Zuverlässige Datenpipelines leicht gemacht
Vereinfachen Sie Batch- und Streaming-ETL mit automatisierter Zuverlässigkeit und integrierter D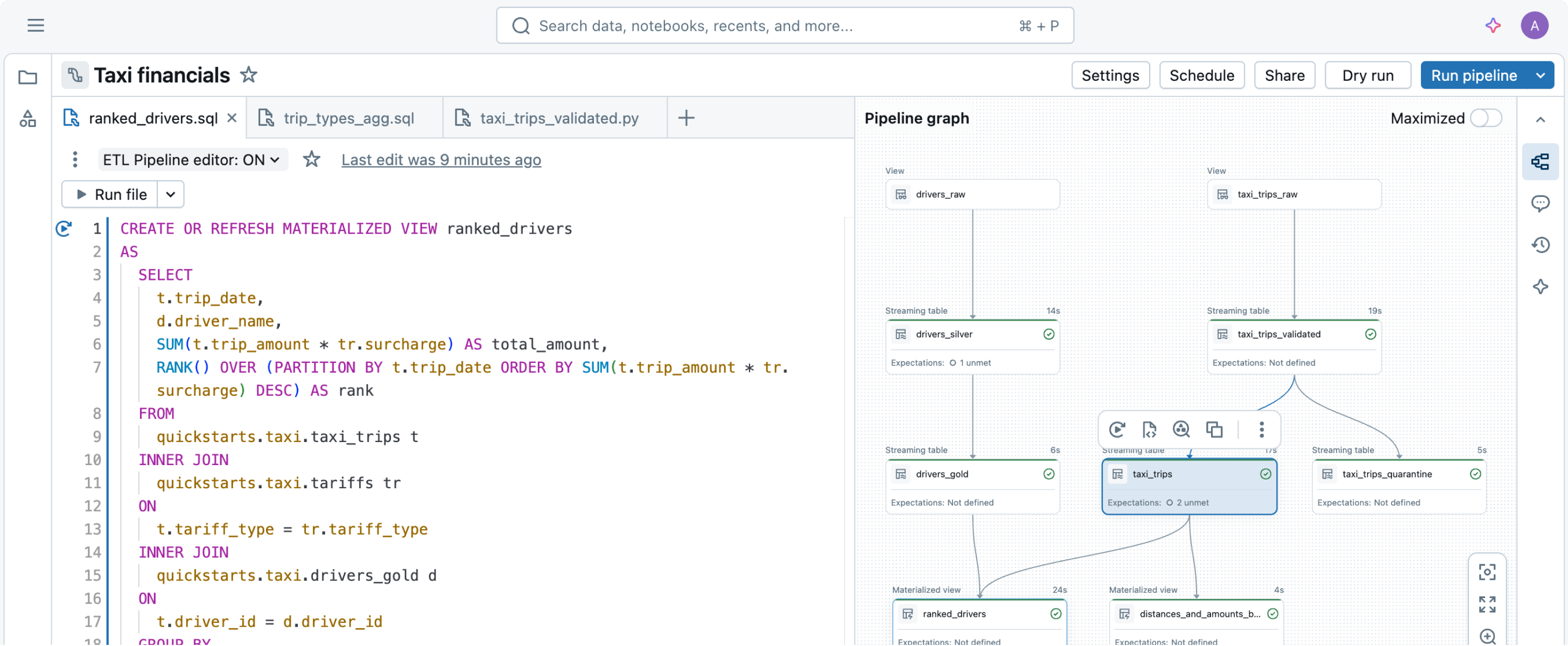
SPITZENTEAMS SETZEN AUF INTELLIGENTE DATENPIPELINES
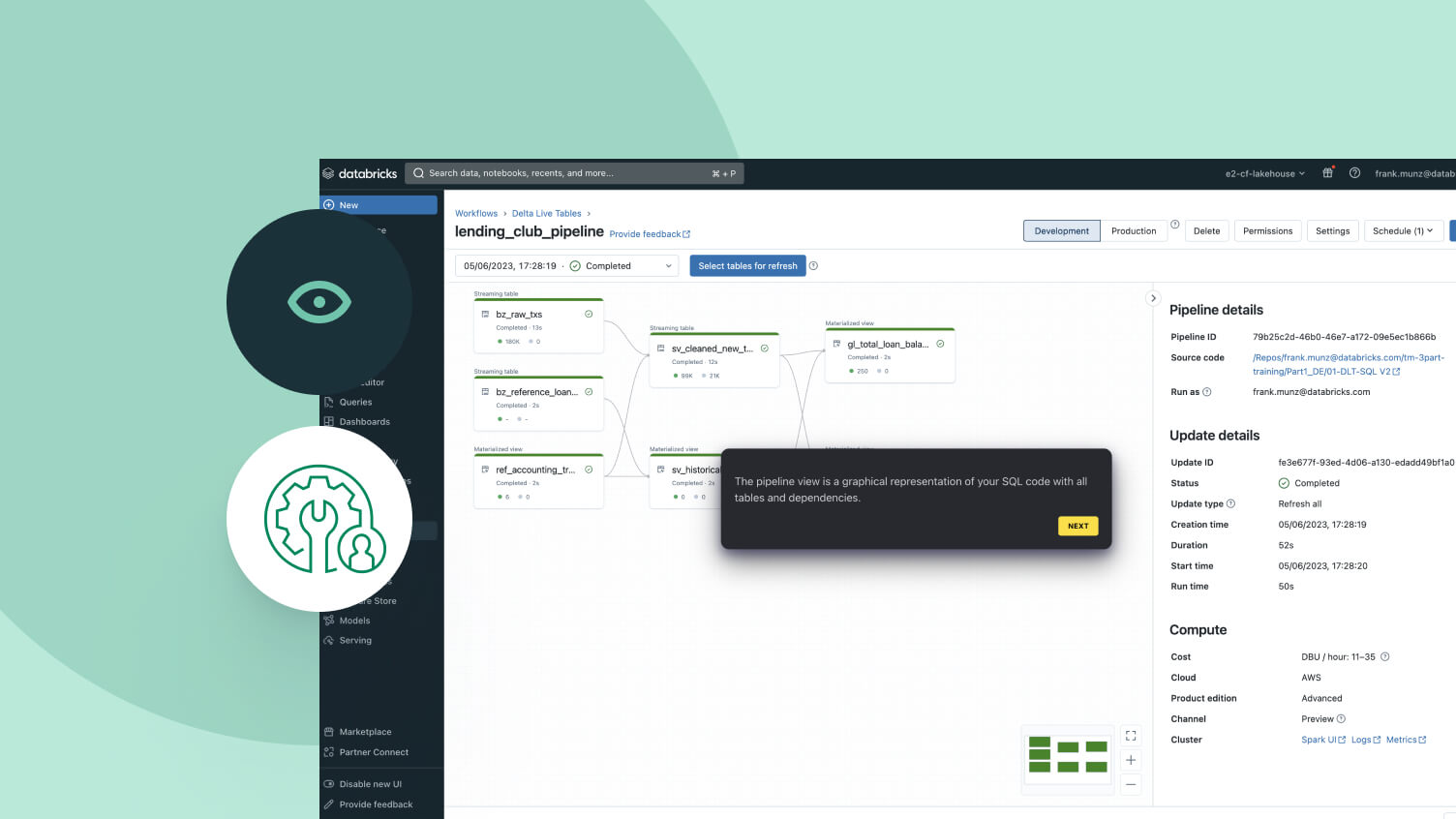
Festgeschriebene Best Practices für Datenpipelines
Definieren Sie einfach die gewünschten Datentransformationen – Spark Declarative Pipelines kümmert sich um den Rest.Effiziente Datenaufnahme
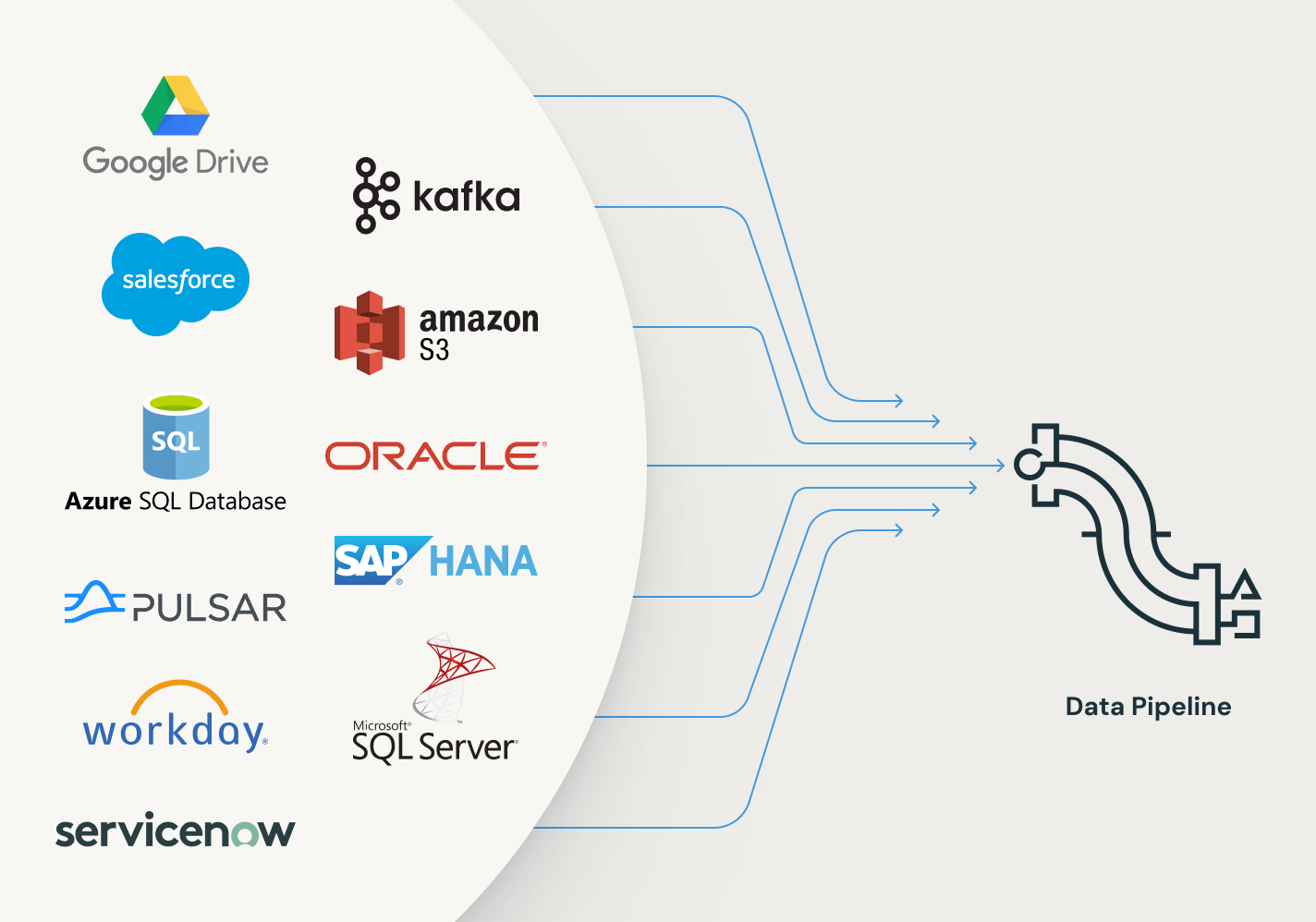
Der Aufbau produktionsbereiter ETL-Pipelines beginnt mit der Datenaufnahme. Spark Declarative Pipelines ermöglicht eine effiziente Datenaufnahme für Data Engineers, Python-Entwickler, Data Scientists und SQL-Analysten. Laden Sie Daten von jeder von Apache Spark™ unterstützten Quelle in Databricks – ganz gleich, ob Batch, Streaming oder CDC.
Intelligente Transformation
Aus nur wenigen Codezeilen ermittelt Spark Declarative Pipelines die effizienteste Methode zum Erstellen und Ausführen Ihrer Batch- oder Streaming-Datenpipelines und nimmt dabei automatisch Optimierungen für Kostenersparnis oder Performance vor – bei gleichzeitiger Minimierung der Komplexität.
Automatisierter Betrieb
Spark Declarative Pipelines vereinfacht die ETL-Entwicklung, indem sie Best Practices vom ersten Moment an implementieren und die übliche betriebliche Komplexität durch Automatisierung beseitigen. Mit Spark Declarative Pipelines können sich Engineers auf die Bereitstellung hochwertiger Daten konzentrieren, statt eine Pipeline-Infrastruktur zu betreiben und zu verwalten.
Für die einfachere Erstellung von Datenpipelines entwickelt
Das Erstellen und Betreiben von Datenpipelines kann komplex sein, muss es aber nicht. Spark Declarative Pipelines kombiniert Performance mit Einfachheit. So können Sie robustes ETL mit nur wenigen Codezeilen umsetzen.Durch die Nutzung der vereinheitlichten API von Spark für die Batch- und Stream-Verarbeitung ermöglichen Spark Declarative Pipelines das einfache Umschalten zwischen den Verarbeitungsmodi.

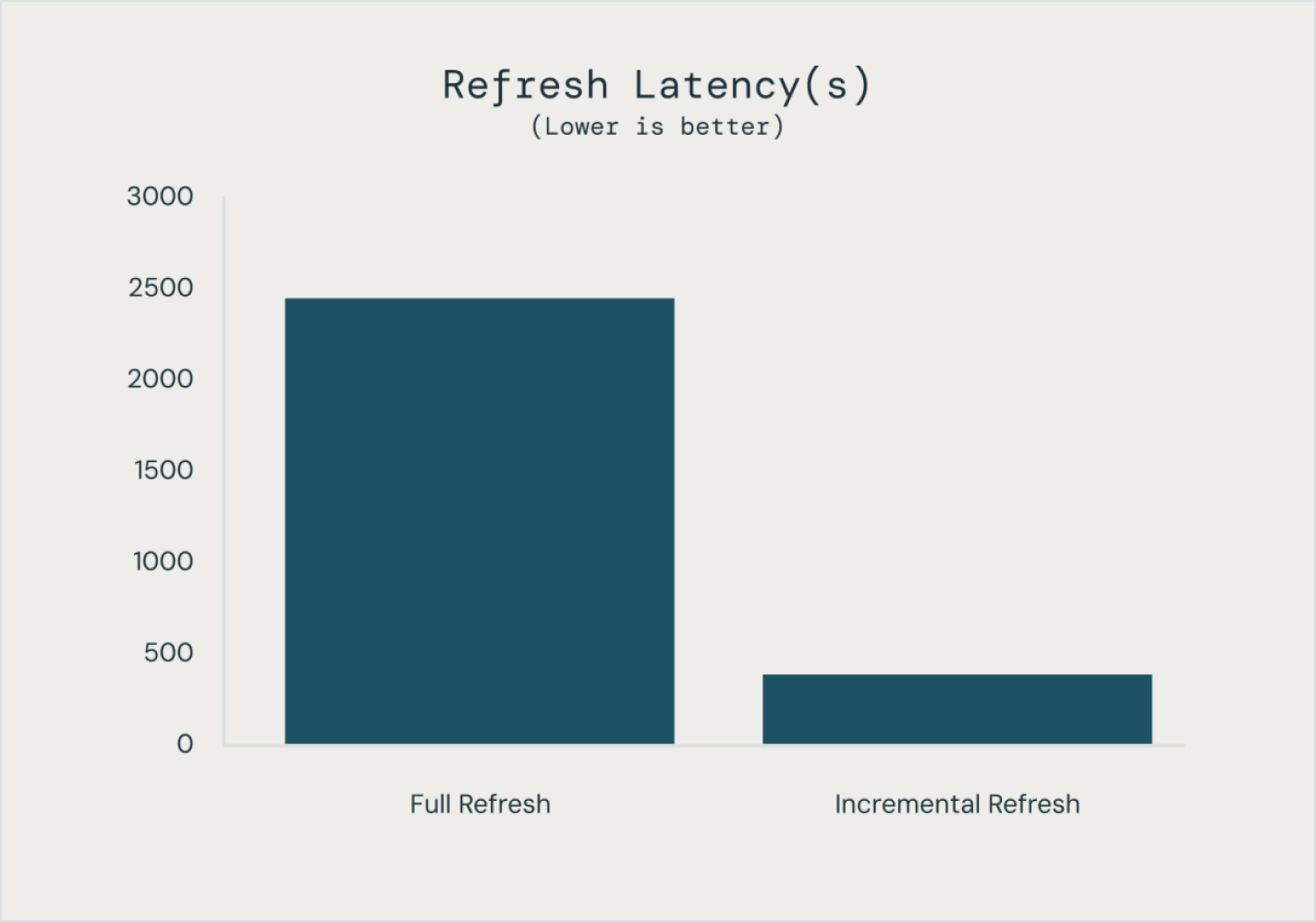
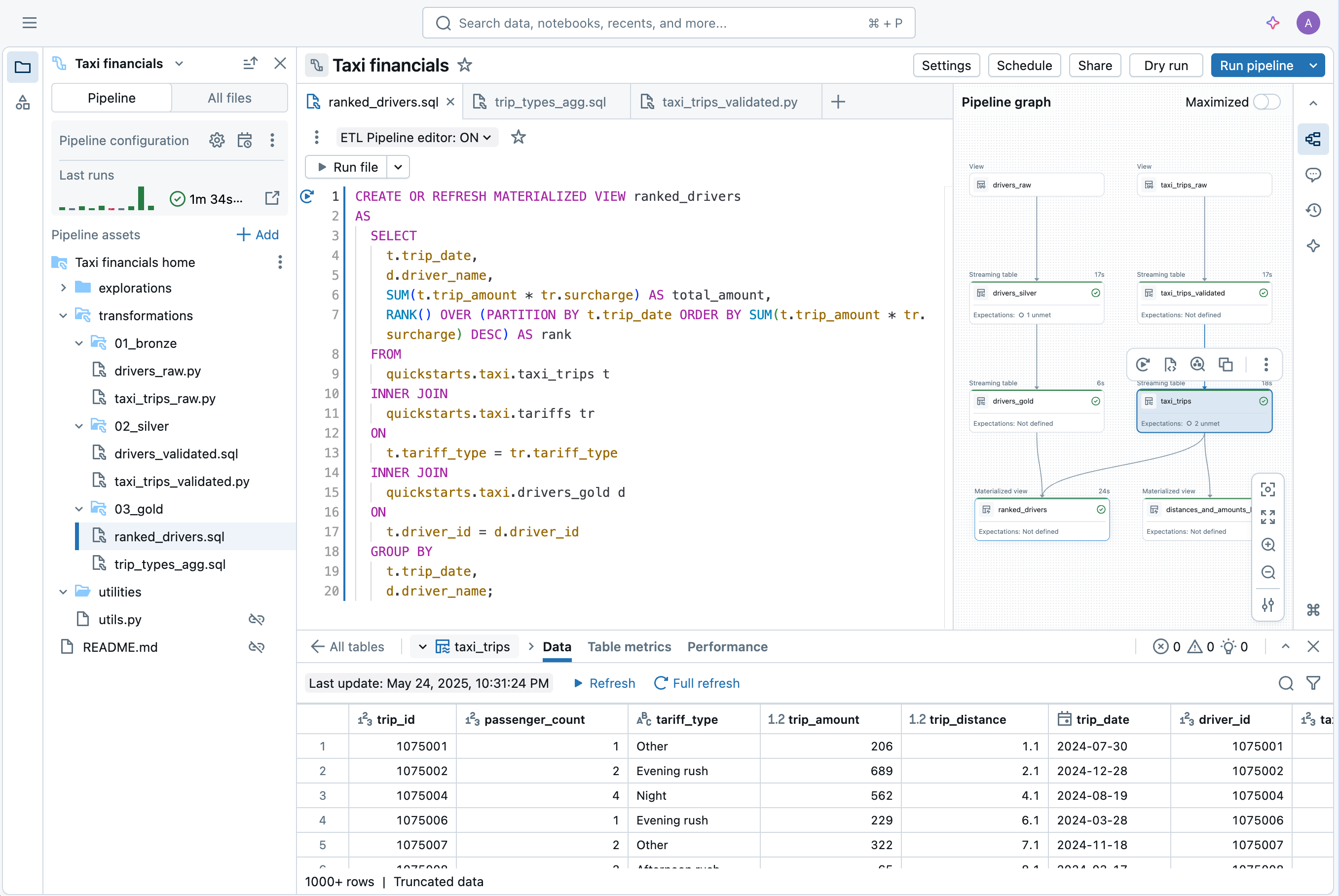
Weitere Funktionen
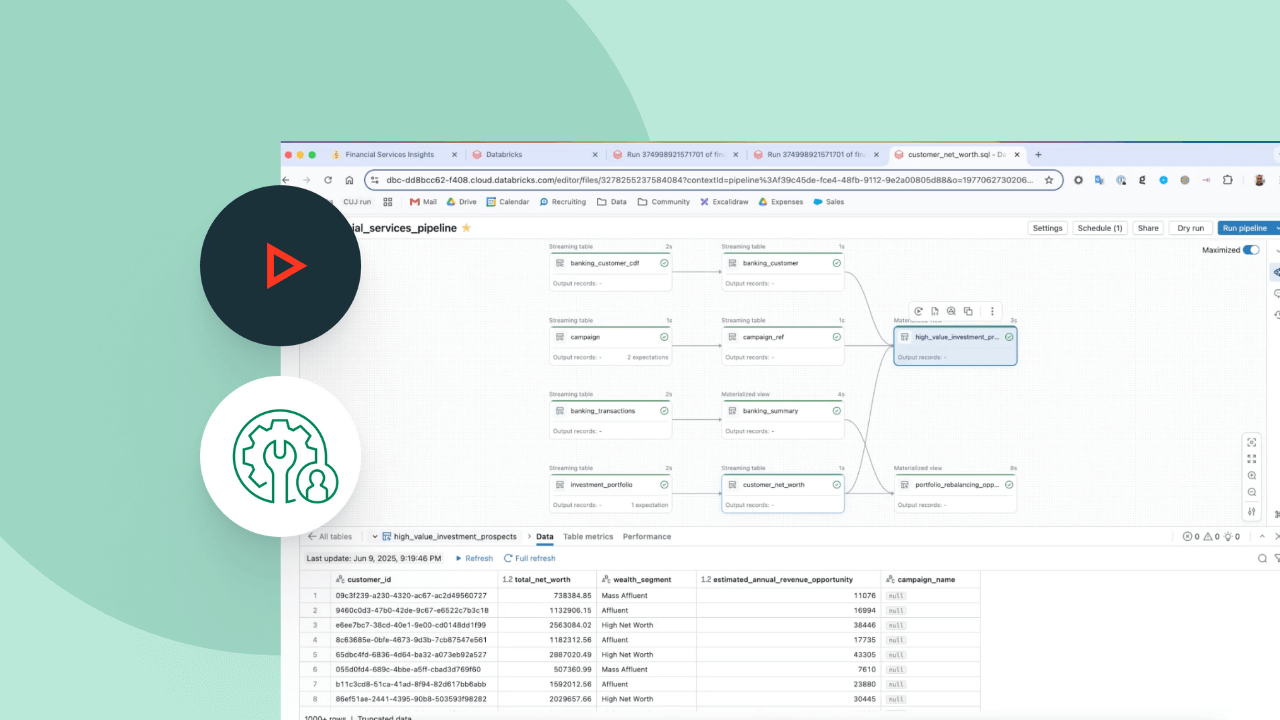
Datenpipelines rationalisieren

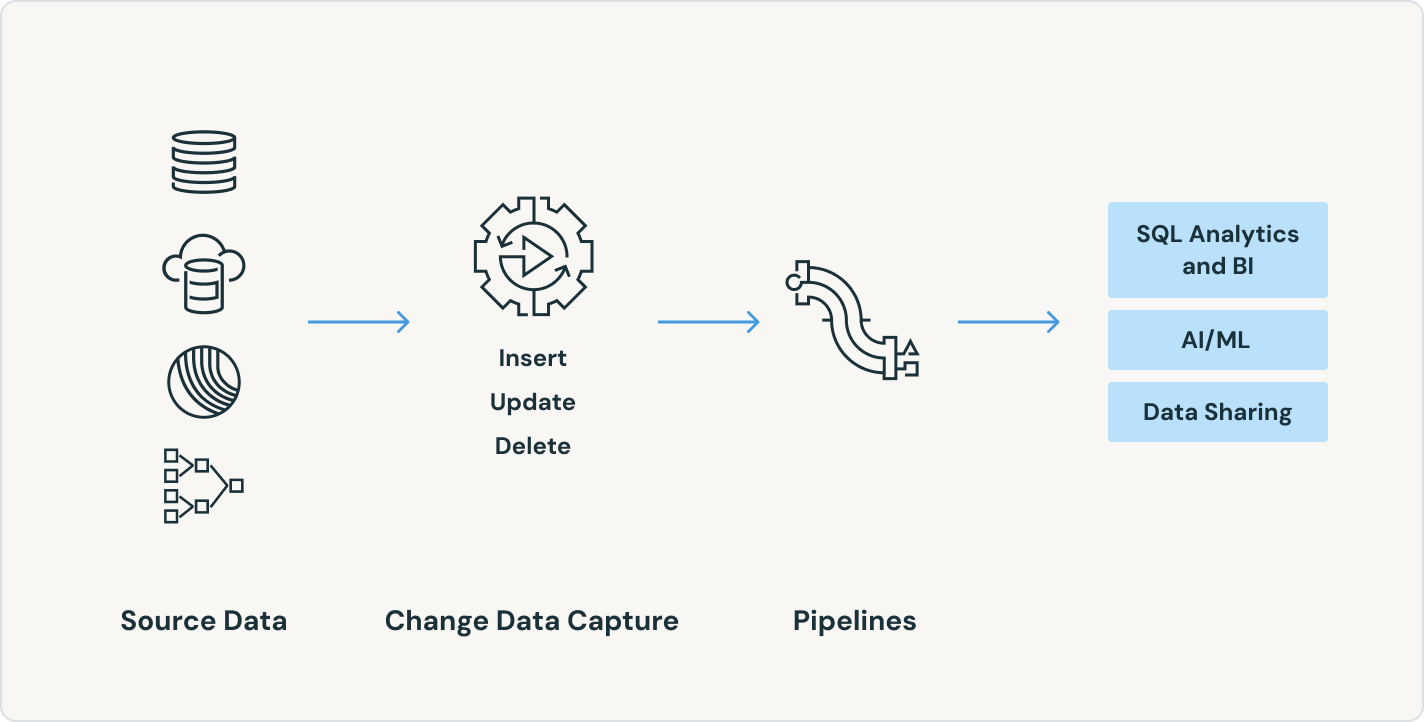
Datenintegrität und Datenkonsistenz bequem sicherstellen
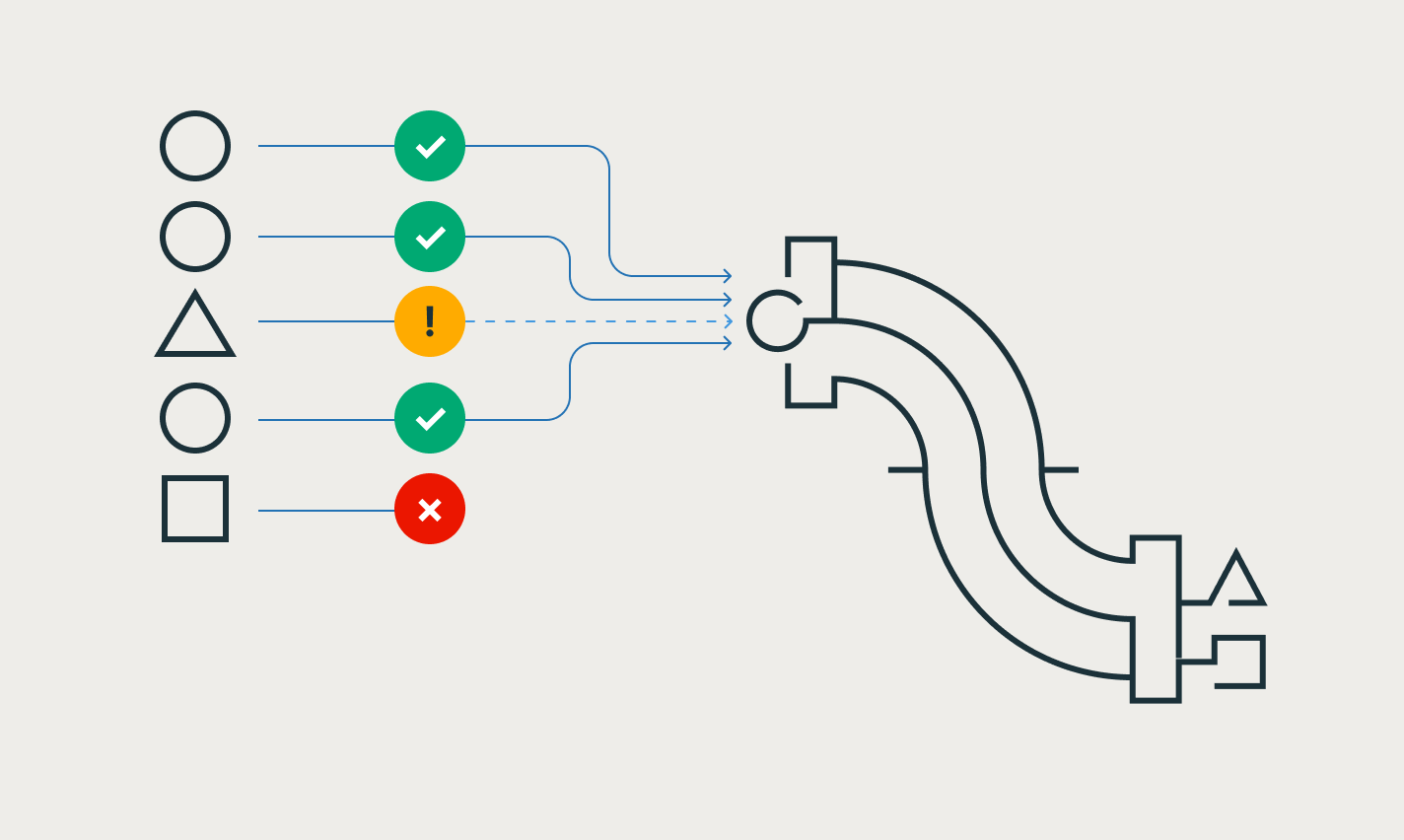
Machen Sie Change Data Capture leichter – mit den APPLY CHANGES-APIs für Change Data Feeds und Datenbank-Snapshots. Spark Declarative Pipelines verarbeitet automatisch außerhalb der Sequenz liegende Datensätze für SCD Typ 1 und 2, was die schwierigsten Teile von CDC vereinfacht.
Leistungsstarke Echtzeit-Anwendungsfälle ohne zusätzliche Tools erschließen
Erstellen und betreiben Sie Batch- wie auch Streaming-Pipelines an zentraler Stelle mit steuerbaren und automatisierten Aktualisierungseinstellungen, um Zeit zu sparen und die betriebliche Komplexität zu verringern. Operationalisieren Sie Streaming-Daten, um Genauigkeit und Umsetzbarkeit Ihrer Analytics und KI direkt zu verbessern.
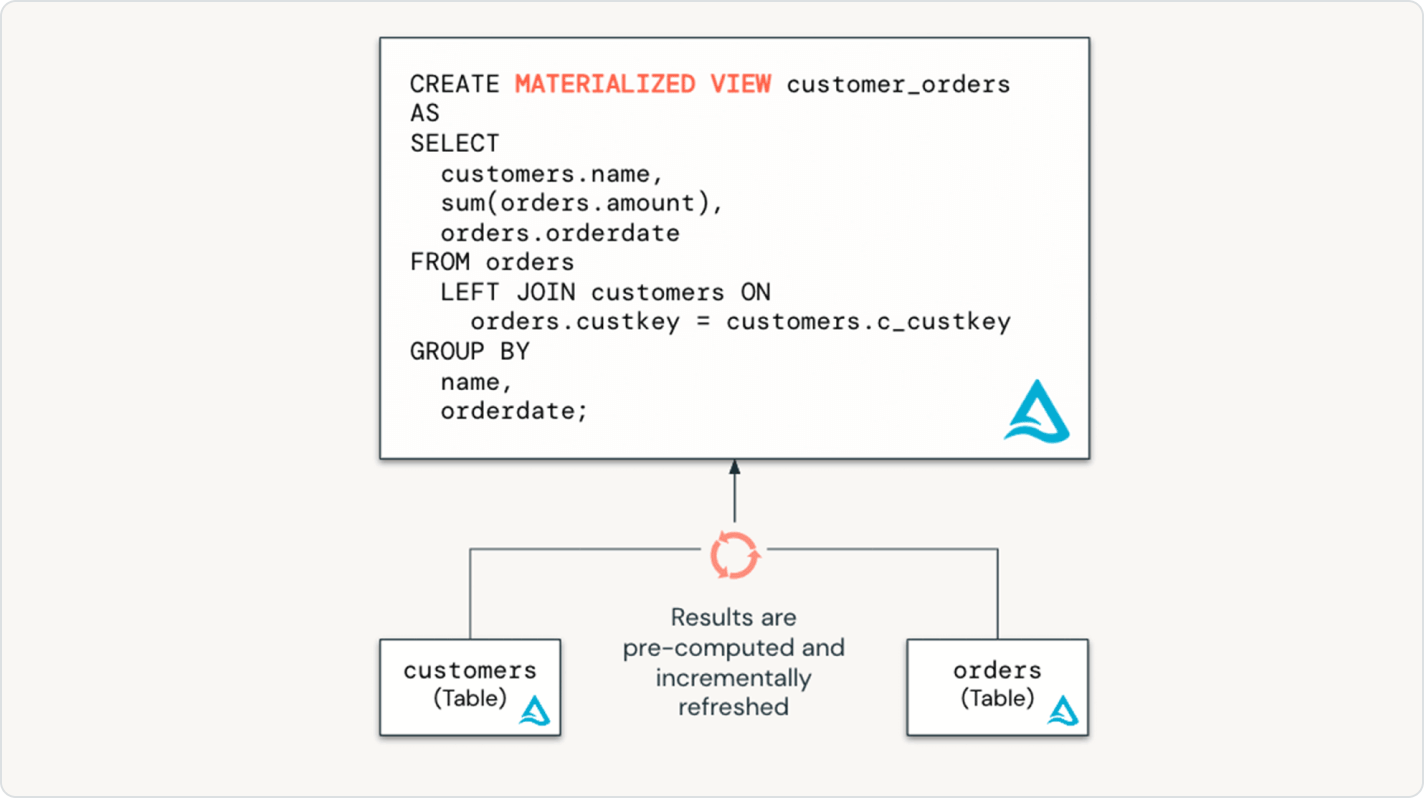
Nahtlose Übernahme von Best Practices aus dem Data Engineering in die Welt des Data Warehousing
Mit Lakeflow Deklarativen Pipelines haben Data-Warehouse-Benutzer die volle Kraft des deklarativen ETL über eine zugängliche SQL-Schnittstelle. Unterstützen Sie Ihre SQL-Analysten mit infrastrukturfreien Low-Code-Datenpipelines, die neue Daten für das Unternehmen erschließen – mit einem Minimum an Einrichtung und Abhängigkeiten.
Ausgaben im Griff dank nutzungsbasierter Abrechnung
Sie zahlen nur für die Produkte, die Sie tatsächlich nutzen – und das sekundengenau.Mehr entdecken
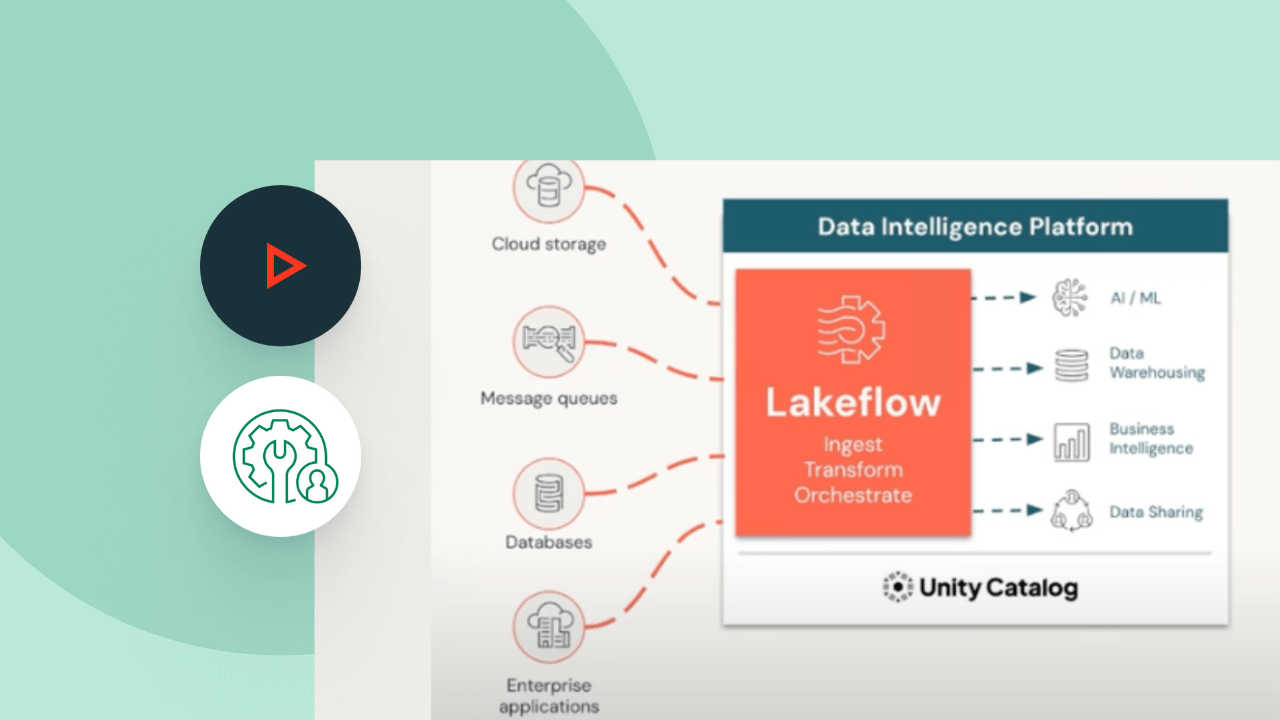
Entdecken Sie weitere integrierte, intelligente Angebote auf der Data Intelligence Platform.
LakeFlow Connect
Effiziente Konnektoren für die Datenaufnahme aus beliebigen Quellen und native Integration mit der Data Intelligence Platform erschließen einen einfachen Zugang zu Analytik und KI mit einheitlicher Governance.

Lakeflow Jobs
Sie können Workflows mit mehreren Tasks für ETL-, Analytics- und ML-Pipelines unkompliziert definieren, verwalten und überwachen. Mit einer breiten Palette unterstützter Task-Typen, umfassenden Beobachtbarkeitsfunktionen und hoher Zuverlässigkeit sind Ihre Datenteams in der Lage, jede Pipeline besser zu automatisieren und zu orchestrieren sowie produktiver zu werden.

Lakehouse-Speicherung
Vereinheitlichen Sie die Daten in Ihrem Lakehouse format- und typenübergreifend für alle Ihre Analytics- und KI-Workloads.

Unity Catalog
Regulieren Sie alle Ihre Datenressourcen nahtlos mit der branchenweit einzigen einheitlichen und offenen Governance-Lösung für Daten und KI, die in die Data Intelligence Platform von Databricks integriert ist.
Die Data Intelligence Platform
Erfahren Sie mehr darüber, wie die Databricks Data Intelligence Platform Ihre Daten- und KI-Workloads unterstützt.
Wagen Sie den nächsten Schritt
Ähnliche Inhalte




Spark Declarative Pipelines – FAQ
Möchten Sie ein Daten- und KI-Unternehmen werden?
Machen Sie die ersten Schritte Ihrer Transformation