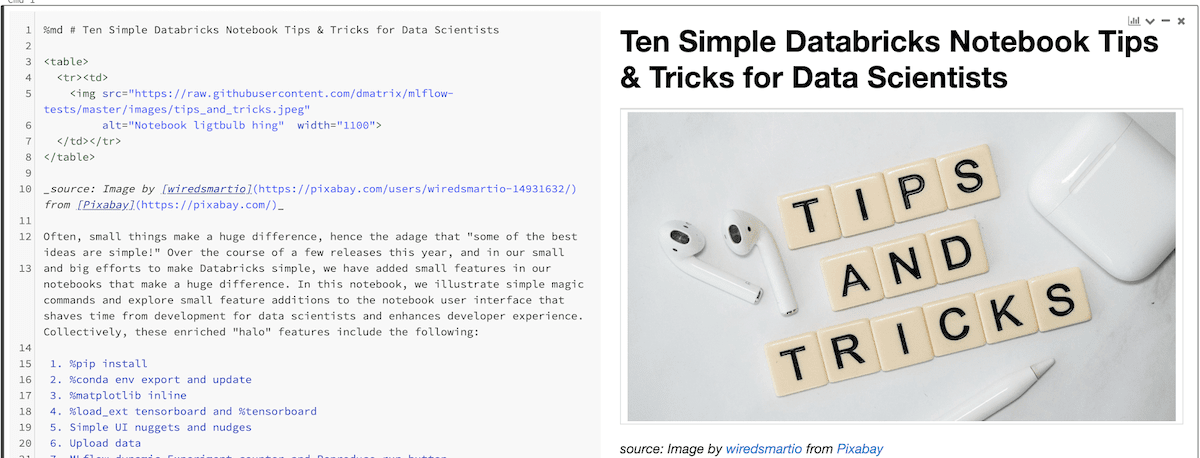
データサイエンティスト向け:Databricks Notebook を使いこなす 10 のヒント

「最高のアイディアにはシンプルなものがある」という格言があるように、たとえ小さくても大きな違いを生むことがあります。今年行った数回のリリースの過程で、Databricks をシンプルにするために、大きな違いにつながる小さな機能を Notebook に追加しました。
このブログと付随する Notebook では、簡単なマジックコマンドを紹介し、データサイエンティストの開発時間を短縮し、開発者のエクスペリエンスを向上させるために Notebook に追加したユーザーインターフェースの機能を解説します。
強化された機能には、次のものが含まれます。
- %pip install
- %conda env export および update
- %matplotlib inline
- %load_ext tensorboard および %tensorboard
- %run:外部ノートブックの実行でコードをモジュール化
- データのアップロード
- MLflow:Experiment の動的カウンター、および Reproduce Run ボタン
- UI に関するちょっとした機能
- SQL コードのフォーマット
- クラスタにログインするための Web ターミナル
ここでは簡潔に各機能の使い方をご紹介しますが、あわせて Notebook をダウンロードしていただくことをお勧めします。Databricks レイクハウスプラットフォーム(Databricks 統合分析プラットフォーム)をまだご利用いただいていない方は、こちらからお試しください。Databricks レイクハウスプラットフォームに Notebook をインポートして、実際に使ってみてください。
1. %pip マジックコマンド:Python パッケージのインストールと Python 環境の管理
Databricks ランタイム(DBR)または機械学習向け Databricks ランタイム(MLR)は、Python と一般的な機械学習(ML)ライブラリ一式をインストールします。しかし、実行したいタスクに応じた特定のライブラリやバージョンがあらかじめインストールされているとは限りません。そのため、%pip と %conda を使用して、クラスタ上の Python パッケージを簡単にカスタマイズして管理できます。
この機能がリリースされる以前は、データサイエンティストは精巧な init スクリプトを開発し、ローカルで wheel ファイルを構築し、それを DBFS(Databricks File System)にアップロードし、init スクリプトを実行してパッケージをインストールしなければなりませんでした。これは脆弱なプロセスです。現在は、プライベートまたはパブリックリポジトリから %pip install <package> を実行するだけです。
%pip install vaderSentiment
インストールするパッ�ケージが複数ある場合は、%pip install -r <path>/requirements.txt を実行できます。
pip と conda の両方を使用して Notebook スコープの Python 環境を管理する方法についてさらに理解を深めるには、こちらのブログをご覧ください。
2. %conda マジックコマンドと %pip マジックコマンド:Notebook 環境の共有
クラスタ用に環境がセットアップされたら、次の 2 つのことができます。
a)以降のセッションで再インストールできるようにファイルを保存する。
b)他のユーザーと保存したファイルを共有する。
クラスタは一時的なものなので、インストールされたパッケージはクラスタがシャットダウンされると消えてしまいます。そのため、インストールされているパッケージのリストを保存しておくとよいでしょう。再現性が向上し、データチームのメンバーが開発やテストのために環境を再現するのに役立ちます。今年リリースされた新機能の一部である %conda マジックコマンドのサポートにより、このタスクはよりシンプルになりました。インストールされた Python パッケージのリストをエクスポートして保存するだけです。
%conda env export -f /jsd_conda_env.yml or %pip freeze > /jsd_pip_env.txt
共通の共有場所またはパブリック DBFS から、別のデータサイエンティストが %conda env update -f <yaml_file_path> を実行することで、クラスタの Python パッケージ環境を簡単に再現できます。
3. %matplotlib inline マジックコマンド:画像をインラインで表示
探索的データ解析(EDA)プロセスの一環として、データの可視化は最も重要なステップです。最初のデータクレンジングのあとや、特徴量エンジニアリングとモデルのトレーニングの前に、パターンや関係を見出すために視覚的に検証することができます。
数あるデータ可視化用 Python ライブラリの中でも、matplotlib はデータの可視化によく使用されています。DBR や MLR にはこれらの Python ライブラリの一部が含まれていますが、現在 Notebook セルでサポートされているのは、matplotlib inline の機能のみです。
DBR 6.5 以降で組み込まれたこのマジックコマンドを使用すると display(figure) や display(figure.show()) に対する明示的なメソッド呼び出しや spark.databricks.workspace.matplotlibInline.enabled = true を設定する代わりに、Notebook セル内にプロットを表示できます。
4. PyTorch や TensorFlow における %tensorboard マジックコマンド
DBR の一部としてブログで発表されたこのマジックコマンドは、TensorBoard から取得したトレーニングメトリクスを同じ Notebook 内に表示します。この新機能は、これまで提供していた dbutils.tensorboard.start() を置き換えるものです。旧機能では、TensorBoard のメトリクスを別タブで表示する必要があり、Databricks Notebook から離れてフローを中断せざるを得ないものでした。
もう、Notebook から離れ、別のタブから TensorBoard を起動する必要はありません。これにより、開発時のエクスペリエンスが大きく向上してさらにシンプルに作業が行えるようになります。
機械学習モデルには、DBR や MLR にインストールされている TensorFlow と PyTorch のライブラリを使用できますが、ここでは PyTorch(コードと表示は Notebook を参照)を使用しています。
%load_ext tensorboard
%tensorboard --logdir=./runs
5. 外部ノートブックをインスタンス化するための %run マジックコマンド
ソフトウェアエンジニアリングの一般的なソフトウェアデザインパターンやプラクティスを参考に、データサイエンティストはクラス、変数、ユーティリティメソッドを外部ノートブックで定義できます。つまり、IDE(統合開発環境)の Python モジュールと同じように、これらのクラスを「インポート」できます。ただし、ノートブックの場合、これらの定義されたクラスは %run auxiliary_notebook コマンドによって現在のノートブックスコープに読み込まれます。
これまで述べてきたような新機能ではありませんが、この使用法により、ドライバ(またはメイン)ノートブックが読みやすくなり、クラスタリングが大幅に軽減されます。開発者の中には、この外部ノートブックを使用してデータ処理を個別のノートブックに分割し、それぞれがデータの前処理、探索、分析を行い、その結果を呼び出し元のノートブックのスコープに取り込みます。
この外部ノートブックのもう 1 つの使用法としては、クラス、変数、およびユーティリティ関数の再利用が挙げられます。例えば、Utils と RFRModel は、他のクラスとともに、外部ノートブック cls/import_classes で定義されています。%run ./cls/import_classes を実行することで、全てのクラスは呼び出し元のノートブックのスコープに読み込まれます。この簡単な手順で、ドライバノートブックが散在することはなくなります。クラスを別の場所で定義し、コードをモジュール化して再利用すればいいのです。
MLOps のビッグブック

6. 新しいデータの高速アップロード
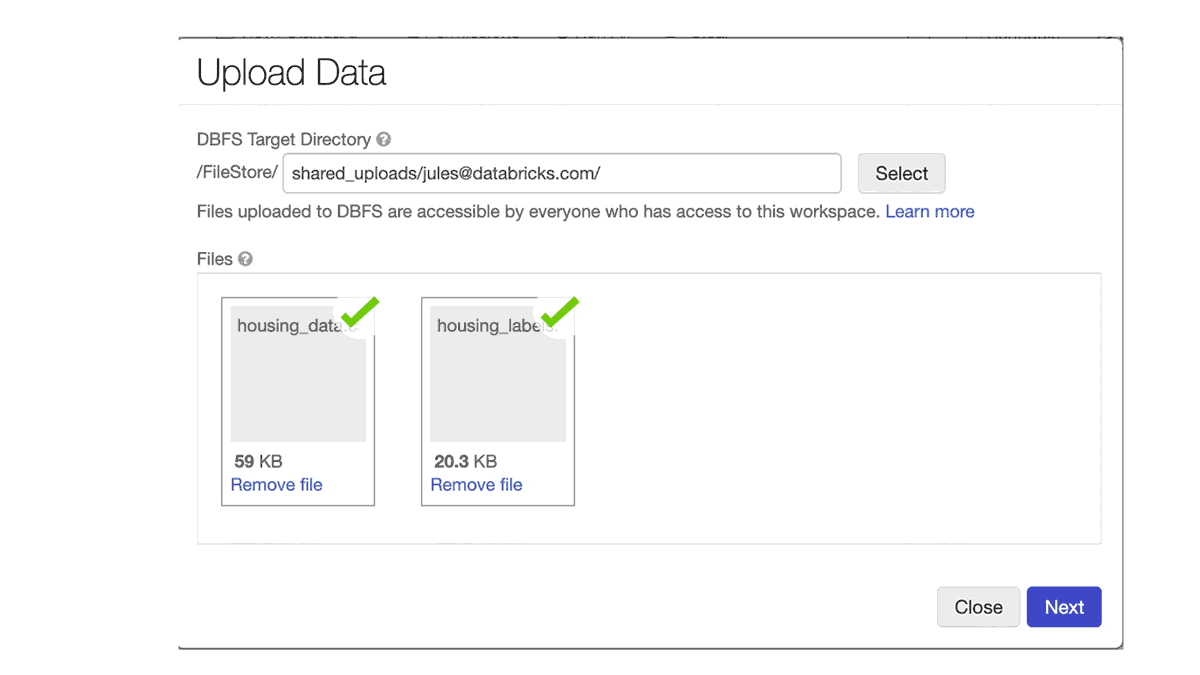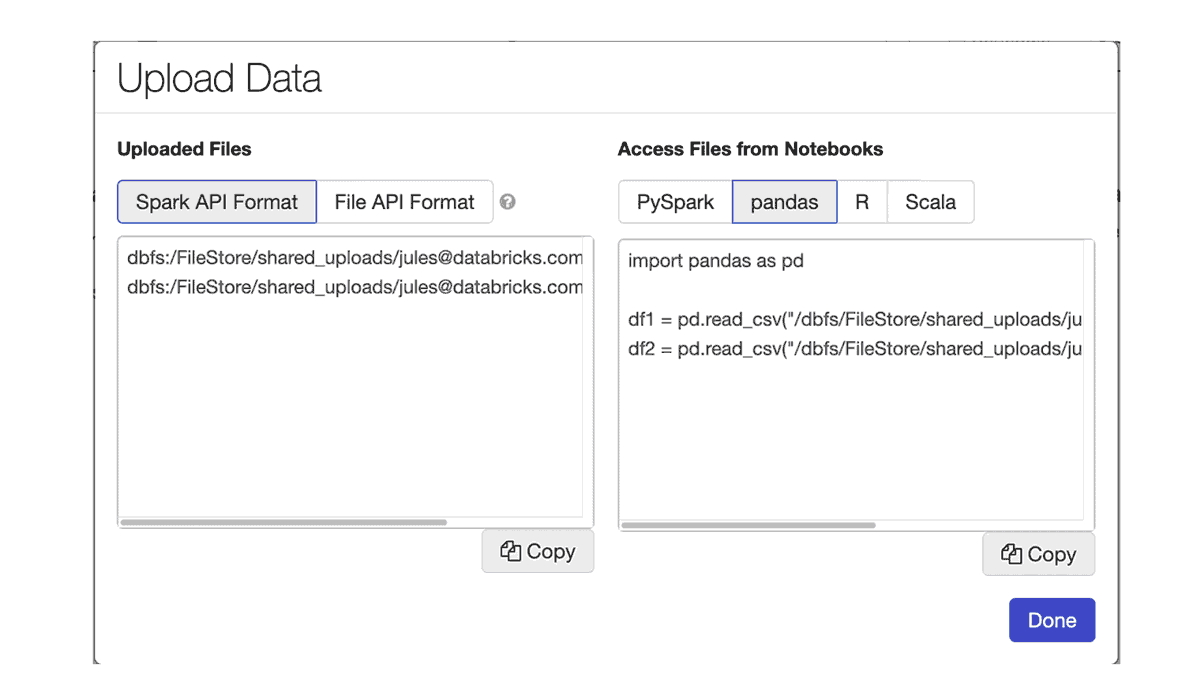
ノート PC のローカルにあるデータにアクセスし、Databricks を使用して分析を実行したいということもあるでしょう。新機能のデータアップロードは Notebook の File メニューにあり、ローカルデータをワークスペースにアップロードします。デフォルトのターゲットディレクトリは、/shared_uploads/your-email-address ですが、保存先を選択し、Upload File ダイアログのコードを使用してファイルを読み込むことが可能です。今回は、CSV ファイルを読み込むために pandas のコードを選択します。
一度アップロードしたデータファイルには、処理や機械学習トレーニングのためのアクセスが可能です。
7.1 MLflow:Experiment の動的カウンター
MLflow の UI は、Databricks Notebook に密接に連携しています。MLflow API を使用してモデルをトレーニングすると、実行がログに記録されて終了する際に Experiment ラベルカウンターが動的に増加し、データサイエンティストに進行中の実験を視覚的に示します。

Experiment をクリックすると、サイドパネルに各実行の主要パラメータとメトリクスの表形式のサマリーが表示され、実行、パラメータ、メトリクス、アーティファクト、モデルといった詳細な MLflow エンティティを確認できます。
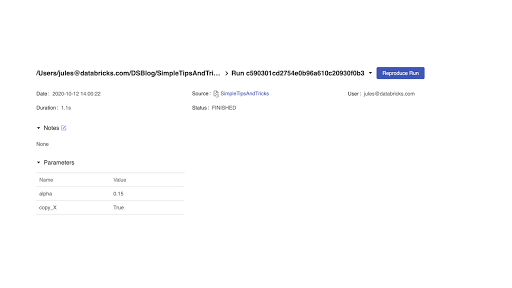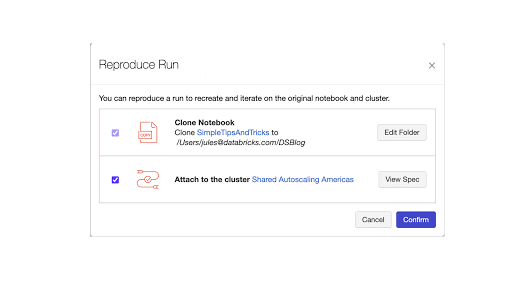
7.2 MLflow:Reproduce Run ボタン
MLflow のもう 1 つの機能改善点は、Notebook の実行を再作成して Experiment を再現できることです。MLflow の実行ページのいずれからも、Reproduce Run ボタンを使用して Notebook を再作成し、現在のクラスタまたは共有クラスタにアタッチできます。
8. UI に関するちょっとした機能
データサイエンティストがデータをすばやく確認したり、削除したセルを元に戻したり、画面を分割して表示したり、タスクをより速く実行できるように、Notebook に次のような機能強化を行いました。
より優れた使用法、実行の高速化のためのヒント:Notebook セル内のコードブロックが実行されるたびに、DBR はコードを実行する効率的な方法の探索や、現在のセルのタスクを強化する追加機能を示すためにヒントを提供することがあります。例えば、モデルのトレーニングを行う場合は、MLflow を使用してトレーニングメトリクスとパラメータを追跡することが推奨されるかもしれません。

Parquet 形式の DataFrame を SQL テーブルとして永続化する場合には、データソースに対する将来のトランザクション操作を効率的かつ確実に行うために、Delta Lake テーブルを使用することが推奨される場合があります。また、最適化可能な複雑な Spark 操作を実行している場合や、1 つは非常に大きく、もう一方は非常に小さいといった 2 つの不均一な Spark DataFrame を結合していることをバックエンドのエンジンが検出した場合、Apache Spark 3.0 から導入された Adaptive Query Execution を有効にして性能を向上させるように提案することがあります。
このようなちょっとした工夫で、データサイエンティストやデータエンジニアは、Spark の最適化された機能を活用したり、MLflow などの追加ツールを利用して、モデルのトレーニングを管理しやすくするのに役立ちます。
削除したセルを元に戻す:セルで重要なコードを開発する過程で誤ってその��セルを削除してしまい、取り返しのつかない状態になってから気づくということが何度あったことでしょうか。削除したセルは、Notebook が削除されたセルを追跡して保持しているため、元に戻すことができます。
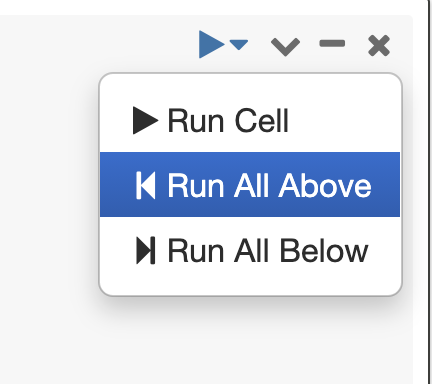
ここまでを全て実行する(Run All Above):シナリオによっては、現在のセルより上にある以前のセルのバグを修正し、現在のセルから再びここまでのセル全てを実行したいというケースがあるでしょう。この作業を簡単に実行できます。
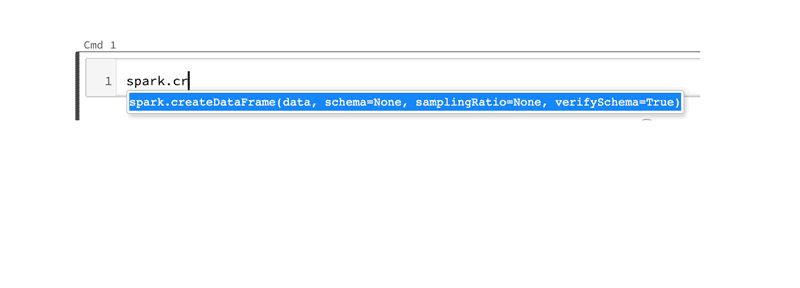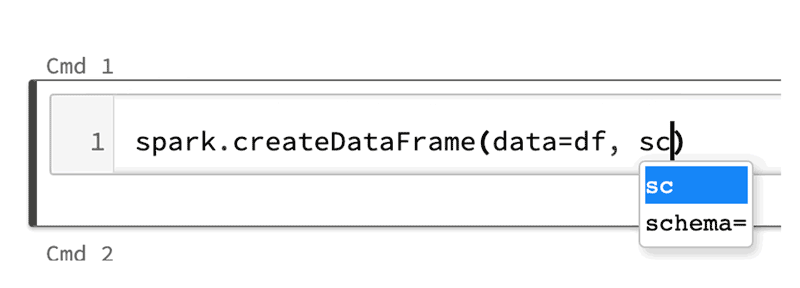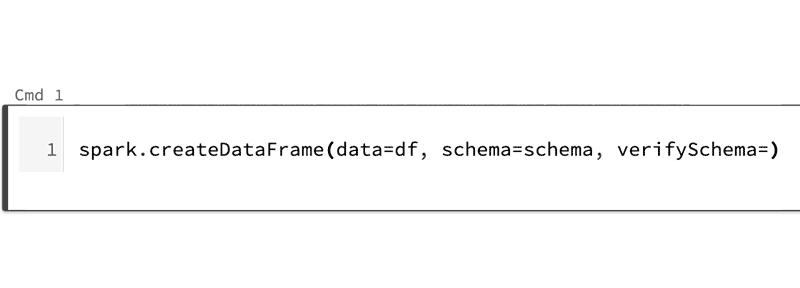
コード補完と関数シグネチャのためのタブキー:一般的な Python 3 の関数と Spark 3.0 のメソッドの両方において、メソッド名のあとでタブキーを押すと、コードを補完するために選択できるメソッドとプロパティのドロップダウンリストが表示されます。
Side-by-Side(横並び)ビューを使用する:
PyCharm などの Python IDE と同様に、マークダウンファイルを作成し、そのレンダリング結果を横並びのパネルで表示できます。Notebook セルを作成および表示するには、View → Side-by-Side を選択します。
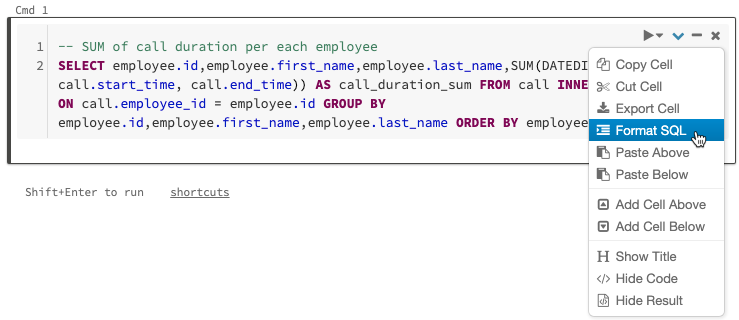
9. SQL コードのフォーマット
新しい機能ではありませんが、フリーフォーマットの SQL コードをすばやく簡単に入力し、セルメニューで SQL コードをフォーマットできます。
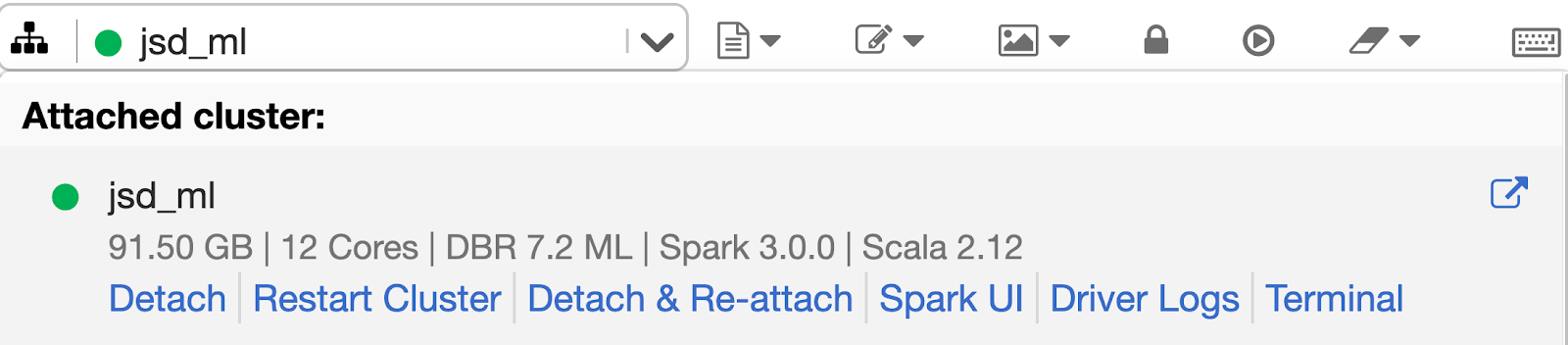
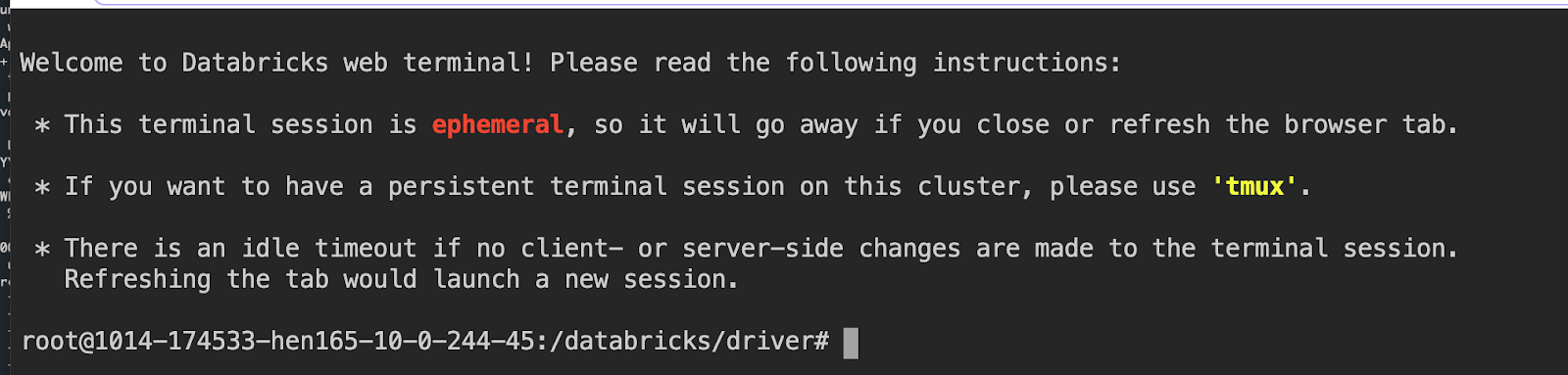
10. クラスタにログインするための Web ターミナル
データサイエンティストを含むデータチームのメンバーは、Notebook から直接ドライバノードにログインできます。SSH や認証トークンの面倒な設定が必要な %sh ssh マジックコマンドは不要です。さらに、システム管理者とセキュリティチームは、仮想プライベートネットワ�ークに SSH ポートを開くことを嫌います。ユーザーとして、クラスタ上のドライバノードに対話型ターミナルを接続するために SSH キーを設定する必要はありません。Databricks の管理者がクラスタへの "Can Attach To" 権限を付与していれば、すぐに Web ターミナルを利用できます。
こちらのブログで発表されたこの機能は、完全なインタラクティブシェルと、クラスタのドライバノードへの制御されたアクセスを提供します。Web ターミナルを使用するには、ドロップダウンメニューから Terminal を選択するだけです。
ご紹介したこれらの機能は、摩擦を軽減し、コードフローを容易にし、実験やプレゼンテーション、データ探索を可能にします。Databricks Notebook で、これらのシンプルな機能をお試しください。
Notebook ��をダウンロード、インポートし、Databricks レイクハウスプラットフォーム(DBR 7.2 以降、または MLR 7.2以降)で実際に使用できます。
データチームが世界の困難なデータ問題をどのように解決しているのかを知るために、ぜひ Data + AI サミット にご参加ください。