時系列データの予測力を解き放て!
Mosaic AIモデルトレーニングでサーバーレス時系列予測が登場 🚀
Summary
- サーバーレスアーキテクチャは、クラスタ管理の必要性を排除しながらパフォーマンスを最適化することで、トレーニングを簡素化します。- モデルは自動的にUnity Catalogに登録され、コンプライアンスを簡素化し、追加のガバナンスポリシーの必要性を排除します。- 改良された使いやすさにより、バッチまたはリアルタイムでモデルをワンクリックで提供できます。- ボックスから出るモデルの品質が高く、最大50%の予測精度が向上します。
時系列予測は、将来のトレンド、需要、ユーザー行動を予測することで、データに基づく意思決定��を目指す企業にとって極めて重要です。たとえば、小売業界の Databricks 顧客は、時系列予測モデルを活用して、季節や地域ごとの製品需要を精度高く予測し、在庫管理を最適化しています。同様に、エネルギー企業は消費パターンを予測して供給と需要のバランスを効率的に保ち、コスト削減や電力網の安定性を確保しています。
Databricksの顧客は、クラスタの管理やデータおよびモデルガバナンスの複雑さに煩わされることなく、Data Intelligence Platformを活用して洞察を提供することに集中したいと考えています。また、最高品質の予測を実現するために、最先端のモデルアーキテクチャへのアクセスを求めています。
これらの課題に対応するため、Mosaic AIモデルトレーニングに新機能として時系列予測を導入しました。この新しいAutoML製品は、柔軟性、ガバナンス、パフォーマンスを強化し、企業が時系列データの予測力を最大限に引き出すのを助けます。
サーバーレス体験でモデルトレーニングを簡素化
データサイエンティストは、クラスタの設定や管理のオーバーヘッドなしに、予測問題の解決に取り組むことができます。Databricksは自動スケーリングによりパフォーマンスとコストを自動的に最適化し、最高のユーザー体験を提供しながら、時系列モデルのトレーニングと提供の運用負荷を軽減します。これは、あなたがインフラではなく洞察に焦点を当てるための時間を増やすことを意味します。
統一されたガバナンスとシームレスな統合
新たな機能により、時系列予測モデルを含む最適なモデ��ルが自動的に Unity Catalog に登録されます。この統合により、顧客がモデルのための別のデータガバナンスポリシーセットを維持する必要がなくなります。予測結果も自動でUnity Catalogのテーブルに保存されます。これにより、モデルとデータを一つのガバナンスフレームワークで管理することができ、組織全体での一貫性、セキュリティ、コンプライアンスが向上します。
すぐに使える高品質モデル
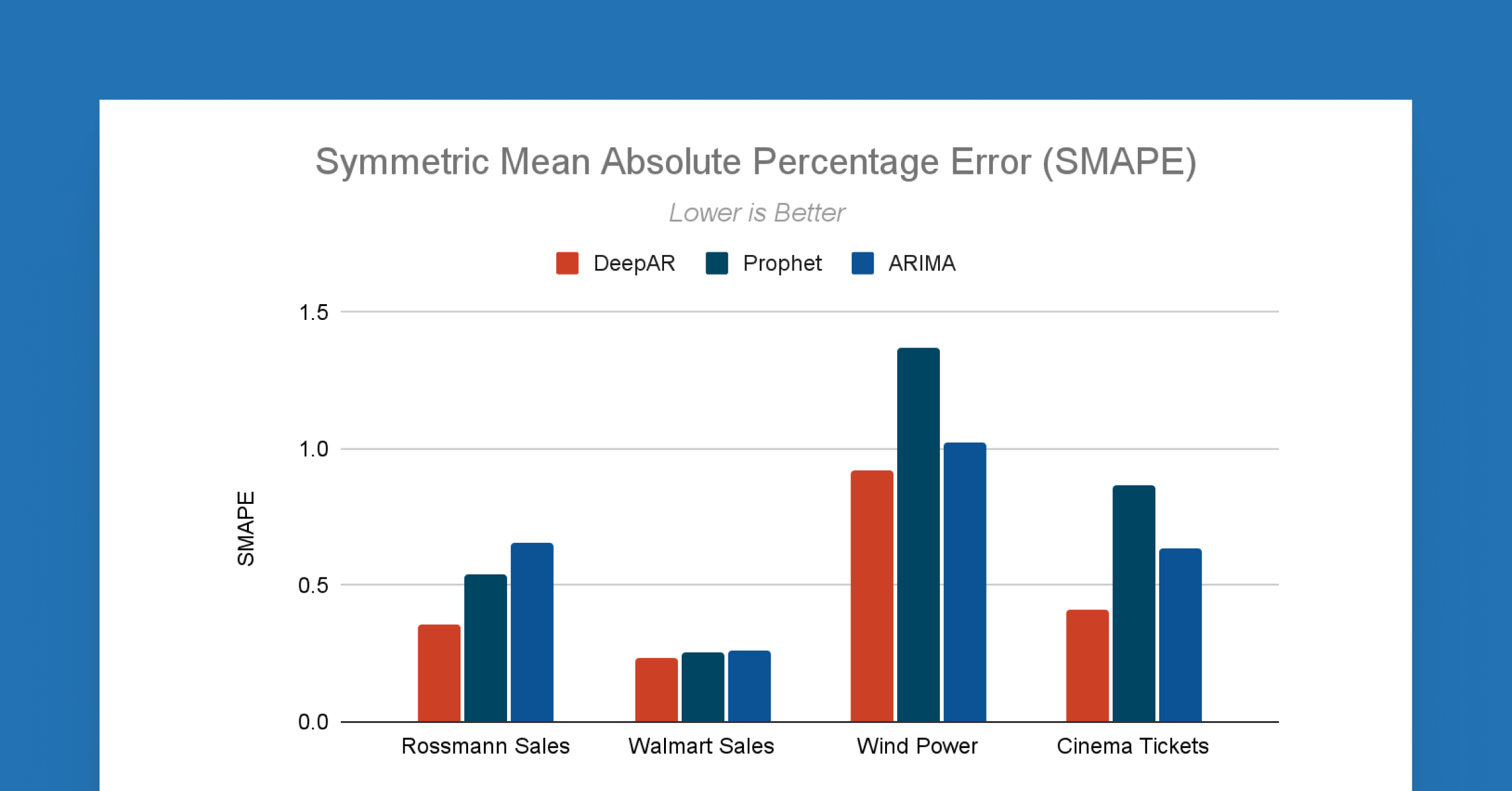
時系列予測ツールのポートフォリオに、ディープニューラルネットワークモデルを活用した高精度な時系列予測アルゴリズムである DeepAR を導入します。DeepAR は、時系列予測における精度向上に特化しており、ベンチマークによれば予測誤差率を最大 50% 削減します。以下の比較グラフをご覧ください。この新しいアルゴリズムはデフォルトで有効になっています。顧客は、追加のチューニングなしで最先端のモデル性能を利用でき、高品質な予測を簡単に得ることができます。
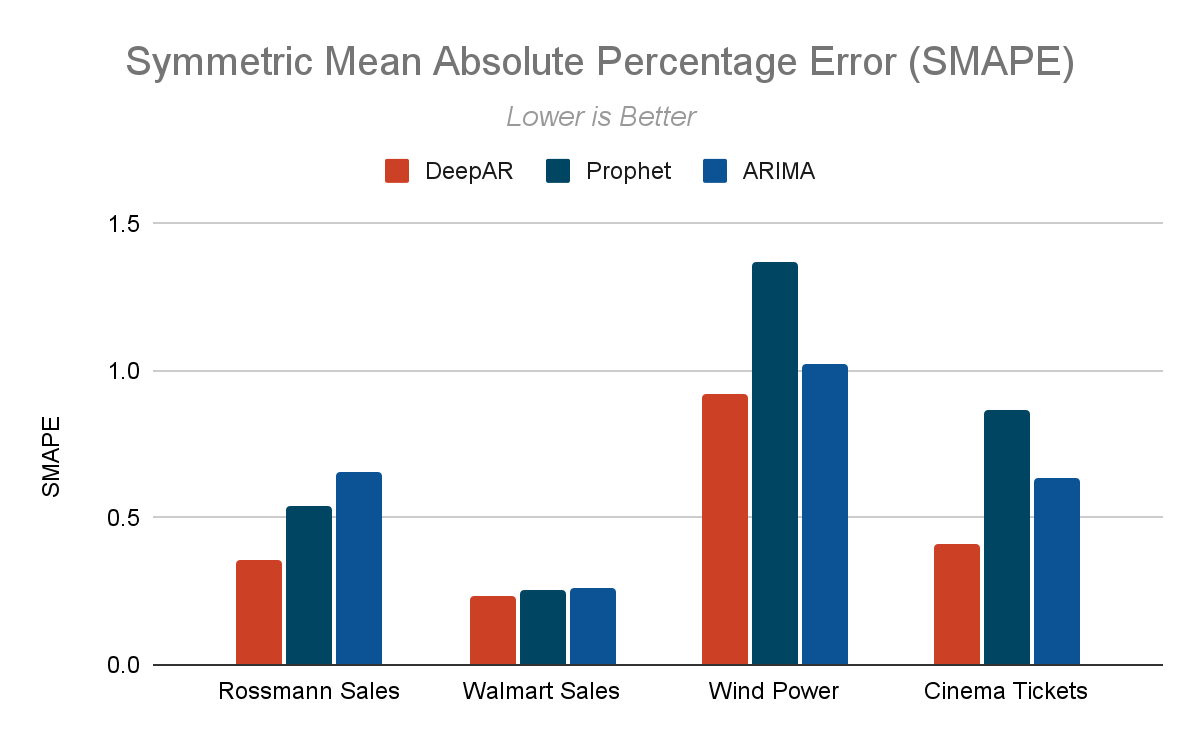
ベンチマークデータセット: rossmann, walmart, wind, cinema
新機能で使いやすさが向上
時系列予測をよりカスタマイズ可能で効果的にするために、多くの新機能を導入しました:
- データ分割の柔軟なカスタマイズ
Train/Validate/Testデータの分割をカスタマイズして、データの特有のパターンやトレンドに対応可能にしました。これにより、モデル評価の精度が向上し、ファインチューニングがより効果的になります。 - 加重評価で精度向上
個々の時系列に異なる重みを割り当てて評価を実施。これにより、データセット内で最も重要または影響力のある時系列に焦点を当てられます。重要な部分で最高の精度を発揮するモデルが選ばれるようになります。 - 強化されたユーザーインターフェース
改善された UI により、時系列予測モデルのバッチ推論やリアルタイムエンドポイントをワンクリックで利用可能にしました。この直感的なUIにより、モデルの本番環境へのデプロイが容易になり、予測から価値を得るまでの時間を短縮できます。
今日からはじめましょう
売上予測で収益を増加させたい、あるいはユーザートレンドを予測してエンゲージメントを向上させたい場合、当ツールが複雑なモデル構築を自動化します。これにより、チームはゼロからモデルを構築するのではなく、洞察の活用に集中できます。
詳細はドキュメンテーションをご覧ください。