Was ist Spark Streaming?
Wie Spark Streaming Mikro-Batches von Echtzeitdaten mit DStreams verarbeitet und warum Structured Streaming mittlerweile die bevorzugte Engine ist

Summary
- Erfahren Sie, was Apache Spark Streaming ist, wie es die Spark-Kern-API erweitert und warum es im Vergleich zu Structured Streaming mittlerweile als ältere Streaming-Engine gilt.
- Sehen Sie, wie Spark Streaming Daten aus Quellen wie Kafka, Flume und Amazon Kinesis aufnimmt, sie in Mikro-Batches verarbeitet und die Ergebnisse mithilfe von DStreams in Dateien, Datenbanken oder Dashboards speichert.
- Entdecken Sie die wichtigsten Vorteile von Spark Streaming, wie die einheitliche Batch- und Streaming-Verarbeitung, Fehlertoleranz und die Integration mit MLlib und Spark SQL.
Apache Spark Streaming ist die Vorgängergeneration der Streaming-Engine von Apache Spark. Es gibt keine Updates mehr für Spark Streaming und es ist ein Auslaufprojekt. Es gibt eine neuere und einfacher zu verwendende Streaming-Engine in Apache Spark, die Structured Streaming heißt. Sie sollten Spark Structured Streaming für Ihre Streaming-Anwendungen und -Pipelines verwenden. Weitere Informationen finden Sie unter Structured Streaming.
Was ist Spark Streaming?
Apache Spark Streaming ist ein skalierbares, fehlertolerantes Streaming-Verarbeitungssystem, das nativ sowohl Batch- als auch Streaming-Workloads unterstützt. Es handelt sich hierbei um eine Erweiterung der Spark-Kern-API, die es Data Engineers und Data Scientists erlaubt, Echtzeitdaten aus verschiedenen Quellen – insbesondere Kafka, Flume und Amazon Kinesis – zu verarbeiten. Diese verarbeiteten Daten können dann an Dateisysteme, Datenbanken und Live-Dashboards übergeben werden. Seine wichtigste Abstraktion ist ein Discretized Stream – kurz „DStream“ –, der einen in kleinere Batches unterteilten Datenstrom darstellt. DStreams setzen auf RDDs auf, der zentralen Datenabstraktion von Spark. Dadurch lässt sich Spark Streaming nahtlos mit anderen Spark-Komponenten wie MLlib und Spark SQL integrieren. Spark Streaming unterscheidet sich von anderen Systemen, die entweder über eine nur für Streaming konzipierte Verarbeitungs-Engine oder aber über ähnliche Batch- und Streaming-APIs verfügen, die jedoch intern zu anderen Engines kompiliert werden. Die zentrale Ausführungs-Engine von Spark und das einheitliche Programmiermodell für Batch und Streaming bieten einige besondere Vorteile gegenüber anderen herkömmlichen Streaming-Systemen.
Gartner®: Databricks als Leader für Cloud-Datenbanken

Vier Hauptaspekte von Spark Streaming
- Schnelle Wiederherstellung nach Ausfällen und bei Nachzüglern
- Besserer Lastausgleich und effizientere Ressourcennutzung
- Kombinieren von Streaming-Daten mit statischen Datasets und interaktiven Abfragen
- Native Integration mit fortschrittlichen Verarbeitungsbibliotheken (SQL, maschinelles Lernen, Graphverarbeitung)
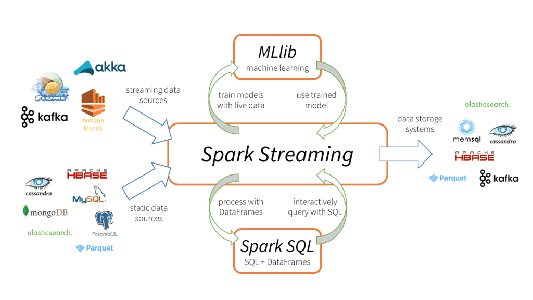
Diese Vereinheitlichung unterschiedlicher Datenbearbeitungsverfahren ist der entscheidende Grund für die schnelle Akzeptanz von Spark Streaming. Für Entwickler ist es damit sehr einfach, ein zentrales Framework zu verwenden, das alle ihre Verarbeitungsanforderungen erfüllt.