特徴量エンジニアリングは、機械学習のプロセスの中で最も重要なステップの 1 つであり、多くの時間を要します。データサイエンティストやアナリストは、さまざまな特徴量を組み合わせた実験を重ねてモデルを改善し、ビジネスに有益な情報を提供する BI レポートの作成を目指します。そのような状況下で、データサイエンティストが扱うデータの規模および複雑さが増大し、次のような事柄が課題となっています。
- 特徴量をシンプルかつ一貫性のある方法で定義すること
- 既存の特徴量の識別と再利用
- 既存の特徴量を利用した拡張
- 特徴量やモデルのバージョン管理
- 特徴量定義のライフサイクルの管理
- 特徴量の計算と保存の効率化
- 大規模テーブル(>1000 列)の効率的な計算と永続化
- 意思決定につながるモデルのもとになった特徴量の再現(例:監査や解釈可能性などの実証)
このブログでは、大規模データの特徴量を生成する際のデザインパターンについて解説します。また、デザインパターンのリファレンス実装をダウンロード可能な Notebook で提供し、ファーストクラスのデザインパターンによって、いかに特徴量エンジニアリングのプロセスが簡素化され、組織のサイロを解消し効率化を実現するかを示します。ここで紹介するアプローチは、最近リリースされた Databricks Feature Store と統合可能です。Databricks Feature Store は MLOps とデータプラットフォームの協調設計による初の特徴量ストアであり、Delta Lake と MLflow のストレージや MLOps のケイパビリティを活用できます。
今回の例では、TPC-DS のトレーニングデータセットを使用して、Apache Spark™ による大規模なファーストクラス特徴量エンジニアリングのワークフローの利点を示しています。これらの複雑な変換は自己文書化されており、効率的で拡張も可能です。売上や取引などの基本的な指標を、顧客や時間などのディメンションを対象に修正・変換し、モデル化可能な特徴量を作成しました。これらの複雑な変換は自己文書化されており、効率的で拡張も可能です。ファーストクラス特徴量エンジニアリングのフレームワークは業界に特化したものではありませんが、それぞれの組織の個別の目標に合わせて容易に拡張できるものでなければなりません。このブログでは、フレームワーク内で高階関数を適用して適合させることで、拡張が可能であることを示しています。
今回の特徴量エンジニアリング��のアプローチは、データの大規模化に起因する困難な課題にも対応できるように設計されています。ほぼ全てのビジネスにおいてデータが爆発的に増加しており、特徴量そのものだけでなく、その作成や管理も含めた作業の指数関数的な増加が、業界を問わず大きな課題となっています。このブログで紹介するフレームワークは既に複数の業界で検討・導入されており、その一部について以下で解説します。
今回の特徴量エンジニアリングのアプローチは、データの大規模化に起因する困難な課題にも対応できるように設計されています。ほぼ全てのビジネスにおいてデータが爆発的に増加しており、特徴量そのものだけでなく、その作成や管理も含めた作業の指数関数的な増加が、業界を問わず大きな課題となっています。このブログで紹介するフレームワークは既に複数の業界で検討・導入されており、その一部について以下で解説します。
アーキテクチャの概要
このブログで紹介しているデザインパターンは、Feature Factory にまとめられたものに基づ��いています。以下の図は、典型的なワークフローです。まず、未加工のデータからベースとなる特徴量が定義され、他の特徴量の構成要素となります。例えば、特徴量 total_sales を基本特徴量として定義し、顧客ごとにグループ化して sales_value の合計を求めることが可能です。新たに生成された特徴量は、基本特徴量に対してより複雑な操作を行うための入力値として使用できます。多数の特徴量の生成、文書化、テスト、検証、永続化を、数行のコードで迅速に行うことができます。
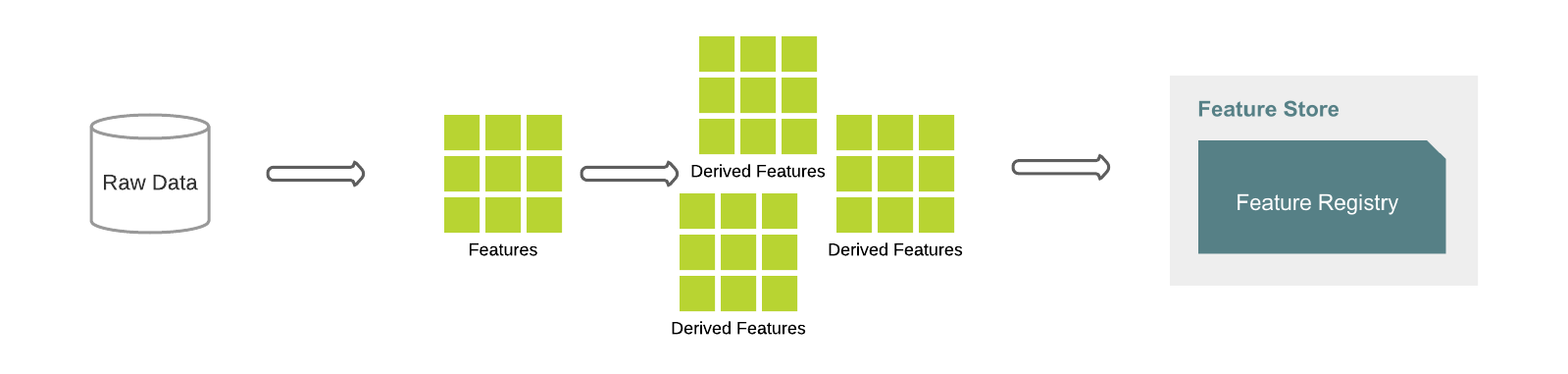
Feature Store API を使用し、特徴量の定義を未加工のデータに適用して、特徴量をデータフレームとして生成することも可能です。データフレームを Feature Registry に保存することもできます。また、Delta Lake では、特徴量生成エンジンで利用する複数の最適化機能を提供しています。特徴量の定義はバージョン管理されており、トレーサビリティ、再現性、時間的な解釈可能性が必要になる場面や、監査の際に利用できます。
以下のコード例では、特徴量の定義をマテリアライズし、Feature Store に登録する方法を示しています。
シンプルな特徴量の乗算による結果
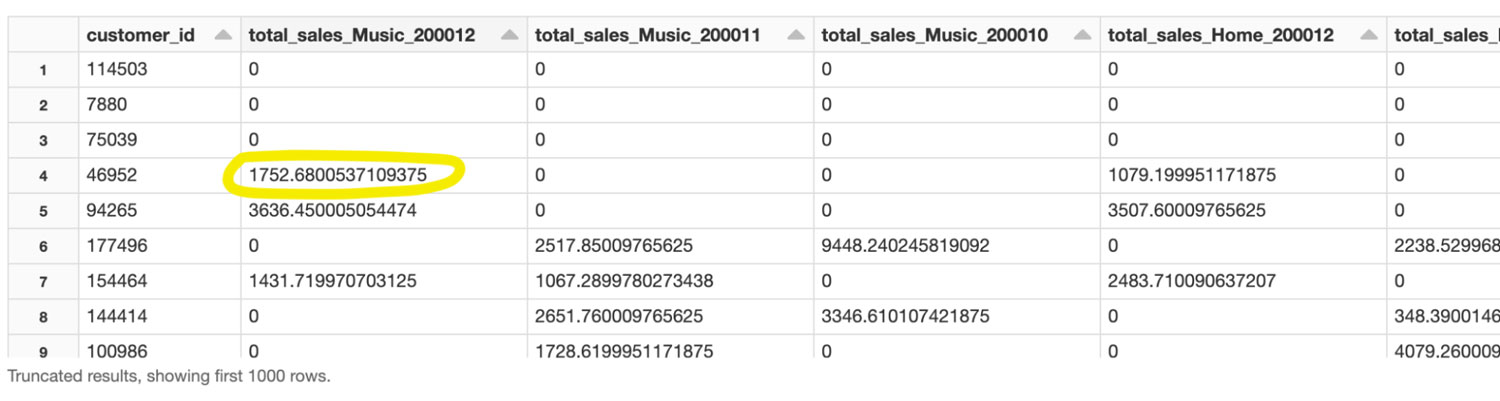
Feature Store で生成された特徴量
例として、上記の表では、total_sales_Music_200012(customer_id 46952 )が 1752.68 になっています。つまり、この顧客は、2000年 12 月時点の定義における total_sales として、1752.68 ドルに相当する楽曲を購入したことになります。
データセット
リファレンス実装では、原則として TPC-DS の3つの販売チャネル(Web、Store、Catalog)に基づいています。このブログのコード例では、date_dim で結合されたStoreSales テーブルと item テーブルから作成された特徴量を示しています。各テーブルで定義する内容は以下のとおりです。
- Store_Sales:実店舗内での製品取引から生じた収益
- Date_Dim:日付のディメンションを表すカレンダー型のテーブル
- Item:販売可�能な SKU
基本特徴量の定義
Spark API には、特徴量エンジニアリングに利用できるデータエンジニアリング向けの強力な機能が用意されており、ラッパーといくつかのコンテキスト定義を使って、複雑な内容を抽象化し、簡単に再利用できるようにします。Feature クラスは、統一されたインタフェースを提供し、次のコンポーネントを使って特徴量を定義します。
_base_col:シンプルな列型の表現のカラムやその他の特徴量。- _filter:条件リスト、または True/False の列型表現。True の場合は、 _base_col で定義されたロジックが特徴量として使用され、そうでない場合には
_negative_valueを使用して特徴量が計算される。 _negative_value:_filter が False を返す場合に評価される表現。_agg_func:ベースカラムの集計に使用する Spark SQL 関数を定義。_agg_func が定義されていない場合、その特徴量は集約表現ではない(つまり、特徴量は 1 つのみ)。
以下は、2019年上半期の売上を集計する集約特徴量の定義方法の例です。
以下は、上と同等の表現です。
特徴量のモジュール化
特徴量エンジニアリングにおいてよくみられる問題は、データサイエンスチームが独自に特徴量を定義する一方、その特徴量定義の文書化や可視化がされておらず、他のチームと簡単に共有できないことで�す。その結果、取り組みやコードの重複だけでなく、最悪の場合には、同じ意図に基づいた特徴量であってもロジックや結果が異なるということが起こります。チーム間でバグの修正、改善、文書化を行うことは、非常に困難です。特徴量の定義をモジュール化することで、これらの一般的な課題を軽減することができます。
組織や部門間で共有する場合、組織内での担当領域が異なると同様の概念に対しても計算方法が違ってくるため、抽象化の程度をさらに深める必要があります。例えば、net_sales の計算は、店舗、ウェブ、通信販売の事業部門で必要ですが、入力だけでなく計算についても事業部門ごとに異なる可能性があります。net_sales をより多様な組織を対象に異なる形で導き出せるようにするには、net_sales とその共通項を common_module(例:sales_common)に昇格させ、そこにユーザーが事業ごとのルールを反映させられるようにする必要があります。ほとんどの特徴量は、他の事業部門と大きく重複することはなく、共通項となることはありません。しかし、そのような特徴量が別の事業部門では価値がないということにはなりません。異なる概念を組み合わせて扱う特徴量を生成することは可能です。ただし、共通の上位概念が存在しない場合、使用に際しては、元の概念(channel 等)のルールに従う必要があります。例えば、店舗の売上を予測する機械学習(ML)モデルでは、通信販売の特徴量から値を取得することがよくあります。catalog_sales を店舗の売上の主要指標として想定する場合、通信販売と店舗という概念上の相違を超えて特徴量を定義づけるこ��とはできますが、この場合、ユーザーが外部モジュール(例:名前空間)の構造を通じて定義ルールを理解できるようになっていなければなりません。このような抽象化の詳細については、これ以上はこのブログ記事では取り上げません。
リファレンス実装では、Feature Family(特徴量の集まり)としてモジュールを実装しています。各特徴量には読み取り専用のプロパティが定義されており、簡単にアクセスできるようになっています。Feature Familyは、汎用性のある ImmutableDictBase クラスから拡張されており、特徴量コレクションのベースクラス、フィルター、その他のオブジェクトとして機能します。下のコード例では、フィルターの定義が特徴量から抽出され、別の Filters クラスを構成します。複数のファミリーで共有される共通の特徴量も、再利用のために別の共通 Features クラスに抽出されます。フィルターと共通の特徴量の両方が、StoreSales ファミリークラスに継承され、共通の定義に基づいて新しい特徴量が定義されます。
コード例では、チャンネルは 1 つだけですが、複数のチャンネルで同じ CommonFeatures を共有しています。特定のチャンネルから特徴量の定義を取得するには、store_channel.total_sales などのように、そのファミリークラスのプロパティにアクセスするだけです。
特徴量のオペレーション
特徴量の生成については、大抵の場合、共通のパターンが見受けられます。より高次の関数を含むように特徴量をスケーリングし、冗長な��部分を減らして可読性と定義の質を向上させ、より容易に再利用できるようにすることなどです。例えば、以下のようなケースがあります。
- アナリストが、前月、前四半期、前年など、さまざまな期間における複数の製品の傾向を測定し、比較することを希望する。
- データサイエンティストが、広告出稿のためのレコメンドシステムを開発する際に、商品カテゴリや市場セグメントごとに顧客の購買パターンを分析する。
多様なユースケースで、類似する一連の操作(フィルター等)を、類似または同等の基本特徴量の上に実装することで、より深く、強力で、具体的な特徴量を生成します。
リファレンス実装では、特徴量がFeature クラスとして定義されており、Feature クラスのメソッドとしてオペレーションが実装されています。より多くの特徴量を生成するために、基本特徴量に乗数を掛けて、個別の時間範囲、値、またはデータ列(Spark Sql Expression 等)のリストとして使用できます。例えば、総売上高の特徴量に月の範囲を掛け合わせて、月別の総売上高の特徴量ベクトルを生成できます。
この乗算は、カテゴリ値にも適用できます。次の例では、カテゴリ別の特徴量から、特徴量 total_sales を導き出す方法を示しています。
なお、これらの処理では、さまざまな乗算の結果として得られる特徴量を組み合わせて、さらに特徴量を変換するような組合せも可能です。
必要に応じて、高次のラムダを適用して、特徴量のリストに特徴量のリストを掛け合わせたリスト内包表記を利用することもできます。例えば、以下の出力変数 total_sales_1M_home は、過去 1 か月間の家庭用品の店舗総売上高を導き出したものです。データサイエンティストが、自分だけが読める何百行もの非効率なコードを使って、何日もかけてデータを処理することがありますが、このフレームワークによりその煩雑な作業が大幅に軽減されます。
特徴量ベクトル
同じオペレーションで使用する複数の特徴量を 1 つのベクトルに格納することで、特徴量のオペレーションをさらに簡単にすることができます。特徴量ベクトルは、Feature Dictionary の特徴量名を列挙することで作成できます。
特徴量ベクトルでは、単純な乗算や除算、あるいは既存のベクトルに対する統計関数によって、別の特徴量ベクトルを作り出すことが可能です。乗算、除算、統計解析などのメソッドを実装しており、既存の基本特徴量のリストから特徴量を生成するプロセスを簡略化できます。同様に、Spark の特徴量トランスフォーマーをラッピングして、スケーラーや二値化などの一般的な特徴量化手法を実行することもできます。以下は One-hot(ワンホット)エンコーディング(ダミー変数)の例です。
上記の結果��、各カテゴリー(grocery、meat、dairy)ごとの total_sales と total_trans に新しい特徴量が生成されます。より動的な処理を行うには、カテゴリの値をハードコーディングするのではなく、ディメンションテーブルの列から読み取ります。なお、乗算の出力は 2 次元ベクトルです。
| GROCERY | MEAT | DAIRY | |
| total_sales | total_sales_grocery | total_sales_meat | total_sales_dairy |
| total_trans | total_trans_grocery | total_trans_meat | total_trans_dairy |
以下は、FeatureVector の実装方法です。