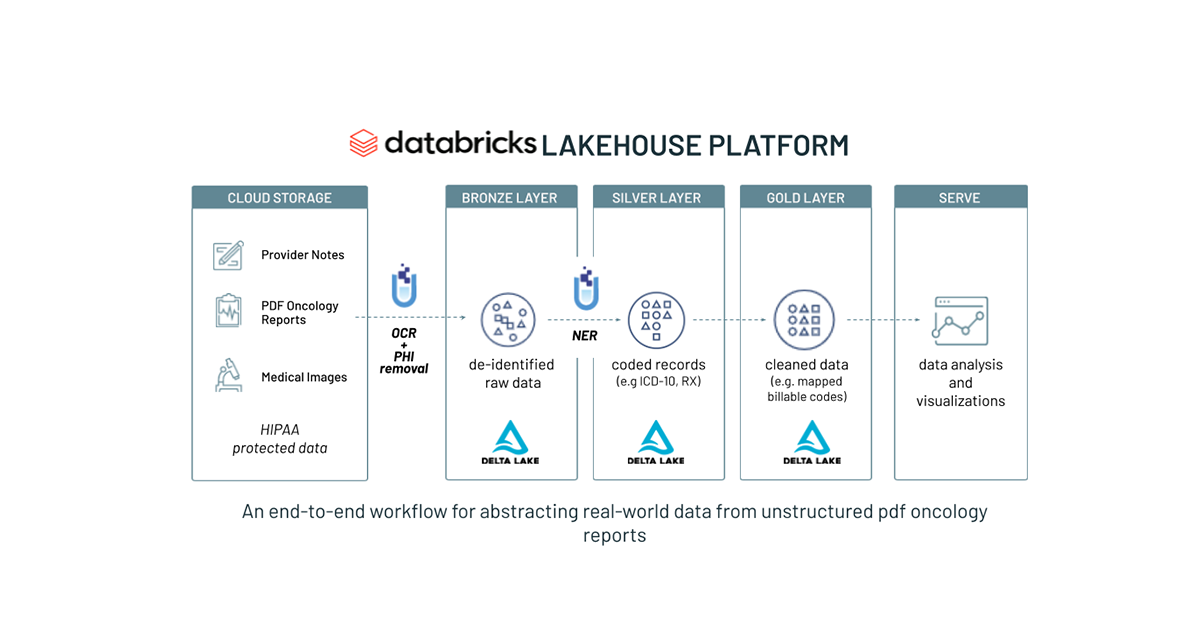
Hugging Faceトランスフォーマーのパイプラインを使ったNLPを始めよう

Original Blog : Getting started with NLP using Hugging Face transformers pipelines
翻訳: junichi.maruyama
自然言語処理(NLP)の進歩は、企業がテキストデータから価値を引き出すための前例のない機会を解き放ちました。自然言語処理は、テキストの要約、人や場所などの固有名詞の認識、感情分類、テキスト分類、翻訳、質問応答など、幅広い用途に使用できます。多くの場合、大規模なテキストデータセットで事前に訓練された機械学習モデルから、高品質の結果を得ることができます。これらの事前学習済みモデルの多くは、オープンソースで公開されており、無料で使用することができます。Hugging Faceは、これらのモデルの素晴らしいソースの一つであり、彼らのTransformersライブラリは、モデルを適用し、また自分のデータにも適応させるための使いやすいツールです。また、これらのモデルを自分のデータに合わせて微調整�をすることも可能です。
例えば、サポートチームを持つ企業では、訓練済みのモデルを使用して、人間が読めるテキストの要約を提供し、従業員がサポートケースの重要な問題を迅速に評価できるようにすることができます。また、この企業は、すぐに利用できる基礎モデルに基づいてワールドクラスの分類アルゴリズムを簡単にトレーニングし、サポートデータを社内のタクソノミに自動的に分類することができます。
Databricksは、Hugging Face Transformersを実行するための優れたプラットフォームです。これまでのDatabricksの記事では、事前学習済みモデルの推論とfine-tuningのためのトランスフォーマーの使用について説明してきましたが、この記事では、Lakehouse上でトランスフォーマーを使用する際のパフォーマンスと使いやすさを最適化するために、これらのベストプラクティスを統合します。また、Databricks では、事前学習済みモデルの推論とfine-tuning のための完全なノートブックの例も提供しています。
事前学習済みモデルの使用
センチメント分析やテキスト要約など、多くのアプリケーシ��ョンでは、事前にトレーニングされたモデルは、追加のモデルトレーニングなしでうまく機能します。🤗 トランスフォーマーパイプラインは、テキストに対する推論に必要な様々なコンポーネントをシンプルなインターフェースで包み込みます。多くのNLPタスクでは、これらのコンポーネントはトークナイザーとモデルで構成されています。パイプラインはベストプラクティスをコード化することで、簡単に始めることができます。例えば、パイプラインは、GPUが利用可能な場合、GPUに送信されるアイテムのバッチ処理を可能にし、より良いスループットを実現します。
Spark上で推論を分散させるために、Databricksはパイプラインをpandas UDFでカプセル化することを推奨しています。Sparkはブロードキャストを使用して、pandas UDFが必要とするオブジェクトをワーカーノードに効率的に転送します。また、SparkはGPUをワーカーに自動的に再割り当てするので、マルチGPUマルチマシンクラスターをシームレスに使用することができます。
以下は、バンドEnergy Orchardに関するWikipediaの記事のスナップショットに対する要約のサンプルである。サマライザーに渡す前に、Wikipediaのマークアップをクリーンアップしていないことに注意してください。


このセクションでは、Hugging Face Transformersを使用してDatabricks上で大規模なテキスト処理を開始することがいかに簡単であるかを示しました。次のセクションでは、これらのモデルのパフォーマンスをさらに調整する方法について説明します。
パフォーマンスチューニング
UDFのパフォーマンスチューニングには、2つのポイントがあります。1つ目は、各GPUを効率よく使いたいということで、これはTransformersパイプラインによってGPUに送られるアイテムのバッチサイズを変更することで調整することができます。もう1つは、データフレームをうまく分割してクラスタ全体を活用することです。
しかし、これではワーカーが利用できるリソースを効率的に利用できていない可能性があります。パフォーマンスを向上させるためには、使用しているモデルやハードウェアに合わせてバッチサイズを調整することができます。Databricksでは、クラスタ上のパイプラインのバッチサイズをいろいろ試してみて、最高のパフォーマンスを見つけることを推奨しています。パイプラインのバッチ処理とその他のパフォーマンスオプションの詳細については、Hugging Faceのドキュメントをご覧ください。クラスタのライブganglia metricsを表示し、GPUプロセッサ利用率の「gpu0-util」やGPUメモリ利用率の「gpu0_mem_util」など、メトリックを選択することでGPUパフォーマンスを監視することができます。

バッチサイズを調整する目的は、GPUをフルに活用しつつ、「CUDA out of memory」エラーが発生しない程度の大きさに設定することです。
クラスタのハードウェアをうまく利用するために、Spark DataFrameを再分割する必要がある場合があります。一般的に、ワーカーのGPU数(GPUクラスタの場合)またはクラスタ内のワーカー全体のコア数(CPUクラスタの場合)の倍数��が、実際にうまく機能します。このUDFの使い方は、Sparkの他のUDFの使い方と同じです。例えば、select文で使用して、モデル推論の結果を持つ列を作成することができます。
構築済みのモデルをMLflowのモデルとしてラッピングする
事前にトレーニングされたモデルをMLflowモデルとして保存することで、バッチまたはリアルタイム推論のためのモデルのデプロイがさらに容易になります。また、モデルレジストリによるモデルのバージョン管理が可能になり、推論ワークロードのモデル読み込みコードを簡素化することができます。
パイプラインのカスタムモデルを作成し、モデルの読み込み、GPU使用量の初期化、推論機能などをカプセル化するのです。
このコードは、上記で説明したpandas_udfを作成し使用するためのコードと密接に類似しています。1つの違いは、パイプラインがMLflowモデルのコンテキストで利用可能になったファイルからロードされることです。これは、モデルをログに記録するときに MLflow に提供されます。Hugging Face transformers パイプラインは、モデルをドライバ上のローカルファイルに保存することを容易にし、それを MLflow pyfunc インターフェイスの log_model 関数に渡します。
MLOps のビッグブック

MLflowモデルを使ったバッチ推論
MLflowは、ログに記録されたモデルや登録されたモデルをspark UDFに読み込むための簡単なインターフェイスを提供します。Model Registryやlogged experiment run UIからモデルURIを検索することができます。
Transformers Trainer🤗を使って、1台のマシンでモデルのfine-tuningを行う
訓練済みのモデルがそのままではニーズに応えられないこともあり、独自のデータでモデルのfine-tuningを行う必要があります。例えば、サポートチケットをサポートチームのオントロジーに分類する基礎モデルに基づいてテキスト分類器を作成したい場合や、自分のデータでカスタムスパム分類器を作成したい場合などがあります。
モデルのfine-tuningをするためにDatabricksを離れる必要はありません。適度な大きさのデータセットであれば、GPUをサポートした1台のマシンでこれを行うことができます。Hugging Face transformers Trainerユーティリティを使用すると、モデルトレーニングのセットアップと実行が非常に簡単になります。より大きなデータセットの場合、Databricksは分散型マルチマシン・マルチGPUディープラーニングもサポートしています。
手順としては、GPUをサポートしたシングルマシンのクラスタを作成し、データセットを準備してドライバーにダウンロードし、Trainerを使用してモデルトレーニングを実行し、結果のモデルをMLflowにログ出力します。
データの準備とダウンロード
まず、トレーニングデータをトレーナーの期待に沿うような表にフォーマットすることから始めます。テキスト分類の場合、これは2つの列を持つテーブルです:テキスト列とラベルの列。このexample notebook では、テキストメッセージのスパムデータを読み込んでいます:

Hugging Face transformersでは、テキスト分類のモデルローダーとしてAutoModelForSequenceClassificationを提供しており、カテゴリーラベルとして整数IDを想定しています。ただし、整数ラベルから文字列ラベルへのマッピングを指定する必要があります。文字列ラベルを持つDataFrameがあれば、次のように情報を収集することができます:
そして、整数のidをpandas_udfでラベルカラムとして作成します:
データをトレーニング/テストに分割し、ドライバのファイルシステムで利用できるようにする。その方法として、DBFSのルートボリュームやマウントポイントを利用する方法がある。
これらのパーケットファイルは、マウントされた/dbfsパスを使用してドライバ上のファイルシステムで利用できるようになりました。トレーニングおよび評価データセットを作成するために、🤗 データセットユーティリティを使用して、パーケットファイルへのパスを指定することができます。
このモデルは、ダウンロードしたデータのテキストではなく、トークン化された入力を想定しています。ベースモデルとの互換性を確保するために、ベースモデルからロードされたAutoTokenizerを使用します。HuggingFaceデータセットでは、トレーニングデータとテストデータの両方に一貫してトークナイザーを直接適用することができます。
トレーナーの構築
Trainer のクラスでは、メトリクス、ベースモデル、トレーニングの設定をユーザが提�供する必要があります。デフォルトでは、Trainerはメトリックとして損失を計算し使用しますが、これはあまり解釈しやすいものではありません。以下は、モデルのトレーニング中に精度を追加で計算するメトリクス関数を作成する例です。
テキスト分類の場合は、AutoModelForSequenceClassificationを使用して、テキスト分類用のベースモデルを読み込みます。ここでは、クラスの数とラベルのマッピングを指定します。
最後に、トレーニングの設定を作成する必要があります。TrainingArgumentsクラスでは、出力ディレクトリ、評価戦略、学習率、その他のparametersを指定することができます。
data collatorを使用すると、訓練と評価のデータセットの入力を一括して処理します。DataCollatorWithPaddingをデフォルトで使用すると、テキスト分類のベースライン性能が良好になります。
これらのパラメータをすべて構築した上で、Trainerを作成することができます。
トレーニングの実行とモデルのロギング
Hugging Face��はMLflowとうまく連携し、MLflowCallback.を使用してモデルトレーニング中に自動的にメトリクスをログに記録します。しかし、訓練されたモデルを自分でログに記録する必要があります。上記の例と同様に、Databricksは学習済みモデルをトランスフォーマーパイプラインでラップし、MLflowのpyfunc log_model機能を使用することを推奨します。そのためには、カスタムモデルクラスが必要です。
Tokenizerと学習済みモデルから変換パイプラインを構築し、ローカルディスクに書き込む。最後に、モデルをMLflowに記録します。
推論用モデルのロードは、MLflowでラップされた事前学習済みモデルのロードと同じです。
このセクションでは、Hugging Face Transformer Trainer API を直接使用して、新しいテキスト分類問題に対してモデルをFine-Tuningする方法を示しました。AutoModel classes for Natural Language Processingは素晴らしい基礎を提供します。.
まとめ
このブログ記事では、いくつかのベストプラクティスを示し、DatabricksでNLP��タスクのためにトランスフォーマーを使い始めるのがいかに簡単であるかを示しました。
推論のために思い出すべき重要なポイントは以下の通りです:
- 🤗トランスフォーマーパイプラインは、トランスフォーマーモデルを簡単に使用することができます、
- フルクラスタを利用するために必要であれば、データを再分割します、
- GPUを効率的に使用するために、バッチサイズを調整することができます、
- Sparkは、マルチマシンGPUクラスターでGPUを自動的に割り当てます、
- Pandas UDFは、モデルのブロードキャストとデータのバッチングを管理し
- パイプラインは、MLflowへのトランスフォーマーモデルのロギングを簡素化します。
シングルマシンモデルのトレーニングで思い出すべきポイント:
- 🤗トランスフォーマー トレーナーは、モデルのFine-Tuningをするための身近な手段です
- Spark上でデータセットを準備し、モデリングタスクに必要な場合はラベルをidにマッピングし、トークン化はTransformersにお任せします🤗
- データセットをドライバーのファイルシステムで利用できるようにする、
- AutoTokenizerを使用してデータセットをトークン化し、モデルに適したトークナイザーをロードします、
- Fine-Tuningを行う場合は、Trainerを使用します、
- トークナイザーとFine-Tuningされたモデルからパイプラインを構築し
- パイプラインをラップするカスタムモデルを使用して、MLflowにログを記録します。
Databricksは、Databricks上でモデルトレーニングや推論をスケールさせるよりシンプルな方法への投資を続けています。データロード、分散モデルトレーニング、そしてMLflowモデルとしてのTransformersパイプラインとモデルの保存に関する改良にご期待ください。
これらの例で始めるには、事前訓練されたモデルの使用とfine-tuningのためのこれらのノートブックをインポートしてください。