最新の Data Lakehouse で健康データの力を解き放つ

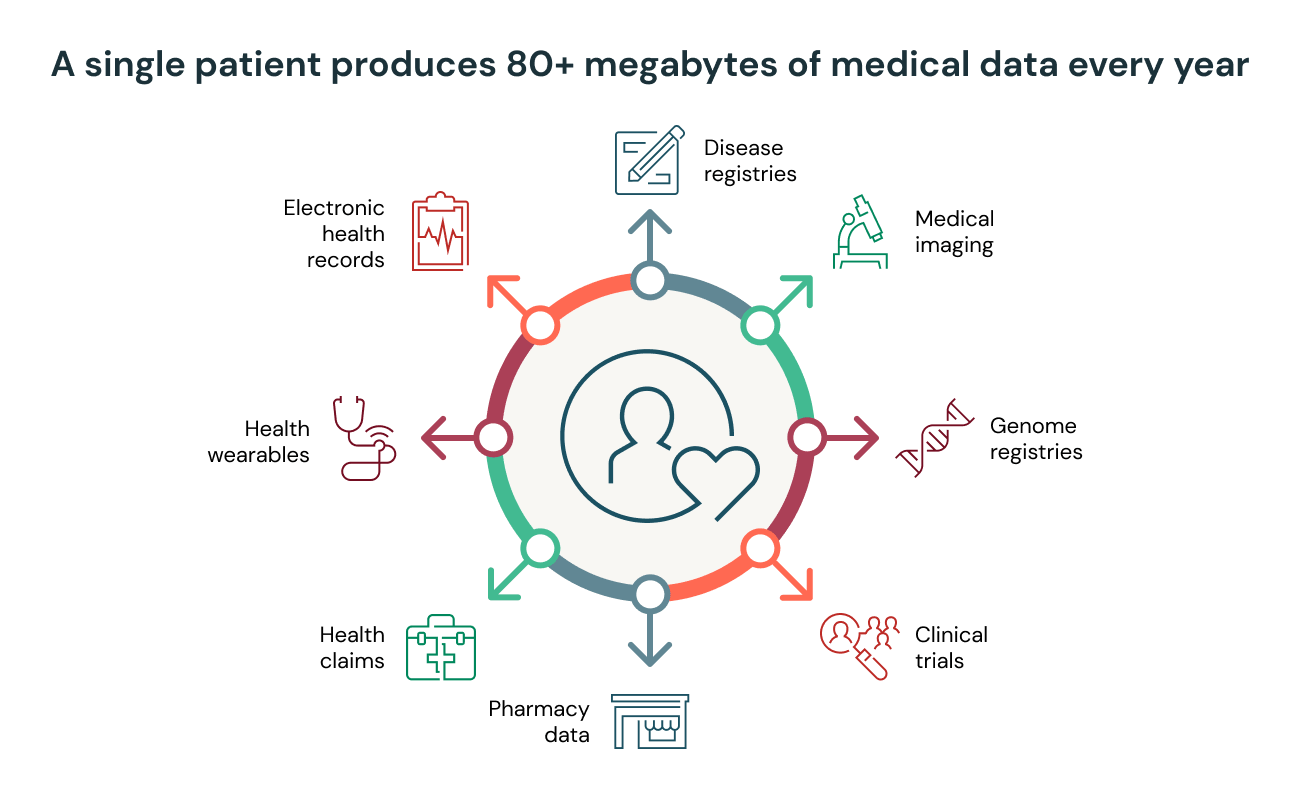
患者 1 人に対して年間およそ 80 MB の医療データが生成されるといわれています。数千人規模の患者の生涯に換算すると、貴重な知見の源となるペタバイト級の患者データが生成されることになります。膨大なデータから知見を抽出することで、臨床業務の効率化、創薬研究の加速、患者の転帰の改善が図れます。これを可能にするためには、データを収集するだけでなく、準備段階として、データの前処理が必要です。ダウンストリームの分析や AI で利用できるよう、収集したデータのクリーニングや構造化を行います。ヘルスケア・ライフサイエンス組織のほとんどが、この準備段階に多大な時間を消費しているのが実情です。
業界におけるデータ分析の課題
ヘルスケア・ライフサイエンス業界の組織が抱える、データ準備、分析、AI における課題には数多くの理由が存在しますが、そのほとんどは、データウ��ェアハウス(DWH)上に構築されたレガシーなデータアーキテクチャへの投資に関係するものです。この業界における 4 つの主要な課題は次のとおりです。
課題 1 - ボリューム:急増するデータに対応するスケーリング
ヘルスケア業界におけるデータの爆発的な増加を示す最適な例は、ゲノミクスです。当初、ゲノムのシーケンスにかかるコストは 10 億ドルを超えていました。膨大なコストゆえ、初期は(今もなお多く)、人間のゲノムのごく一部、通常0.1%程度において特定の変異体を見つけ出すプロセスである、ジェノタイピングに注力されていました。その後、ゲノム上のタンパク質をコードする領域を解析対象とする全エクソームシーケンスへと移行しましたが、それでもゲノム全体の 2% 未満でした。現在、企業は全ゲノムシーケンス(WGS)による顧客への直接検査を提供しており、30 回の WGS で 300 ドル以下となっています。集団レベルにおいては、2021 年に、UK バイオバンクが研究用として 20 万以上の全ゲノムを公開しています。ゲノミクスに限らず、画像、ウェアラブル医療機器、電子医療記録もまた急速に増加しています。
集団医学分析や創薬などの取り組みへの鍵は、スケーリングです。レガシーアーキテクチャの多くは、オンプレミスに構築されており、ピーク時の容量にあわせて設計されています。そのため、使用率が低い期間はコンピューティングパワーの未使用が発生し(最終的にはコストの無駄)、アップグレードが必要な場合も、迅速にスケーリングできません。
課題 2 - 種類:多様なヘルスケアデータの分析
ヘルスケア・ライフサイエンスの組織は、��それぞれ違いのある膨大な種類のデータを取り扱っています。医療データの 80% 以上が非構造化データであることは広く知られていますが、多くの組織はいまだ構造化データ、従来の SQL ベースの分析向けに設計されたデータウェアハウスに注目しています。非構造化データには、腫瘍学、免疫学、神経学などの分野(コストが増大している分野)において、疾患の診断や進行度の測定に不可欠な画像データや、患者の既往歴や社会歴の完全な把握に欠かせない医療記録のナラティブなテキストデータが含まれます。これらのデータタイプを無視したり、後回しにしたりするなどもってのほかです。
問題をさらに複雑にしているのは、ヘルスケアのエコシステムが相互に関連しあうようになってきており、ステークホルダーは新たなデータタイプに取り組む必要があることです。例えば、医療提供者は、リスクシェアリング契約の管理と裁定のために請求データを必要とし、保険者は事前承認などのプロセスのサポートや品質評価の推進のために臨床データを必要とするいったことです。これらの組織では多くの場合、新しいデータタイプをサポートするデータアーキテクチャやプラットフォームが欠如しています。
一部の組織では、非構造化データや高度な分析のサポートを目的としてデータレイクに投資していますが、これは新たな課題を引き起こしています。この環境においては、データチームはデータウェアハウスとデータレイクの2つのシステムを管理する必要があり、サイロ化されたツール間でのデータコピーはデータ品質と管理上の問題を引き起こします。
課題 3 - 速度:リアルタイムな知見を取得するためのストリーミングデータ処理
ヘルスケアは、多くのケースにおいて、生死に関わる問題です。状況は劇的に変化しうるため、日次ベースのバッチデータ処理では不十分なことがほとんどです。介入性治療の成功には、最新情報へのアクセスが不可欠です。病院や国際医療システムでは、命を救うために、敗血症の予測やICU病床のリアルタイム需要予測など、あらゆることにストリーミングデータを使用しています。
さらに、データ処理速度は、ヘルスケアにおけるデジタル革命の主要コンポーネントです。個人はかつてないほど多くの情報にアクセスでき、リアルタイムで治療に影響を及ぼすことができます。例えば、Livongo が提供する持続血糖モニターなどのウェアラブルデバイスは、モバイルアプリにリアルタイムでデータをストリーミングし、パーソナライズされた行動を提案します。
このような早期の成功にもかかわらず、いまだ多くの組織はストリーミングデータの速度に対応可能なデータアーキテクチャを設計していません。信頼性の問題やリアルタイムデータと過去のデータの統合に関する課題が、イノベーションを阻害しています。
課題 4 - 真実性:ヘルスケアデータと AI の信頼性
ヘルスケアにおいては、臨床および規制基準により、データの高精度が求められます。ヘルスケアの組織は、公衆衛生上の高いコンプライアンス要件を満たさなければなりません。組織内でのデータの民主化には、ガバナンスが不可欠です。
さらに、人工知能(AI)や機械学習(ML)を臨床現場に導入する場合には、優れたモデルガバナンスが必要となります。しかし、組織の多くは、データサイエンスのワークフロー用にデータウェアハウスと断絶された別のプラットフォームを使用しています。これは、AI を活用したアプリケーションにおけるデータの信頼性と再現性に大きな問題を引き起こします。
ETL を実行する

レイクハウスでヘルスケアデータの可能性を最大化
レイクハウスアーキテクチャは、クラウドデータレイクの低コスト、スケーラビリティ、柔軟性と、データウェアハウスの性能、ガバナンスを兼ねそろえたモダンデータアーキテクチャであり、ヘルスケア・ライフサイエンスの組織が信頼性と再現性の課題を解決することを支援します。組織では、レイクハウスを用いて、あらゆるタイプのデータを格納でき、オープンな環境で、あらゆる分析、機械学習を実�行できます。
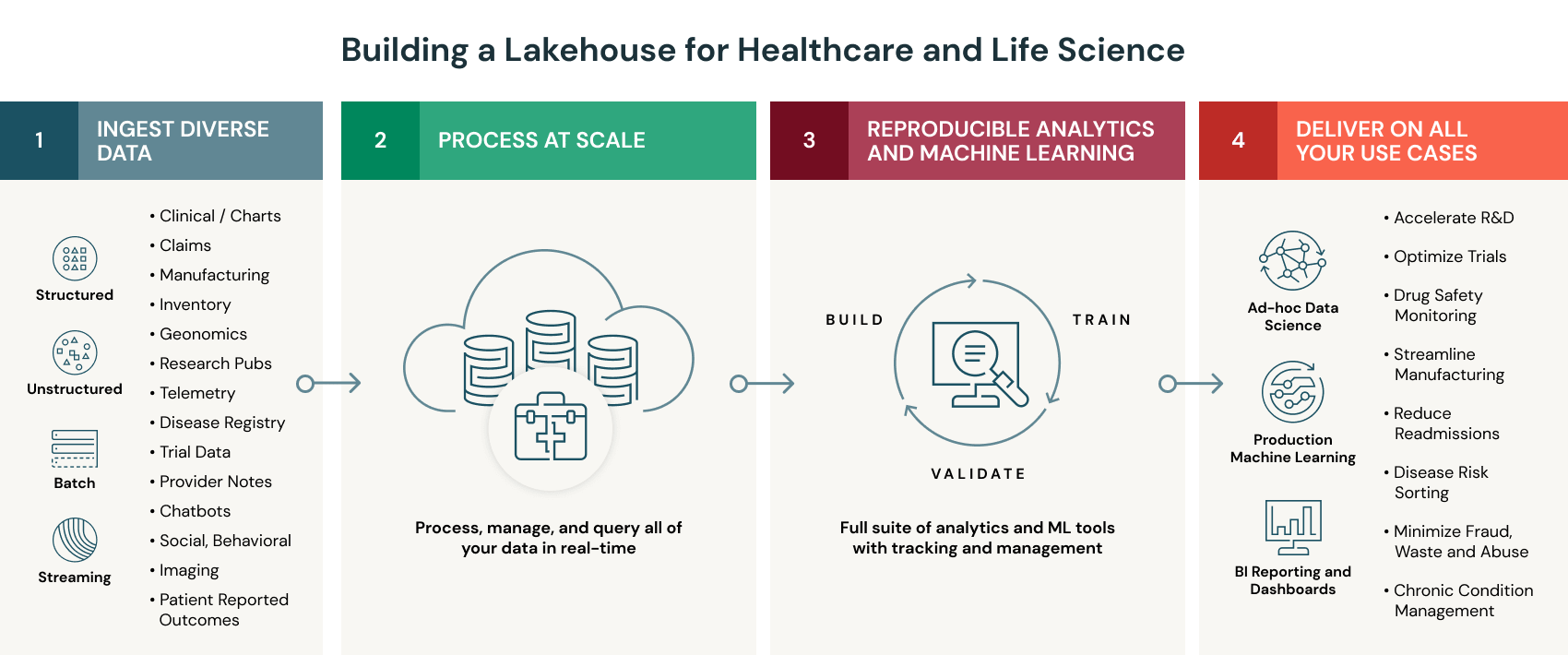
レイクハウスは、ヘルスケア・ライフサイエンスの組織に次のようなメリットをもたらします。
- あらゆるヘルスケアデータを大規模に整理:Databricks のレイクハウスプラットフォームのコアは、オープンソースのデータ管理レイヤーである Delta Lake であり、任意のデータレイクに信頼性と性能をもたらします。Delta Lakeは、従来型のデータウェアハウスとは異なり、あらゆる構造化・非構造化データをサポートします。Databricksでは、電子医療記録やゲノミクスなどのドメイン固有のデータタイプに対応したコネクタを開発し、ヘルスケアデータの取り込みを容易にしています。これらのコネクタでは、クイックスタートのソリューションアクセラレータに業界標準のデータモデルがパッケージされています。さらに、Delta Lake には、データのキャッシングやインデックス作成用にビルトインの最適化機能が備えられており、データの処理速度は著しく上がっています。これらの機能により、チームは全ての未加工データを一元管理でき、患者のヘルスに関する全体像を把握できます。
- 患者分析と AI を最大活用:レイクハウスにデータが一元化されることで、チームは、データに対して直接、患者分析の実施、予測モデルの構築ができるようになります。Databricks は、分析および AI ツールを備え、SQL、R、Python、Scala などの幅広いプログラミング言語をサポートするコラボレーティブなワークスペースを提供し、このようなケイパビリティを可能にします。データサイエンティスト、データエンジニア、医療インフォマティシストなど、さまざまなユーザーグループがコラボレーションをしながら、ヘルスケアデータの分析、モデル構築、可視化を行うことができます。
- 患者に関する知見をリアルタイムで提供:レイクハウスは、ストリーミング、バッチデータに対する統合アーキテクチャを提供します。2 つの異なるアーキテクチャを管理する必要はなく、信頼性の問題で頭を抱えることもありません。さらに、Databricks 上でレイクハウスアーキテクチャを運用することで、企業はワークロードに応じて自動的にスケールする、クラウドネイティブなプラットフォームにアクセスできるようになります。これにより、ストリーミングデータの取り込み、ペタバイト規模の履歴データとの組み合わせが容易になり、集団規模でのニアリアルタイムの知見を抽出できます。
- データ品質とコンプライアンスを提供:レイクハウスには、スキーマ強制、監査、バージョン管理、高粒度のアクセス制御など、従来のデータレイクにはない機能が備わっており、データの信頼性を高めています。レイクハウスによる重要なメリッ��トは、同一で信頼性の高いデータソースに、分析と機械学習の両方を実行できることです。加えて、Databricks は機械学習モデルのトラッキングや管理機能を提供し、チームが環境間で結果を再現することを容易にしており、コンプライアンス基準を満たすサポートをしています。これらの機能は全て、HIPAA 準拠の分析環境で提供されます。
レイクハウスは、ヘルスケア・ライフサイエンスデータの管理において、最適なアーキテクチャです。このアーキテクチャと Databricks の機能の相乗効果により、組織は、創薬や慢性疾患管理プログラムなど、極めてインパクトのある幅広いユースケースへの対応を支援できるようになります。
ヘルスケア・ライフサイエンスに特化したレイクハウスの構築を始めるには
Databricks では、ヘルスケア・ライフサイエンスの組織が特定のニーズにあわせてレイクハウスの構築ができるように、一連のソリューションアクセラレータを提供しています。ソリューションアクセラレータには、Databricks Notebook にあるサンプルデータ、事前構築されたコード、ステップごとの説明が含まれています。
- 新しいソリューションアクセラレータ:リアルワールドエビデンスのためのレイクハウス
リアルワールドデータは、製薬会社に臨床試験外の患者の健康状態や薬効に関する新たな知見を提供します。このアクセラレータでは、Databricks 上にリアルワールドエビデンスのレイクハウスを構築できます。患者集団に対するサンプルの EHR データの取り込みから、OMOP 共通データモデルを用いたデータの構造化、薬剤の処方パターンの調査まで、��大規模な分析を実行する方法を紹介します。
リアルワールドエビデンスのレイクハウス構築に関する Notebook はこちらからダウンロード可能です。
- 近日リリース:集団医学のためのレイクハウス
ヘルスケアのペイヤーと医療提供者は、より多くの情報に基づいた意思決定を可能にする、患者のリアルタイムの知見を必要としています。このアクセラレータでは、Databricks 上で HL7 ストリーミングデータを容易に取り込み、患者の疾病リスクを予測するようなユースケースに対する優れた機械学習モデルを構築する方法を紹介します。