PySpark で Pandas UDF を使用する
ネイティブな Python コードを PySpark ですばやく実行する方法

※ Spark 3.0 では、新しい Pandas UDF が導入されました。詳細はブログ「New Pandas UDFs and Python Type Hints in the Upcoming Release of Apache Spark 3.0」をご覧ください。
ニューヨークの Two Sigma Investments, LP のソフトウェアエンジニア、Li Jin 氏によるゲストコミュニティー投稿です。このブログは Two Sigma にも掲載されています。
このノートブックを Databricks でお試しいただけます。
更新:本ブログは、2018年 2月 22日に一部変更点を含む更新を行いました。
このブログでは、Python のユーザー定義関数(UDF)のパフォーマンスと使い勝手を大幅に向上させる、次期リリース Apache Spark 2.3 の Pandas UDF(別名:Vectorized UDF)機能について紹介します。
ここ数年、Python はデータサイエンティストにとってデフォルトの言語となりました。pandas、numpy、statsmodel、scikit-learn などのパッケージは、大きな支持を得て、主流のツールキットとなりました。同時に、 Apache Spark は、ビッグデータ処理におけるデファクトスタンダードとなりました。データサイエンティストがビッグデータの価値を活用できるように、Spark はバージョン0.7 で Python API を追加し、ユーザー定義関数をサポートするようになりました。このユーザー定義関数は 1 行ずつ処理するため、シリアライゼーションと呼び出しのオーバーヘッドが大きいという問題があります。そのため、多くのデータパイプラインでは、Java や Scala で UDF を定義し、Python から呼び出しています。
Apache Arrow 上に構築されたPandas UDF は、オーバーヘッドが少なく、高性能な UDF を完全に Python で定義可能で、両者の良いとこ取りを実現しています。
Spark 2.3 では、スカラーとグループ化されたマップの2種類の Pandas UDF が用意されています。次に、4 つのサンプルプログラムを使って、その使い方を説明します。プラスワン、累積確率、平均値の引き算、最小二乗法による線形回帰です。
スカラー Pandas UDF
スカラー Pandas UDF は、スカラー演算をベクトル化するために使用されま��す。スカラー Pandas UDF を定義するには、@pandas_udf を使って、pandas.Series を引数に取り、同じサイズの別の pandas.Series を返すPython関数をアノテーションすればよいのです。以下では、2つの例を使って説明します。プラスワンと累積確率です。
プラスワン
v + 1 の計算は、行単位で実行するUDFとスカラ Pandas UDF の違いを示す簡単な例です。このシナリオでは、組み込みの列演算子はより高速に実行できることに注意してください。
行単位で実行する UDF の使い方:
Pandas UDF を使用:
上記の例では、同じ「プラス1」計算を行う行単位 UDF "plus_one" とスカラー Pandas UDF "pandas_plus_one" を定義しています。UDF の定義は、関数デコレータを除いて同じです。"udf" と "pandas_udf " です。
row-at-a-time バージョンでは、ユーザー定義関数はdouble "v" を受け取り、"v + 1" の結果を double として返します。Pandas 版では、ユーザ定義関数は pandas.Series "v " を受け取り、"v + 1 " の結果を pandas.Series として返します。v + 1 "は pandas.Series 上でベクトル化されるため、Pandas バージョンは行単位バージョンよりはるかに高速です。
スカラー pandas UDF を使用する場合、2つの重要な要件があることに注意してください。
- 入力と出力の系列は同じサイズでなければならない。
- 列がどのように複数の
pandas.Seriesに分割されるかは Spark の内部的なものなので、ユーザー定義関数の結果は分割とは無関係��でなければならない。
累積確率
この例では、スカラー Pandas UDF のより実用的な使い方として、scipy パッケージを使って、正規分布N(0,1) における値の累積確率を計算することを示します。
stats.norm.cdf はスカラー値と pandas.Series の両方で動作し、この例は row-at-a-time UDF でも同様に書くことができます。前の例と同様に、後の「性能比較」で示すように、Pandas 版の方がはるかに高速に実行されます。
グループ化されたマップ Pandas UDF
Python ユーザはデータ分析における分割-適用-結合のパターンにかなり慣れています。Grouped map Pandas UDF はこのシナリオのために設計されており、例えば「各日付に対して、この操作を適用する」というように、あるグループの全データに対して操作を行います。
グループ化されたマップ Pandas UDF は、まず Spark DataFrame を groupby 演算子で指定した条件に基づいてグループに分割し、各グループに対してユーザ定義関数(pandas.DataFrame -> pandas.DataFrame)を適用、結果を結合して新しい Spark DataFrame として返します。
グループ化されたマップ Pandas UDF はスカラー Pandas UDFと同じ関数装飾子 pandas.udf を使用しますが、いくつかの違いがあります。
- ユーザー定義関数の入力
- スカラー:
pandas.Series - グループ化されたマップ:
pandas.DataFrame
- スカラー:
- ユーザー定義関数の出力
- スカラー:
pandas.Series - グループ化されたマップ:
pandas.DataFrame
- スカラー:
- グループ化のセマンティクス
- スカラー:グループ化セマンティクスなし
- グループ化されたマップ: "groupby "節で定義
- 出力サイズ
- スカラー:入力サイズと同じ
- グループ化されたマップ:任意のサイズ
- 関数デコレータの戻り値の型
- スカラー: 返される
pandas.Seriesの型を指定する DataType - グループ化されたマップ:返される
pandas.DataFrameの各列名と型を指定する StructType
- スカラー: 返される
次に、グループ化マップ Pandas UDF のユースケースを説明するために、2つの例を見ていきましょう。
平均値の引き算
この例では、グループ化されたマップの Pandas UDF の簡単な使い方を示しています。
この例では、各グループの v の各値からvの平均値を引いています。グループ化のセマンティクスは「groupby」関数で定義されています。つまり、ユーザー定義関数への各入力 pandas.DataFrame は同じ「id」値を持っています。このユーザ定義関数の入力と出力のスキーマは同じなので、スキーマを指定するためにデコレータ pandas_udf に "df.schema" を渡しています。
Grouped map Pandas UDF は、ドライバー上でスタンドアローンの Python 関数として呼び出すこともできます。これはデバッグの際などに非常に便利です。
上記の例では、まず Spark DataFrame の小さなサブセットを pandas.DataFrame に変換し、それに対してスタンドアロン Python 関数として subtract_mean を実行します。関数のロジックを確認した後、データセット全体に対して Spark で UDF を呼び出すことができます。
普通最小二乗法による線形回帰
最後の例は、statsmodels を使用して各グループの OLS 線形回帰を実行する方法を示しています。各グループについて、統計モデル Y = bX + cに従って、X = (x1, x2) に対するベータ b = (b1, b2) を計算します。
この例は、グループ化されたマップの Pandas UDF が、任意の Python 関数(pandas.DataFrame -> pandas.DataFrame)で使用できることを示しています。返されたpandas.DataFrame は、入力と同じように異なる数の行と列を持つことができます。
ガートナー®: Databricks、クラウドデータベースのリーダー

性能比較
最後に、row-at-a-time UDFとPandas UDFの性能比較を示したいと思います。上記の例のうち 3つ(プラスワン、累積確率、減算平均)について、マイクロベンチマークを実行しました。
構成と方法論
Databricks コミュニティエディション上のシングルノードの Spark クラスタ上でベンチマークを実行しました。
構成の詳細です。
データ Int カラムと Double カラムを持つ 10M 行の DataFrame
クラスタ 6.0GBメモリ、0.88コア、1DBU
Databricks ランタイムバージョン:最新 RC 版(4.0、Scala 2.11)
ベンチマークの詳細な実装は、Pandas UDF Notebook をご覧ください。
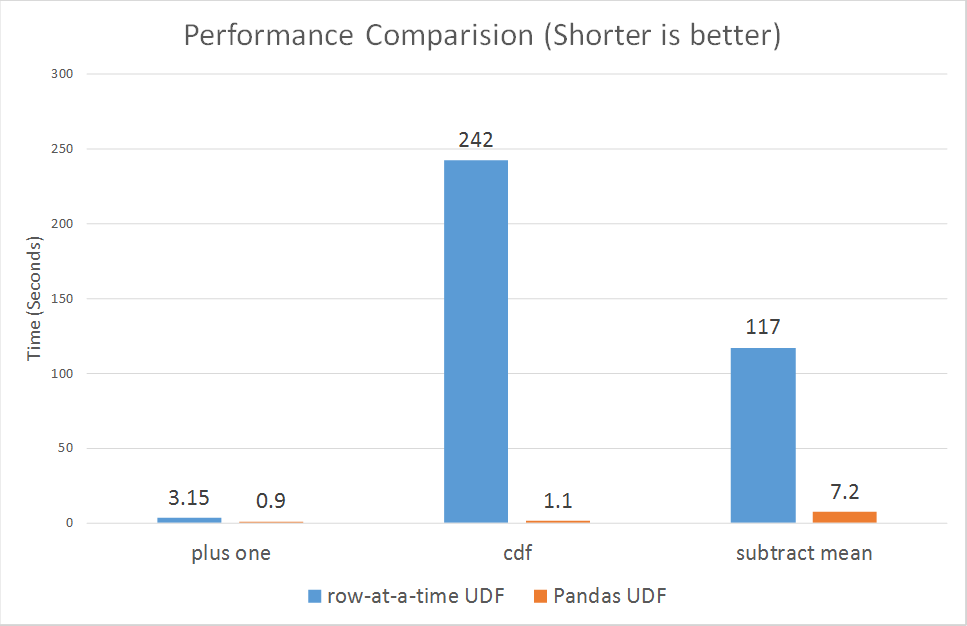
グラフに示すように、Pandas UDF は 3 倍から 100 倍以上と、軒並み row-at-a-time UDF よりはるかに優れた性能を発揮しています。
結論と今後の課題
次期 Spark 2.3リリースでは、Python のユーザー定義関数の機能と性能を大幅に向上させるための基盤が整備されます。将来的には、集計やウィンドウ関数におけるPandas UDF のサポートを導入する予定です。関連する作業は、SPARK-22216 で追跡可能です。
Pandas UDF は、Spark コミュニティの努力の賜物です。Bryan Cutler 氏、Hyukjin Kwon 氏、Jeff Reback 氏、Liang-Chi Hsieh 氏、Leif Walsh 氏、Li Jin 氏、Reynold Xin 氏、Takuya Ueshin 氏、Wenchen Fan 氏、Wes McKinney 氏、Xiao Li 氏、その他多くの方の貢献に感謝します。最後に、この作業を可能にしてくれた Apache Arrow コミュニティに特別な感謝を捧げます。
次のステップ
Pandas UDF Notebook を試すことができます。この機能は Databricks Runtime 4.0 ベータ版の一部として提供されています。