PySparkでのメモリプロファイリング

Original Blog : Memory Profiling in PySpark
翻訳: junichi.maruyama
PySparkのプログラムのパフォーマンスには多くの要因があります。PySparkは様々なプロファイリングツールをサポートしており、プログラムのタイトループを公開し、パフォーマンス改善の意思決定を行うことができます(詳細を見る)しかしプログラムの性能の重要な要因の1つであるメモリは、PySparkのプロファイリングでは見落とされていました。Sparkドライバ上のPySparkプログラムは、通常のPythonプロセスとしてMemory Profilerでプロファイリングできますが、Sparkエグゼキュータ上のメモリを簡単にプロファイリングする方法は存在しませんでした。
PySpark UDFは最も人気のあるPython APIの1つで、Sparkエグゼキュータによって生成されたPythonワーカーサブプロセスで実行されます。Apache Spark™エンジンの上でカスタムコードを実行することができるため強力なツールです。しかしメモリ消費量を理解せずにUDFを最適化することは困難です。PySpark UDFを最適化し、メモリ不足のエラーが発生する可能性を減らすために、PySparkのメモリプロファイラがメモリの総使用量に関する情報を提供します。これはUDFのどのコード行が最もメモリを使用しているのかを特定するものです。
エクゼキュータにメモリプロファイリングを実装することは困難です。エクゼキュータはクラスタ上に分散しているため、各エクゼキュータからメモリプロファイルを収集し、総メモリ使用量を表示するために適切に集計する必要がある。一方デバッグや刈り込みのために、メモリ消費量と各ソースコード行の間のマッピングを提供する必要があります。Databricks Runtime 12.0では、PySparkがこれらの技術的な困難を克服し、メモリプロファイリングをエクゼキュータ上で有効にしました。このブログでは、ユーザー定義関数(UDF)の概要を説明し、UDFを使ったメモリプロファイラの使い方を実演します。
User-defined Functions(UDFs) 概要
PySparkでサポートされるUDFには、大きく分けて2つのカテゴリがあります。Python UDFとPandas UDFです。
- Python UDFは、Pickleでシリアライズ/デシリアライズされたPythonオブジェクトを受け取り/返すユーザー定義のスカラー関数で、一度に1行ずつ操作します。
- Pandas UDF (a.k.a. Vectorized UDF) は、Apache Arrowでシリアライズ/デシリアライズされたpandas SeriesやDataFrameを受け取り/返すUDFで、ブロック単位で動作します。Pandas UDFは、用途別に分類されたいくつかのバリエーションがあり、特定の入力と出力のタイプがあります。Series to Series、Series to Scalar、Iterator to Iteratorです。
Pandas UDFsの実装に基づき、Pandas Function APIも用意されています。Map (例: mapInPandas) と (Co)Grouped Map (例: applyInPandas) 、そして Arrow Function API - mapInArrow です。メモリプロファイラが適用されるのは、関数がイテレータを取り込み/出力する場合を除き、上記のすべてのUDFタイプです。
メモリプロファイリングを有効にする
クラスタ上でメモリプロファイリングを有効にするには、以下のようにMemory Profilerライブラリをインストールし、Sparkの設定「spark.python.profile.memory」を「true」に設定する必要があります。
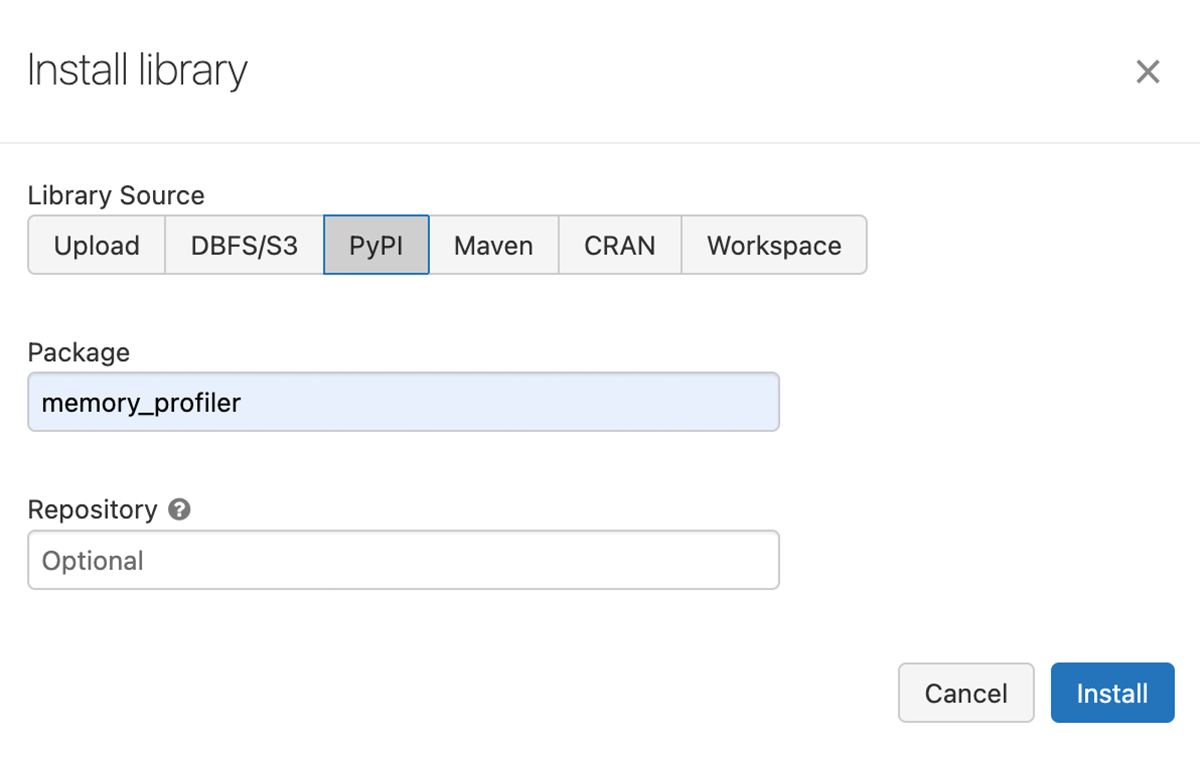
- クラスタにMemory Profilerライブラリをインストールします。
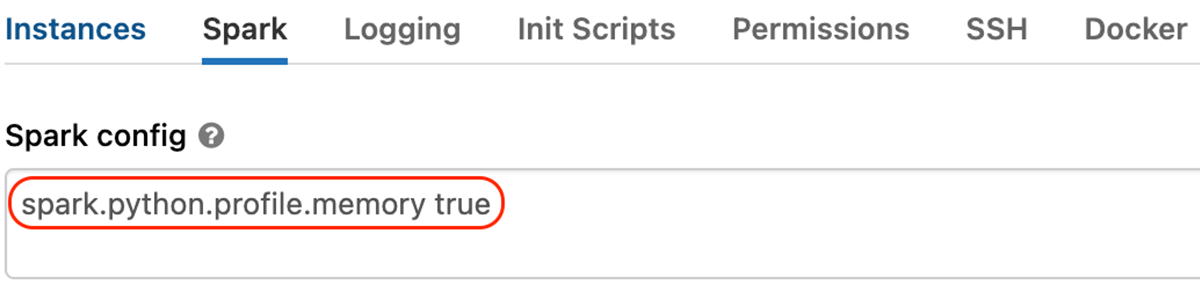
- Sparkの設定「spark.python.profile.memory」を有効化��します。
そして、UDFのメモリをプロファイルすることができます。GroupedData.applyInPandasでメモリプロファイラを説明します。
まず下図のように4,000,000行のPySpark DataFrameを生成します。その後 id列でグループ化することで、1グループ1,000,000行の4グループが生成されます。
そして、以下のように関数arith_opが定義され sdfに適用されます。
上記のコードを実行し、sc.show_profiles()を実行すると、以下の結果プロファイルが表示されます。この結果プロファイルは、sc.dump_profiles(path)によってディスクにダンプすることもできます。
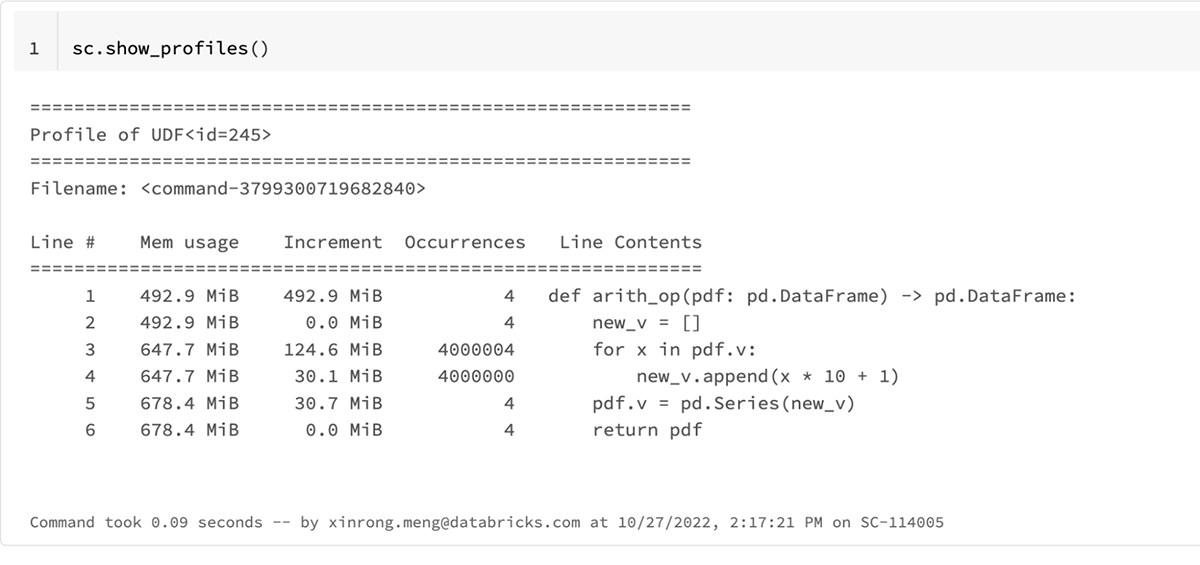
上記の結果プロファイルのUDF ID、245は、res.explain()を呼び出すことで示すことができるresの次のSparkプランのものと一致します。
sc.show_profiles()の結果プロファイルの本文では、カラムの見出しに
- Line # : プロファイルされたコードの行番号。
- Mem usage: その行が実行された後のPythonインタ�プリタのメモリ使用量
- Increment: 最後の行に対する現在の行のメモリの差分
- Occurrences: この行が実行された回数
- Line Contents: プロファイリングされたコード
結果プロファイルを見ると3行目("for x in pdf.v")が最もメモリを消費していることがわかります。この関数の総メモリ使用量は、185MiBです。
以下のようにpdf.vの反復を削除することで、よりメモリ効率の良い関数に最適化することができます。
更新された結果プロファイルは以下の通りです。
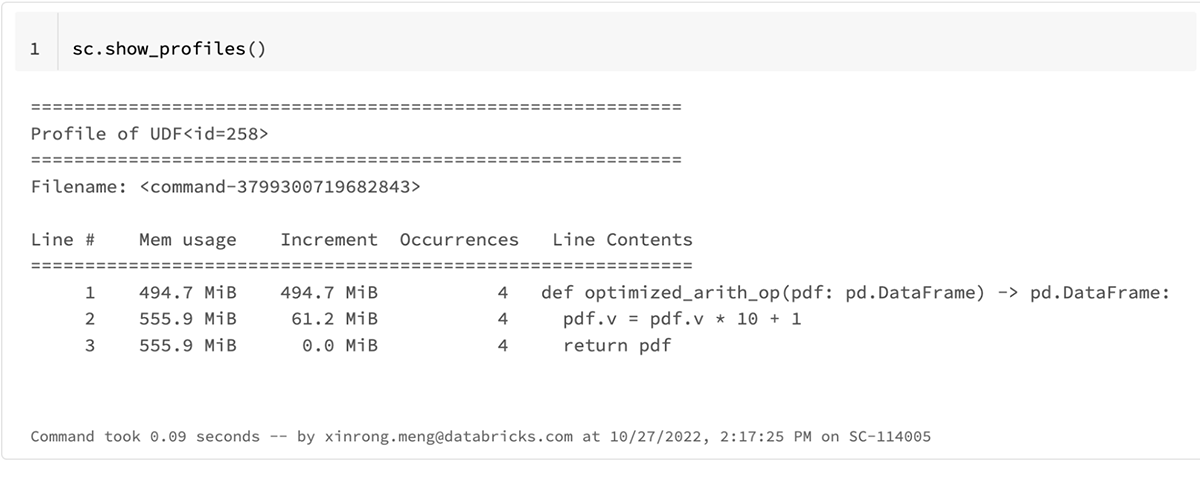
optimized_arith_opの総メモリ使用量は、2倍少ない61MiBに減少しています。
上記の例はメモリプロファイラがUDFのメモリ消費量を深く理解し、メモリのボトルネックを特定し関数をよりメモリ効率的にするのに役立つことを示しています。
Conclusion
PySparkのメモリプロファイラがMemory Profilerをベースに実装されています。Pythonワーカーから結果プロファイルを収集する際には、Spark Accumulatorsも重要な役割を果たします。メモリプロファイラでは、UDFの総メモリ使用量を計算し、どのコード行が最もメモリ使用量が多いかをピンポイントで��特定します。使い方は簡単で、Databricks Runtime 12.0.から利用できます。
さらに、PySparkメモリプロファイラをApache Spark™コミュニティにオープンソース化しました。メモリプロファイラが利用可能になるのはSpark 3.4からです。より詳細はSPARK-40281をご覧ください。

