Koalas(PySpark)がDask よりも高速な理由 – SQL クエリ最適化など
によって Xinrong Meng 、 Hyukjin Kwon による投稿
Koalas は、Apache Spark 上で pandas API を実装するデータサイエンスライブラリです。Koalas を利用することで、データサイエンティストは、使い慣れた API を介してあらゆる規模のデータセットを扱うことができます。今回私たちは、ビッグデータ分析の際によく使用される pandas API を実装した並列計算ライブラリの Dask と、PySpark の Koalas とのパフォーマンス比較を行いました。ベンチマークテストを繰り返したところ、Koalas のパフォーマンスは、Dask と比較して、シングルノードで 4 倍、クラスタで 8 倍、ケースによっては最大 25 倍高速であるという結果が出ました。このブログでは、テストの内容と結果の詳細を解説します。
最初に、ベンチマークの設定方法、実施環境、テスト結果について説明します。次に、コード生成やクエリ(query)の最適化などの高度な技術を用いて最適化された Spark の SQL エンジンの詳細を明らかにし、Koalas/Spark が Dask よりも極めて高速である理由について解説します。
ベンチマークの方法
今回のベンチマーク比較は、ニューヨーク市タクシー・リムジン委員会(TLC)の乗車記録データから、「2009 年から2013 年のイエロータクシーの乗車記録(157GB)」を抽出して実行しました。また、データセットに対する基本的な統計計算、テーブル結合、フィルタリング、グループ化など、pandas ワークロードにおける共通のオペレーションを特定しました。
シングルノードのケースとクラスタコンピューティングのケースの双方を総合的にカバーするように、ローカルでの実行と分散環境での実行を対象としました。実際のワークロードを想定し、フィルタリングおよびキャッシュを有効にした場合と無効にした場合を測定しました。
まとめると、次のような側面でのベンチマーク評価を行ったことになります。
- 標準のオペレーション(ローカル/分散環境での実行)
- フィルタリング有効時のオペレーション(ローカル/分散環境での実行)
- フィルタリングとキャッシュ有効時のオペレーション(ローカル/分散環境での実行)
データセット
イエロータクシーの乗車記録には、数値型とテキスト型の 17 の列で構成された CSV ファイルが含まれており、乗車および降車日時、乗車および降車地点、乗車距離、項目別運賃、料金種別、支払い種別、ドライバー申告による乗客数などのフィールドがあります。作業を効率化するために、CSV ファイルを Databricks File System(DBFS)にダウンロードし、Koalas を介して Parquet ファイルに変換しました。
オペレーション
既存の複数の pandas ワークロードを分析し、共通するオペレーションのいくつかのパターンを特定しました。特定されたオペレーションの疑似コードを以下に示します。
両方のシステムにおける遅延評価、キャッシュ、関連する最適化の影響を考慮する目的で、フィルタリングとキャッシュをそれぞれ有効または無効にして各オペレーションを実行しました。
- 標準のオペレーション
- フィルタリング有効時のオペレーション
- フィルタリングのオペレーションでは、1 ~ 5 ドルのチップを受け取った記録を検出し、元のデータの 36% までフィルタリングします。
- フィルタリングとキャッシュ有効時のオペレーション
- キャッシュを有効にした場合、データが全てキャッシュされてからオペレーションの測定が行われます。
ベンチマークテストに使用された完全なコードについては、このブログの最後に掲載している Notebook を参照してください。
環境
ベンチマークテストは、ローカルでの実行のシングルノード、分散環境での実行の 3 ワーカーノードのクラスタの両方で実行しています。環境のセットアップを容易にするために、Databricks Runtime 7.6(Apache Spark 3.0.1)とDatabricks Notebook を使用しています。
システム環境
- オペレーティングシステム:Ubuntu 18.04.5 LTS
- Java:Zulu 8.50.0.51-CA-linux64 (build 1.8.0_275-b01)
- Scala:2.12.10
- Python:3.7.5
Python ライブラリ
- pandas:1.1.5
- PyArrow:1.0.1
- NumPy:1.19.5
- Koalas:1.7.0
- Dask:2021.03.0
ローカルでの実行
ローカルでの実行には、AWS の単体の i3.16xlarge VM を使用しました。メモリ 488 GB、64 コア、25 Gb イーサネットを備えています。

分散環境での実行
分散環境での実行には、i3.4xlarge VM による 3 つのワーカーノードを使用しました。それぞれ、メモリ 122 GB、16 コア、10 Gb イーサネット(最大)を備えています。このクラスタの総メモリ量は、シングルノード構成の場合と同じです。
結果
以下のベンチマークテストの結果には、Koalas と Dask の全体的なパフォーマンスの比較を説明するために、幾何平均(相乗平均)を用いた概要が含まれています。それぞれの棒グラフは経過時間の比率(Dask の値を Koalas の値で割った割合)を示しています。Koalas API は PySpark 上に作成されていることから、このベンチマークテストの結果は、PySpark の結果としても適用することもできます。
標準のオペレーション
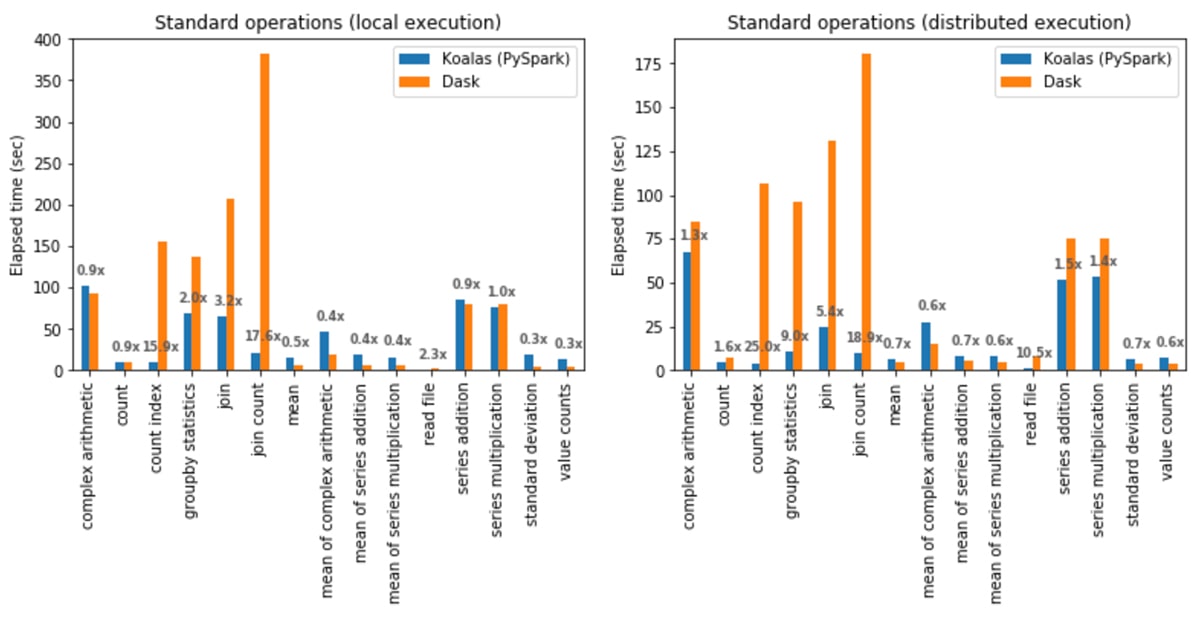
ローカルでの実行:Koalas は Dask よりも平均 1.2 倍高速でした。
- join と count の組み合わせ(join count)は、Koalas が Dask よりも 17.6 倍高速。
- 標準偏差(standard deviation)の計算は、Dask が Koalas よりも 3.7 倍高速。
分散環境での実行:Koalas は Dask よりも平均 2.1 倍高速でした。
- count index 操作は、Koalas が Dask よりも 25 倍高速。
- 複素数演算の平均算出は、Dask が Koalas よりも 1.8 倍高速。
フィルタリング有効時のオペレーション
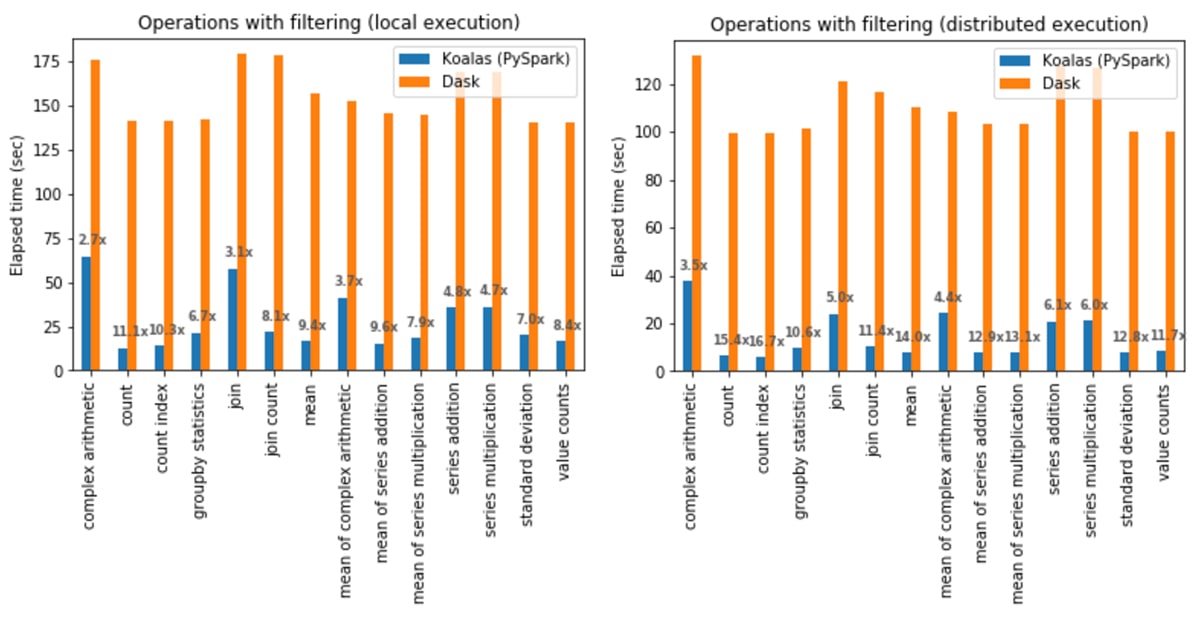
ローカルでの実行:Koalas は全てのケースで Dask よりも平均 6.4 倍高速でした。
- count 操作は、Koalas が Dask よりも 11.1 倍高速。
- 複素数演算は、最も差が小さく、Koalas が Dask よりも 2.7 倍高速。
分散環境での実行:Koalas は全てのケースで Dask よりも平均 9.2 倍高速でした。
- count 操作は、 Koalas が Dask よりも 16.7 倍高速。
- 複素数演算は、最も差が小さく、Koalas が Dask よりも 3.5 倍高速。
フィルタリングとキャッシュ有効時のオペレーション
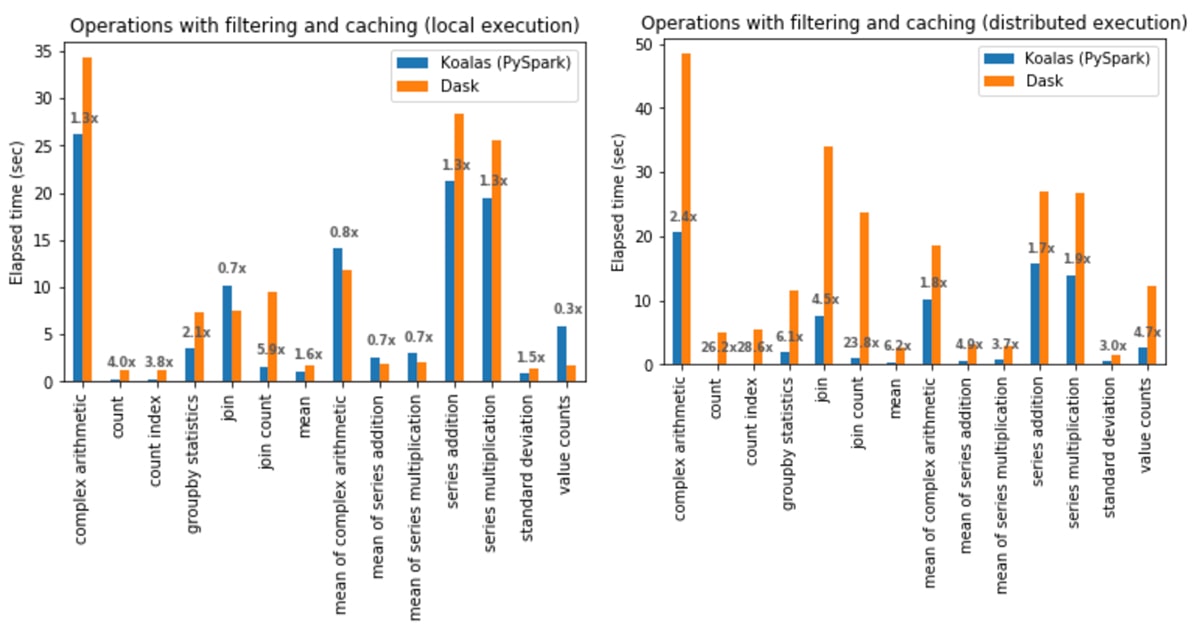
ローカルでの実行:Koalas は Dask より平均 1.4 倍高速でした。
- join と count の組み合わせ(join count)は、Koalas が Dask よりも 5.9 倍高速。
Series.value_counts(value counts)は、Dask が Koalas よりも 3.6 倍高速。
分散環境での実行:Koalas は全てのケースで Dask より平均 5.2 倍高速でした。
- count index 操作は、 Koalas が Dask よりも28.6 倍高速。
- 複素数演算は、最も差が小さく、Koalas が Dask よりも 1.7 倍高速。
分析
Koalas(PySpark)は、ほとんどのケースで Dask よりも大幅に高速でした。その理由は単純です。Koalas と PySpark はいずれも Spark をベースとしており、Spark は分散コンピューティングエンジンの中でも最も高速なエンジンの 1 つだからです。Spark は、高度なクエリ実行計画の最適化とコード生成機能を備えた完全最適化 SQL エンジン(Spark SQL)を搭載しています。大まかな比較ですが、Spark SQL では 1,600 人以上のコントリビュータが 11 年以上かけて 100 万行近くのコードを用意しているのに対し、Dask では 400 人以上のコントリビュータが 6 年程かけて Spark の 10% 程度のコードベースを用意しているに過ぎません。
Spark SQL の多くの最適化手法の中でも、 Koala のパフォーマンスに最も貢献している要素を特定するため、Koalas が Dask よりも高いパフォーマンスを示している分散環境でのフィルタリング有効時のオ��ペレーションを対象とし、以下のオペレーションについて分析を行いました。
- 統計計算
- テーブル結合(join)
これらの実行および実行計画最適化について精査したところ、Spark SQL におけるコード生成とクエリ実行計画の最適化が、最も有意な要素であることが判明しました。
コード生成
Spark SQL で最も重要な実行時の最適化機能が、コード生成です。Spark エンジンにより、実行時のクエリごとに最適化されたバイトコードが生成され、パフォーマンスを大きく改善します。この最適化により仮想関数のディスパッチの回避するなど、Koalas の統計計算と join 実行時のベンチマークに極めて大きな影響を与えていました。詳細については、コード生成について紹介しているブログ記事(Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop)で解説しています。
例えば、Databricks の本番運用環境でコード生成を無効にした場合、同じベンチマークコードの平均値の計算は、約 8.37 秒、join count で約 27.5 秒かかります。コード生成を有効(デフォルト設定)にすると、平均値の計算は、約 1.26 秒、join count が約 2.27 秒になります。すなわち、それぞれ 650%、1200% 改善されることになります。
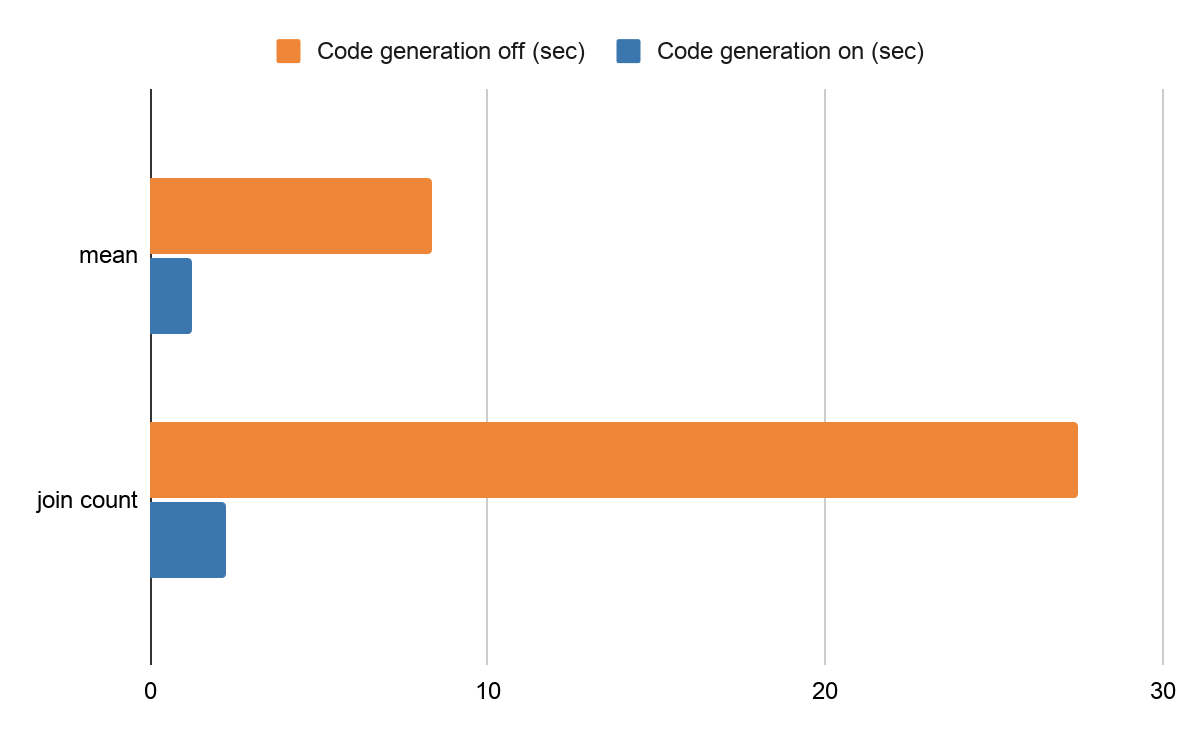
コード生成におけ��るパフォーマンスの違い
SQL クエリ(query)実行計画の最適化
Spark SQL には、非常に高度なクエリ実行計画最適化ツールである Catalyst が用意されています。Catalyst により、実行処理を通じてクエリ計画が動的に最適化されます(適応型クエリ実行)。Koalas で統計計算や join をフィルタリング有効時に行う場合、Catalyst オプティマイザによってもパフォーマンスが大きく改善されます。
Catalyst によるクエリ実行計画の最適化を使用しない場合、Koalas での平均値計算時における Spark SQL の元の実行計画は、大体以下のようになります。ブルートフォースで全ての列を読み込み、平均値を計算するまでに、フィルタを使って実行計画の作成を複数回行っています。
これではより多くのデータを読み込む必要があるうえ、I/O にも時間がかかり、計画作成を複数回繰り返すことになって、非効率です。
一方、以下の計画では、Catalyst オプティマイザを使用して効率よく動作するように最適化されています。
計画は大幅にシンプルになります。計算に必要な列だけが読み込まれ(列プルーニング)、ソースレベルでデータがフィルタリングされることでメモリの使用量が削減されています(フィルタプッシュダウン)。
Koalas(PySpark)での join と count(join count)の場合でも、以下のようなSpark SQL の元の実行計画を作成します。
ここでも、平均値の計算の際と同じ問題が生じています。不要な読み込み処理と複数回の計画作成が実行されています。一点だけ異なるのは、join を行うためにデータのシャッフルと交換が行われていることです。通常はこのようなオペレーションにより相当量のネットワーク I/O が発生し、パフォーマンスを大きく損ないます。Catalyst オプティマイザでは、join の対象となるデータの片方が非常に小さい場合にはシャッフル処理を取り除き、以下に示すように BroadcastHashJoin にすることができます。
列プルーニングやフィルタプッシュダウンを行うだけでなく、より小さな DataFrame をブロードキャストすることでシャッフルの手順を取り除いています。内部的には、より小さな DataFrame を各エグゼキュータに送信し、データを交換することなく join を実行しています。これにより、不要なシャッフル処理を回避し、パフォーマンスを大きく改善しています。
まとめ
ベンチマークテストの結果からは、ほとんどのユースケースで Koalas(PySpark)が Dask のパフォーマンスを上回っており、Spark SQL の実行エンジンと複数の高度な最適化手法がその大きな要因であることが示されました。
まず、特定のオペレーションにおいて Koalas のローカル/分散環境での実行は、 Dask(Python で記述された並列計算用のオープンソースライブラリ)よりはるかに�高速であることがわかりました。
- ローカルでの実行:幾何平均:2.1 倍、単純平均:4 倍
- 分散環境での実行:幾何平均:4.6 倍、単純平均:7.9 倍
次に、キャッシュの使用は Koalas と Dask の両方のパフォーマンスに影響し、経過時間を大幅に短縮することがわかりました。
最後に、分散環境でフィルタリングが有効な場合に統計計算と join を実行すると最もパフォーマンスの差が開き、幾何平均(相乗平均)では Koalas(PySpark)が全てのケースで 9.2 倍高速であることが明らかなりました。
今回のベンチマークテストの結果については、全て自己完結型の Notebook に含めています。データセット、オペレーション、全ての設定、ベンチマークコードを確認できるようにしています。以下の Notebook を参照してください。
- データセット
- 標準のオペレーション(ローカルでの実行)
- 標準のオペレーション(分散環境での実行)
- フィルタリング有効時のオペレーション(ローカルでの実行)
- フィルタリング有効時のオペレーション(分散環境での実行)
- フィルタリングとキャッシュ有効時のオペレーション(ローカルでの実行)
- フィルタリングとキャッシュ有効時のオペレーション(分散環境での実行)
- ローカルでの実行の概要
- 分散環境での実行の概要
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。