コーニングがDatabricks LakehouseプラットフォームでエンドツーエンドのMLを構築した方法

“This blog is authored by Denis Kamotsky, Principal Software Engineer at Corning”
翻訳:Junichi Maruyama
オリジナルブログはこちら
コーニングは約200年にわたり、材料科学における世界有数のイノベーターであり続けています。これらのイノベーションには、トーマス・エジソンの電灯用の最初のガラス電球、最初の低損失光ファイバー、触媒コンバーターを可能にするセルラー基板、モバイル機器用の最初の破損防止カバーガラスなどが含まれます。コーニングでは、限界に挑戦し続けるとともに、機械学習のような破壊的技術を駆使して、より優れた製品を提供し、効率化を推進しています。
機械学習による製造工程の効率化
高品質な製品を提供することは、世界中の製造拠点に�おける重要な目標であり、MLがその目標達成にどのように貢献できるかを模索し続けています。例えば、乗用車や商用車のエアフィルターや触媒コンバーターに使用されるコーニングのセラミックを製造する工場がそうです。これらのフィルター製造のほとんどの工程はロボット化されていますが、一部の工程はまだ手作業です。特に品質検査では、高解像度の画像を撮影し、セルの凹凸を探すことで、漏れや不良部品の予兆を見つけることができる。しかし、製造環境のゴミが画像に写り込んでしまうため、偽陽性が多いことが課題です。
この問題に対処するため、私たちは撮影前に手作業でフィルターのブラッシングとブローを行いました。私たちは、どの部品をクリーニングすべきかをオペレーターに通知することで、プロセスに必要な総時間を大幅に短縮できることを発見し、機械学習が役に立ちました。私たちは、オペレーターが撮像装置内でフィルターをセットアップしている間に撮影された低解像度の画像に基づいて、フィルターがきれいか汚れているかを予測するためにMLを使用しました。この予測に基づき、オペレーターは部品をクリーニングするかどうかのシグナルを得ることができるため、最終的な高解像度画像での誤検出が減り、生産工程をより迅速に進め、高品質のフィルターを提供することができるようになりました。
このMLモデルを実行するには、低解像度画像用の2値分類器が必要でした。ここで重要なのは、工場の現場で人間のオペレーターとやりとりするため、低レイテンシーのモデルでなければならないということです。私たちのモデルを設計する際、実行にかかる時��間はわずか数ミリ秒でなければならないことはわかっていました。
以下は、私たちがどのように行ったかの内訳である
The data team
私たちは、Databricksを使ってディープラーニングのアプローチで低レイテンシーモデルを構築するために、部門横断的なチームを作ることから始めました。データサイエンティストがゼロから実験し、モデルを構築できるようにするため、私たちはまず、彼らが使用できる数千の画像を収集しました。私たちは、このすべてのデータを管理し、これらの画像にラベルを付けるためのフロントエンドアプリを導入し、データパイプラインを構築し、大規模にモデルをトレーニングしました。そして最後に、モデルのトレーニングが完了したら、世界中のコーニング環境テクノロジー工場でエッジに展開する必要がありました。
モデルの構築
Databricksは、私たちの戦略と変革の中心でした。Databricksは、シンプルで統一されたプラットフォームを提供し、私たちのデータとML作業のすべてを一元化することができるからです。モデルをトレーニングし、MLflowに登録し、すべての追加成果物(エクスポートされたフォーマットなど)を生成し、生成したベースモデルと同じ場所でそれらを追跡することができます。さらに、AWSのデータ同期を使用して、製造施設内のWindows共有から画像を収集し、プロジェクトに応じてS3バケットに格納します。画像に多くの前処理が必要な場合は、画像に変換または変換を適用し、変換された画像をバイナリカラムとしてDeltaテーブル自体に格納することもあります。レイクハウスを使うということは、それがS3上のファイルの束であろう��と、デルタテーブルのカラムであろうと、コードにとってはすべて同じに見えるということです。つまり、データにアクセスするためのプログラミングモデルは、フォーマットに関係なく同じなのだ。
次に、DatabricksのジョブAPIを使ってモデルのトレーニングを開始する。トレーニングによりモデルが生成され、HDF5ファイルとして保存されます。モデルはMLflowによって追跡され、最新バージョンとしてMLflowレジストリに登録されます。次のステップは、そのモデルの評価を実行し、得られたメトリクスをこれまでのモデルから得られた最良のメトリクスと比較することです。これらのモデルはMLflowでタグ付けされ、モデルのベストバージョンを追跡することができます。
モデルの展開
上記のステップに続いて、エキスパートは MLflow ユーザーインターフェースからログインし、トレーニングジョ ブによって生成されたすべての成果物を調査して、最適なモデルを生成します。この評価を終えると、エキスパートは最も性能の良いモデルを本番環境に導入するために前進し、エッジシステムは MLflow レジストリから MLflow API を使用してそのモデルをダウンロードすることができます。このループは、ドリフト検出の監視に再利用できるため、非常に優れている。
最終的にデプロイされたモデルは約 20 万のパラメータを持ち、90%以上の精度で動作しています。
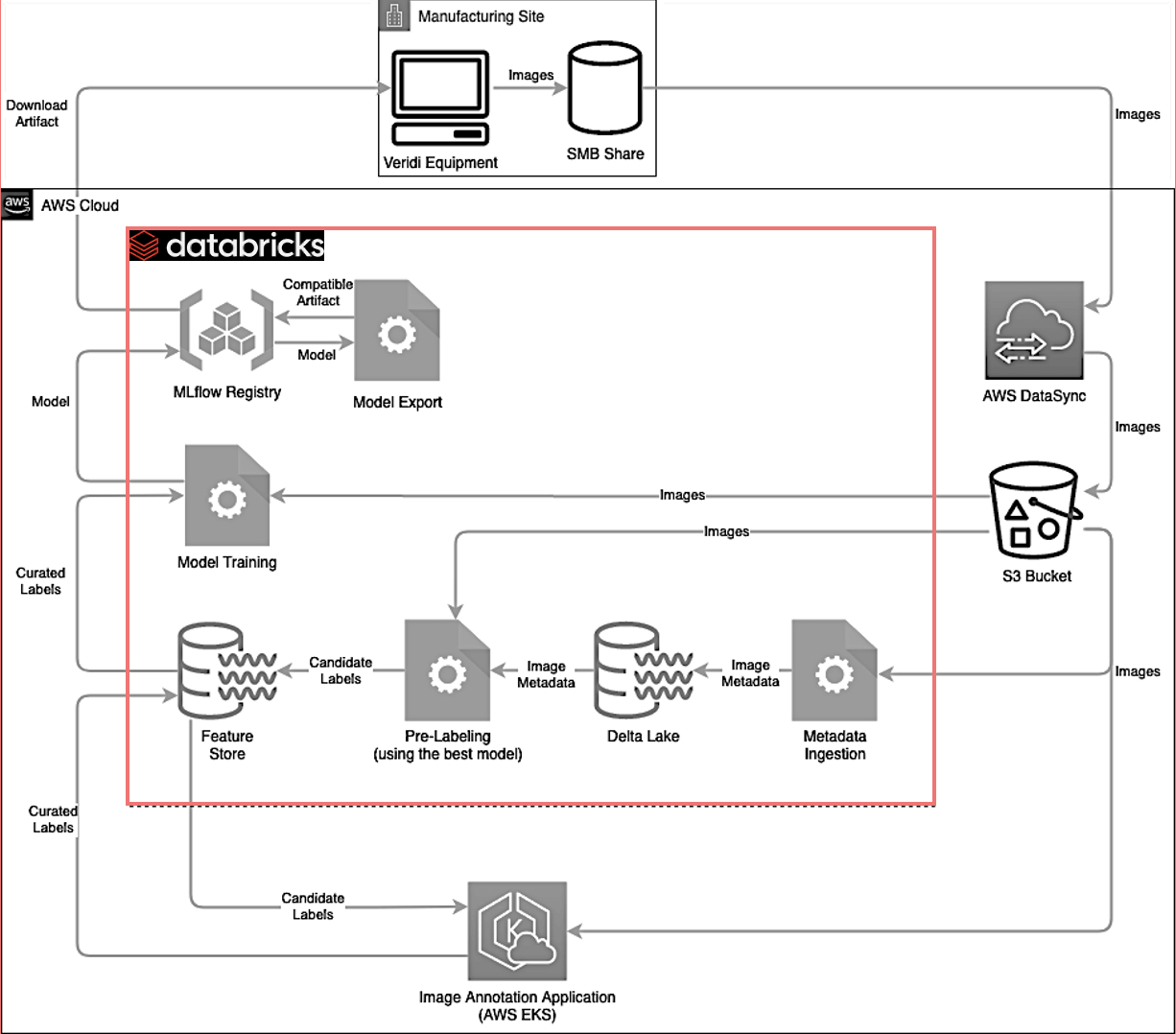
エンド・ツー・エンドのMLを実現するDatabricks
Databricksは、Python中心のデータサイエンティストやディープラーニングエンジニアのための素晴らしい開発環境であり、エンドツーエンドのMLのためのコラボレーションを可能にする。Scikit-learn、TensorFlow、PyTorchなどのPythonエコシステム全体がプリインストールされた環境がある。クラスタのプロビジョニングは非常に迅速で、ノートブック環境も充実している。ノートブックだけでなく、MLflowの実験でもチーム間のコラボレーションが容易です。
Databricksのもう1つの利点は、データサイエンティスト個人に個別のコンピューティング環境を提供できることだ。データ・サイエンティストは、自分自身にノードのクラスタを提供することができる。そのクラスターの分散性は、オープンソースのプログラミング・エンジンであるSparkによって管理され、その上に興味深いソリューションを実装することができ、JavaやScalaを超える柔軟性とオプションを提供することができる。これらの並列コンピューティング機能はすべて非常に強力で、ワークロードを複数のノードで並列化することで、高いスループットを達成することができます。Databricksでは、Databricks Academyでディープダイブクラスを提供しており、多くの例やノートブックが用意されています。
ビジネスインパクト
Databricks Lakehouse Platform上の機械学習を使用することで、私たちのビジネスでは、初年度に製造上のアップセットイベントの削減を通じて200万ドルのコスト回避を達成しました。これは、コーニング環境技術のすべての製造施設に導入されています。私たちのプロジェクトの成功は、業界におけるAIと機械学習の2022年の製造リーダーシップ協議会賞の獲得にも貢献しました。
AWS re: Inventのこのセッションの詳細ビデオはこちらからご覧いただけます:
AWS re:Invent 2022 - How Corning built E2E ML on a data lakehouse platform with Databricks (PRT321)
Databricksの投稿を見逃さないようにしましょう
次は何ですか?


ニュース
December 24, 2024/2分で読めます