Part 1:Databricks Notebook と Azure DevOps で Databricks に CI/CD を実装
によって マイケル・シュテルマ 、 Piotr Majer による投稿
ブログ内に掲載されているコードの詳細は、こちらからご覧ください。
このブログは、エンドツーエンドの MLOps ソリューションを Databricks Notebook と Repos API を使用して設定、構築する方法を解説するブログシリーズの Part 1 です。今回は、Notebook をベースとした Databricks における CI/CD(継続的インテグレーション/継続的デリバリ)フレームワークについて解説します。継続的インテグレーション(CI)は Microsoft Azure DevOps のエコシステムと、継続的デリバリ(CD)は Repos API と連携します。Part 2 では、Repos API 機能を活用して、Databricks 上に完全な CI/CD ライフサイクルを実装し、本格的な MLOps ソリューションに拡張する方法をご紹介します。
Databricks Repos による CI/CD
Databricks Repos と Repos API の新機能により、MLOps アプローチを支えるバージョン管理、テスト、パイプラインにおける全ての重要な側面をカバーできるようになりました。Databricks Repos は、Databricks に Git リポジトリ全体のクローンを作成できます。また、Repos API を使用すると、最初に Git リポジトリのクローンを作成して必要なブランチをチェックアウトすることで、このプロセスを自動化できます。機械学習(ML)の実務者は、IDE(統合開発環境)でよく知られているリポジトリ構造を使用してプロジェクトを構築し、モジュールの実装にノートブックや .py ファイルを使用するようになりました(Databricks Repos における任意のファイル形式のサポートは、ロードマップで計画されています)。これにより、Github、Gitlab、Azure Repos などの任意のツールでプロジェクト全体のバージョン管理を行い、一般的な CI/CD パイプラインと連携ができます。Databricks の Repos API を使用すると、リポジトリ(Git プロジェクトは、Databricks でリポジトリとしてチェックアウトされます)を特定の Git ブランチの最新バージョンに更新できます。
チームは、開発において従来の Git フローや GitHub フローに従うことができ、Git リポジトリ全体を Databricks Repos でチェックアウトできます。ユーザーは、ノートブックだけでなく、プレーンな Python ファイルや任意のファイルをサポートするテキストファイル形式を使用、編集できます。これにより、従来のプロジェクト構造を使用して Python ファイルからモジュールをインポートし、ノートブックと組み合わせることが可能です。
- 機能ブランチで個々の機能を開発し、単体テストによるテストを実施します。(例:実装されたノートブック)
- CI/CD パイプラインが結合テストを実行する機能ブランチに変更をプッシュします。
- Azure DevOps の CI/CD パイプラインが Databricks の Repos API をトリガーして、このテストプロジェクトを最新バージョンに更新できます。
- CI/CD パイプラインが、Jobs API を介して結合テストのジョブをトリガーします。結合テストは、テスト構成でテストするパイプラインを最初に実行するシンプルなノートブックとして実装できます。これは、対応するモジュールで適切なノートブックを実行するか、Jobs API を使用して実際のジョブをトリガーすることで実行できます。
- 結果を検証し、テスト実行全体をグリーンあるいはレッドとしてマークします。
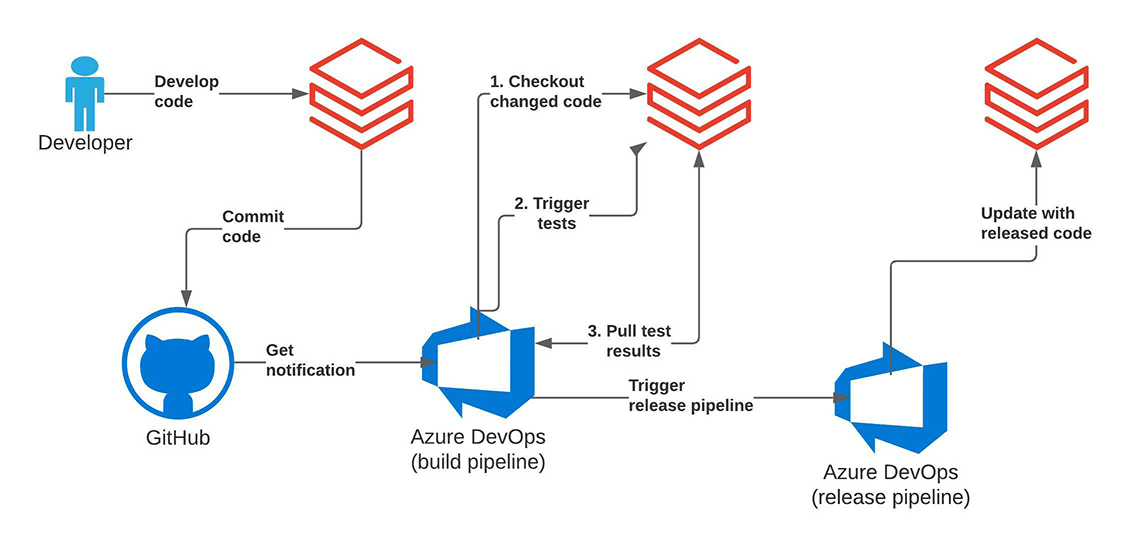
上記のアプローチをどのように実装できるのかを見てみましょう。サンプルワークフローとして、Kaggle における LendingClub 社のコンペティションで使用されたデータにフォーカスします。多くの金融機関と同様に、申請者のクレジットスコアを評価するような場合、個人の所得データを理解して予測したいと考えます。そのために、現在の職業、持ち家の有無、学歴、位置情報、婚姻歴、年齢に至るまで、申請者のさまざまな特徴量、属性を分析します。これは、過去のクレジット申請などで銀行が収集した情報であり、現在では回帰モデルのトレーニングに使用されています。
さらに、ビジネスはダイナミックに変化し、日々大量の新たな観測が実施されていることを私たちは知っています。新規データを定期的に取り込むため、モデルの再トレーニングが重要です。そのため、再トレーニングジョブの完全自動化と、継続的デプロイメントパイプライン全体にフォーカスします。新しくトレーニングされたモデルの高品質な結果と、高い予測能力を確保するために、トレーニングされた各ジョブのあとに評価ステップを追加します。ここでは、ML モデルはキュレートされたデータセットでスコアリングを行い、現在デプロイされている本番バージョンと比較されます。結果として、新規イタレーションが高い予測能力を持っている場合にのみ、モデルのプロモーションが行われます。
プロジェクトにおいては積極的に開発が行われるため、新規コードの完全自動テストやライフサイクルにおける次ステージへのプロモーションでは、プッシュ/プルリクエスト時に単体/結合テストを行うために Azure DevOps フレームワークを利用します。テストは、Azure DevOps フレームワークを通じてオーケストレーションされ、Databrikcs のプラットフォームで実行されます。これは、プロセスの CI 部分をカバーしており、コードベースの高いテストカバレッジを保証し、人間による監視を最小限に抑えます。
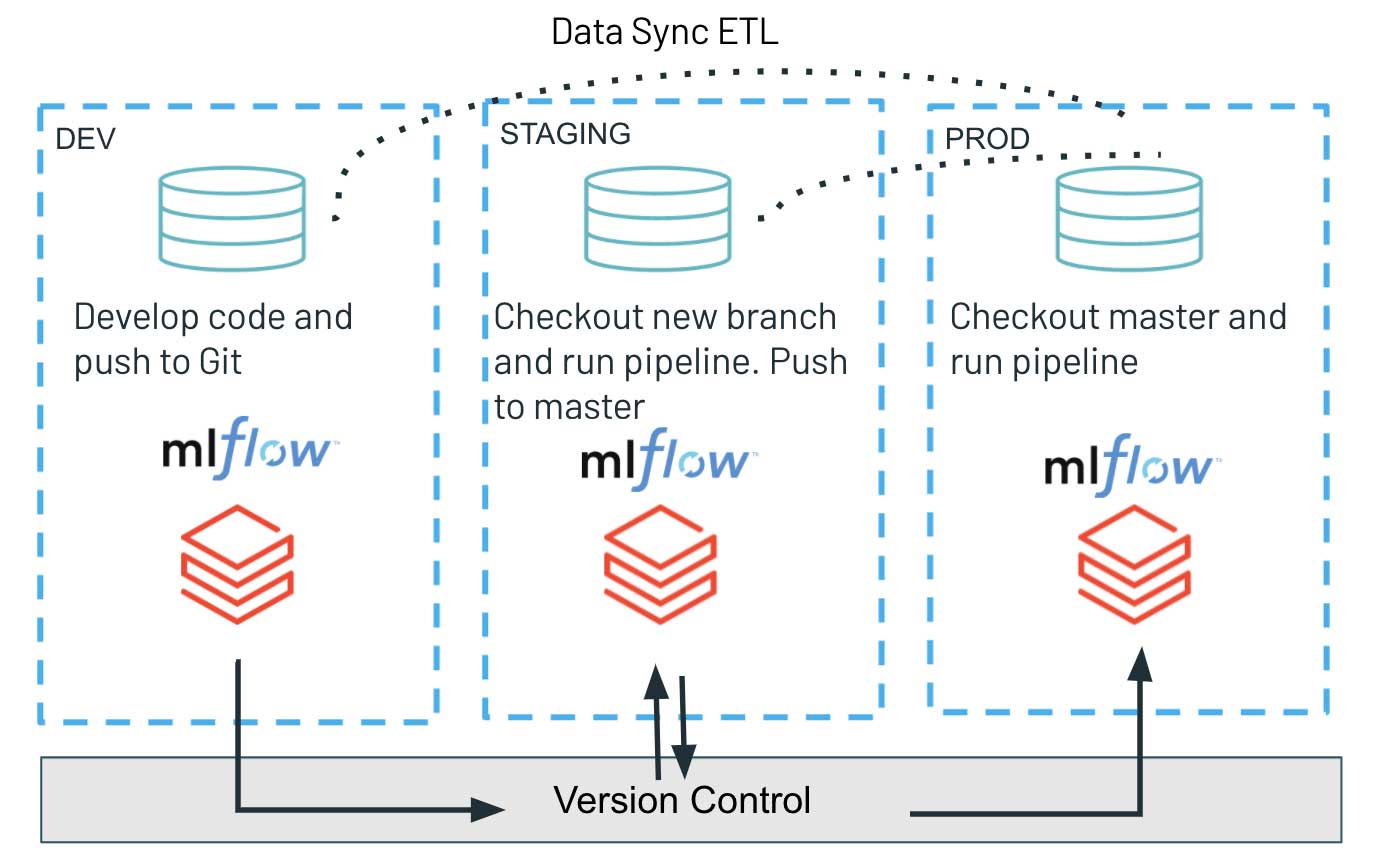
CD 部分では、Repos API のみを活用します。プログラムインターフェースを使用して Git ブランチでコードの最新バージョンをチェックアウトし、最新のスクリプトをデプロイしてワークロードを実行します。これにより、アーティファクトのデプロイメントプロセスを簡素化し、テスト済みのコードバージョンを開発環境、ステージング環境、本番環境へと簡単にプロモーションできます。さまざまな環境の完全な分離を保証するこのようなアーキテクチャは、通常、セキュリティが強化された環境で好まれます。開発環境、ステージング環境、本番環境は、バージョン管理システムのみを共有し、非常に重要な本番ワークロードとの潜在的な干渉を最小限に抑えます。同時に、開発環境ではアクセス制御がより緩和される可��能性があるため、探索的作業とイノベーションは切り離されています。
Azure DevOps と Databricks を使用した CI/CD パイプラインの実装
以下でご紹介するコードリポジトリは、Azure DevOps による CI/CD パイプラインを使用して ML プロジェクトを実装しました。このプロジェクトでは、データの準備とモデルのトレーニングにノートブックを使用しています。
これらのノートブックを Databricks 上でテストする方法を見てみましょう。Azure DevOps は、Azure で利用できる完全な CI/CD ワークフローのためのごく一般的なフレームワークです。詳細は、提供されている機能の概要、および Databricks における継続的インテグレーションをご参照ください。
ここでは、Azure DevOps パイプラインを YAML ファイルとして取り扱います。パイプラインは、Databricks Notebook をシンプルな Python ファイルとして取り扱うため、CI/CD パイプライン内で実行できます。ここで使用する Azure CI/CD パイプラインの YAML ファイルを、azure-pipelines.yml に含めています。このファイルの最も興味深い点は、Databricks の Repos API を呼び出して Databricks 上の CI/CD プロジェクトの状態を更新し、Databricks Jobs API を呼び出して結合テストのジョブ実行をトリガーすることです。これらのいずれも deploy.py スクリプト/ノートブックで開発されました。Azure DevOps パイプライン内では、次のようにして呼び出せます。
DATABRICKS_HOST と DATABRICKS_TOKEN 環境変数は、使用している Databricks のワークスペースに対して認証するため、databricks_cli パッケージに必要です。これらの変数は、Azure DevOps 変数グループを介して管理できます。
では、deploy.py スクリプトを見てみましょう。スクリプトでは、databricks_cli API を使用して Databricks の Jobs API を操作しています。最初に、API クライアントを作成する必要があります。
次に、プロジェクトのために新規に一時的なレポジトリを Databricks 上に作成し、新たに作成したリポジトリから最新バージョンを取得できます。
そして、Databricks 上で結合テストのジョブ実行をキックします。
最後に、ジョブの完了を待って結果を検証します。
複数のワークスペースでの作業
CD に Databricks の Repos API を使用することは、開発/ステージング環境と本番環境を完全に分離しようと努力しているチームにとって特に有用なものとなります。この新機能により、データチームは Databricks 上のソースコードを使用して、更新されたコードベースとワークロードのアーティファクトを複�数の環境にまたがるシンプルなコマンドインタフェースを介してデプロイできます。バージョン管理システムにおける最新コードベースをプログラムでチェックアウトできるため、タイムリーかつシンプルなリリースプロセスが保証されます。
MLOps の実践に関しては、さまざまな環境間の適切なアーキテクチャ設定について多くの重大な考慮事項があります。ここでは、完全分離のパラダイムにのみフォーカスしていますが、開発、ステージング、本番に関連づけられた複数の MLflow インスタンスも対象とします。この観点から、シリアル化されたオブジェクトは単体の共通モデルレジストリを介してロードされるため、開発環境でトレーニングされたモデルは、次のステージにはプッシュされません。デプロイされる唯一のアーティファクトは、ステージング環境でリリース、実行された新規トレーニングパイプラインのコードベースであり、その結果、新しいモデルがトレーニングされ、MLflow に登録されます。
この共有なしの原則は、本番/ステージング環境における厳格な権限管理と、開発環境におけるアクセスパターンの緩和をもって、堅牢かつ高品質なソフトウェア開発を実現します。同時に、開発インスタンスでより高い自由度を提供し、データチーム全体のイノベーションと実験を加速します。
まとめ
このブログでは、ノートブックベースのプロジェクトを使用した Databricks における CI/CD パイプラインのエンドツーエンドのアプローチについて解説しました。このワークフローは Repos API 機能をベースとしており、データチームがプロジェクトをより実用的な方法で構造化およびバージョン管理できるようにするだけでなく、CI/CD ツールの実装と実行を劇的に簡素化します。全ての運用環境が完全に分離され、ML を用いた本番ワークロードの高度なセキュリティを確保するアーキテクチャをご紹介しました。
CI/CD パイプラインは、選択したフレームワークを利用して Databricks のレイクハウスプラットフォームとスムーズに統合され、コードの実行とインフラストラクチャのプロビジョニングをエンドツーエンドでトリガーします。Repos API は、プロジェクトライフサイクルのバージョン管理、コードの構造化、開発部分だけでなく、継続的デリバリも大幅に簡素化し、環境間で本番アーティファクトとコードをデプロイできるようにします。これは、Databricks の全体的な効率性とスケーラビリティを高め、ソフトウェア開発者のエクスペリエンスを大幅に向上させる重要な改善です。
ブログ内に掲載されているコードの詳細は、こちらからご覧ください。
参考文献:
- https://www.databricks.com/blog/2021/06/23/need-for-data-centric-ml-platforms.html
- 機械学習の継続的デリバリ マーティン・ファウラー(Martin Fowler) https://martinfowler.com/articles/cd4ml.html
- MLOps の概要 https://www.kdnuggets.com/2021/03/overview-mlops.htm
Azure DevOps の紹介 https://azure.microsoft.com/en-us/blog/introducing-azure-devops/ - Azure DevOps を使用した Azure Databricks での継続的インテグレーションとデリバリ https://docs.microsoft.com/ja-jp/azure/databricks/dev-tools/ci-cd/ci-cd-azure-devops
- Kaggle における LendingClub 社のデータセット https://www.kaggle.com/wordsforthewise/lending-club
- Git 統合のためのリポジトリ https://docs.databricks.com/repos.html
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。