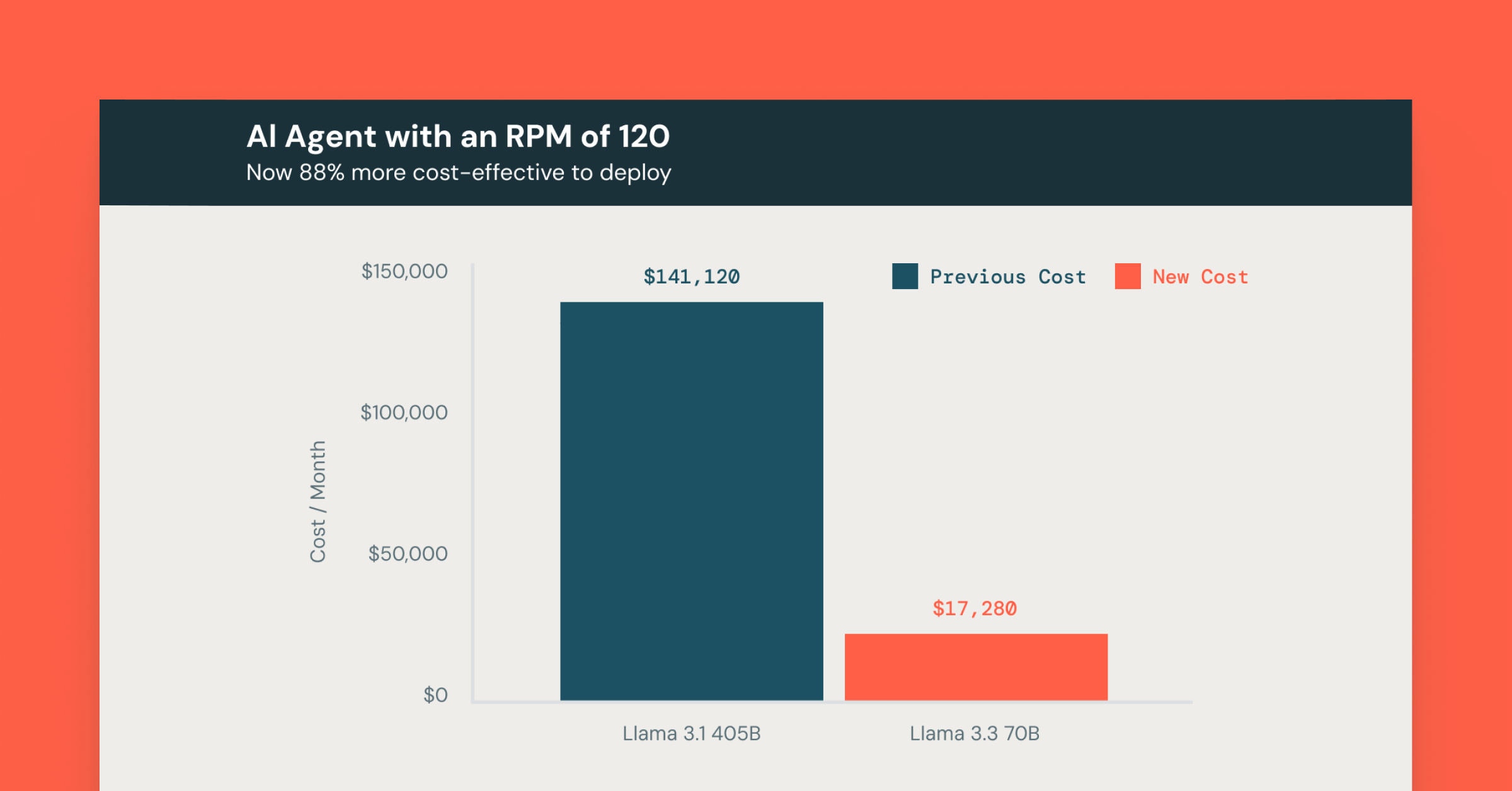
Predictive I/O for UpdatesのGAを発表 - DMLクエリの高速化
15兆回を超える不必要な行の書き込みを防止し、まだ始まったばかりだ。
この度、Predictive I/Oのアップデートの一般提供を開始いたしました。
この機能では、Photonと LakehouseのAIを活用することで、MERGE、UPDATE、DELETEなどのデータ操作言語(DML)操作を大幅に高速化し、読み取りクエリのパフォーマンスについては変更されない。
更新のためのPredictive I/Oは、 デルタレイクの 機能である Deletion Vectorsを インテリジェントに適用するAIモデルによって実現され、超最適化されたビットマップファイルによって削除された行の追跡を可能にする。その結果、データ・エンジニアリング・チームのオーバーヘッドを大幅に削減しながら、クエリーを大幅に高速化することができる。
GA後まもなく、新しいテーブルでデフォルトで更新のPredictive I/Oを有効にする。 すぐにオプトインするには、当社のドキュメントまたはこの記事の一番最後にある手順を参照してください。
従来のアプローチ:進むも地獄、退くも地獄だが、どっちにする?
従来、DMLクエリーの処理には2つのアプローチがあり、それぞれ異なる長所と短所があった。
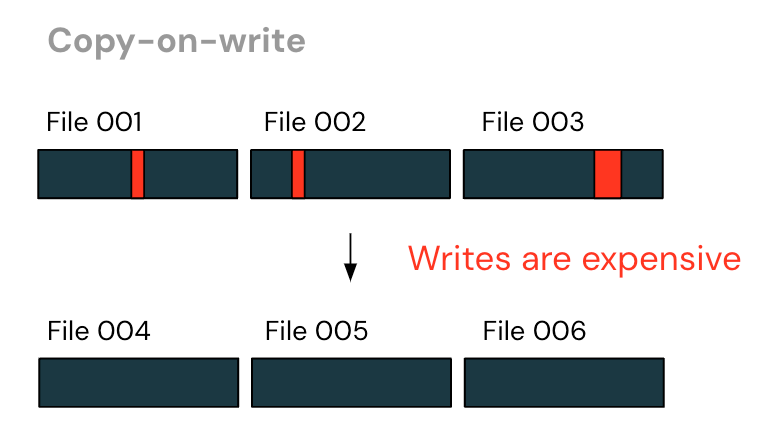
最初の、最も一般的なアプローチは「コピー・オン・ライト」である。 クエリーエンジンは、修正が必要な行を含むファイルを特定し、未修正の行をすべて新しいファイルに書き換えて、削除された行をフィルタリングし、更新された行を追加する。
このアプローチでは、書き込みは非常に高くつく。 DMLクエリでは、数行しか変更されないのが普通である。 コピー・オン・ライトでは、ほとんど変更がないにもかかわらず、ファイル全体が書き換わることになる�!
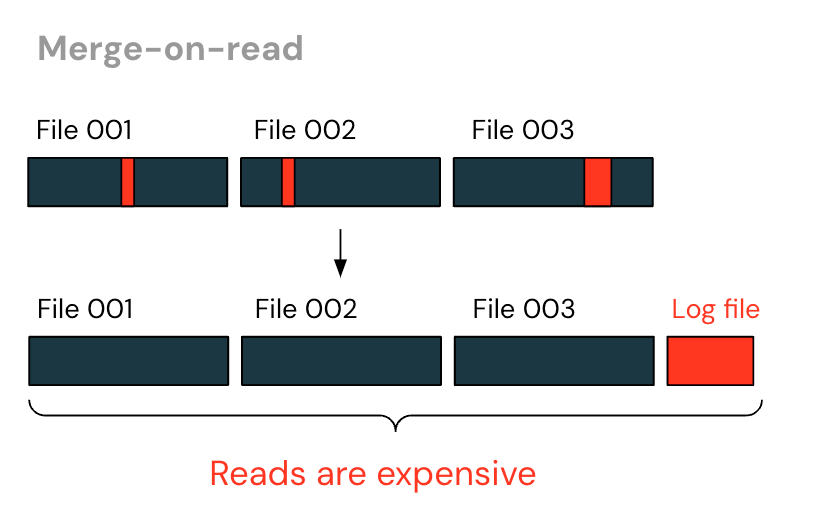
別のアプローチとして、"merge-on-read "がある。 ファイル全体を書き換える代わりに、削除された行を追跡するログファイルが書き込まれる。 そして、読者はデータファイルと追加ログファイルの両方を読むことによって、表を構成する。
merge-on-readsを使えば、書き込みはずっと速くなる。変更されていないファイルを書き直す必要がなくなるからだ。 しかし、時間の経過とともに、より大きなログファイルが生成され、そのすべてを読者がまとめなければならないため、読み取りはますます高価になる。 エンドユーザーはまた、妥当な読み取りパフォーマンスを維持するために、ログファイルとデータファイルを新しいデータファイルに書き換える「パージ」のタイミングを決定しなければならない。
結局のところ、従来のアプローチにはそれぞれ長所と短所があり、「毒を選ぶ」ことを余儀なくされる。 各テーブルについて、このユースケースにはコピー・オン・ライトとマージ・オン・リードのどちらが適しているのか��? 後者の場合、どのくらいの頻度でログファイルをパージすべきなのか?
アップデートのためのPredictive I/Oの導入 - AIはあらゆる世界のベストを提供する
更新のためのPredictive I/Oは、光速のDML操作と優れた読み取りパフォーマンスという、すべての世界のベストを提供します。 これは、Delta LakeのDeletion Vectorsの適用とパージのタイミングを自動的に判断するAIモデルを使って実現されている。
Predictive I/Oが更新のために書き込んだテーブルは、オープンなDelta Lakeフォーマットのままであり、OSS Delta 2.3.0以上を実行するTrinoやSparkを含むDelta Lakeエコシステムのコネクターで読むことができる。
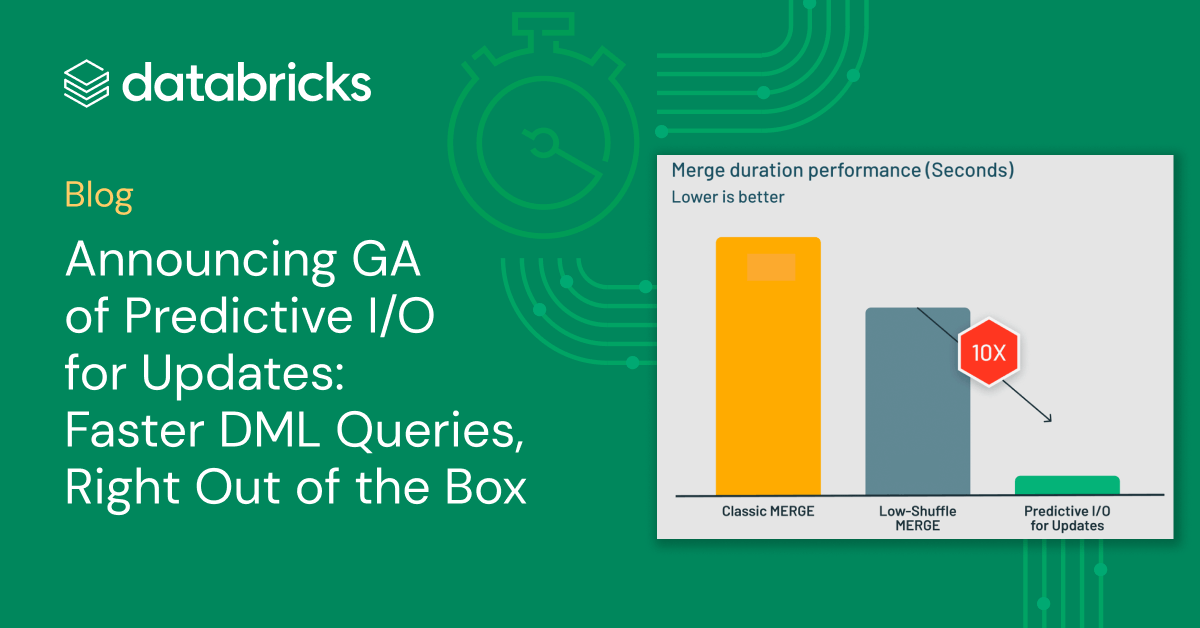
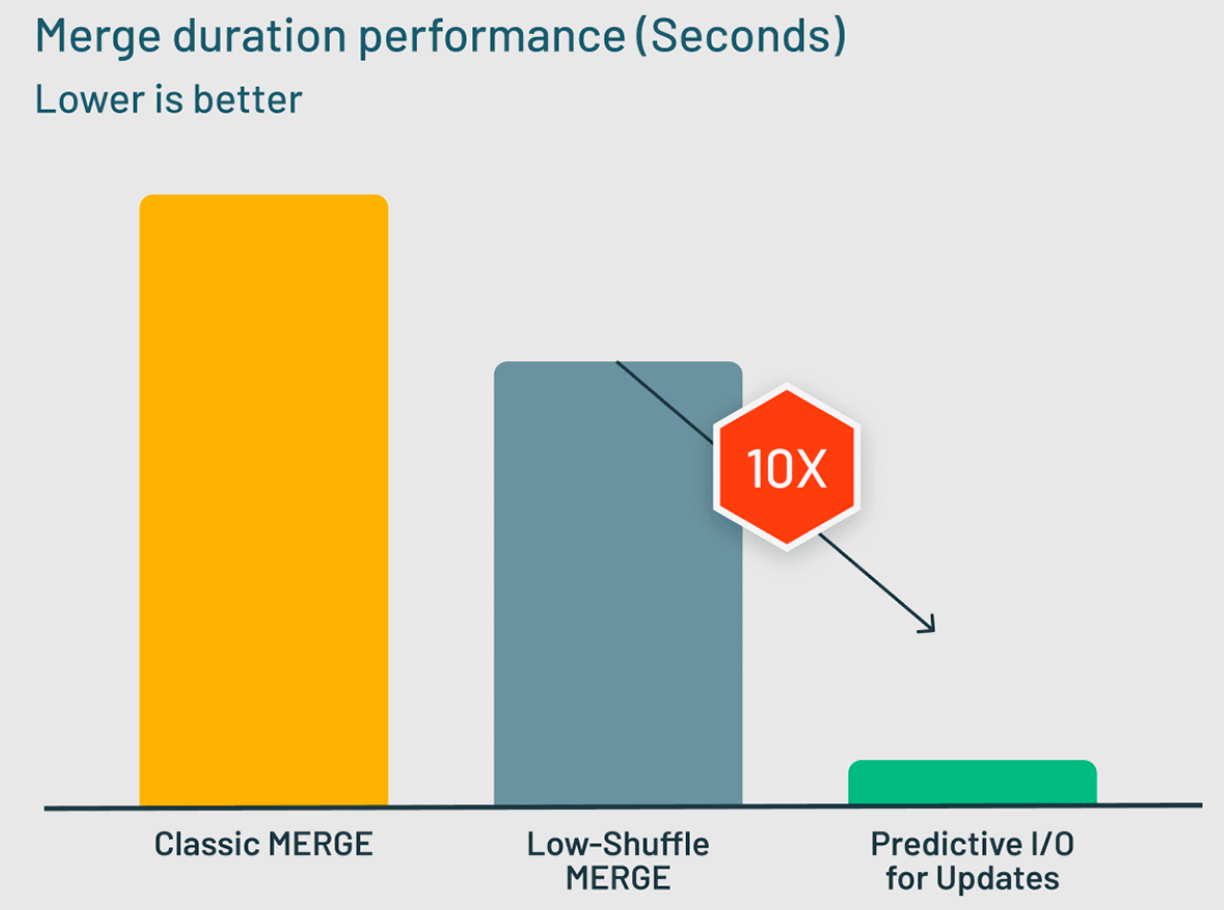
典型的なデータウェアハウスのMERGEワークロードのベンチマークでは、更新のためのPredictive I/Oは、Photonが以前使用していたLow-Shuffle Merge技術よりも10倍のパフォーマンス向上を実現しました。
4月にPredictive I/OのPublic Preview for updatesが発表されて以来、DMLクエリのパフォーマンスを大幅に向上させるためにこの機能を使用することに成功した何百ものお客様と協力してきました。
この間、Predictive I/O for updatesは何十億ものDeletion Vectorsを書き込んでおり、そのデータを使って、Deletion Vectorsを適用する最適なタイミングを判断するためのAIモデルをさらに改良してきた。 私たちは、Deletion Vectorsによって、コピー・オン・ライト方式でなければ書き込まれていたであろう15兆行以上の不必要な書き換えを防ぐことができたことを発見した。 DMLワークロードの大幅な高速化が報告されたのも当然である:
"更新のための予測I/Oは、DMLオペレーションを大幅にスピードアップし、計算コストを削減し、Time-to-Insightを加速するのに役立っています。 私たちは、この機能がセット・アンド・フォーゲットになったことで、データからビジネス価値を得ることに集中する時間を確保できるようになったことに満足している。"-- Antonio del Rio, Data Engineering, Avoristech
近日公開:新しく作成されたテーブルに対して、すぐに更新の予測I/Oが有効になる。
パブリック・プレビューで得られた有望な結果は、この機能を一般提供する自信につながっただけでなく、新しく作成されたテーブルに対してデフォルトでPredictive I/Oを有効にし始める自信にもつながった。 これらの変更は、Photonが有効になっていないクラスタでも、Deletion Vectorsを有効にする場合にも適用される。
この改善により、関連するテーブル・プロパティを忘れずに設定しなくても、すぐにパフォーマンスを向上させることができる。
新しいワークスペース設定によって、ワークロード全体の更新に対してPredictive I/Oを有効にすることができる。 この設定はAzureとAWSで現在利用可能で、GCPでも近日中に利用可能になる予定だ。 アクセスするには
- ワークスペース管理者として、ワークスペースの管理者設定に移動
- ワークスペース設定タブを選択
- Deletion Vectors(削除ベクター)の自動有効化と題された設定に進む
この設定は、Databricksランタイム14.0+を使用するすべてのDatabricks SQLウェアハウスおよびクラスタに対して有効になります。
また、この同じ設定を使用して、単に設定を「無効」に設定することで、デフォルトで有効化をオプトアウトすることもできます。
今すぐPredictive I/Oを有効にして、DMLクエリにAIのパワーをチャージしましょう! そして、AIを活用したDatabricksのさらなる機能の登場にもご期待ください。