Pandas-API im kommenden Apache Spark™ 3.2
Die Free Edition ersetzt die Community Edition und bietet erweiterte Features kostenlos. Nutzen Sie die Free Edition noch heute.
Wir freuen uns, bekannt zu geben, dass die pandas-API Teil des kommenden Apache Spark™ 3.2-Release sein wird. pandas ist eine leistungsstarke, flexible Bibliothek und hat sich schnell zu einer der Standardbibliotheken für Data Science entwickelt. Ab sofort können Pandas-Nutzer die Pandas-API auf ihren bestehenden Spark-Clustern nutzen.
Vor einigen Jahren haben wir Koalas ins Leben gerufen, ein Open Source-Projekt, das die pandas DataFrame-API auf Spark implementiert und bei data scientists sehr beliebt wurde. Kürzlich wurde Koalas im Rahmen von Project Zen offiziell durch SPIP: Support pandas API layer on PySpark in PySpark zusammengeführt (siehe auch Project Zen: Making Data Science Easier in PySpark vom Data + AI Summit 2021).
pandas-Nutzer werden ihre Workloads im kommenden Spark 3.2-Release mit der Änderung einer einzigen Codezeile skalieren können:
Dieser Blogpost fasst die Unterstützung der pandas-API in Spark 3.2 zusammen und hebt die wichtigsten Features, Änderungen und die Roadmap hervor.
Skalierbarkeit über einen einzelnen Rechner hinaus
Eine der bekannten Einschränkungen von pandas ist, dass es aufgrund der Verarbeitung auf einem einzigen Rechner nicht linear mit dem Datenvolumen skaliert. Zum Beispiel tritt bei pandas ein Out-of-Memory-Fehler auf, wenn versucht wird, ein Dataset zu lesen, das größer ist als der auf einem einzigen Rechner verfügbare Speicher:
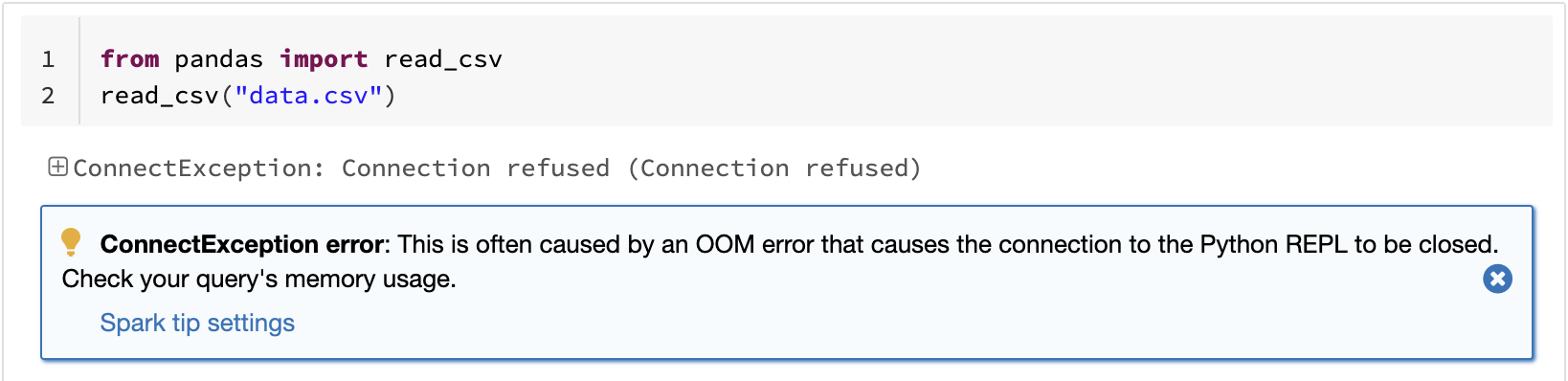
Die Pandas-API auf Spark überwindet diese Einschränkung und ermöglicht es Benutzern, große Datasets mithilfe von Spark zu verarbeiten:

Die pandas-API in Spark skaliert auch gut auf große Cluster. Das folgende Diagramm zeigt die Performance bei der Analyse eines 15-TB-Parquet-Datasets mit Clusters unterschiedlicher Größe. Jeder Rechner im Cluster verfügt über 8 vCPUs und 61 GiB Arbeitsspeicher.
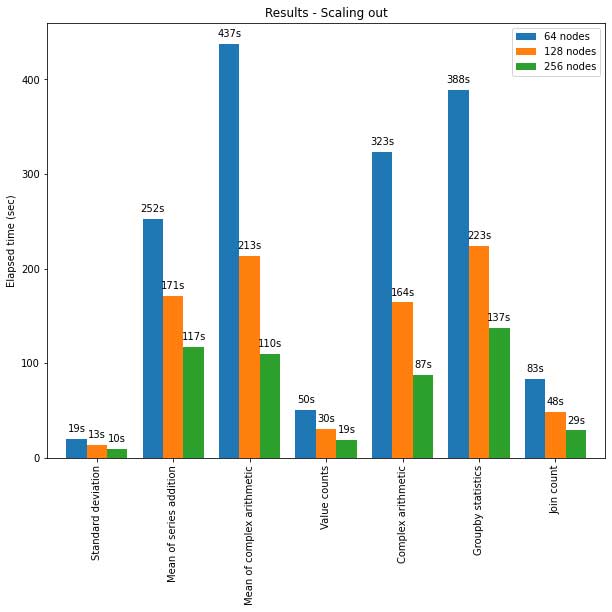
Die verteilte Ausführung der pandas-API auf Spark skaliert in diesem Test fast linear. Die Laufzeit halbiert sich, wenn sich die Anzahl der Maschinen in einem Cluster verdoppelt. Die Beschleunigung im Vergleich zu einer einzelnen Maschine ist ebenfalls signifikant. Zum Beispiel kann ein Cluster aus 256 Maschinen beim Benchmark Standardabweichung in ungefähr der gleichen Zeit ~250-mal mehr Daten verarbeiten als eine einzelne Maschine (jede Maschine hat 8 vCPUs und 61 GiB Arbeitsspeicher):
| Einzelmaschine | Cluster aus 256 Rechnern | |
| Parquet-Datensatz | 60 GB | 60 GB x 250 (15 TB) |
| Verstrichene Zeit (Sek.) der Standardabweichung | 12s | 10 s |
Optimierte Performance für Einzelrechner
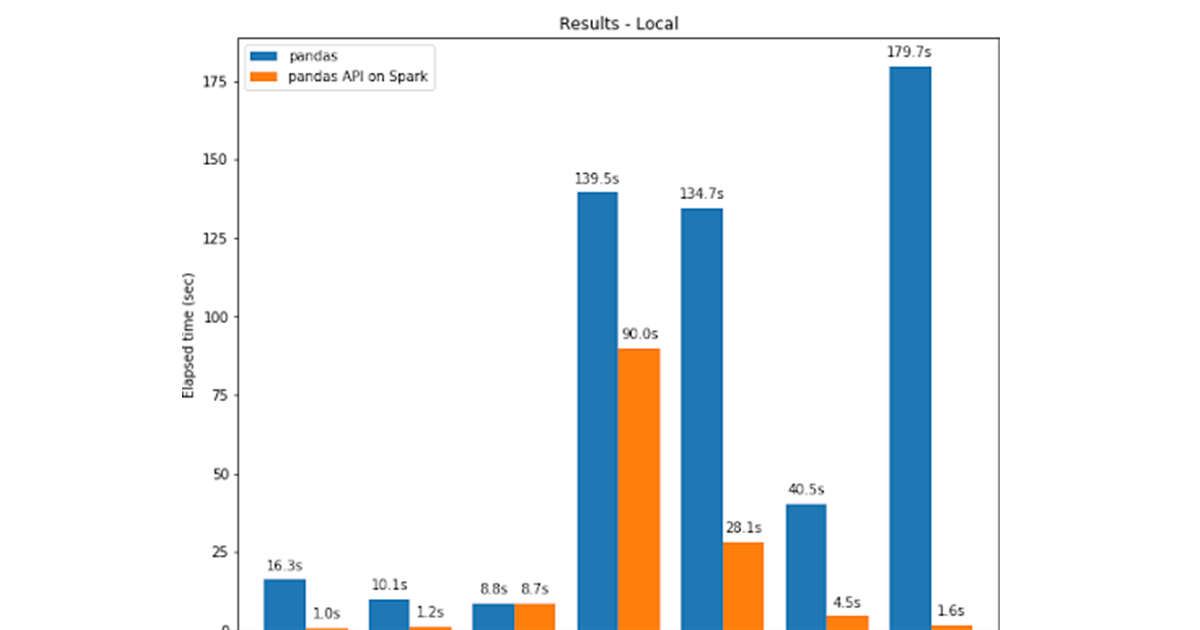
Die Pandas-API für Spark übertrifft Pandas dank der Optimierungen in der Spark-Engine oft sogar auf einem einzigen Rechner. Das nachstehende Diagramm vergleicht die pandas-API für Spark mit pandas auf einem Rechner (mit 96 vCPUs und 384 GiB Speicher) anhand eines 130-GB-CSV-Datasets:
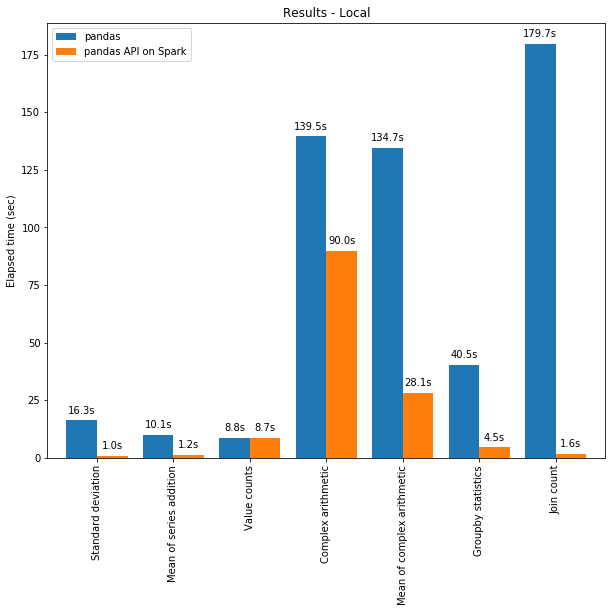
Sowohl Multi-Threading als auch der Spark SQL Catalyst Optimizer tragen zur optimierten Performance bei. Zum Beispiel ist der Join Count -Betrieb mit der Whole-Stage-Codegenerierung ca. 4-mal schneller: 5,9 s ohne Codegenerierung, 1,6 s mit Codegenerierung.
Spark hat einen besonders großen Vorteil bei der Verkettung von Operationen. Der Catalyst-Abfrageoptimierer kann Filter erkennen, um Daten intelligent zu überspringen, und kann datenträgerbasierte Joins anwenden, während Pandas dazu neigt, bei jedem Schritt alle Daten in den Arbeitsspeicher zu laden.
Betrachtet man eine Query, die zwei gefilterte Frames einen Join durchführt und dann den Mittelwert des verbundenen Frames berechnet, ist die Pandas-API für Spark innerhalb von 4,5 s erfolgreich, während Pandas aufgrund des folgenden OOM-Fehlers (Out of Memory) fehlschlägt:
Interaktive Datenvisualisierung
pandas verwendet standardmäßig matplotlib, das statische Diagramme bereitstellt. Der folgende Code generiert zum Beispiel ein statisches Diagramm:
Im Gegensatz dazu verwendet die pandas-API auf Spark standardmäßig ein plotly -Backend, das interaktive Diagramme bereitstellt. Beispielsweise können Benutzer damit interaktiv hinein- und herauszoomen. Basierend auf dem Diagrammtyp bestimmt die pandas-API in Spark bei der Erstellung interaktiver Diagramme automatisch die beste Methode zur internen Ausführung der Berechnung:
Nutzung einheitlicher Analysefunktionen in Spark
pandas wurde für Python Data Science mit Batch-Verarbeitung entwickelt, während Spark für unified analytics konzipiert wurde, einschließlich SQL, Streaming-Verarbeitung und Machine Learning. Um die Lücke zwischen ihnen zu schließen, bietet die pandas-API auf Spark fortgeschrittenen Nutzern viele verschiedene Möglichkeiten, die Spark-Engine zu nutzen, zum Beispiel:
- Benutzer können Daten mit der optimierten SQL-Engine von Spark direkt per SQL abfragen, wie unten dargestellt:
- Es unterstützt auch die String-Interpolationssyntax, um auf natürliche Weise mit Python-Objekten zu interagieren:
- pandas API on Spark unterstützt auch Streaming-Verarbeitung:
- Benutzer können die skalierbaren Machine Learning Libraries (MLlib) in Spark einfach aufrufen:
Siehe auch den Blogpost über die Interoperabilität zwischen PySpark und der pandas-API in Spark.
Was kommt als Nächstes?
Für die nächsten Spark-Releases konzentriert sich die Roadmap auf:
• Mehr Typ-Hinweise
Der Code in der pandas-API auf Spark ist derzeit teilweise typisiert, was weiterhin statische Analysen und automatische Vervollständigung ermöglicht. In Zukunft wird der gesamte Code vollständig typisiert sein.
• Leistungsverbesserungen
Es gibt mehrere Stellen in der pandas-API auf Spark, an denen wir die Leistung weiter verbessern können, indem wir enger mit der Engine und dem SQL-Optimierer interagieren.
• Stabilisierung
Es gibt mehrere Stellen, die korrigiert werden müssen, insbesondere im Zusammenhang mit fehlenden Werten wie NaN und NA, die in Grenzfällen unterschiedliche Verhaltensweisen aufweisen.
Darüber hinaus wird die pandas-API auf Spark ihr Verhalten in diesen Fällen an die neueste Version von pandas anpassen.
• Mehr API-Abdeckung
Die pandas-API in Spark hat eine Abdeckung von 83 % der pandas-API erreicht, und diese Zahl steigt weiter an. Jetzt liegt das Ziel bei bis zu 90 %.
Bitte melden Sie ein Problem, wenn es Fehler oder fehlende Features gibt, die Sie benötigen. Selbstverständlich freuen wir uns auch immer über Beiträge aus der Community.
Erste Schritte
Wenn Sie die Pandas-API auf Spark in Databricks Runtime 10.0 Beta (bevorstehendes Apache Spark 3.2) ausprobieren möchten, registrieren Sie sich kostenlos für die Databricks Community Edition oder die Databricks-Testversion und legen Sie in wenigen Minuten los.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Verpassen Sie keinen Beitrag von Databricks
Was kommt als Nächstes?

Data Science e ML
October 31, 2023/9 min de leitura
