Data Warehouse

Was ist ein Data Warehouse?
Ein Data Warehouse ist ein Datenverwaltungssystem, das aktuelle und historische Daten aus verschiedenen Quellen in einer unternehmensgerechten Weise speichert, um Einblicke und Berichte zu erleichtern. Data Warehouses kommen in der Regel in Bereichen wie Business Intelligence (BI), Analysen, Berichterstellung, Datenanwendungen, der Aufbereitung von Daten für Machine Learning (ML) und Datenanalyse zum Einsatz.
Data Warehouses ermöglichen schnelle und einfache Analysen von Unternehmensdaten, die aus operativen Systemen wie Kassensystemen, Bestandsverwaltungssystemen oder Marketing- und Vertriebsdatenbanken importiert werden. Die Daten durchlaufen möglicherweise einen operativen Datenspeicher und müssen bereinigt werden, um die Datenqualität sicherzustellen, ehe sie im Data Warehouse für Berichte verwendet werden können.
Ähnliche Themen erkunden


Für welche Zwecke werden Data Warehouses verwendet?
Data Warehouses werden für BI, Analytics, Berichterstattung, Datenanwendungen, die Vorbereitung von Daten für maschinelles Lernen und die Datenanalyse zu dem Zweck eingesetzt, Daten aus operativen Datenbanken zu extrahieren und zusammenzufassen. Informationen, die sich direkt in Transaktionsdatenbanken nur unter Schwierigkeiten analysieren lassen, können über Data Warehouses ausgewertet werden. Ein Beispiel: Das Management möchte die Gesamteinnahmen ermitteln, die jeder Verkäufer monatlich für jede Produktkategorie erzielt. Diese Daten werden in Transaktionsdatenbanken vielleicht nicht erfasst, mit einem Data Warehouse geht das jedoch.
Welche Arten von Data Warehouses gibt es?
- Traditionelles Data Warehouse: Ein solches Data Warehouse speichert nur strukturierte Daten. Die Struktur eines Data Warehouse ermöglicht es Benutzern, schnell und bequem auf Daten für Berichte und Analysen zuzugreifen.
- Intelligentes Data Warehouse: Hierbei handelt es sich um eine moderne Data-Warehouse-Variante, die auf einer Lakehouse-Architektur basiert und über eine intelligente und automatisch optimierende Plattform verfügt. Ein intelligentes Data Warehouse bietet nicht nur Zugriff auf KI- und ML-Modelle, sondern nutzt KI außerdem zur Unterstützung bei Abfragen, der Erstellung von Dashboards und der Optimierung von Performance und Skalierung.
Data-Warehouse-Architektur
Ein verbreitetes Modell für die Architektur von Data Warehouses ist mehrschichtig. Diese Architektur wurde von Bill Inmon entwickelt, einem Informatiker, der oft als Vater des Data Warehouse bezeichnet wird.
Untere Schicht
Die untere Schicht einer Data-Warehouse-Architektur umfasst Datenquellen und Datenspeicher. In dieser Schicht befinden sich Datenzugriffsmethoden, wie etwa APIs, Gateways, ODBC, JDBC und OLE-DB. Auch die Datenaufnahme oder ETL sind in der untersten Schicht enthalten.
Mittlere Schicht
Die mittlere Schicht einer Data-Warehouse-Architektur besteht aus einem OLAP-Server, der entweder relational (ROLAP) oder multidimensional (MOLAP) ist. Diese beiden Typen können zu einem hybriden OLAP (HOLAP) kombiniert werden.
Obere Schicht
Die obere Schicht einer Data-Warehouse-Architektur besteht aus den Front-End-Clients für Abfragen, BI, Dashboards, Berichterstellung und Analysen.
Welche drei Varianten von Data Warehouses gibt es?
- Enterprise Data Warehouse (EDW): Ein zentralisiertes Data Warehouse, das von vielen verschiedenen Teams in einer Organisation genutzt wird. Es fungiert oft als Single Source of Truth (maßgebliche Datenquelle) für BI, Analysen und Berichterstellung.
- Operational Data Store (ODS): Dies ist eine Form des Data Warehouse, bei der der Schwerpunkt auf den aktuellen Betriebs- oder Transaktionsdaten liegt.
- Data Mart: Eine vereinfachte Version des Data Warehouse, die einen einzelnen Geschäftsbereich (Line of Business, LOB) oder ein einzelnes Projekt unterstützt. Ein Data Mart ist kleiner als ein EDW, aber die Anzahl der Data Marts nimmt in der Regel mit dem Wachstum einer Organisation zu, da die Geschäftsbereiche Self-Service wünschen.
Data Lake, Datenbank und Data Warehouse im Vergleich
Worin besteht der Unterschied zwischen einem Data Lake und einem Data Warehouse?
Data Lakes und Data Warehouses sind zwei unterschiedliche Ansätze zur Verwaltung und Speicherung von Daten.
Ein Data Lake ist ein unstrukturiertes oder halbstrukturiertes Daten-Repository, das die Speicherung großer Mengen von Rohdaten in ihrem ursprünglichen Format ermöglicht. Data Lakes sind so konzipiert, dass sie alle Arten von Daten – strukturierte, halbstrukturierte oder unstrukturierte – ohne vordefiniertes Schema aufnehmen und speichern können. Daten werden häufig in ihrem ursprünglichen Format gespeichert und nicht bereinigt, transformiert oder integriert, was das Speichern und Zugreifen auf große Datenmengen erleichtert.
Bei einem traditionellen Data Warehouse hingegen handelt es sich um ein strukturiertes Repository, in dem Daten aus verschiedenen Quellen gut organisiert gespeichert werden. Ziel ist es, eine Single Source of Truth für Business Intelligence und Analysen bereitzustellen. Die Daten werden bereinigt, umgewandelt und in ein Schema integriert, das für Abfragen und Analysen optimiert ist.
Ein intelligentes Data Warehouse, das die Lakehouse-Architektur verwendet, fungiert ebenfalls als Single Source of Truth für Business Intelligence und Analysen. Es erweitert ein traditionelles Data Warehouse durch Speicherung strukturierter, halbstrukturierter und unstrukturierter Daten. Auch umfasst es Funktionen zur Datenverwaltung wie Datenqualität und Threshold-Warnungen.
Wie unterscheidet sich ein Data Warehouse von einer Datenbank?
Eine Datenbank ist eine Sammlung strukturierter Daten, die über Text und Zahlen hinausgehen und auch Bilder, Videos und mehr enthalten können. Häufig werden solche Datenbankverwaltungssysteme mit dem zugehörigen Akronym DBMS (für „Data-Base Management System“) bezeichnet. Ein DBMS ist das Speichersystem für Daten, die in Anwendungen und Analysen verwendet werden.
Bei einem traditionellen Data Warehouse hingegen handelt es sich um ein strukturiertes Repository, das Daten für Business Intelligence und Analysen bereitstellt. Die Daten werden bereinigt, umgewandelt und in ein Schema integriert, das für Abfragen und Analysen optimiert ist. Dabei werden auch gängige Aggregationen hinzugefügt.
Worin besteht der Unterschied zwischen einem Data Lake, einem Data Warehouse und einem Data Lakehouse?
Ein Data Lakehouse ist ein hybrider Ansatz, der das Beste aus beiden Welten kombiniert. Es handelt sich um eine moderne Datenarchitektur, die die Funktionen eines traditionellen Data Warehouse und eines Data Lake auf einer einheitlichen Plattform zusammenführt. Es ermöglicht die Speicherung von Rohdaten in ihrem ursprünglichen Format wie bei einem Data Lake und bietet die gleichen Funktionen zur Datenverarbeitung und -analyse wie ein Data Warehouse.
Zusammenfassend lässt sich sagen, dass der wesentliche Unterschied zwischen einem Data Lake, einem traditionellen Data Warehouse und einem Data Lakehouse in der Art und Weise liegt, wie die Daten verwaltet und gespeichert werden. Ein traditionelles Data Warehouse speichert strukturierte Daten in einem vordefinierten Schema, ein Data Lake speichert Rohdaten in ihrem ursprünglichen Format, und ein Data Lakehouse ist ein hybrider Ansatz, der die Funktionen beider Systeme kombiniert.
Data Lake | Data Lakehouse | Traditionelles Data Warehouse | |
|---|---|---|---|
Datentypen | Alle Typen: strukturierte Daten, halbstrukturierte Daten, unstrukturierte (Roh-)Daten | Alle Typen: strukturierte Daten, halbstrukturierte Daten, unstrukturierte (Roh-)Daten | Nur strukturierte Daten |
Kosten | $ | $ | €€€ |
Format | Offenes Format | Offenes Format | Geschlossenes, proprietäres Format |
Skalierbarkeit | Skalierbar, um Datenmengen jeglicher Größenordnung zu geringen Kosten zu speichern, unabhängig vom Datentyp | Skalierbar, um Datenmengen jeglicher Größenordnung zu geringen Kosten zu speichern, unabhängig vom Datentyp | Eine Skalierung nach oben wird aufgrund der Anbieterkosten exponentiell teurer |
Zielgruppe | Begrenzt: Data Scientists | Vereinheitlicht: Datenanalysten, Data Scientists, Machine Learning Engineers | Begrenzt: Datenanalysten |
Zuverlässigkeit | Geringe Qualität, Datensumpf | Hochwertige und zuverlässige Daten | Hochwertige und zuverlässige Daten |
Anwenderfreundlichkeit | Problematisch: Die Analyse großer Mengen von Rohdaten kann sich ohne Tools zur Organisation und Katalogisierung der Daten schwierig gestalten | Einfach: Kombiniert die Bequemlichkeit und Struktur eines Data Warehouse mit den breiter angelegten Anwendungsfällen eines Data Lake | Einfach: Die Struktur eines Data Warehouse ermöglicht es Benutzern, schnell und problemlos auf Daten für Berichte und Analysen zuzugreifen |
Performance | Mangelhaft | Hoch | Hoch |
Kann ein Data Lake ein Data Warehouse ersetzen?
Eigentlich nicht. Bei einem Data Lake und einem Data Warehouse handelt es sich um zwei unterschiedliche Ansätze zur Verwaltung und Speicherung von Daten. Beide Ansätze haben Vor- und Nachteile. Zwar kann ein Data Lake ein Data Warehouse ergänzen, indem er Rohdaten für erweiterte Analysen bereitstellt, doch kann er ein Data Warehouse im herkömmlichen Sinne nicht vollständig ersetzen. Vielmehr können sich ein Data Lake und ein Data Warehouse gegenseitig ergänzen. Dabei dient der Data Lake als Quelle von Rohdaten für erweiterte Analysen, während das Data Warehouse eine strukturierte, organisierte und zuverlässige Quelle von Unternehmensdaten für Berichte und Analysen bietet.
Ein Data Lake bildet die Grundlage für ein Data Lakehouse, das ein traditionelles Data Warehouse ersetzen kann und Zuverlässigkeit sowie Leistung bei offenen Datenformaten wie Delta Lake und Apache Iceberg™ bietet.
Kann ein Data Lakehouse ein traditionelles Data Warehouse ersetzen?
Ja. Bei einem Data Lakehouse handelt es sich um eine moderne Datenarchitektur, die die Vorteile eines Data Warehouse und eines Data Lake in einer einheitlichen Plattform vereint. Ein Data Lakehouse setzt auf einen offenen Data Lake auf und kann als Ersatz für ein herkömmliches Data Warehouse dienen, da es sowohl die Funktionen eines Data Lake als auch eines Data Warehouse auf einer zentralen Plattform bietet.
Ein Data Lakehouse ermöglicht die Speicherung von Rohdaten in ihrem ursprünglichen Format wie bei einem Data Lake und bietet zugleich Funktionen zur Verarbeitung und Analyse von Daten wie ein Data Warehouse. Darüber hinaus bietet es einen Schema-on-Read-Ansatz, der eine flexible Verarbeitung und Abfrage von Daten ermöglicht. Die Kombination aus einem Data Lake und einem Data Warehouse auf einer zentralen Plattform sorgt für mehr Flexibilität, Skalierbarkeit und Kosteneffizienz.
Was ist ein modernes Data Warehouse?
Das Data Warehousing entwickelt sich ständig weiter. Ein modernes Data Warehouse wird auch als „intelligentes“ Data Warehouse bezeichnet, da es neuere Technologien wie KI verwendet. Ein intelligentes Data Warehouse nutzt die offene Data-Lakehouse-Architektur anstelle der traditionellen Data-Warehouse-Architektur. Das intelligente Data Warehouse vollzieht die Besonderheiten Ihrer Daten nach und optimiert die Plattform automatisch, um eine geringe Latenz und hohe Nebenläufigkeit zu erzielen. Ein intelligentes Data Warehouse benötigt außerdem eine einheitliche Governance für Sicherheit, Kontrollen und Workflows. Ein intelligentes Data Warehouse nutzt KI, um Abfragen zu generieren, Fehler zu korrigieren, Visualisierungen anzubieten und vieles mehr.
Was ist ETL in einem Data Warehouse?
Ein Data Warehouse benötigt Daten. Diese Daten müssen in das Data Warehouse geladen (oder mithilfe eines Konzepts namens Lakehouse Federation referenziert) werden. Der Prozess der Datenextraktion aus Quellsystemen, der Datentransformation und des anschließenden Ladens der Daten in das Data Warehouse wird als ETL (Extract, Transform, Load) bezeichnet. ETL wird in der Regel zur Integration strukturierter Daten aus mehreren Quellen in ein vordefiniertes Schema verwendet.
Der Abfrageverbund ist ein ETL-Stil, mit dem Abfragen von Daten aus mehreren Quellen und auch cloudübergreifend ausgeführt werden können. Sie können alle Daten an zentraler Stelle anzeigen und abfragen, ohne sie erst vollständig in ein einheitliches System migrieren zu müssen. Manchmal wird dieses Konzept auch als Datenvirtualisierung bezeichnet.
Was ist eine Dimension in einem Data Warehouse?
Eine Dimension wird im Data Warehouse verwendet, um die Daten mit strukturierten Labeln zu beschreiben. Diese Informationen einer Dimension werden zum Filtern, Gruppieren und Kennzeichnen verwendet. Eine Dimension könnte beispielsweise eine wirtschaftliche Einheit wie etwa ein Kunde oder ein Produkt sein.
Was ist ein Fakt in einem Data Warehouse?
Ein Data-Warehouse-Fakt wird verwendet, um die Daten numerisch zu quantifizieren. Beispiele für Fakten wären Kundenaufträge oder Finanzdaten.
Was ist dimensionales Modellieren in einem Data Warehouse?
Dimensionales Modellieren ist ein Data-Warehousing-Verfahren, bei dem Daten in Form von Dimensionen und Fakten organisiert werden. Beim dimensionalen Modellieren werden wichtige Geschäftsprozesse ermittelt. Anschließend wird das Data Warehouse dann so modelliert, dass diese Geschäftsprozesse unterstützt werden.
Was ist ein Sternschema bei einem Data Warehouse?
Ein Sternschema ist ein mehrdimensionales Datenmodell, mit dem Daten in einer Datenbank so organisiert werden, dass sie leicht zu verstehen und zu analysieren sind. Sternschemata können auf Data Warehouses, Datenbanken, Data Marts und weitere Tools angewendet werden. Das Sternschemadesign ist für die Abfrage großer Datenmengen optimiert.
Sternschemata wurden in den 1990er-Jahren von Ralph Kimball vorgestellt und eignen sich zum effizienten Speichern von Daten, zur Verlaufsverwaltung und zur Datenaktualisierung, denn sie reduzieren die Duplizierung sich wiederholender Geschäftsdefinitionen und beschleunigen so Aggregation und Filterung von Daten im Data Warehouse.
Welche Vorteile können Unternehmen von einem Data Warehouse erwarten?
- Die Konsolidierung von Daten aus vielen Quellen. Ein Data Warehouse kann zu einem zentralen Zugangspunkt für alle Daten werden, sodass Benutzer keine Verbindung zu Dutzenden oder gar Hunderten von einzelnen Datenspeichern mehr herstellen müssen.
- Data Intelligence für historische Daten. Ein Data Warehouse integriert Daten aus zahlreichen Quellen, um historische Trends aufzuzeigen.
- Von den Transaktionsdatenbanken entkoppelte Analyseverarbeitung, um die Performance beider Systeme zu verbessern.
- Qualität, Konsistenz und Richtigkeit von Daten. Ein wohlgeformtes Data Warehouse verwendet eine standardisierte semantische Struktur für Daten, einschließlich konsistenter Benennungen, Codes für verschiedene Produkttypen, Sprachen, Währungen usw.
- Jeder kann Antworten anhand der Daten gewinnen, auch Benutzer ohne SQL-Kenntnisse.
Herausforderungen bei Data Warehouses
Unabhängig von der Art des von Ihnen verwendeten Data Warehouse gibt es immer gewisse Herausforderungen:
- Unzusammenhängende Tools für Daten und KI-Ressourcen ergeben einen fragmentierten Ansatz, der die Data Governance beeinträchtigt.
- Benutzer benötigen Fachkenntnisse und spezielle Schulungen, um Abfragen zu schreiben, Datenstrukturen zu verstehen, die besten Datenquellen zu finden und eine Verbindung mit ihnen herzustellen usw.
- Je größer Warehouses werden, desto langsamer werden sie – und in der Cloud aufgrund hoher Cloud-Computing-Kosten auch schnell teuer
Skalierbarkeit und Leistung
Bei wachsenden Datenmengen verteilt eine Lakehouse-Architektur die Rechenfunktionen unabhängig vom Speicher, um eine gleichbleibende Leistung zu möglichst geringen Kosten zu gewährleisten. Sie benötigen eine Plattform, die auf Elastizität ausgelegt ist, d. h., die es Organisationen ermöglicht, ihre Datenoperationen nach Bedarf zu skalieren. Die Skalierbarkeit erstreckt sich dabei über verschiedene Dimensionen:
- Serverless: Die Plattform sollte es ermöglichen, die Workloads je nach erforderlicher Rechenkapazität flexibel anzupassen und zu skalieren. Eine solche dynamische Ressourcenzuweisung garantiert eine schnelle Datenverarbeitung und -analyse auch bei hoher Nachfrage.
- Gleichzeitigkeit: Die Plattform sollte Serverless Compute und KI-gesteuerte Optimierungen nutzen, um eine gleichzeitige Datenverarbeitung und Abfrageausführung zu ermöglichen. Somit wird sichergestellt, dass viele Benutzer und Teams gleichzeitig Analyseaufgaben ohne Leistungseinschränkungen durchführen können.
- Speicher: Die Plattform sollte sich nahtlos in Data Lakes integrieren lassen, um eine kostengünstige Speicherung umfangreicher Datenmengen zu ermöglichen und gleichzeitig die Verfügbarkeit und Zuverlässigkeit der Daten zu gewährleisten. Auch sollte sich die Datenspeicherung für eine bessere Leistung optimieren lassen, um die Speicherkosten zu senken.
Skalierbarkeit ist zwar unerlässlich, wird aber durch Leistung ergänzt. Die Plattform sollte eine Vielzahl KI-gesteuerter Anpassungen nutzen, um die Leistung zu optimieren:
- Abfrageoptimierung: Die Plattform sollte Machine-Learning-Optimierungstechniken verwenden, um die Abfrageausführung zu beschleunigen. Mithilfe von automatischer Indexierung, Caching und Predicate Pushdown wird sichergestellt, dass Abfragen effizient verarbeitet werden und der Erkenntnisgewinn beschleunigt wird.
- Automatische Skalierung: Die Plattform sollte Serverless-Ressourcen intelligent skalieren können, um sie an Ihre Workloads anzupassen. Dabei ist sicherzustellen, dass Sie nur für tatsächlich genutzte Rechenleistung zahlen, während gleichzeitig eine optimale Abfrageleistung gewährleistet bleibt.
- Schnelle Abfrageleistung: Die Plattform sollte kostengünstig eine extrem schnelle Abfrageleistung (Dateneingabe, ETL, Streaming, Data Science und interaktive Abfragen) direkt in Ihrem Data Lake bieten.
- Delta Lake: Die Plattform sollte KI-Modelle nutzen, um verbreitete Probleme bei der Datenspeicherung zu lösen. Dadurch erhalten Sie eine höhere Leistung, ohne Tabellen manuell verwalten zu müssen – und zwar auch dann, wenn es dort im Laufe der Zeit zu Änderungen kommt.
- Predictive Optimization: Hiermit werden Ihre Daten automatisch für das bestmögliche Preis-Leistungs-Verhältnis optimiert. Die Funktion lernt aus Ihren Datennutzungsmustern, erstellt einen Plan für die passenden Verbesserungen und führt diese dann auf einer hyperoptimierten serverlosen Infrastruktur aus.
Herausforderungen bei herkömmlichen Data Warehouses
Bei traditionellen Warehouses kommen weitere Herausforderungen hinzu:
- Nur eingeschränkte oder gar keine Unterstützung unstrukturierter Daten wie Bilder, Text, IoT-Daten oder Messaging-Frameworks wie HL7, JSON und XML. Herkömmliche Data Warehouses können nur saubere und in hohem Maße strukturierte Daten speichern. Nach Einschätzung des US-Marktforschungsunternehmens Gartner handelt es sich jedoch bei bis zu 80 % der Daten eines Unternehmens um unstrukturierte Daten. Unternehmen, die ihre unstrukturierten Daten nutzen möchten, um die Vorteile von KI für sich zu erschließen, stehen vor der Herausforderung, andere Lösungen zu finden.
- Keine Unterstützung von KI und Machine Learning: Data Warehouses wurden speziell für gängige Data-Warehouse-Workloads wie Verlaufsberichte, BI und Abfragen entwickelt und optimiert. Sie wurden jedoch nicht dafür konzipiert, Workloads für Machine Learning zu unterstützen.
- Reine SQL-Lösung: Data Warehouses bieten in der Regel keine Unterstützung für Python oder R, die bevorzugten Sprachen von App-Entwicklern, Data Scientists und Machine Learning Engineers.
- Duplizierte Daten: Zahlreiche Unternehmen verfügen neben einem Data Lake auch über Data Warehouses und themenspezifische (oder abteilungsspezifische) Data Marts. Dies führt zu duplizierten Daten, einer Fülle von redundantem ETL und dem Fehlen einer Single Source of Truth.
- Schwer zu synchronisieren: Zwei Kopien der Daten zwischen dem Lake und dem Warehouse zu synchronisieren, geht mit einer zusätzlichen Komplexität und Fragilität einher, die schwer zu verwalten ist. Datenabweichungen können zu inkonsistenten Berichten und fehlerhaften Analysen führen.
- Geschlossene, proprietäre Formate erhöhen die Anbieterbindung: Die meisten Data Warehouses von Unternehmen verwenden ihr eigenes, proprietäres Datenformat anstelle von Formaten, die auf Open Source und offenen Standards basieren. Dies erhöht die Herstellerbindung und macht es schwierig oder gar unmöglich, Ihre Daten mit anderen Tools zu analysieren. Auch die Migration Ihrer Daten wird dadurch erschwert.
- Kostenintensiv: Kommerzielle Data Warehouses berechnen Ihnen die Kosten für die Speicherung Ihrer Daten sowie für deren Analyse. Somit sind die Kosten für Speicherung und Compute nach wie vor eng gekoppelt. Die Entkopplung von Compute und Speicherplatz in einem Lakehouse bedeutet, dass Sie beide Bereiche je nach Bedarf und unabhängig voneinander skalieren können.
- Separate Berichtslösungen: Häufig müssen Sie nur einfache Fragen zu Ihren Daten stellen, für die die umfassenden Funktionen einer separaten Berichterstattungslösung gar nicht benötigt werden, wie z. B.: „Wie hoch ist der Umsatz im dritten Quartal?“
- Festlegung auf Tabellenformate: Sie benötigen geschäftsbereichs- und anwendungsfallübergreifende Flexibilität, aber Data Warehouses binden Sie oft an ein bestimmtes Tabellenformat (z. B. Apache Iceberg).
Proprietäre Tabellenformate
Das Tabellenformat ist die primäre Technologie, die die Vorteile von Data Warehouses auf Data Lakes überträgt. Tabellenformate organisieren Daten und Metadaten so, dass sie den Zustand einer Tabelle im zeitlichen Verlauf darstellen.
Proprietäre Tabellenformate werden in der Regel in Cloud-Umgebungen verwendet, in denen ein effizienter Zugriff auf große Datasets für Aufgaben wie Analysen, Berichterstellung und maschinelles Lernen von entscheidender Bedeutung ist. Bestimmte Anbieter erstellen Dateiformate oder -strukturen, um spezielle Probleme zu lösen, wie z. B. eine Reduzierung der Speichergröße, eine Beschleunigung von Lese- und/oder Schreibvorgängen oder das Hinzufügen einer Versionskontrolle.
Bei Delta Lake, dem proprietären Format von Databricks, handelt es sich um eine Datenmanagement- und Governance-Schicht mit einem offenen Open-Source-Format, die das Beste aus Data Lakes und Data Warehouses kombiniert. Zu den wichtigsten Merkmalen gehören:
- ACID-Transaktionen: Delta Lake sorgt für konsistente Daten, selbst bei gleichzeitigen Vorgängen wie Aktualisierungen, Löschungen und Einfügungen. So wird sichergestellt, dass Ihre Daten immer aktuell und konsistent sind.
- Skalierbare Metadaten: Mit wachsenden Datasets wächst auch Delta Lake mit und ermöglicht es Benutzern, Metadaten in Tabellen zu speichern. So lassen sich Änderungen an Daten leichter nachverfolgen und teilen.
- Schemaerzwingung: Delta Lake sorgt dafür, dass alle Ihre Daten in einem festgelegten Format in einer Tabelle gespeichert werden.
- Kompatibilität mit Apache Spark™: Da Delta Lake quelloffen ist, ist es mit Apache Spark-APIs kompatibel. Sie können Delta Lake in Ihren bestehenden Spark-Anwendungen nutzen, ohne Ihren Code anpassen zu müssen.
Wenn Sie sich nicht auf das Open Table Format (OTF) festlegen oder sich nicht zwischen Delta Lake und Apache Iceberg entscheiden müssen möchten, können Sie ein universelles Format wie Delta Lake UniForm verwenden.
Multi-Cloud
Vielleicht hat Ihre Organisation Daten auf zwei oder mehr Cloud-Anbieter verteilt, um Kosten zu optimieren oder den speziellen Anforderungen Ihres Datasets gerecht zu werden. Dies kann zu Problemen führen, falls Daten in verschiedenen Netzwerken und mit unterschiedlichen Datenspeicherschemata verwaltet werden.
Eine moderne Lakehouse-Architektur ist nicht auf ein einzelnes Cloud-System festgelegt und kann Daten daher anbieterübergreifend verwalten. Dies ermöglicht Ihrer Organisation Folgendes:
- Daten verteilen: Wenn Ihre Daten auf verschiedene Cloud-Plattformen verteilt sind, kann Ihr Unternehmen die Dienste so kombinieren, dass sie optimal zu Ihrem Budget oder Ihren Compliance-Anforderungen passen.
- Resilienz stärken: Multi-Cloud-Umgebungen verbessern die Datenverfügbarkeit, indem sie Workloads und Sicherungen auf mehrere Anbieter verteilen. Dies kann sich als entscheidend erweisen, wenn es bei einem Cloud-Dienst zu einem Problem oder zu unerwarteten Ausfallzeiten kommt.
- Datenintegration: Ein Data Warehouse, das Multi-Cloud-Konfigurationen unterstützt, kann auch Daten aus diesen Quellen in Echtzeit integrieren und Ihnen so Zugang zu hochwertigen Daten und fundierten Entscheidungen bieten.
- Compliance: Eine Multi-Cloud-Architektur kann Ihnen dabei helfen, bestimmte gesetzliche und behördliche Anforderungen zu erfüllen, die unter Umständen vorschreiben, wo Ihre Daten geografisch aufbewahrt werden müssen oder wie sie über mehrere Cloud-Dienste hinweg zu speichern sind.
Herausforderungen bei intelligenten Data Warehouses
Bei intelligenten Data Warehouses liegen die Herausforderungen anders:
- Dieser moderne Ansatz ist noch in der Entwicklung begriffen, weswegen Sie eine Organisation brauchen, die bereit ist, ihre Strategie stetig weiterzuentwickeln.
- KI-Richtlinien: Ihre Organisation sollte über Richtlinien festlegen, welche Personen und Systeme die KI-Funktionen in einem intelligenten Data Warehouse nutzen dürfen.
Welche Lösungen bietet Databricks für das Data Warehousing an?
Databricks bietet mit Databricks SQL ein intelligentes Data Warehouse an, das auf der offenen Data-Lakehouse-Architektur basiert. Databricks SQL ist Teil einer integrierten Plattform, der Data Intelligence Platform, die Machine Learning, Data Governance, Workflows und vieles mehr umfasst. Durch Verwendung einer offenen, einheitlichen Grundlage für alle Ihre Daten erhalten Sie ML/KI, Streaming, Orchestrierung, ETL und Echtzeitanalysen, Data Warehousing, einheitliche Sicherheit, Governance und Katalogisierung sowie eine vereinheitlichte Datenspeicherung und profitieren so von Zuverlässigkeit und gemeinsamer Datennutzung auf einer zentralen Plattform. Da die Databricks Data Intelligence Platform auf einer offenen Data-Lakehouse-Architektur beruht, können Sie außerdem alle Rohdaten – wie Protokolle, Texte, Audio-, Video- und Bilddateien – hier speichern.
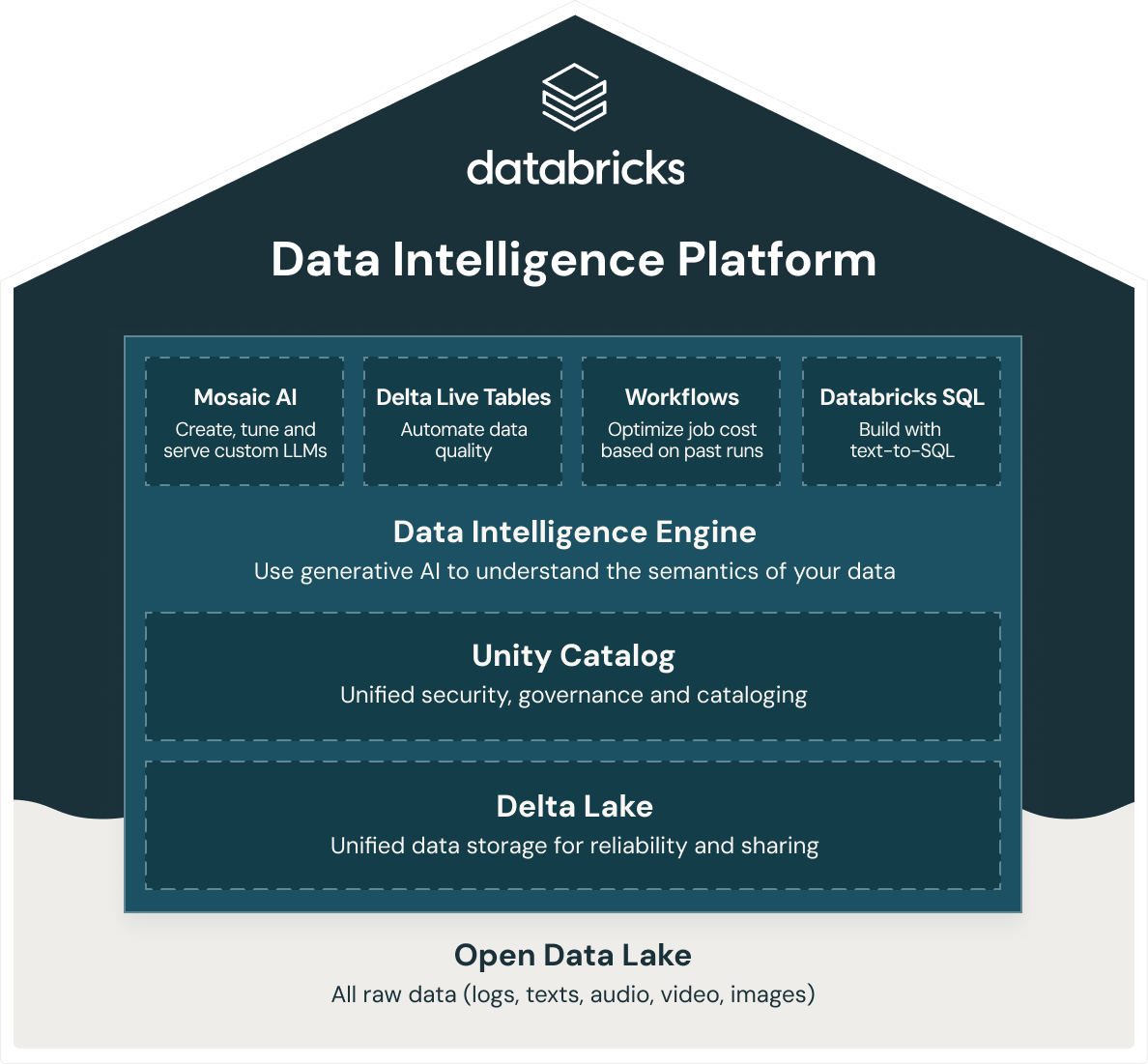
Unternehmen, die ein erfolgreiches Lakehouse aufbauen möchten, setzen auf Delta Lake. Dabei handelt es sich um eine Datenmanagement- und Governance-Schicht mit einem offenen Open-Source-Format, die das Beste aus Data Lakes und Data Warehouses kombiniert. Die Databricks Data Intelligence Platform nutzt Delta Lake, um Ihnen folgende Vorteile zu bieten:
- Rekordverdächtige Data-Warehouse-Performance zu kostengünstigen Data-Lake-Konditionen
- Serverless SQL Compute, das eine Infrastrukturverwaltung überflüssig macht
- Nahtlose Integration mit modernen Data Stacks, wie dbt, Tableau, Power BI und Fivetran, um Daten direkt aufzunehmen, abzufragen und zu transformieren
- Erstklassige SQL-Entwicklung für Datenexperten in Ihrem Unternehmen dank ANSI-SQL-Unterstützung
- Präzise Verwaltung mit Datenherkunft, Tags auf Tabellen-/Zeilenebene, rollenbasierter Zugriffssteuerung und mehr
- KI-gestützte Data Intelligence Engine, mit der Sie die Semantik Ihrer Daten verstehen