Databricks モデルサービングの新たなアップデートで生成 AI アプリ開発を加速

昨年、 Databricksモデルサービングにおける基盤モデルのサポートを開始し 、企業が統合データおよび AI プラットフォーム上で安全でカスタマイズされた��生成 AI アプリを構築できるようにしました。 それ以来、何千もの組織がモデルサービングを使用して、独自のデータセットに合わせてカスタマイズされた生成 AI アプリを展開してきました。
本日、生成 AI アプリの実験、カスタマイズ、展開を容易にする新しいアップデートを発表できることを嬉しく思います。 これらの更新には、新しい大規模言語モデル (LLM) へのアクセス、より簡単な検出、よりシンプルなカスタマイズ オプション、および改善された モニタリング が含まれます。 これらの改善により、生成 AI アプリの開発と拡張をより迅速かつ低コストで行うことができます。
Databricks モデルサービングは、AI SaaS 内または外部でホストされているものを含む複数の およびオープン モデルに安全にアクセスして管理することを容易にすることで、Databricks 主導のプロジェクトを加速します。一元化されたアプローチにより、セキュリティとコスト管理が簡素化され、データチームは管理オーバーヘッドを減らしてイノベーションに集中できるようになりました - Edmunds.com テクノロジー担当バイスプレジデント、Greg Rokita 氏
統一されたインターフェイスから新しいオープンモデルと独自モデルにアクセス
モデルサービングには継続的に新しいオープンソース モデルと独自モデルが追加され、統一されたイ�ンターフェイスを通じてより幅広いオプションにアクセスできるようになります。
- 新しいオープンソース モデル: DBRX や Llama-3 などの最近の追加機能は、オープン言語モデルの新しいベンチマークを確立し、最先端のクローズド モデル製品に匹敵する機能を提供します。これらのモデルは、 最適化された GPU 推論を備えた基盤モデル APIs を介して Databricks で即座にアクセス可能であり、データはDatabricks のセキュリティ境界内で安全に保たれます。
- 新しい外部モデルのサポート: 外部モデル機能は、Gemini Pro や Claude 3 など、最新の独自の最先端モデルをサポートするようになりました。外部モデルを使用すると、サードパーティモデルプロバイダーの認証情報を安全に管理し、レート制限と権限のサポートを提供できます。
すべてのモデルは、統合された OpenAI 互換のAPIと SQL インターフェースを介してアクセスできるため簡単に比較、実験し、ニーズに最適なモデルを選択できます。
Experian では、コア機能を維持しながら幻覚の発生率が最も低い生成 AI モデルを開発しています。 Databricks で Mixtral 8x7b モデルを利用することで、迅速なプロトタイピングが可能になり、優れたパフォーマンスと迅速な応答時間が実現しました - Experian の AI/ML イノベーション責任者、James Lin 氏
新しい検出ページと検索エクスペリエンスによるモデルとエンドポイントの検出
Databricks のモデルのリストを拡大し続けるにつれて、多くのユーザーから、モデルを見つけることがより困難になっているという声が寄せられています。 モデル検出を簡素化する新機能が導入されました。
- パーソナライズされたホームページ: 新しいホームページでは、一般的なアクションとワークロードに基づいて Databricks エクスペリエンスがパーソナライズされます。Databricks ホームページの [Mosaic AI] タブには、最先端のモデルが紹介されており、簡単に見つけることができます。このプレビュー機能を有効にするには、アカウント プロファイルにアクセスし、[設定] > [開発者] > [Databricks ホームページ] に移動します。
- ユニバーサル検索: 検索バーでモデルとエンドポイントがサポートされるようになり、既存のモデルとエンドポイントをすばやく見つける方法が提供され、検出時間が短縮され、モデルの再利用が容易になりました。
チェーンアプリと関数呼び出しで複合 AI システムを構築する
ほとんどの生成 AI アプリケーションでは、LLM を組み合わせたり、外部システムと統合したりする必要があります。Databricks モデルサービングを使用すると、LangChain または任意の Python コードを使用してカスタムオーケストレーションロジックをデプロイできます。これにより、エンドツーエ��ンドのアプリケーションを完全に 上で管理およびデプロイできます。Databricks プラットフォーム上で 複合システムをさらに簡単にするための更新を導入しています。
- Vector Search (現在 GA) : Databricks Vector Search はモデルサービングとシームレスに統合され、正確でコンテキストに適した応答を提供します。現在、一般提供されており、大規模な本番運用対応の展開に対応しています。
- 関数呼び出し (プレビュー) : 現在、プライベート プレビューでは、関数呼び出しにより、LLM は構造化された応答をより確実に生成できます。この機能により、JSON オブジェクトを出力して引数をマッピングすることで関数を呼び出すことができるエージェントとして LLM を使用できます。一般的な関数呼び出しの例としては、DBSQL などの外部サービスの呼び出し、自然言語の API 呼び出しへの変換、テキストからの構造化データの抽出などがあります。プレビューに参加してください。
- ガードレール (プレビュー): プライベート プレビューでは、ガードレールは、有害または機密性の高いコンテンツに対する要求と応答のフィルター処理を提供します。 プレビューに参加します。
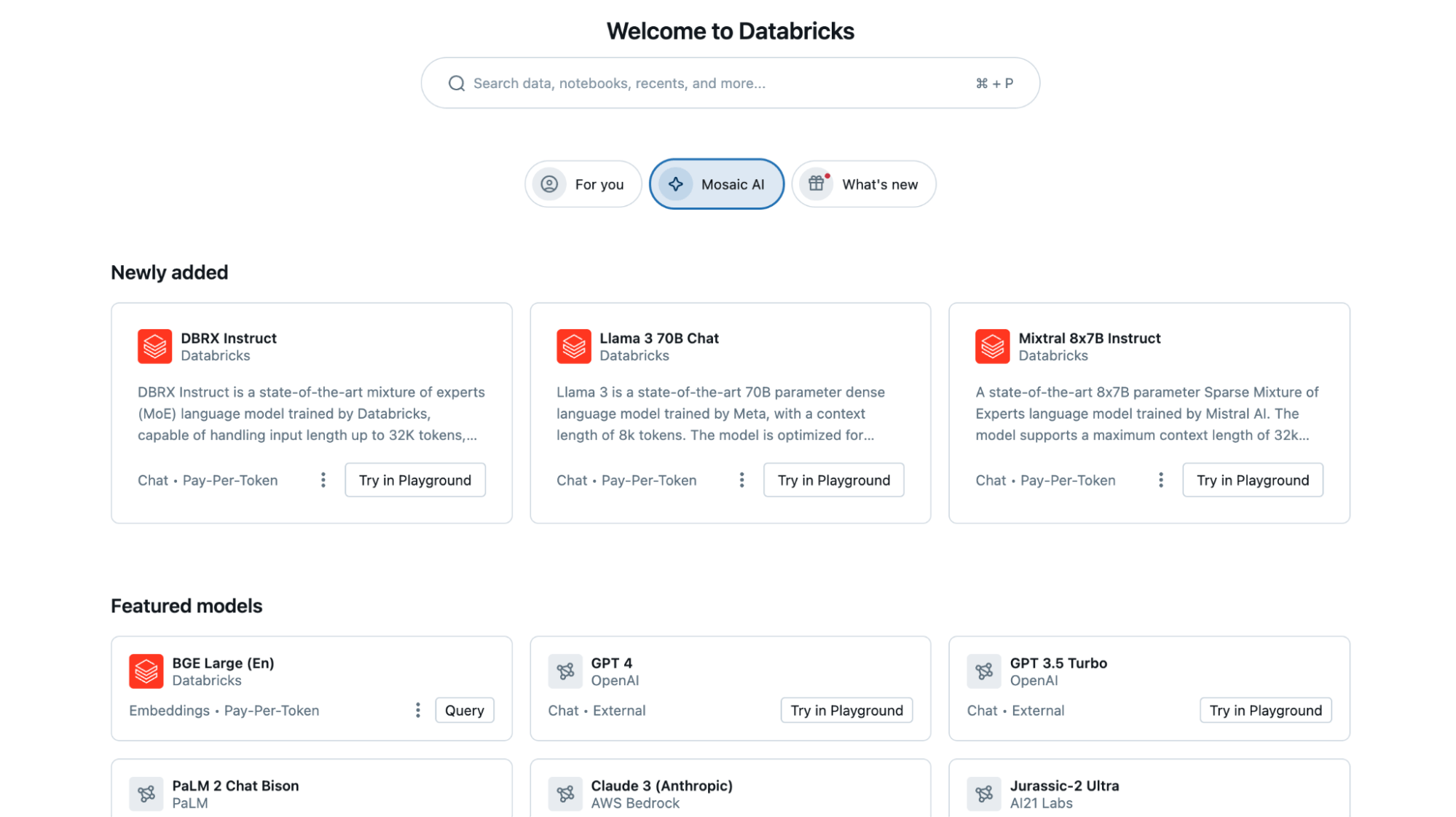
- Secrets UI: 新しい Secrets UI は、エンドポイントへの環境変数とシークレットの追加を効率化し、外部システムとのシームレスな通信を容易にします (APIも利用可能)。
LangChain および PyFunc モデルのストリーミング サポートや、 Databricks 上での最新グレードの複合 AI アプリの構築をさらに簡素化するプレイグラウンド統合など、さらなるアップデートが近日中にリリースされる予定です。
モデルサービングとモニタリングを組み合わせることで、展開されたモデルが常に最新の状態に保たれ、正確な結果が得られることを保証できます。この合理化されたアプローチにより、可用性や運用上の懸念を気にすることなく、 AIのビジネスへの影響を最大化することに集中できます - Hitachi Solutions 製品開発担当副社長、Don Scott 氏
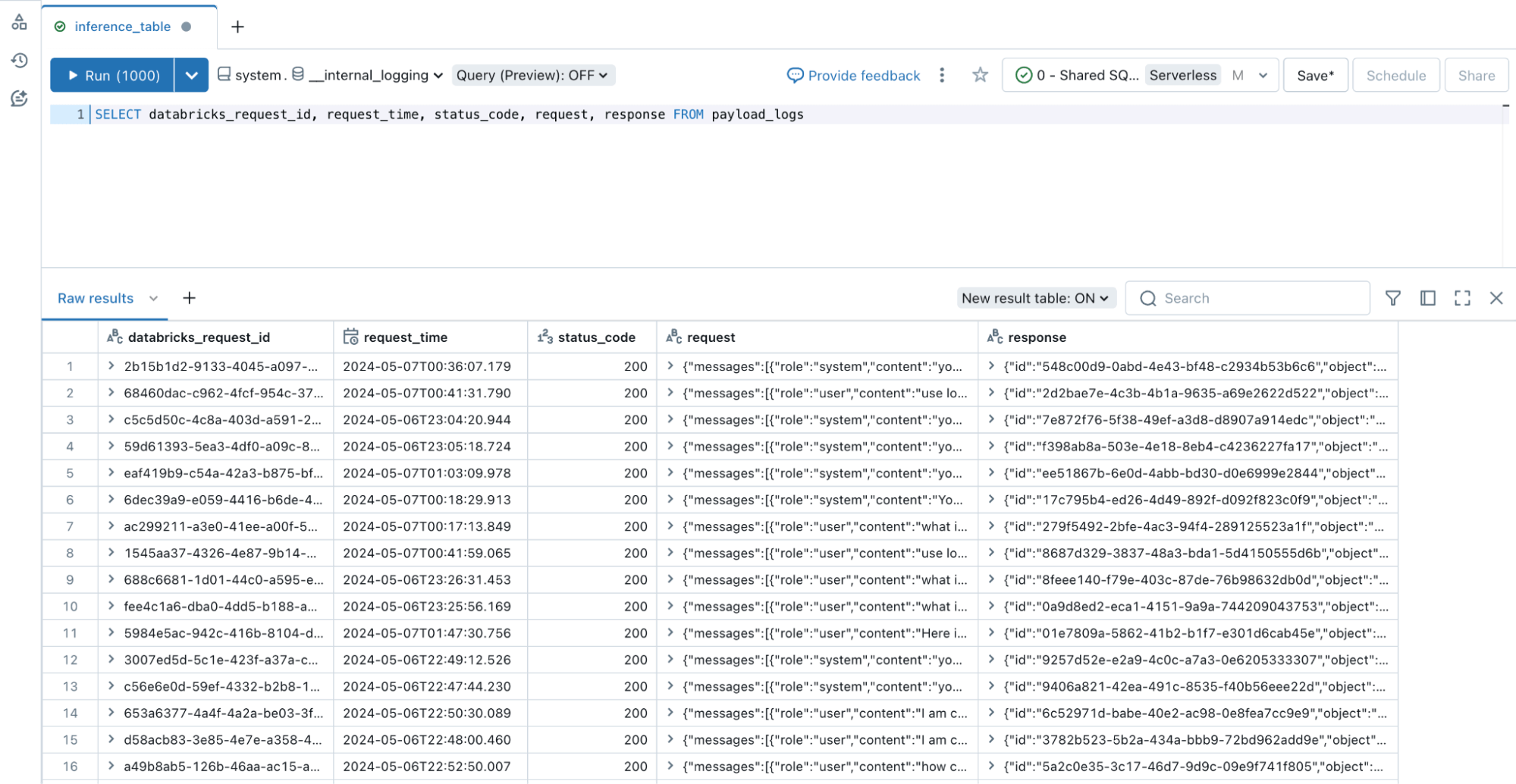
推論テーブルを使用したすべてのタイプのエンドポイントの監視
LLM やその他の AI モデルのモニタリングは、それらをデプロイすることと同じくらい重要です。推論テーブルが、GPU デプロイモデルや外部ホストモデルを含むすべてのエンドポイントタイプをサポートするようになったこ��とをお知らせします。推論テーブルは、 Databricksモ デルサービングエンドポイントからの入力と予測を継続的にキャプチャし、 Unity Catalog Delta Table に記録します。その後、既存のデータツールを使用して AI モデルを評価、監視、微調整できます。
プレビューに参加するには、アカウント > プレビュー > 外部モデルと基盤モデルの推論テーブルを有効にするに移動します。
無料トライアル
Databricks AI Playground にアクセスして、ワークスペースから直接基盤モデルを試してください。詳細については、次のリソースを参照してください。

