DatabricksとApache Spark ClustersにおけるRayのサポートを発表

Original : Announcing Ray support on Databricks and Apache Spark Clusters
翻訳: junichi.maruyama
Rayは、スケーラブルなAIおよびPythonワークロードを実行するため�の著名なコンピュートフレームワークで、さまざまな分散機械学習ツール、大規模なハイパーパラメータチューニング機能、強化学習アルゴリズム、モデル提供などを提供します。同様に、Apache Spark™は、Spark MLlibや、XGBoost, TensorFlow, PyTorchなどの機械学習フレームワークとの深い統合を通じて、分散機械学習用の多様な高性能アルゴリズムを提供しています。機械学習者は、最適なモデルを構築するために、複数のアルゴリズムを検討する必要があり、RayとSparkの両方を含む複数のプラットフォームを使用する必要があることがよくあります。本日、Rayバージョン2.3.0をリリースし、RayワークロードがDatabricksとSparkスタンドアロンクラスターでサポートされ、両方のプラットフォームでモデル開発を劇的に簡素化することをお知らせします。
DatabricksやSparkでRayクラスタを作る
DatabricksまたはSparkクラスタでRayを起動するには、Rayの最新バージョンをインストールし、Ray.util.spark.setup_ray_cluster()関数を呼び出してRayワーカーの数と計算リソースの割り当てを指定するだけです。Databricks Runtimeバージョン12.0以上のDatabricksクラスタと、バージョン3.3以上のSparkクラスタがサポートされています。例えば、以下のコードはDatabricksノートブックにRayをインストールし、2つのワーカーノードを持つRayクラスターを初期化します:
わずか数行のコードでRayクラスタを作成し、モデルのトレーニングを開始する準備ができました。
Ray TrainとRay RLlibでモデルを鍛える
Rayクラスターを起動したところで、いよいよ分散型機械学習のパワーを活用してモデルを構築してみましょう。すべてのRayアプリケーションとRayに統合された機械学習アルゴリズムは、DatabricksとSparkクラスタ上で何の変更もなくサポートされています。例えば、DatabricksノートブックでRay Train API を使用すると、XGBoostモデルのトレーニングを簡単に分散し、トレーニング時間を短縮してモデルの精度を向上させることができます:
また、Rayは強化学習のネイティブサポートを提供しています。例えば、以下のRay RLlib のコードをDatabricksノートブックで実行すると、Taxi Gymnasium environmentでPPO強化学習アルゴリズムを学習することができます:
その他のモデルトレーニングの情報や例については、Ray TrainのドキュメントとRay RLlibのドキュメントをご覧ください。
Ray Tuneで最適なモデルを探す
モデルの品質を向上させるために、Ray Tuneを活用して、何千ものモデルパラメータ構成を大規模に並行して探索することも可能です。例えば、次のコードはRay Tuneを使用してscikit-learnの分類モデルを最適化しています:
Ray と MLflowの併用など、Rayでのモデルチューニングに関する詳細な情報や例は、 Ray Tune documentationに掲載されています。
Rayのダッシュボードを見る
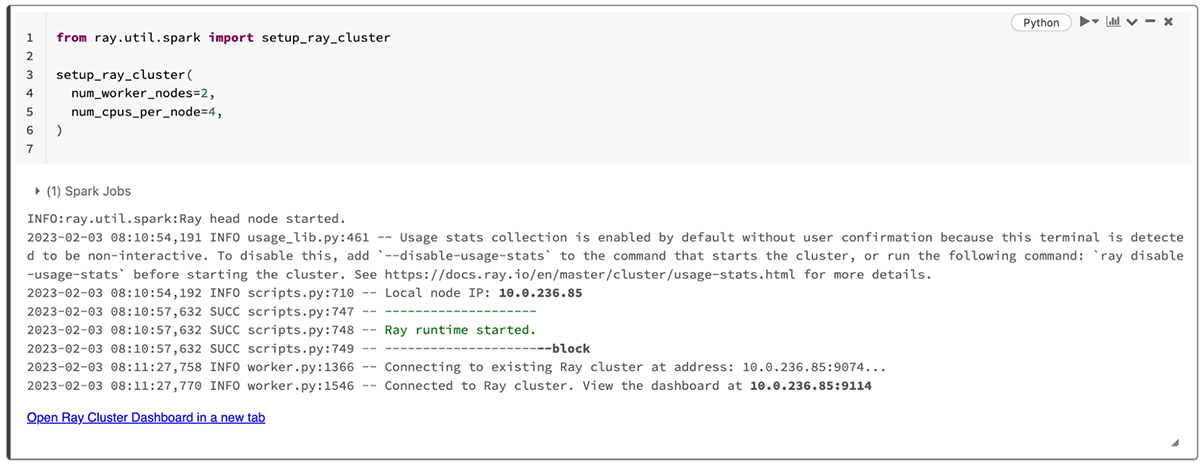
モデル開発中、Ray dashboardを使用して、Ray機械学習タスクの進捗とRayノードの健全性を監視できます。Rayクラスタを作成すると、ray.util.spark.setup_ray_cluster()でRayダッシュボードへのリンクが表示されます。
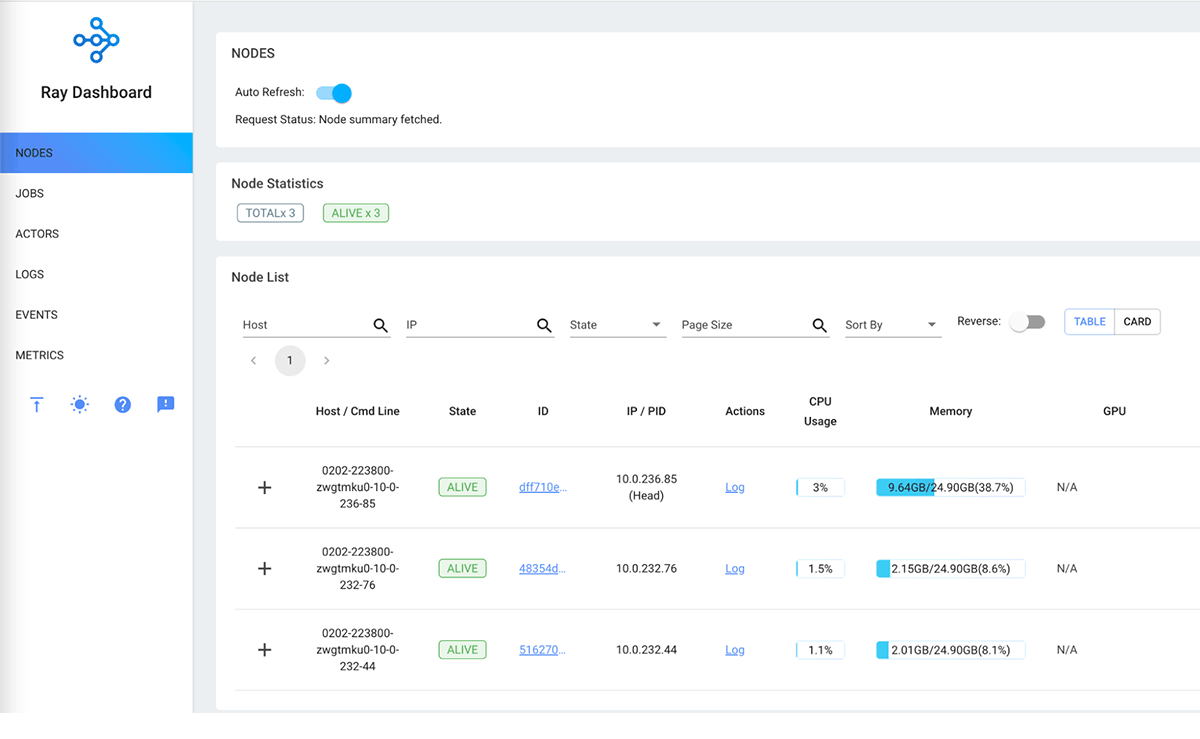
Rayダッシュボードでは、Rayクラスタのノード、アクター、メトリクス、イベントログを包括的に表示することができます。個々のノードのリソース利用メトリクスを簡単に表示したり、すべてのノードのメトリクスを集計したりすることができます。Rayダッシュボードの詳細については、Ray dashboard documentationをご覧ください。
Ray on DatabricksまたはSparkを今すぐ始める
Ray 2.3.0の提供により、今日からDatabricksまたはSparkクラスタ上でRayアプリケーションを実行することができます。Databricksのお客様であれば、バージョン12.0以上のDatabricks RuntimeでDatabricksクラスタを作成し、Ray on Databricks documentationをチェックするだけで始められます。最後に、スタンドアロンのSparkクラスタ上でRayを起動するための手順は、Ray on Spark documentationで提供されています。また https://docs.ray.io/en/latest/ では、Rayでの機械学習について詳しく知ることができます。
私たちは分散型機械学習の相互運用性が一歩前進したことを大変嬉しく思っており、RayアプリケーションをApache Spark™とDatabricksで動かすことを楽しみにしています!


