einige Multiple-Choice-Fragen wie "Ungefähr wie viele Personen sind bei dem Unternehmen oder der Organisation beschäftigt, für die Sie arbeiten?" ermöglichen Antworten wie "2-9 Mitarbeiter". Dies sind praktisch gruppierte kontinuierliche Werte, und es kann nützlich sein, sie wieder auf abgeleitete kontinuierliche Werte wie "2" abzubilden, damit das Modell ihre Reihenfolge und relative Größe berücksichtigen kann. Diese Umwandlung ist leider manuell und erfordert einige Ermessensentscheidungen.
Der Apache Spark -Code, mit dem dies erreicht werden kann, befindet sich für Interessierte im begleitenden Notebook.
Modellauswahl mit Apache Spark
Nachdem die Daten in eine für Machine Learning besser geeignete Form gebracht wurden, besteht der nächste Schritt darin, ein Regressionsmodell anzupassen, das das Gehalt anhand dieser Features vorhersagt. Der Datensatz selbst ist nach dem Filtern und der Transformation mit Spark nur 4 MB groß, enthält 206 Features von etwa 12.600 Entwicklern und würde problemlos als DataFrame auf Ihre Armbanduhr passen, geschweige denn auf einen Server.
xgboost, ein beliebtes Paket für Gradient-Boosted Trees, kann ein Modell in wenigen Minuten auf einem einzelnen Computer ohne Spark an diese Daten anpassen. xgboost bietet viele abstimmbare „Hyperparameter“, die die Qualität des Modells beeinflussen: maximale Tiefe, Lernrate, Regularisierung usw. Anstatt zu raten, ist es gängige Praxis, viele Einstellungen dieser Werte auszuprobieren und die Kombination zu wählen, die zum genauesten Modell führt.
Glücklicherweise kommt hier Spark wieder ins Spiel. Es kann Hunderte dieser Modelle parallel erstellen und die Ergebnisse von jedem sammeln. Da der Datensatz klein ist, ist es einfach, ihn an die Worker zu übertragen, eine Reihe von Hyperparameter-Kombinationen zum Testen zu erstellen und mit Spark für jede Kombination denselben einfachen, nicht verteilten xgboost -Code auf die Daten anzuwenden, der auch lokal ein Modell erstellen könnte.
Dadurch werden viele Modelle erstellt. Um die Ergebnisse zu verfolgen und auszuwerten, kann mlflow jedes Ergebnis mit seinen Metriken und Hyperparametern loggen und sie im Experiment des Notebooks anzeigen. Hier wird ein Hyperparameter über viele Ausführungen mit der resultierenden Genauigkeit (mittlerer absoluter Fehler) verglichen:
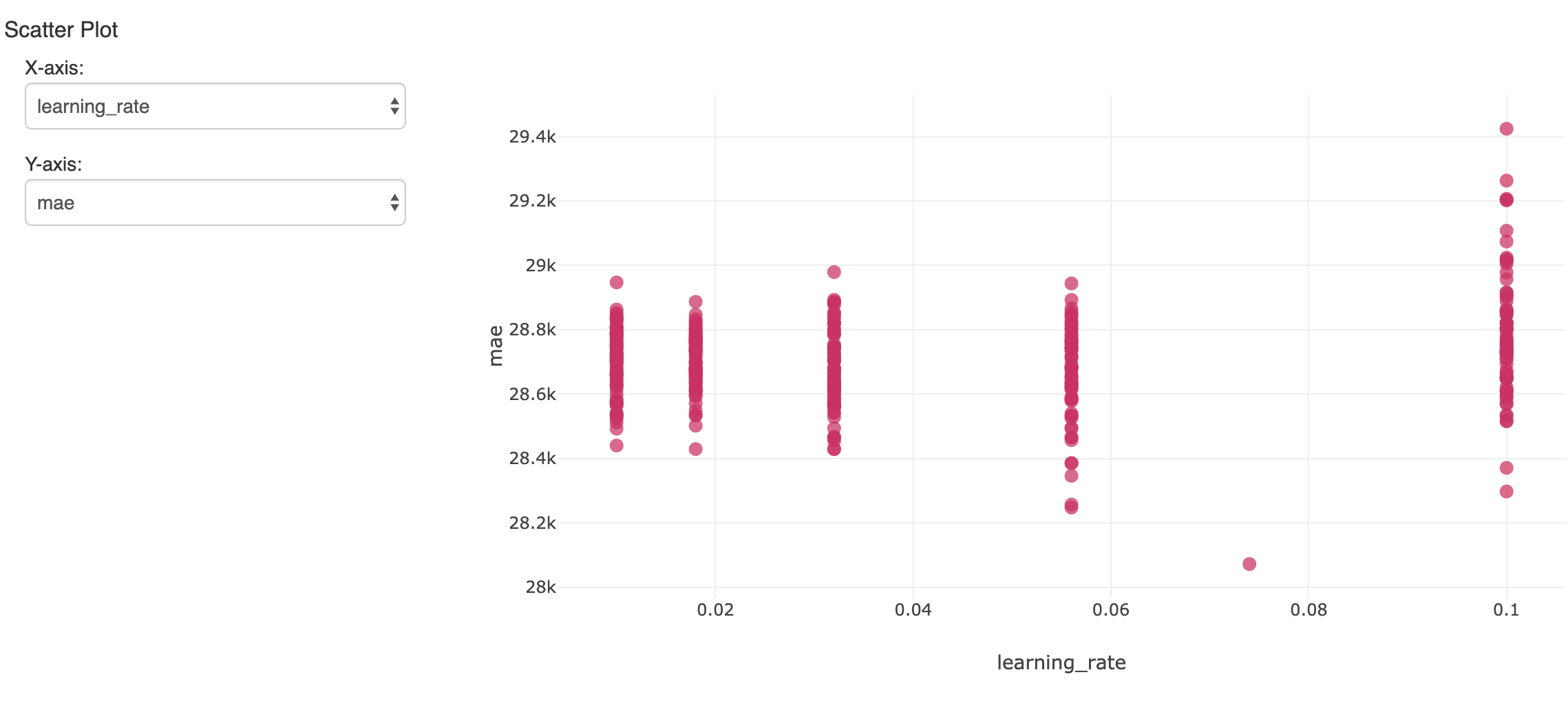
Das einzelne Modell, das auf dem zurückgehaltenen Validierungsdatensatz den geringsten Fehler aufwies, ist von Interesse. Es ergab einen mittleren absoluten Fehler von etwa 28.000 $ bei Gehältern von durchschnittlich etwa 119.000 $. Nicht schlecht, obwohl wir uns bewusst sein sollten, dass das Modell nur den größten Teil der Gehaltsunterschiede erklären kann.
Interpretation des xgboost-Modells
Obwohl das Modell zur Vorhersage zukünftiger Gehälter verwendet werden kann, geht es stattdessen um die Frage, was das Modell über die Daten aussagt. Welche Features scheinen bei der genauen Vorhersage des Gehalts am wichtigsten zu sein? Das xgboost -Modell selbst berechnet die Feature-Wichtigkeit:
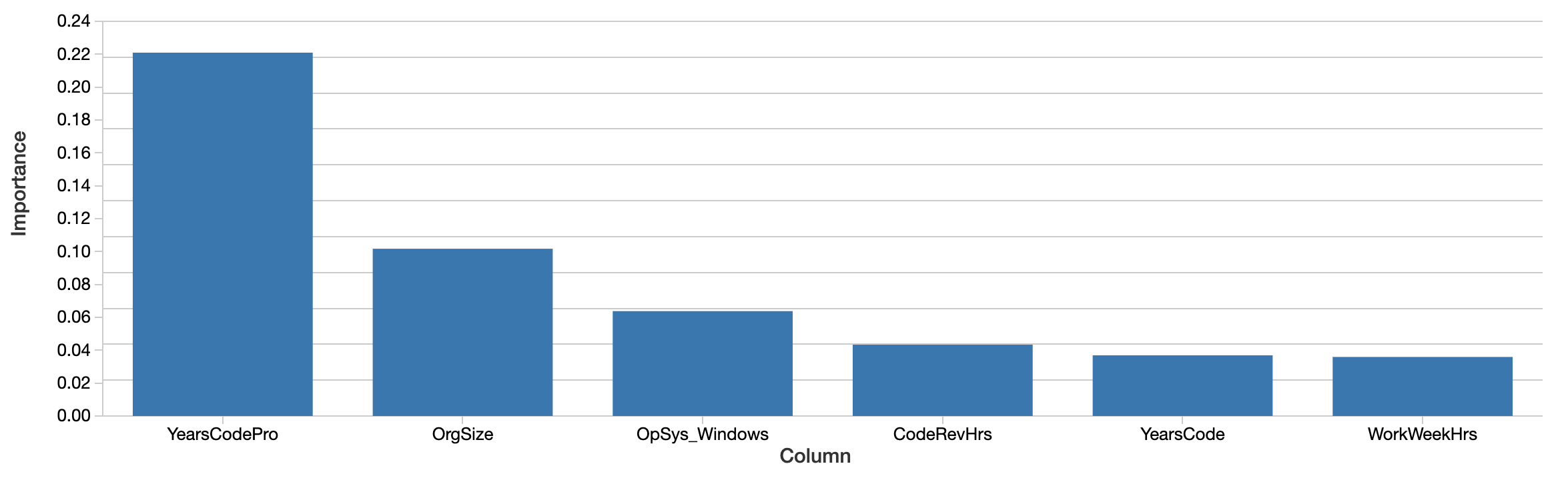
Faktoren wie jahrelange professionelle Programmiererfahrung, die Unternehmensgröße und die Verwendung von Windows sind am "wichtigsten". Das ist interessant, aber schwer zu interpretieren. Die Werte spiegeln die relative und nicht die absolute Wichtigkeit wider. Das heißt, der Effekt wird nicht in Dollar gemessen. Die hiesige Definition von Wichtigkeit (Gesamtgewinn) ist auch spezifisch für den Aufbau von Entscheidungsbäumen und ist schwer auf eine intuitive Interpretation übertragbar. Die wichtigen Features korrelieren auch nicht zwangsläufig positiv mit dem Gehalt.
Wichtiger noch, dies ist eine 'globale' Ansicht darüber, wie wichtig die Features insgesamt sind. Faktoren wie Geschlecht und ethnische Zugehörigkeit tauchen auf dieser Liste erst weiter unten auf. Das bedeutet nicht, dass diese Faktoren nicht weiterhin signifikant sind. Zum einen können Features korreliert sein oder interagieren. Es ist möglich, dass Faktoren wie das Geschlecht mit anderen Features korrelieren, die die Bäume stattdessen ausgewählt haben, und dies ihre Wirkung zu einem gewissen Grad verschleiert.
Die interessantere Frage ist nicht so sehr, ob diese Faktoren insgesamt eine Rolle spielen – es ist möglich, dass ihre durchschnittliche Auswirkung relativ gering ist –, sondern ob sie in einigen Einzelfällen eine signifikante Auswirkung haben. Dies sind die Instanzen, in denen uns das Modell etwas Wichtiges über die Erfahrung von Einzelpersonen mitteilt, und für diese Einzelpersonen ist diese Erfahrung das, was zählt.
Anwendung des Pakets SHAP für Erklärungen auf Entwicklerebene
Glücklicherweise hat sich in den letzten etwa fünf Jahren eine Reihe von Techniken für eine theoretisch fundiertere Modellinterpretation auf der Ebene einzelner Vorhersagen herausgebildet. Sie werden zusammenfassend als "Shapley Additive Explanations" bezeichnet und sind praktischerweise im Python-Paket shap implementiert.
Für jedes beliebige Modell berechnet diese Bibliothek die "SHAP-Werte". Diese Werte sind leicht interpretierbar, da jeder Wert die Auswirkung eines Features auf die Vorhersage in dessen Einheiten darstellt. Ein SHAP-Wert von 1000 bedeutet hier "erklärt +1.000 $ des prognostizierten Gehalts". SHAP-Werte werden auch so berechnet, dass versucht wird, Korrelation und Interaktion zu isolieren.
SHAP-Werte werden auch für jede Eingabe berechnet, nicht für das Modell als Ganzes, sodass diese Erklärungen für jede Eingabe einzeln verfügbar sind. Es kann auch die Auswirkung von Featureinteraktionen getrennt von der Hauptwirkung jedes Features für jede Vorhersage schätzen.
Erklärbare KI: Die Gesamtauswirkungen der Features aufdecken
Erklärungen auf Entwicklerebene können zu Erklärungen der Auswirkungen der Features auf das Gehalt über den gesamten Datensatz aggregiert werden, indem einfach ihre absoluten Werte gemittelt werden. SHAPs Bewertung der insgesamt wichtigsten Features ist ähnlich:
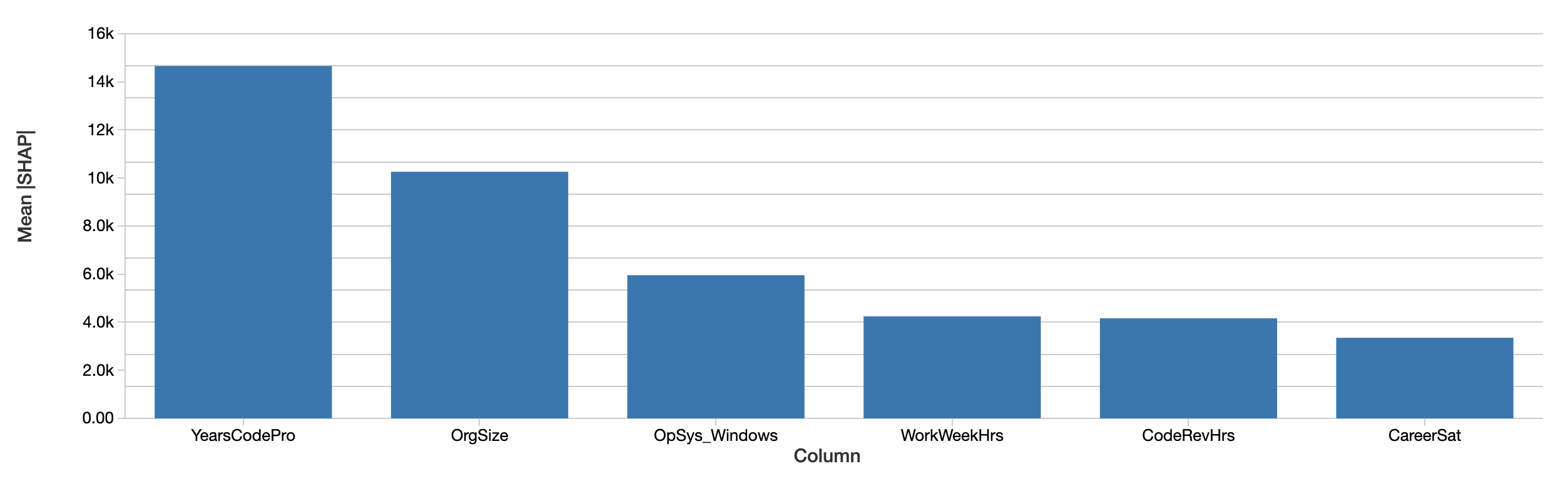
Die SHAP-Werte erzählen eine ähnliche Geschichte. Erstens kann SHAP den Einfluss auf das Gehalt in Dollar quantifizieren, was die Interpretation der Ergebnisse erheblich verbessert. Das obige Diagramm zeigt den absoluten Einfluss jedes Features auf das vorhergesagte Gehalt, gemittelt über alle Entwickler. Die Jahre an professioneller Programmiererfahrung dominieren immer noch und erklären im Durchschnitt einen Einfluss von fast 15.000 $ auf das Gehalt.
Ein praktischer Leitfaden zu Apps auf Databricks

Untersuchung der Auswirkungen des Geschlechts mit SHAP-Werten
Wir haben uns speziell die Auswirkungen von Geschlecht, ethnischer Zugehörigkeit und anderen Faktoren angesehen, die für das Gehalt per se überhaupt nicht prädiktiv sein sollten. Dieses Beispiel untersucht die Auswirkung des Geschlechts, obwohl dies keineswegs bedeutet, dass dies die einzige oder wichtigste Art von Verzerrung ist, nach der man suchen sollte.
Das Geschlecht ist nicht binär, und in der Umfrage werden die Antworten "Mann", "Frau" und "Nicht-binär, genderqueer oder gender-nonkonform" sowie "Trans" separat erfasst. (Beachten Sie, dass die Umfrage zwar auch separat Antworten zur Sexualität erfasst, diese hier aber nicht berücksichtigt werden.) SHAP berechnet für jeden dieser Fälle die Auswirkung auf das prognostizierte Gehalt. Für einen männlichen Entwickler (der sich nur als männlich identifiziert) ist die Auswirkung des Geschlechts nicht nur die Auswirkung, männlich zu sein, sondern auch, sich nicht als weiblich, transgender usw. zu identifizieren.
Die SHAP-Werte ermöglichen es uns, die Summe dieser Effekte für Entwickler abzulesen, die sich jeweils einer der vier Kategorien zuordnen:

Während das Geschlecht männlicher Entwickler einen bescheidenen Beitrag von ca. -230 $ bis +890 $ mit einem Mittelwert von ca. 225 $ erklärt, ist die Spanne für Frauen größer und reicht von ca. -4.260 $ bis -690 $ bei einem Mittelwert von -1.320 $. Die Ergebnisse für transgender und nicht-binäre Entwickler sind ähnlich, wenn auch etwas weniger negativ.
Bei der nachfolgenden Bewertung der Bedeutung ist es wichtig, die Einschränkungen der hier verwendeten Daten und des Modells zu berücksichtigen:
- Korrelation ist keine Kausalität. Die „Erklärung“ des prognostizierten Gehalts ist zwar ein Anhaltspunkt, beweist aber nicht, dass ein Feature direkt verursacht hat, dass das Gehalt höher oder niedriger ist.
- Das Modell ist nicht vollkommen genau.
- Dies sind nur Daten aus einem Jahr und nur von US-Entwicklern.
- Dies spiegelt nur das Grundgehalt wider, nicht Prämien oder Aktien, die stärker variieren können.
Verwendung von SHAP zur Visualisierung von Features, die mit dem Geschlecht interagieren
Die SHAP-Bibliothek bietet interessante Visualisierungen, die ihre Fähigkeit nutzen, die Auswirkungen von Feature-Interaktionen zu isolieren. Die obigen Werte deuten beispielsweise darauf hin, dass für Entwickler, die sich als männlich identifizieren, ein etwas höheres Gehalt als für andere prognostiziert wird, aber steckt da noch mehr dahinter? Ein Dependence Plot wie dieser kann helfen:
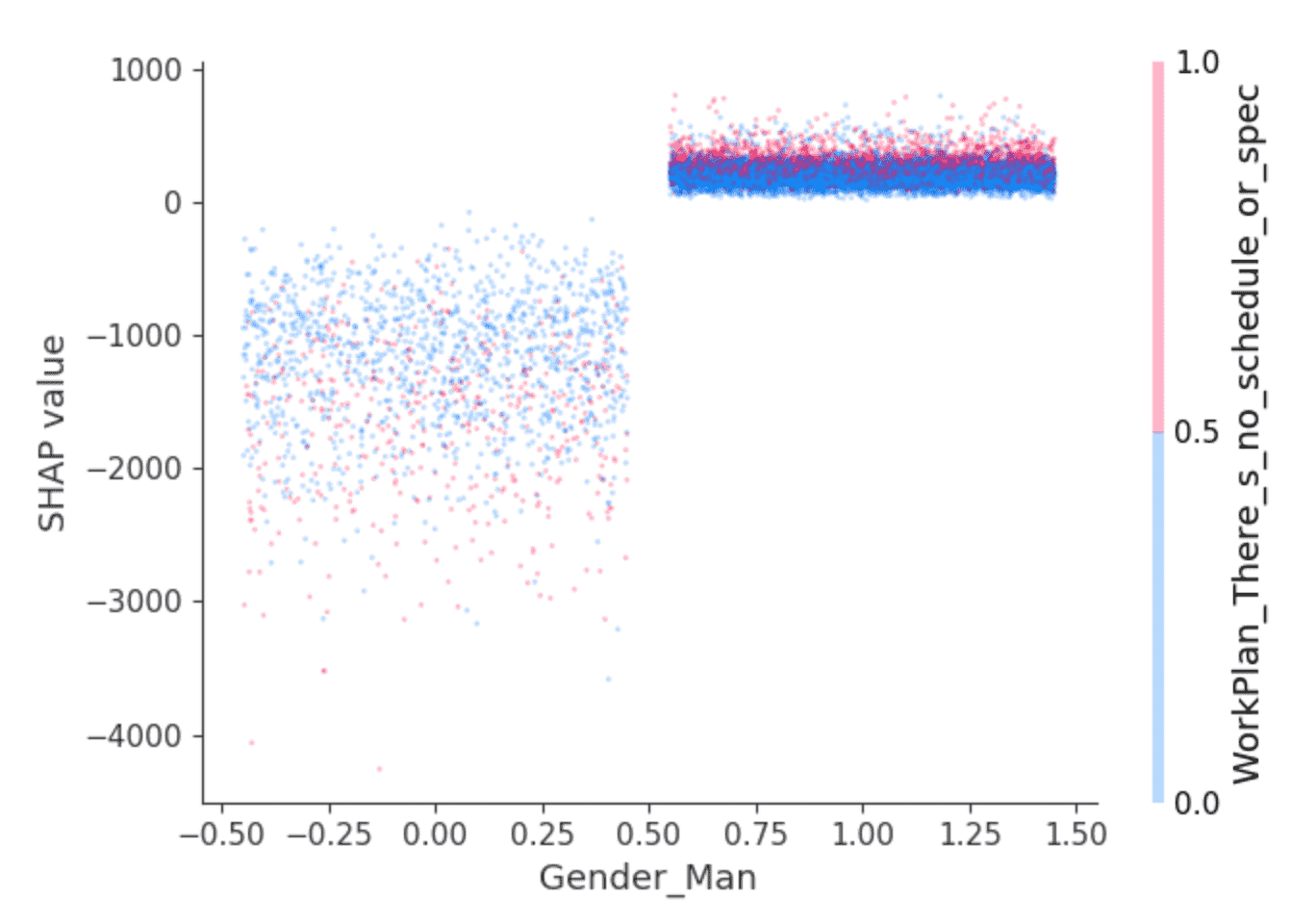
Die Punkte sind Entwickler. Die Entwickler auf der linken Seite sind diejenigen, die sich nicht als männlich identifizieren, und auf der rechten Seite diejenigen, die dies tun, wobei es sich überwiegend um Personen handelt, die sich ausschließlich als männlich identifizieren. (Die Punkte sind zur besseren Übersichtlichkeit horizontal zufällig verteilt.) Die y-Achse ist der SHAP-Wert, d. h. was die Identifizierung als männlich oder nicht-männlich über das vorhergesagte Gehalt für jeden Entwickler aussagt. Wie oben zeigen diejenigen, die sich nicht als männlich identifizieren, insgesamt negative SHAP-Werte, die stark variieren, während andere durchweg einen kleinen positiven SHAP-Wert aufweisen.
Was steckt hinter dieser Varianz? SHAP kann ein zweites Feature auswählen, dessen Auswirkung je nach Wert – in diesem Fall die Identifizierung als männlich oder nicht – am stärksten variiert. Es wählt die Antwort "Ich arbeite an dem, was am wichtigsten oder dringendsten erscheint" auf die Frage "Wie strukturiert oder geplant ist Ihre Arbeit?". Unter den Entwicklern, die sich als männlich identifizieren, scheinen diejenigen, die so geantwortet haben (rote Punkte), etwas höhere SHAP-Werte zu haben. Unter den Übrigen ist die Auswirkung uneinheitlicher, scheint aber im Allgemeinen niedrigere SHAP-Werte aufzuweisen.
Die Interpretation bleibt dem Leser überlassen, aber vielleicht: Bekommen männliche Entwickler, die sich in diesem Sinne bestärkt fühlen, auch etwas höhere Gehälter, während andere Entwickler dies genießen, wenn es mit niedriger bezahlten Rollen einhergeht?
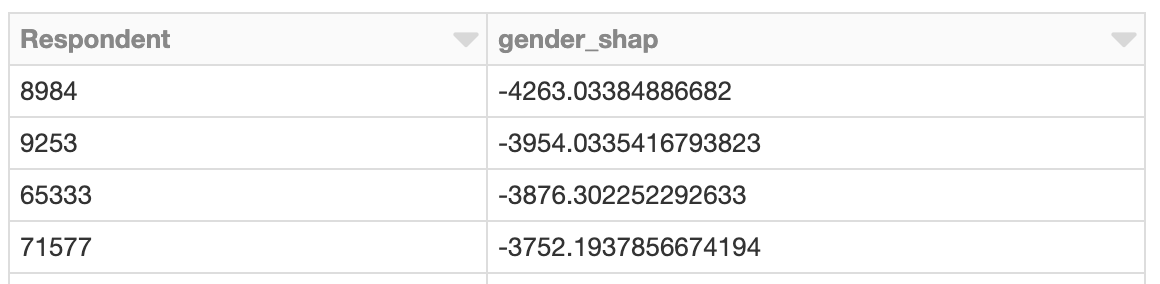
Untersuchung von Instanzen mit übergroßen Geschlechtereffekten
Wie wäre es mit der Untersuchung des Entwicklers, dessen Gehalt am negativsten beeinflusst wird? So wie es möglich ist, die Gesamtauswirkung geschlechtsbezogener Features zu betrachten, ist es auch möglich, nach dem Entwickler zu suchen, dessen geschlechtsbezogene Features den größten Einfluss auf das prognostizierte Gehalt hatten. Diese Person ist weiblich, und die Auswirkung ist negativ. Laut Modell wird für sie aufgrund ihres Geschlechts ein um etwa 4.260 $ geringeres Jahresgehalt prognostiziert:

Das prognostizierte Gehalt, knapp über 157.000 USD, ist in diesem Fall korrekt, da ihr tatsächliches Gehalt 150.000 USD beträgt.
Die drei positivsten und negativsten Features, die das prognostizierte Gehalt beeinflussen, sind, dass sie:
- Hat einen Hochschulabschluss (nur) (+18.200 $)
- Hat 10 Jahre Berufserfahrung (+9.400 $)
- Identifiziert sich als ostasiatisch (+9.100 $)
- ...
- Arbeitet 40 Stunden pro Woche (-$4.000)
- Identifiziert sich nicht als männlich (-$4.250)
- in einer mittelgroßen Organisation mit 100–499 Mitarbeitern arbeitet (-9.700 $)
Angesichts der Größenordnung des Effekts, den die Nicht-Identifizierung als männlich auf das vorhergesagte Gehalt hat, könnten wir hier innehalten und die Details dieses Falls offline untersuchen, um ein besseres Verständnis für den Kontext dieser Entwicklerin zu gewinnen und um zu prüfen, ob ihre Erfahrung, ihr Gehalt oder beides geändert werden muss.
Erklären von Interaktionen mithilfe von SHAP-Werten
Weitere Details zu den -4.260 $ sind verfügbar. SHAP kann die Auswirkungen dieser Features in Interaktionen aufschlüsseln. Der Gesamteffekt der Identifizierung als weiblich auf die Vorhersage kann in den Effekt der Identifizierung als weiblich und der Position als Engineering Manager, und der Arbeit mit Windows usw. zerlegt werden.
Die Auswirkung der geschlechtsspezifischen Faktoren auf das voraussichtliche Gehalt beläuft sich nur auf etwa -$630. Vielmehr ordnet SHAP die meisten Auswirkungen des Geschlechts den Wechselwirkungen mit anderen Features zu:
Die Identifikation als weiblich und die Arbeit mit PostgreSQL wirken sich leicht positiv auf das prognostizierte Gehalt aus, während sich die zusätzliche Identifikation als ostasiatisch negativer auswirkt. Die Interpretation dieser Werte auf dieser Granularitätsebene ist in diesem Kontext schwierig, aber diese zusätzliche Erklärungsebene ist verfügbar.
Anwendung von SHAP mit Apache Spark
SHAP-Werte werden für jede Zeile unabhängig voneinander auf Basis des Modells berechnet, und dies hätte auch parallel mit Spark durchgeführt werden können. Das folgende Beispiel computet SHAP-Werte parallel und findet in ähnlicher Weise Entwickler mit übergroßen geschlechtsbezogenen SHAP-Werten:
Clustering von SHAP-Werten
Die Anwendung von Spark ist vorteilhaft, wenn eine große Anzahl von Vorhersagen mit SHAP bewertet werden soll. Anhand dieser Ausgabe ist es auch möglich, Spark zu verwenden, um die Ergebnisse in Clusters zu gruppieren, zum Beispiel mit bisecting k-means:
Der Cluster, dessen gesamte geschlechtsbezogene SHAP-Effekte am negativsten sind, sollte möglicherweise genauer untersucht werden. Was sind die SHAP-Werte der Befragten in dem Cluster? Wie sehen die Mitglieder des Clusters im Vergleich zur gesamten Entwicklerpopulation aus?
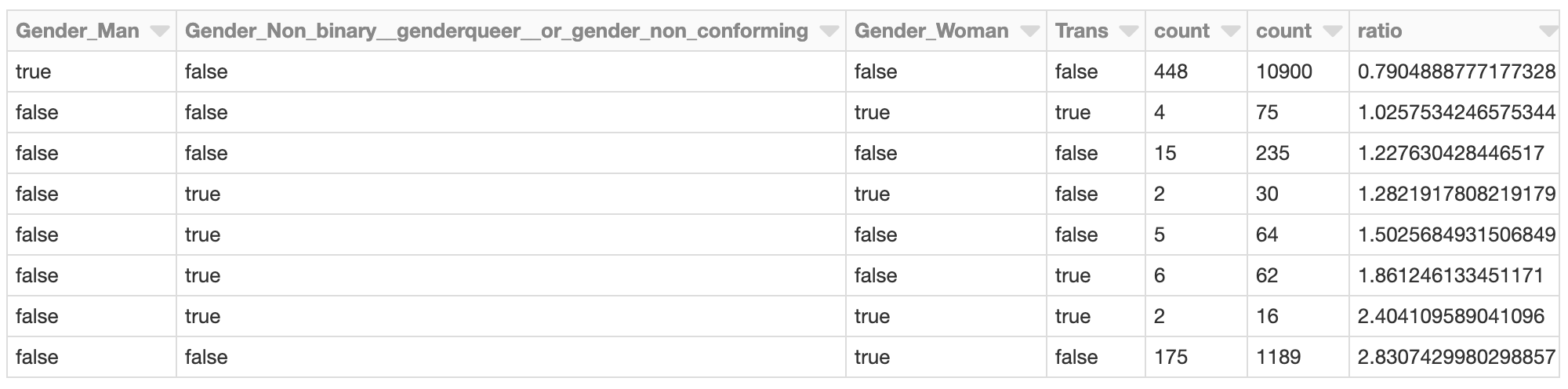
Entwicklerinnen, die sich (ausschließlich) als weiblich identifizieren, sind in diesem Cluster beispielsweise mit einer fast 2,8-mal höheren Rate als in der gesamten Entwicklerpopulation vertreten. Dies ist angesichts der früheren Analyse nicht überraschend. Dieses Cluster könnte weiter untersucht werden, um andere für diese Gruppe spezifische Faktoren zu bewerten, die zu dem insgesamt niedriger prognostizierten Gehalt beitragen.
Fazit
Diese Art von Analysen mit SHAP kann für jedes Modell und auch im großen Scale in Ausführung gebracht werden. Als Analysewerkzeug verwandelt es Modelle in Datendetektive, um einzelne Fälle aufzudecken, deren Vorhersagen darauf hindeuten, dass sie eine genauere Untersuchung verdienen. Die Ausgabe von SHAP ist leicht interpretierbar und liefert intuitive Diagramme, die von Geschäftsanwendern von Fall zu Fall bewertet werden können.
Natürlich beschränkt sich diese Analyse nicht auf die Untersuchung von Fragen bezüglich Voreingenommenheit aufgrund von Geschlecht, Alter oder ethnischer Zugehörigkeit. Nüchterner betrachtet, könnte sie auf Modelle zur Kundenabwanderung angewendet werden. Dabei lautet die Frage nicht nur: "Wird dieser Kunde abwandern?", sondern: "Warum wandert der Kunde ab?" Einem Kunden, der aufgrund des Preises kündigt, kann ein Rabatt angeboten werden, während ein anderer, der wegen begrenzter Nutzung kündigt, möglicherweise ein Upsell benötigt.
Schließlich kann diese Analyse als Teil eines Validierungsprozesses durchgeführt werden, was dem Machine-Learning-Modell insgesamt mehr Transparenz verleiht. Die Modellvalidierung konzentriert sich oft auf die Gesamtgenauigkeit eines Modells. Sie sollte sich auch auf die ‚Begründung‘ des Modells konzentrieren, d. h. darauf, welche Features am meisten zu den Vorhersagen beigetragen haben. Mit SHAP kann auch erkannt werden, wenn die Erklärungen zu vieler einzelner Vorhersagen im Widerspruch zur allgemeinen Feature-Wichtigkeit stehen.