アシュリオン社、レイクハウスでビッグデータのための ETL 導入 – データマート設計など
この記事は、アシュリオン(Asurion)社エンジニアリング部門シニアディレクター Tomasz Magdanski 氏による特別寄稿によるものです。
アシュリオン(Asurion)社では、デ�バイスの保険やインストール、修理、交換、24 時間 365 日のサポートの提供を通じて、お客様がセキュアに、かつ快適に最新テクノロジーを利用できるよう支援しています。1 万人のエキスパートで構成されるサポートチームが、世界中の約 3 億のお客様の日々のニーズに電話やオンライン、対面で対応しています。サポート内容は、スマートフォンの即日交換、快適なストリーミングや接続を可能にするための技術的な問題の解決など多岐に及びます。
アシュリオン社では、種類や購入元にかかわらず、テクノロジーに常にアクセスできる環境、テクノロジーを最大限に活用できる環境をお客様に提供できるよう努めています。
レイクハウスで大規模 ETL を導入した背景と課題
アシュリオン社のエンタープライズデータサービスチームでは、全組織から 3,500 以上のデータ資産を収集し、全てのデータをクリーニング、結合、分析、強化、活用して、データ製品を作成できる単一の場所を提供することを目指していました。
これまで利用していたデータプラットフォームは、主に従来のデータベースやデータウェアハウスソリューションの上に構築されていたため、コンピューティングとストレージが分離されておらず、スケーリングやコストの面で課題がありました。増え続けるビッグデータ、多様なデータタイプ(構造化データベーステーブル、各種 API、データストリームなど)への対応、低レイテンシと高速化の実現が求められ、プラットフォームエンジニアリングチームは、エコシステム全体を Apache Spark™ と Delta Lake に移行し、レイクハウスアーキテクチャを新たな基盤とすることを検討し始めました。
以前のデータプラットフォームはラムダアーキテクチャがベースであり、次のような解決困難な問題がありました。
- データの重複と同期。
- ロジックの重複。バッチとスピードレイヤーで異なる技術を使用する場合が多い。
- 遅延データへの対処方法が統一されていない。
- トランザクションレイヤーがないためにデータの再処理が難しく、再書き込みによる更新や削除に極めて厳密なオーケストレーションが必要。
- データへのアクセス試行の際に、プラットフォームのメンテナンスによりダウンタイムが発生する。
ビッグデータセットに対して従来の ETL(抽出、変換、格納)ツールを使用すると、処理頻度が大幅に制限されました。技術スタックも膨大で複雑でした。
アシュリオン(Asurion)社のレガシーデータプラットフォームでは、8,000 以上のテーブル、10,000 件以上のビュー、2,000 件以上のレポート、2,500 以上のダッシュボードが処理されており、極めて大規模な運用が行われていました。データの取得ソースも、データベースの CDC フィード、API、フラットファイル、Kinesis、Kafka、SNS、SQS からのストリームなど、さまざまでした。また、多くの複雑な依存関係を持つ数百ものテーブルと、約 600のデータマートを組み合わせたデータウェアハウス(DWH)が含まれていました。そのため、新たに導入するレイクハウ�スでは、これらビッグデータのユースケースを全て解決しダウンタイムを削減、単一のプラットフォームに完全に統合する必要がありました。ビッグデータ処理のプロセスを改善した事例を以下でご紹介します。
Databricks 101: 実践入門

Databricks のレイクハウスソリューション
レイクハウスアーキテクチャは、バッチレイヤーおよびスピードレイヤーが排除され、ほぼリアルタイムのレイテンシが実現します。また、多様なデータフォーマットと言語のサポートや、単一エコシステムに統合された技術スタックにより、データプラットフォームがシンプルになります。
プラットフォームのスケーラビリティを確保かつダウンタイムを削減し、今後の開発ライフサイクルの効率化を図るため、初期設計段階ではプラットフォームの脆弱性と硬直性の低減に注力しました。
プラットフォームの脆弱性は、エコシステムのある部分での変化が別の部分の機能を損なわれる場合に発生する可能性が高く、密接に結合したシステムでよく見られます。プラットフォームの硬直性とは、変化を受け入れる際のプラットフォームの抵抗力のことです。例えば、レポートに新しいカラムを追加するためには、多くのジョブやテーブルを変更しなければならず、変更のライフサイクルが長く、大きくなり、エラーやダウンタイムが発生しやすくなります。Databricks のレイクハウスプラットフォームにより、基礎となるコードベースのアーキテクチャと設計に関するアプローチがシンプルになりました。従来の ETL から Delta テーブル間のストリーミングデータパイプラインまでのデータ移動に対する統一されたアプローチが可能になりました。
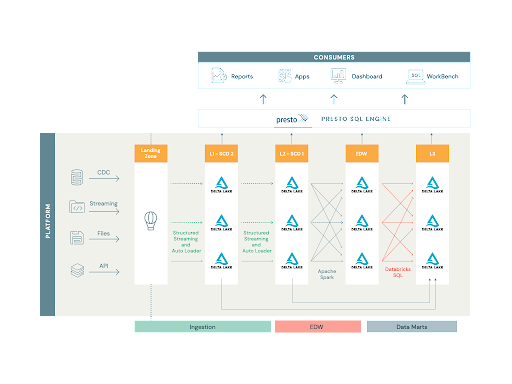
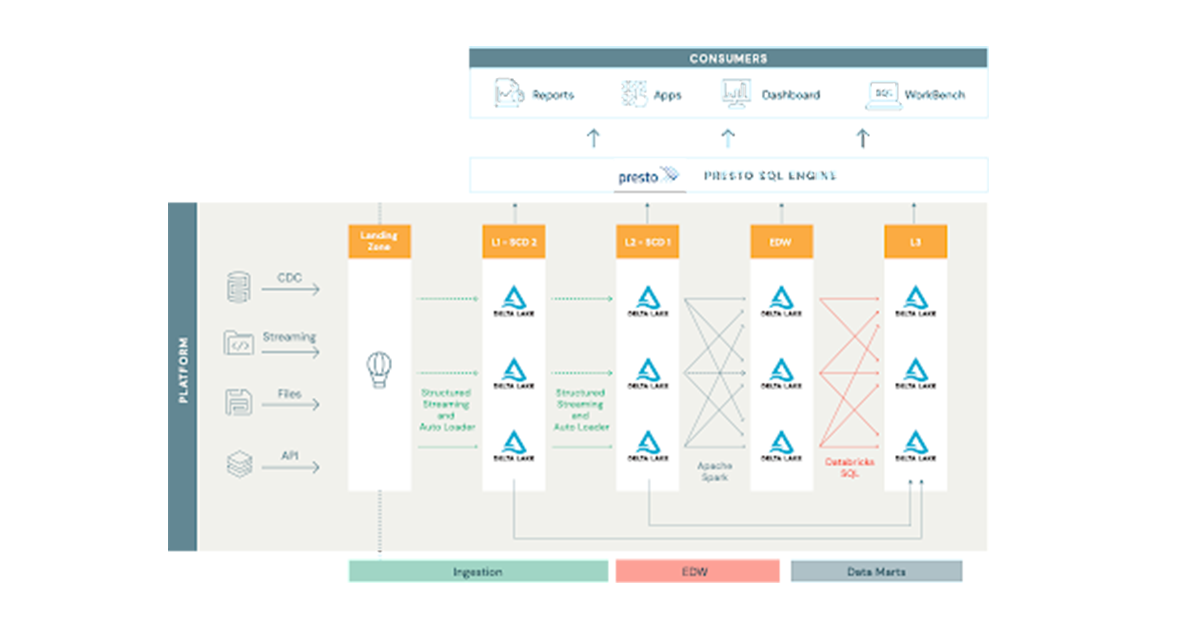
ETL ジョブの設計
以前のバージョンのプラットフォームでは、取り込まれた膨大な数のテーブルにそれぞれ独自の ETL マッピングがあったため、それらの管理と変更サイクルは柔軟に対応できませんでした。新しいアーキテクチャの目標は、柔軟性を備えたジョブを作成し、単�一のジョブを異なる設定で何度も実行できるようにすることでした。この目標を達成すべく、アシュリオン社では、Spark 構造化ストリーミングを採用しました。Spark 構造化ストリーミングでは「厳密に 1 回」と「最低 1 回」のセマンティクスが提供されており、オートローダーを使用することで各ジョブの状態管理が大幅にシンプルになりました。しかし、3,500 以上の Spark ジョブが個別に存在すると、必然的に ETL マッピングが 3,500 ある状態と同じになってしまいます。この ETL ジョブの設計に関する問題を回避するために、Scala と基本的なオブジェクト指向プログラミングにより、Spark を中心としたフレームワークを構築しました。(補足:このソリューションの導入後、Databricks のプラットフォームに Delta Live Tables が導入され、ETL プロセスが大幅に効率化されました。)
さらに、読み込み、変換、書き込み用の豊富なツールセットと、ランタイムでの依存性の挿入を介して詳細を受け入れるジョブクラスを作成しました。このソリューションにより、取り込みジョブを構成して Kafka、Parquet、JSON、Kinesis、SQS からデータフレームに読み込むことが可能になります。また、一般的な変換セットを適用した後に Spark 構造化ストリーミングの foreachBatch API 内で適用される手順を挿入し、Delta テーブルとしてデータを永続化できます。
ETL ジョブのスケジューリング
Databricks では、エフェメラルクラスタを使用した構造化ストリーミングジョブの実行を推奨していますが、ワークスペースごとの同時実行ジョブは 1,000 件までという制限があります。仮にその制限がなかったとしても、1 つのマスターノードと 2 つのワーカーノードで最小クラスタを構成する場合には、各ジョブに 3 つのノードが存在することになり、ノードが合計で 10,000 以上になります。これらはストリーミングジョブであるため、クラスタが常に稼働していなければなりません。このような制約の中で、管理上のオーバーヘッドとコストのバランスを取るためのソリューションを考案する必要がありました。
そこで、ソースでのテーブルの更新頻度に応じて、テーブルを分割してジョブグループにまとめ、それぞれのエフェメラルノートブックに割り当てました。
ノートブックが構成データベースを読み込み、割り当てられたグループに属するジョブを全て収集して、エフェメラルクラスタ上で並列実行します。処理を高速化するために Scala の並列コレクションを使用しており、ドライバーノードのコア数までジョブを並列実行することが可能です。一度に 16 または 32 のジョブが実行され、異なるジョブで異なる量のデータを処理することから、クラスタの CPU を均等かつフルに使用できます。この設定により、25 のノードを備えた 1 つのクラスタ上で最大 1,000 の低速変化テーブルを実行し、foreachBatch API 内でブロンズレイヤーやシルバーレイヤーに追加やマージできるようになりました。
Databricks SQL によるデータマートの設計
アシュリオン社のアプリケーションには、ビジネスユーザーが SQL ベースのデータ変換を定義し、それをデータマートとして保存するように設計されているものがあります。アシュリオン社はベースとなる SQL を受け取り、テーブルの実行とメンテナンスを行います。このアプリケーションは、何も実行されていなくとも 24時間 365日利用可能でなければなりません。私たちは、Databricks のソリューションに不満はありませんでしたが、アイドル状態のコンピューティングに対して、双方向を前提とするクラスタの料金を支払うことには抵抗がありました。そこで登場したのが Databricks SQL です。このソリューションでは、SQL エンドポイントは手頃な価格帯を提供し、ユーザー向けの SQL アプリケーションを対象とした容易な JDBC 接続も利用できるようになっています。現在、アシュリオン社では 600 個のデータマートを設計、保持しており、レイクハウスの本番環境ではさらにデータマートの数は増加しています。
まとめ
アシュリオン(Asurion)社のエンジニアリングチームは、Spark 構造化ストリーミング、Delta Lake、オートローダーなどのレイクハウスアーキテクチャを大規模に導入しました。今後のブログ記事で、ニーズに合わせてソリューションを拡張する際にどのような問題が発生し、またそれらをどのように解決したかをご紹介する予定です。