Databricks レイクハウスプラットフォームでのデータウェアハウスのモデリングと実装
レイクハウスでの Data Vaults と Star Schemas の利用について
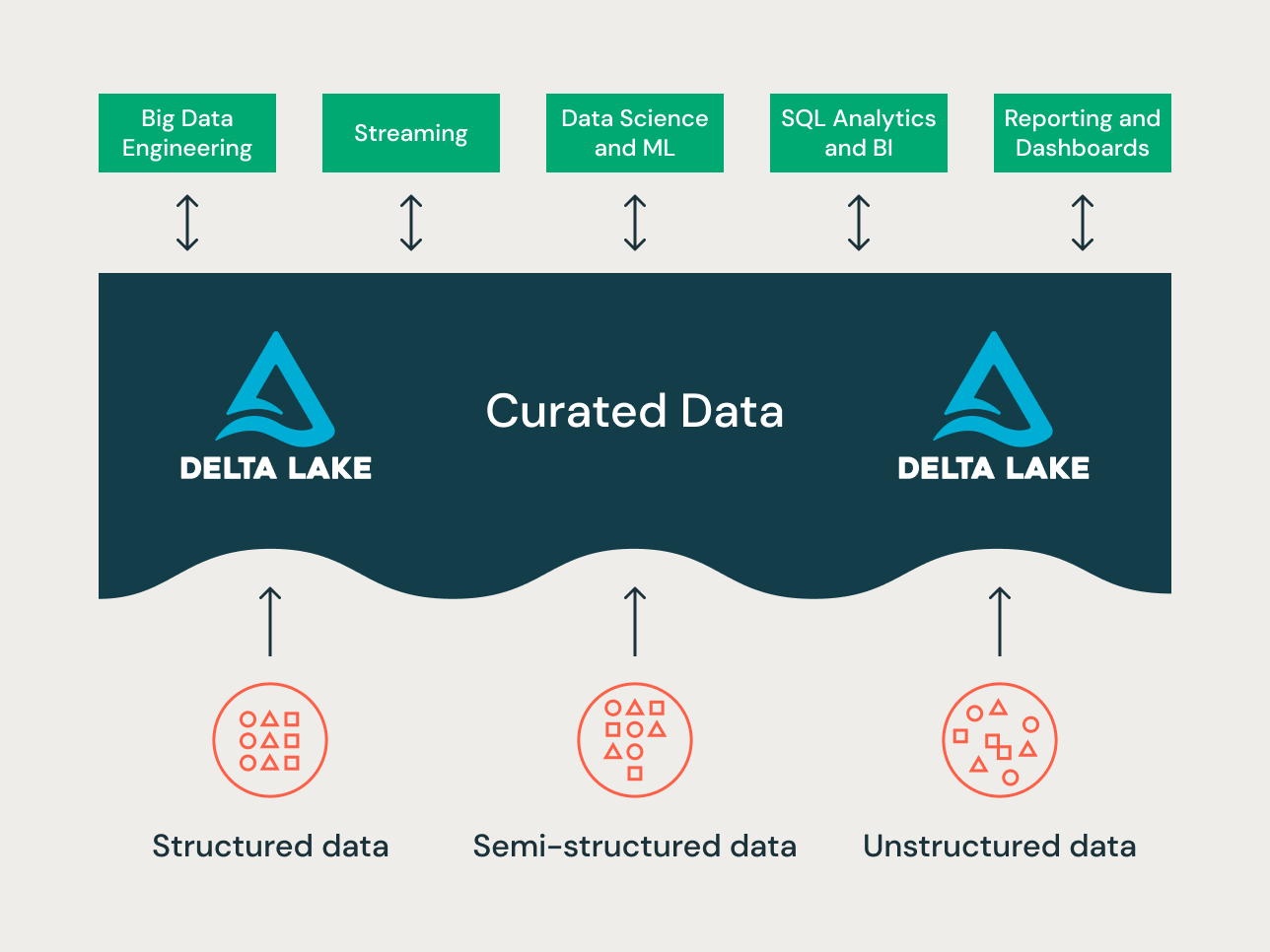
レイクハウスは、データレイクとデータウェアハウスの長所を組み合わせた、新しいデータプラットフォームパラダイムです。多くのユースケースや��データプロダクトを格納できる、大規模なエンタープライズレベルのデータプラットフォームとして設計されています。データレイクとデータウェアハウスを統合した、単一のエンタープライズデータリポジトリとして使用することができます。
- データドメイン
- リアルタイムストリーミングのユースケース
- データマート
- 異種データウェアハウス
- データサイエンス機能ストア、データサイエンスサンドボックス
- 部門別のセルフサービス型分析サンドボックス
ユースケースの多様性を考えると、レイクハウスのプロジェクトによって異なるデータ整理の原則やモデリングテクニックが適用されるかもしれません。技術的には、Databricks レイクハウスプラットフォームは、多くの異なるデータモデリング形式をサポートすることができます。この記事では、レイクハウスの Bronze/Silver/Goldデータ編成原則の実装と、異なるデータモデリング技術が各レイヤーにどのようにフィットするかを説明することを目的としています。
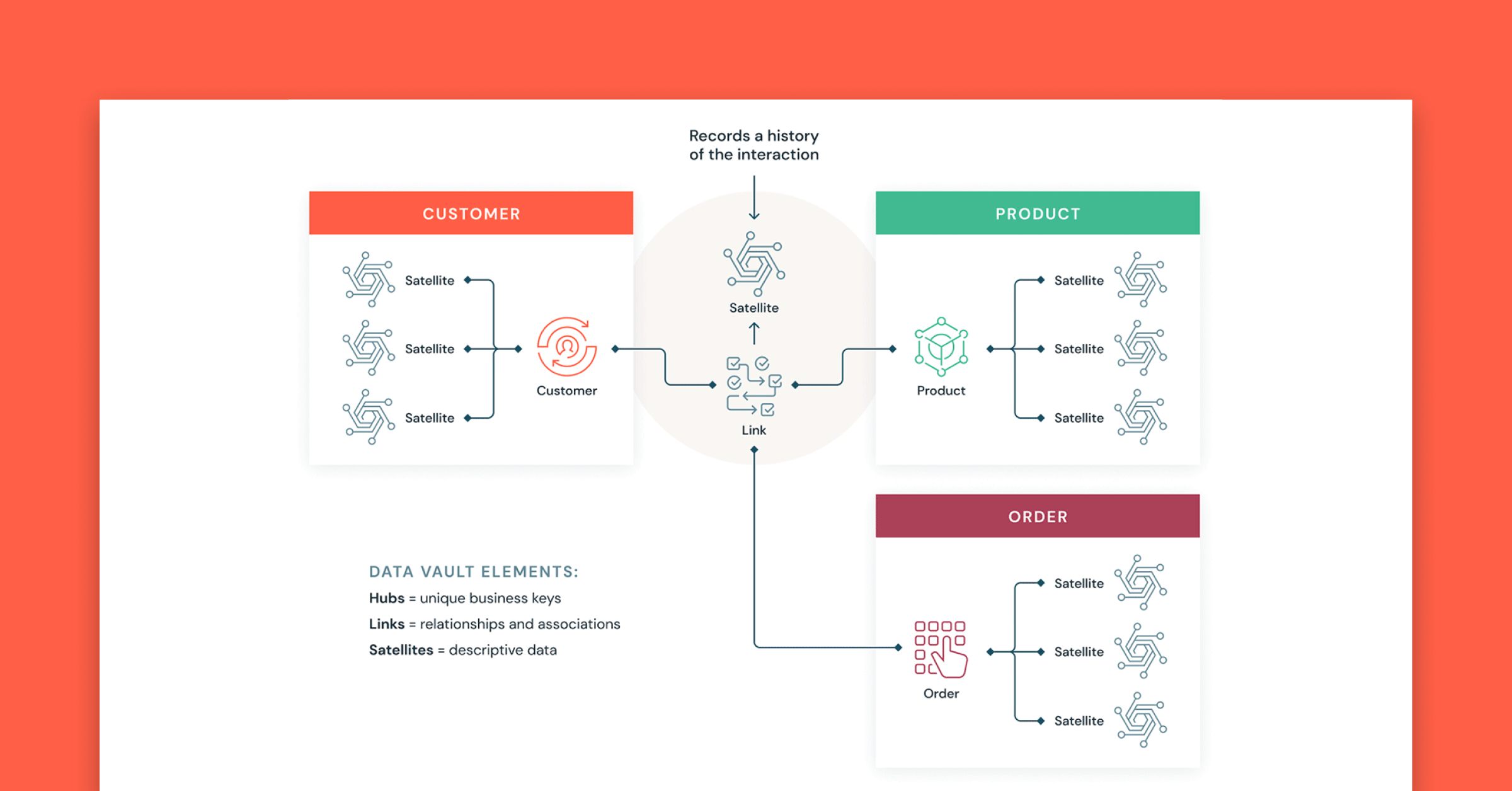
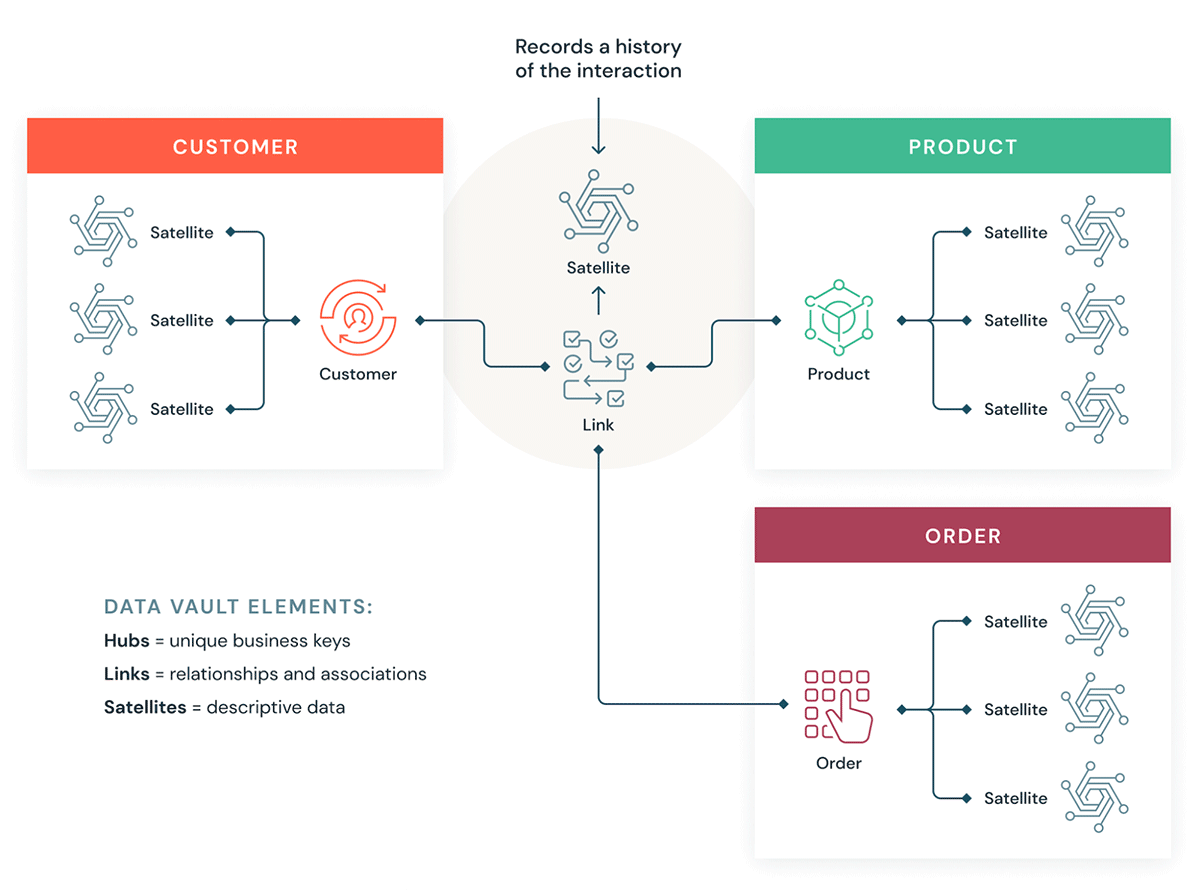
Data Vault とは
Data Vault は、Kimball や Inmon の手法に比べ、企業規模の分析用データウェアハウスを構築するために用いられる、より新しいデータモデリングのデザインパターンです。
Data Vault は、データをハブ、リンク、サテライトの 3 つのタイプに整理しています。ハブはコアのビジネスエンティティを表し、リンクはハブ間の関係を表し、サテライトはハブやリンクに関する属性を格納します。
Data Vault は、拡張性、データ統合/ETL、開発スピードが重要視されるアジャイルデータウェアハウス開発に重点を置いています。ほとんどのお客様は、ランディングゾーン、Vaultゾーン、データマートゾーンを、Databricks の組織パラダイムのブロンズ、シルバー、ゴールドレイヤーに対応させています。Data Vault のハブ、リンク、サテライトテーブルのモデリングスタイルは、通常 Databricks レイクハウスのシルバーレイヤーによく合います。
Data Vault のモデリングについては、Data Vault Alliance で詳しく説明しています。
ディメンショナルモデリングとは
次元モデリングは、データウェアハウスを分析用に最適化するために設計するボトムアップのアプローチです。次元モデルは、ビジネスデータを次元(時間や商品など)とファクト(金額や数量の取引など)に非正規化し、異なる対象領域を適合した次元で接続して、異なるファクトテーブルにナビゲートするために使用されます。
次元モデリングの最も一般的な形式�は、スタースキーマです。スタースキーマは多次元データモデルで、データを整理して理解しやすく、分析しやすく、またレポートの実行が非常に簡単で直感的にできるようにするために使用されます。Kimballスタイルのスタースキーマや次元モデルは、データウェアハウスやデータマートのプレゼンテーション層、さらにはセマンティック層やレポート層におけるゴールドスタンダードと言えます。スタースキーマの設計は、大規模なデータセットに対するクエリに最適化されています。
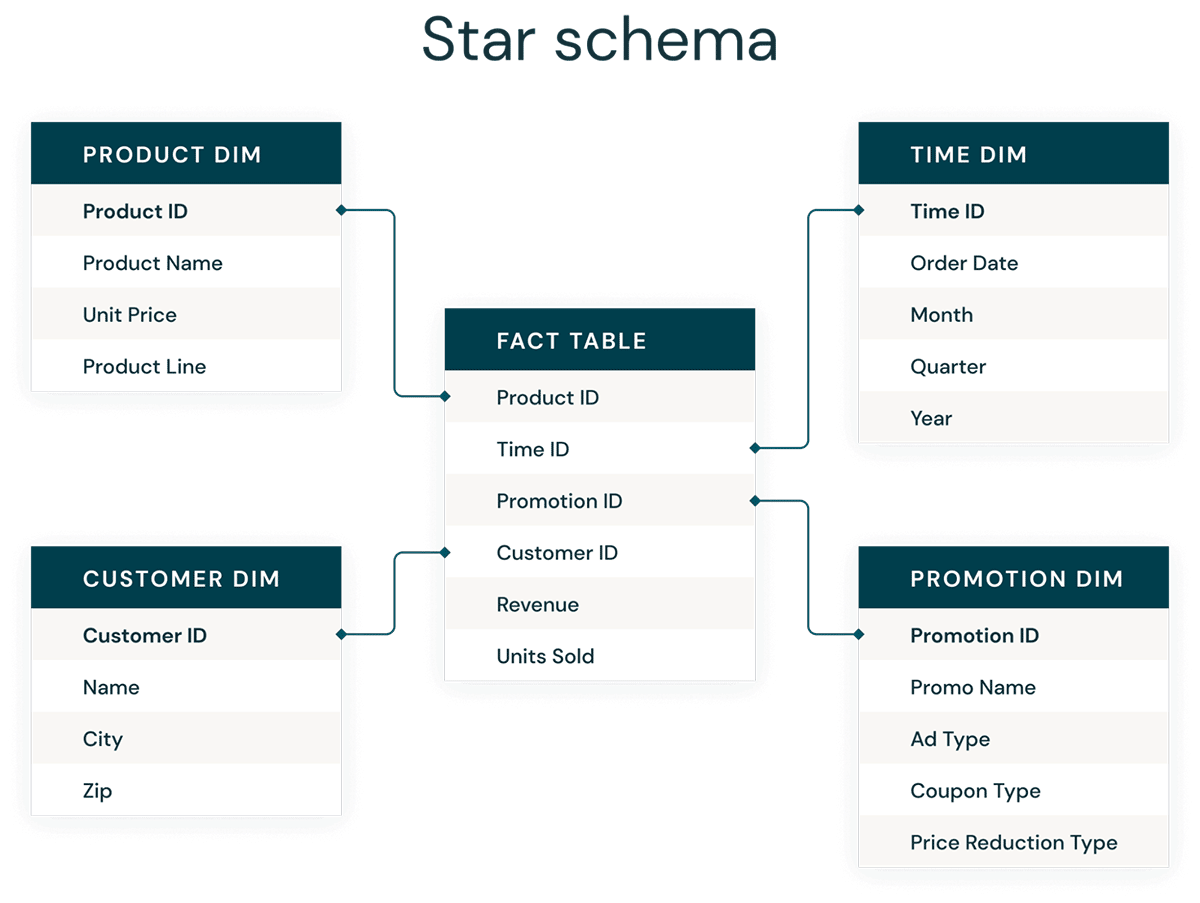
Databricks レイクハウスでは、正規化 Data Vault(書き込み最適化)と非正規化ディメンジョンモデル(読み込み最適化)の両方のデータモデリングスタイルが採用されています。Silver レイヤーの Data Vault のハブおよびサテライトは、スタースキーマのディメンジョンをロードするために使用され、Data Vault のリンクテーブルは、ディメンションモデルのファクトテーブルをロードするためのキードライビングテーブルとなります。Kimball Group のディメンジョンモデリングについて詳しくは、こちらを参照してください。
レイクハウスの各レイヤーにおけるデータ編成の原則
最新のレイクハウスは、全てを網羅したエンタープライズレベルのデータプラットフォームです。ETL、BI、データサイエンス、ストリーミングなど、さまざまなデータモデリングアプローチを必要とするあらゆるユースケースに対応する高い拡張性と性能を備えています。典型的なレイクハウスがどのように構成されているかを見てみましょう。
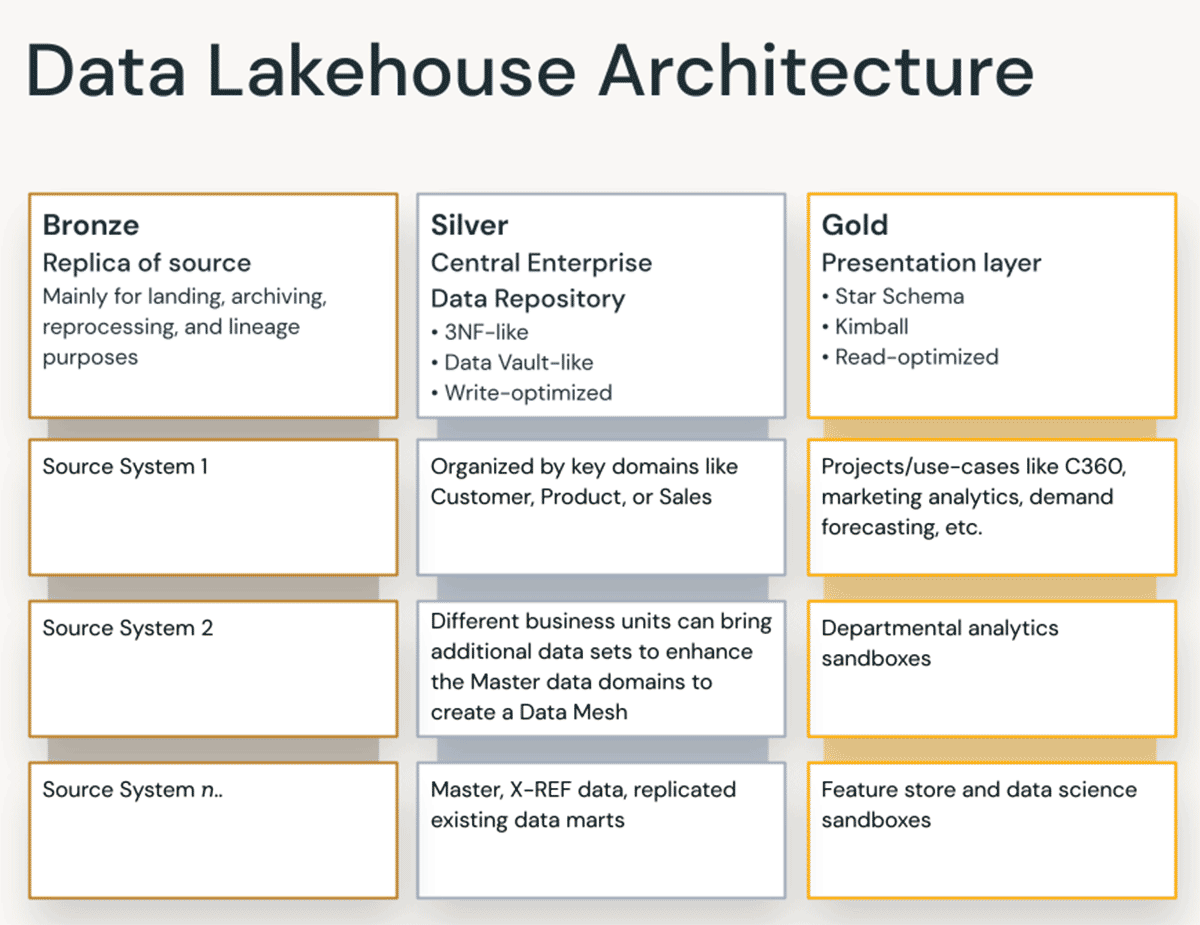
ブロンズレイヤー:ランディングゾーン
Bronze レイヤーは、ソースシステムから全てのデータを取り込む場所である。このレイヤーのテーブル構造は、ロード日時、プロセスIDなどを取得するために追加できるオプションのメタデータカラムを除けば、ソースシステムのテーブル構造に「そのまま」対応する。このレイヤーの焦点は、変更データの取得(CDC)と、ソースデータの履歴アーカイブ(コールドストレージ)、データリネージ、監査可能性、および必要に応じて再処理を提供する機能(ソースシステムからデータを再読込せずに)にあります。
多くの場合、Bronze レイヤーのデータを Delta フォーマットにしておくと、その後の ETL のための Bronze レイヤーからの読み込みが効率的になり、Bronze で CDC の変更を書き込むため�の更新ができるようになります。JSON や XML 形式のデータが届くと、元のソースデータのフォーマットでランディングし、Delta フォーマットに変更してステージングするお客様を時々見かけます。そのため、論理的な Bronze レイヤーを物理的なランディング・ステージングゾーンにするお客様もいらっしゃいます。
ランディングゾーンにオリジナルのソースデータフォーマットで生データを保存することは、ネイティブシンクとして Delta をサポートしていないインジェストツールを介してデータを取り込む場合、またはソースシステムがオブジェクトストアに直接データをダンプする場合の一貫性を保つためにも役立ちます。このパターンは、ソースが raw ファイルのランディングゾーンにデータを取り込み、Databricks オートローダがデータを Delta フォーマットのステージングレイヤーに変換するという、オートローダ取り込みフレームワークともうまく連携しています。
シルバーレイヤー:エンタープライズセントラルレポジトリ
レイクハウスのシルバー層では、ブロンズ層からのデータが照合、マージ、適合、クリーニングされ、シルバー層が全ての主要なビジネスエンティティ、概念、トランザクションの「エンタープライズビュー」を提供できるようにします。これは、エンタープライズオペレーショナルデータストア(ODS)、セントラルリポジトリ、データメッシュのデータドメイン(マスター顧客、製品、重複のないトランザクション、相互参照テーブルなど)に似ています。このエンタープライズビューは、異なるソースからのデータをまとめ、アドホックレポート、高度な分析、MLのためのセルフサービス分析を可能にします。また、部門アナリスト、データエンジニア、データサイエンティストがさらにデータプロジェクトを作成し、ゴールドレイヤーの企業および部門データプロジェクトを通じてビジネス上の問題に答えるための分析を行うためのソースとしても機能します。
レイクハウスデータエンジニアリングのパラダイムでは、従来の Extract-Transform-Load(ETL)に対して、ELT(Extract-Load-Transform)メソドロジーが採用されています。ELTアプローチとは、Silverレイヤーのロード時に最小限の、あるいは「必要十分な」変換とデータクレンジングルールのみが適用されることを意味します。プロジェクト固有の変換ルールがゴールドレイヤーで適用されるのに対して、「エンタープライズレベル」のルールは全てシルバーレイヤーで適用されます。レイクハウスにデータを取り込み、配信するためのスピードと俊敏性が優先されます。
データモデリングの観点からは、シルバーレイヤーはより 3rd-Normal Form に近いデータモデルを持ちます。Data Vaultのような書き込み可能なデータアーキテクチャとデータモデルをこのレイヤーで使用することができます。Data Vaultの手法を使用する場合、生のData VaultとBusiness Vaultの両方がレイクの論理的なシルバー層に収まり、ポイントインタイム(PIT)プレゼンテーションビューまたはマテリアライズドビューはゴールド層に表示されることになります。
ゴールドレ�イヤー:プレゼンテーションレイヤー
ゴールドレイヤーでは、ディメンションモデリングや Kimball 手法に従って、複数のデータマートやウェアハウスを構築することができます。先に述べたように、ゴールドレイヤーはレポーティング用であり、シルバーレイヤーと比較して結合を減らし、より非正規化、読み取り最適化されたデータモデルを使用します。ゴールドレイヤーのテーブルを完全に非正規化することも可能で、通常はデータサイエンティストが特徴抽出のアルゴリズムに利用するためにそのようにします。
シルバーレイヤーからゴールドレイヤーへのデータ変換の際には、「プロジェクト固有」のETLとデータ品質のルールが適用されます。データウェアハウス、データマート、あるいは顧客分析、製品/品質分析、在庫分析、顧客セグメンテーション、製品推奨、マーケティング/販売分析などのデータプロダクトなどの最終的なプレゼンテーション層は、このレイヤーで提供されます。キンブル式のスタースキーマ型データモデルやインモン式のデータマートは、このレイクハウスのゴールドレイヤーに適合します。セルフサービス分析のためのデータサイエンスラボラトリーや部門別サンドボックスも、このゴールドレイヤーに属します。
レイクハウスのデータ整理のパラダイム
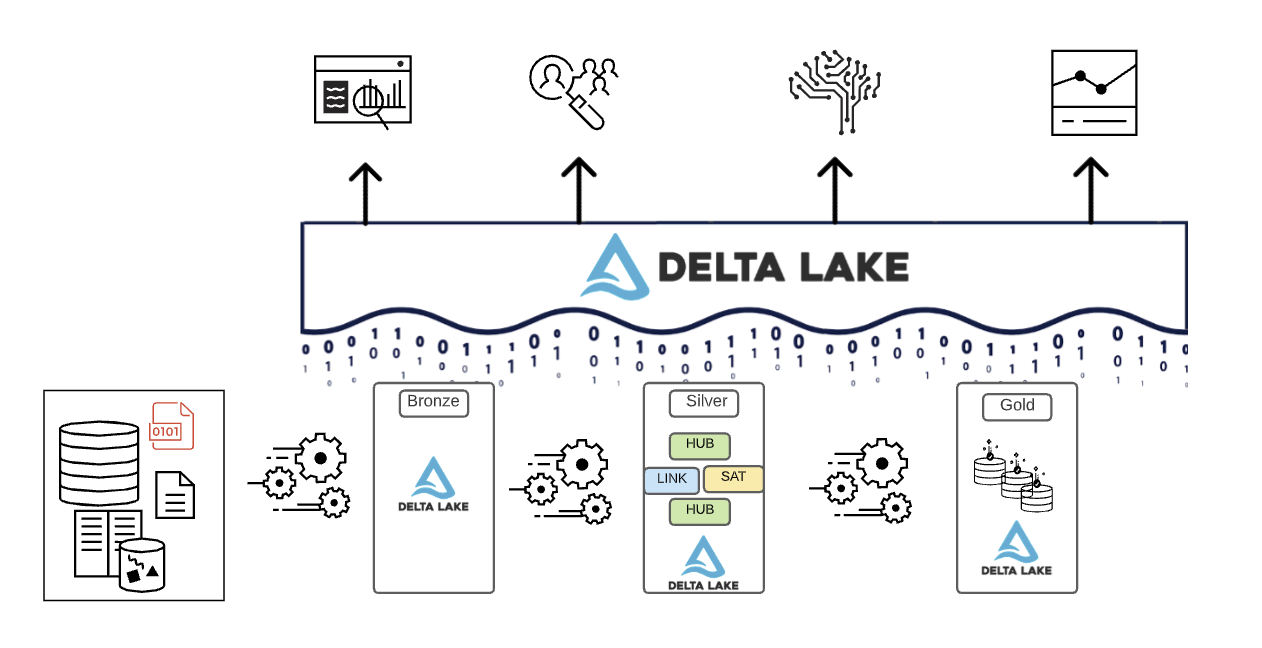
要約すると、データはレイクハウスのさまざまなレ�イヤーを通過する際にキュレーションされるということです。
- ブロンズレイヤーは、ソースシステムのデータモデルを使用します。もしデータが生のフォーマットで着地した場合、このレイヤー内で DeltaLake フォーマットに変換されます。
- シルバーレイヤーは、異なるソースからのデータをまとめ、エンタープライズビューを作成するために適合させます。通常、より正規化され、書き込みが最適化されたデータモデルを使用します。
- ゴールドレイヤーは、シルバーレイヤーよりも非正規化またはフラット化されたデータモデルを持つプレゼンテーションレイヤーで、一般的にはキンボール式のディメンションモデルやスタースキーマが使用されます。ゴールドレイヤーには、企業全体でセルフサービス分析やデータサイエンスを実現するための部門別サンドボックスやデータサイエンスサンドボックスも配置されます。これらのサンドボックスと独立した計算クラスタを提供することで、ビジネスチームがレイクハウス外でデータのコピーを独自に作成することを防ぎます。
このレイクハウスのデータ組織のアプローチは、データのサイロを壊し、チームをまとめ、適切なガバナンスのもと、1つのプラットフォームでETL、ストリーミング、BIやAIを行う権限を与えることを意図しています。中央データチームは、データモデリングプロセスがボトルネックになるのではなく、新しいセルフサービスユーザーのオンボーディングや、多くのデータプロジェクトの開発を並行してスピードアップし、組織内のイノベーションを実現する存在であるべきです。Databricks Unity Catalogは、レイクハウス上で検索と発見、ガバナンス、リネージを提供し、データガバナンスを確実に実行することができます。
Databricks SQLで Data Vaults とスタースキーマデータウェアハウスを今すぐ構築しましょう。