Delta Engine の概要
Delta Lake で従来型分析ワークロードの性能を最大化
によって Adam Conway(アダム・コンウェイ) 、 Joel Minnick による投稿
本日、Databricks は Delta Engine を発表しました。Delta Engine は、Apache Spark 完全互換のベクトル化クエリエンジンで、最新の CPU アーキテクチャに対応し、Databricks Runtime 7.0 に含まれている Spark 3.0 のクエリオプティマイザおよびキャッシング性能の最適化機能を連携させます。その相乗効果により、データレイク、特に Delta Lake で実現されたデータレイクでのクエリ性能が大幅に高速化され、レイクハウスアーキテクチャの採用やスケーリングが容易になります。
実行性能のスケーリング
ハードウェア業界ではここ数年、CPU クロック速度の向上が頭打ちになっています。その理由についてはこのブログでは触れませんが、重要なのは、CPU のパワーだけに頼らずに、データの高速処理を可能にする新たな方法が必要であるということです。その1つに、並列処理できるデータ量の改善が挙げられます。しかし、この並列処理を可能にするには、データ処理エンジンを特別に構築する必要があります。
また、ビジネスが目まぐるしく変化するなか、データのモデリングに十分な時間を割けない状況になっており、そのことがクエリ性能の低下を引き起こしています。これは望ましいことではなく、ビジネスの俊敏性とクエリ性能を同時に最大化する方法が求められています。
高性能クエリを可能にする Delta Engine の登場
Delta Engine は、改良版クエリオプティマイザ、実行レイヤ―とクラウドオブジェクトストレージの間に位置するキャッシングレイヤ―、C++ で記述されたネイティブのベクトル化実行エンジンの 3 つのコンポーネントにより、SQL および DataFrame ワークロードでの Delta Lake を高速化します。
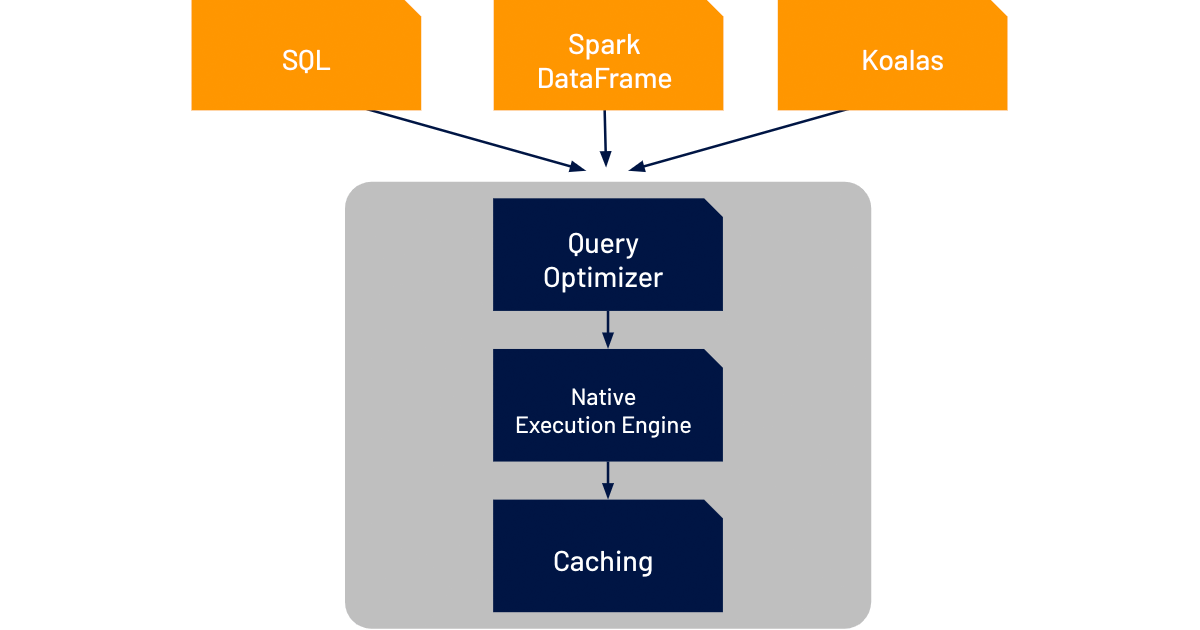
改良版クエリオプティマイザは、Spark 3.0 の機能(コストベースのオプティマイザ、アダプティブクエリ、動的なランタイムフィルタ)を拡張し、より高度な統計で、スタースキーマのワークロードを最大 18 倍まで高速化します。
Delta Engine のキャッシュレイヤ―は、キャッシュする入力データを自動的に選択し、より CPU 効率の高いフォーマットに変換して、NVMe SSD ストレージの高速性を活かし、あらゆるワークロードでスキャン性能を最大 5 倍高速化します。
また、データチームが抱える問題を解決するためのイノベーションとして、Delta Engine は、ネイティブな実行エンジン Photon を実装しました。Databricks 向けに完全に書き換えられた実行エンジンが、最新のクラウドハードウェアに対応してあらゆるタイプのワークロードの性能を改善し、同時にオープンな Spark API との完全な互換性を維持します。
今後、別のブログで Photon の仕組みや重要な機能をご紹介する予定です。
Delta Engine を使ってみる
前述の Delta Engine の 3 つのコンポーネント(クエリオプティマイザ、キャッシュレイヤ―、ネイティブ実行エンジン)のご紹介を通じて、Databricks 内部の複数の箇所における改善が、データレイクでの分析ワークロードの性能をいかに高速化するかをご理解いただけたのではないでしょうか。改良版クエリオプティマイザとキャッシングの改善機能はすぐにご利用可能です。また、Photon に関しても、近日中に皆様にご利用いただけるよう調整中です。
Delta Engine のメリットは、時間・工数・コストの削減に加えて、レイクハウスパターンにおいてデータチームの高度なデータアーキテクチャの設計をサポートし、統合性とシンプルさ向上させることです。ぜひご活用ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。