Databricks Feature Serving(特徴量サービング)の一般提供開始のお知らせ

公開日: March 11, 2024
によって アクラティ・タラティ、マニ・パルケ、Chenen Liang、Jasraj Dange、葛 明陽、アキル・グプタ による投稿
本日、Databricks Feature Serving(特徴量サービング)の一般提供を開始いたします。 特徴量はAIアプリケーションにおいて極めて重要な役割を果たし、通常、正確に計算し、低レイテンシーでアクセスできるようにするためにはかなりの労力を必要とします。 この複雑さによって、本番のアプリケーションの品質を向上させるための新機能の導入が難しくなります。 特徴量サービングを利用すれば、AIアプ��リケーションに対して、単一のREST APIを使用してリアルタイムで、事前に計算された特徴量やオンデマンドの特徴量を簡単に提供することができます!
特徴量サービングは、高速で安全、かつ簡単に使用できるように設計されており、次のような利点があります:
- 高速かつ低TCO- 特徴量サービングは、低TCOで高いパフォーマンスを提供するように設計されており、ミリ秒単位の待ち時間で特徴量を提供できます。
- フィーチャーチェーン- 事前に計算された特徴量とオンデマンド計算のチェーンを指定することで、複雑なリアルタイム特徴量の計算を簡単に指定できます。
- 統一されたガバナンス- ユーザーは、既存のセキュリティおよびガバナンスポリシーを使用して、データおよびML資産を管理しガバナンスを適用できます。
- サーバーレス- オンライン・テーブルを活用した特徴量サービングにより、リソースの管理やプロビジョニングが不要になります。
- トレーニングの歪みを低減- トレーニングと推論で使用される特徴量が全く同じ変換を経ていることを確認し、一般的な失敗モードを排除します。
このブログでは、特徴量サービングの基本を説明し、Databricks オンラインテーブルを使ったシンプルなユーザージャーニーの詳細を共有し、様々なAIユースケースでお客様が既にどのように特徴量サービングを使用しているかについて説明します。
特徴量サービングとは
特徴量サービングは、パーソナライズされたレコメンデーション、カスタマーサービス・チャットボット、詐欺�検知、複合世代AIシステムなどのリアルタイムAIアプリケーションを構築するために、事前に計算されたオンデマンドの特徴量を提供するように設計された低レイテンシーのリアルタイムサービスです。 特徴量は、機械学習モデルにとって意味のある信号を作成するために使用される生データの変換です。
前回のブログポストでは、3種類の特徴計算アーキテクチャについてお話しました:バッチ、ストリーミング、オンデマンドです。 これらの特徴計算アーキテクチャーにより、2つの特徴カテゴリが生まれます:
- 事前計算された特徴量- バッチまたはストリーミングで計算された事前計算された特徴量は、予測要求の前に計算され、Unity Catalogのオフラインデルタテーブルに保存され、モデルのトレーニングで使用され、推論のためにオンラインで提供されます。
- オンデマンド特徴量 - 推論時、つまりモデルへのリクエストと同時にのみ計算可能な特徴量の場合、実効的なデータ鮮度要件は「即時」です。 これらの特徴は、通常、ユーザーのリアルタイムの位置のようなリクエストからのコンテキスト、事前に計算された特徴、または両方の連鎖計算を使用して計算されます。
特徴量サービング(AWS|Azure)は、リアルタイムのAIアプリケーションのために、ミリ秒単位のレイテンシーで両方のタイプの特徴量を利用できるようにします。 特徴量サービングは、さまざまなユースケースで活用できます:
- レコメンデーション - リアルタイムのコンテキスト認識機能でパーソナライズされたレコメンデーション
- 不正検知 - リアルタイムのシグナルで不正取引を特定・追跡
- RAGアプリケーション - RAGアプリケーションへのコンテキスト信号の配信
特徴量サービングをご利用のお客様は、AIアプリケーションにアクセスできるようにするための運用上のオーバーヘッドを気にすることなく、より多くの機能を試すことで、AIアプリケーションの品質向上に集中しやすくなっています。
Databricks 特徴量サービングの簡単なオンラインサービスセットアップのおかげで、顧客向けのレコメンデーションシステムを簡単に導入することができました。モデルのトレーニングから、すべての顧客に対するパーソナライズされたレコメンデーションの展開まで、迅速に移行することができました。特徴量サービングのおかげで、関連性の高いレコメンデーションをお客様に提供することができ、スケーラビリティを容易に処理し、本番の信頼性を確保することができました。これにより、私たちはパーソナライズされたレコメンデーションという私たちの主要な専門分野に集中することができるようになりました。 Mirina Gonzales Rodriguez 氏、Yape Pere データ運用技術リーダー
Databricksデータインテリジェンスプラットフォームとのネイティブ統合
特徴量サービングはDatabricks データインテリジェンスプラットフォームとネイティブに統合されており、ML 開発者は Databricks オンラインテーブル(AWS | Azure)(現在パブリックプレビュー中)を使用して、任意の Delta Table に保存された事前計算済みの特徴量にミリ秒単位のレイテンシーで簡単にアクセスできるようになります。 このシンプルなソリューションにより、データ取り込みパイプラインを別に管理する必要がなくなり、機能をオンラインで利用可能にし、常に更新することができます。
Databricks の自動的な特徴検索とモデルサービングでのリアルタイム計算により、当社の流動性データ管理は一変し、多数の顧客の支払いエクスペリエンスが向上しました。オンラインテーブルとの統合により、ライブの市場データポイントに基づいて口座の流動性ニーズを正確に予測できるようになり、Databricksエコシステム内での業務が効率化されました。Databricks オンラインテーブルは、独自のインフラストラクチャを管理する必要なく、リアルタイム予測のレイテンシを削減し、統合されたエクスペリエンスを提供��してくれました。Jon Wedrogowski 氏、Ripple 応用科学シニアマネージャー
ホテルのレコメンドチャットボットの例を見てみましょう。4つの簡単なステップで特徴量サービングのエンドポイントを作成し、アプリケーションのリアルタイムフィルタリングを可能にするために使用します。
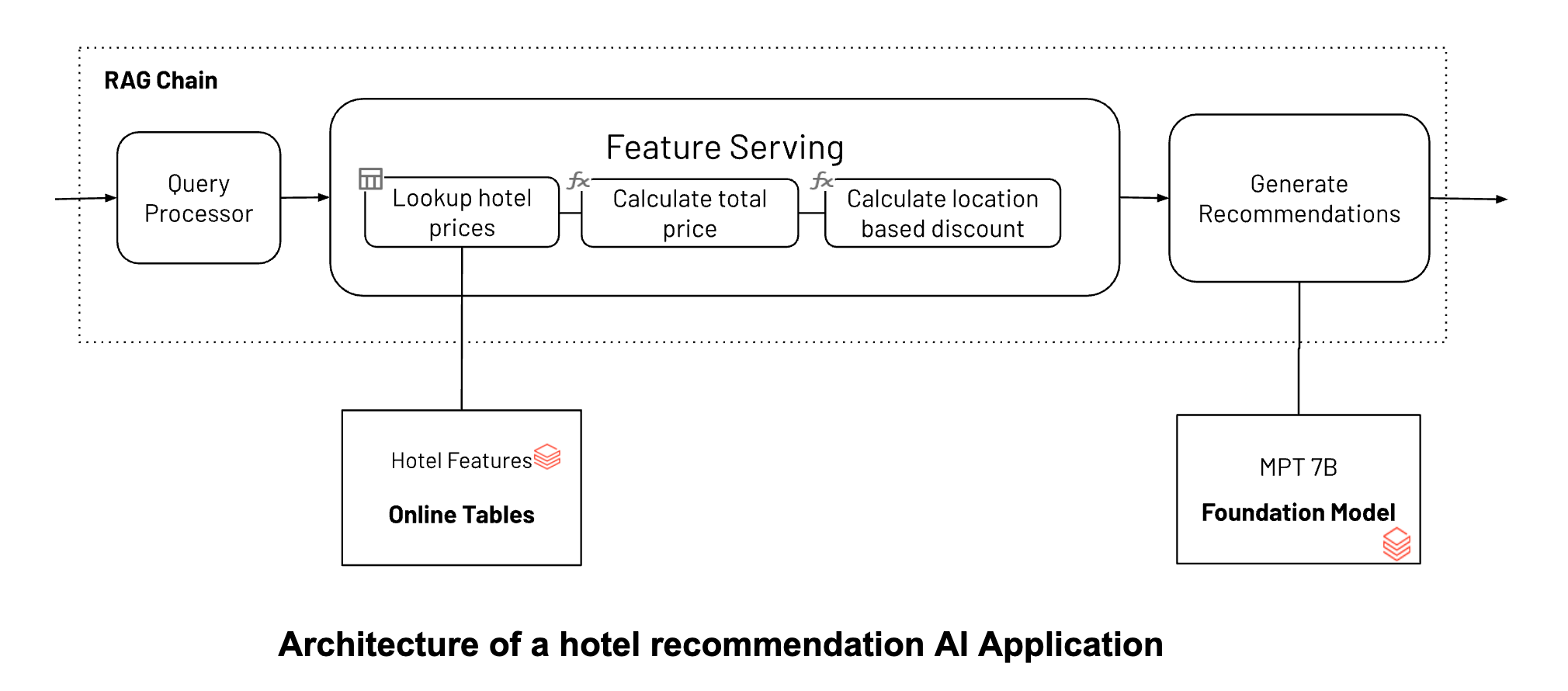
この例では、Unity Catalog内にmain.travel.hotel_pricesというDeltaテーブルがあると仮定しています。 事前に計算されたオフライン機能と、main.travel.compute_hotel_total_pricesと呼ばれる関数があります。 Unity Catalogに登録されている、割引後の合計金額を計算する機能です。 オンデマンド機能の登録方法はこちら(AWS | Azure)をご覧ください。
ステップ1. main.travel.hotel_pricesに 格納されている事前計算された特徴を照会するためのオンラインテーブルを作成します。 UI または REST API/SDK(AWS | Azure)を使用します。
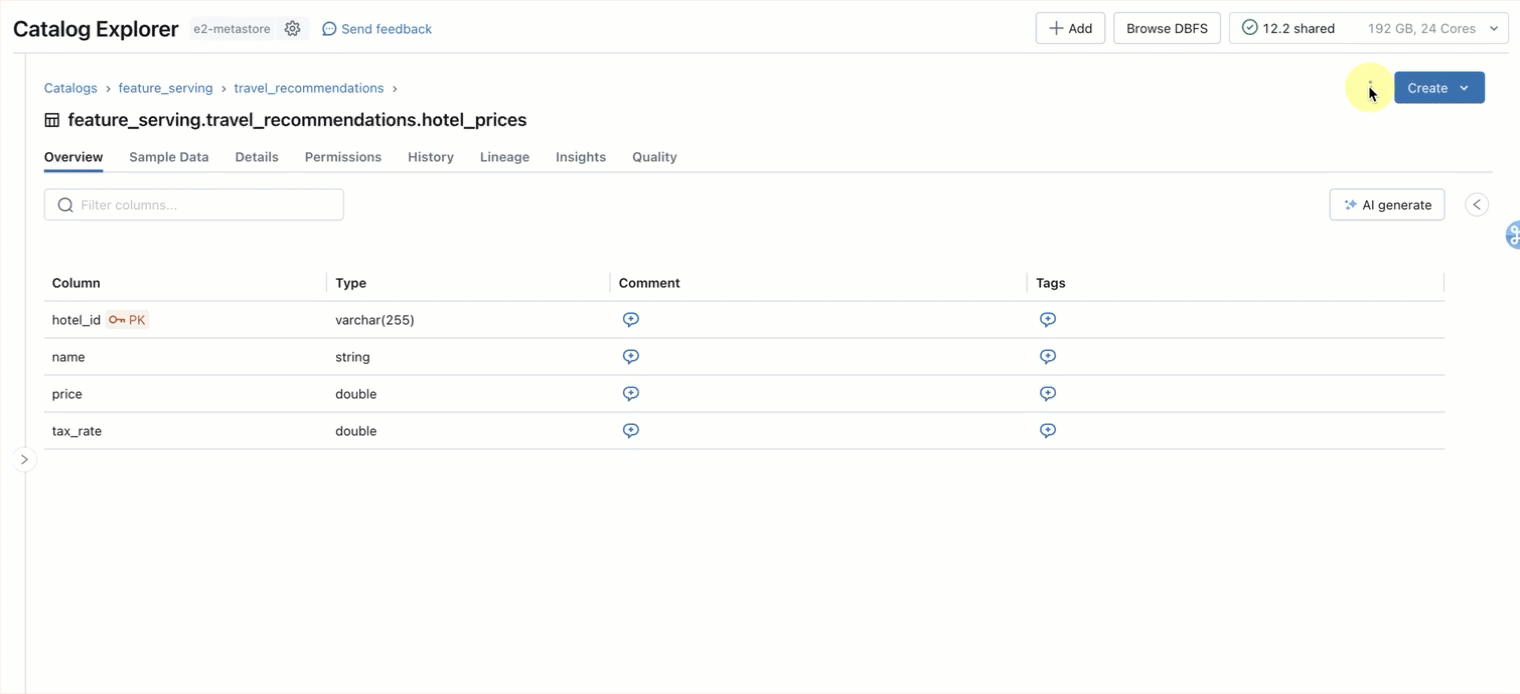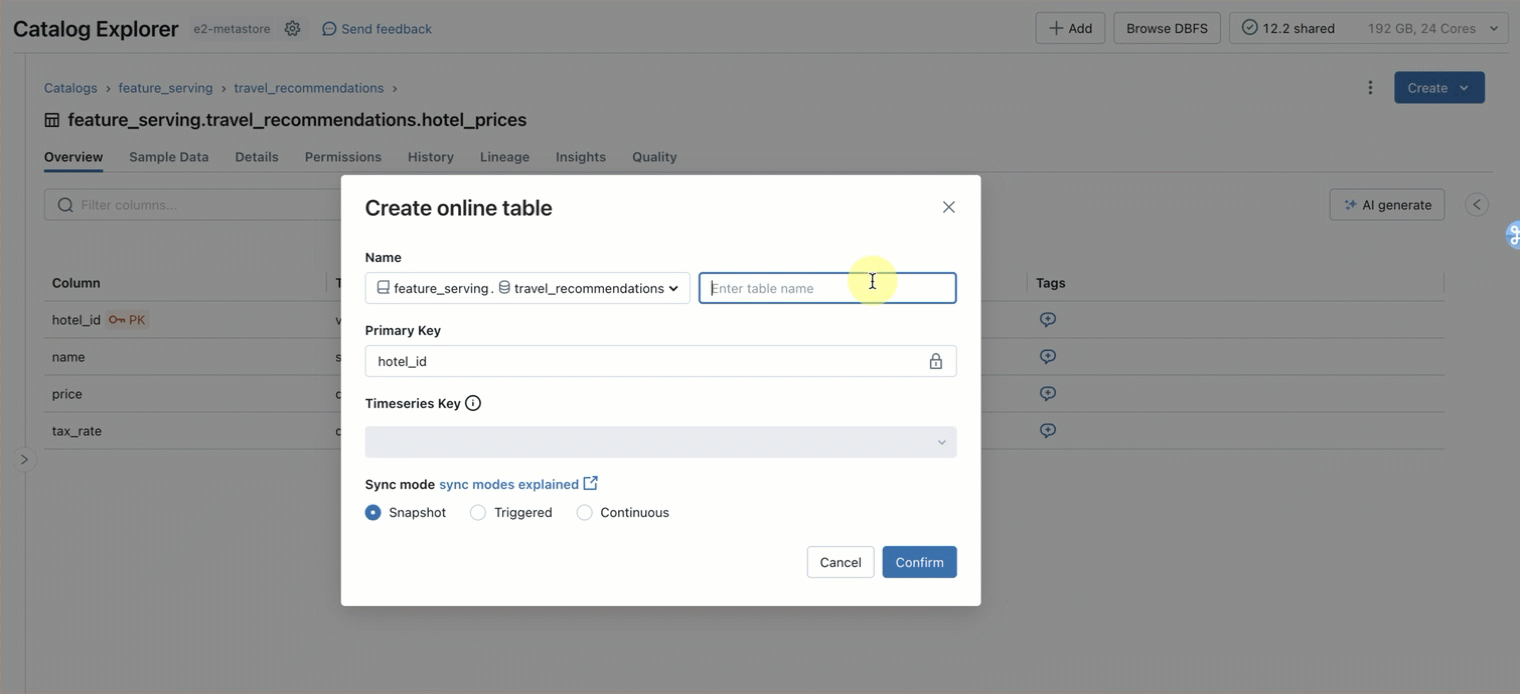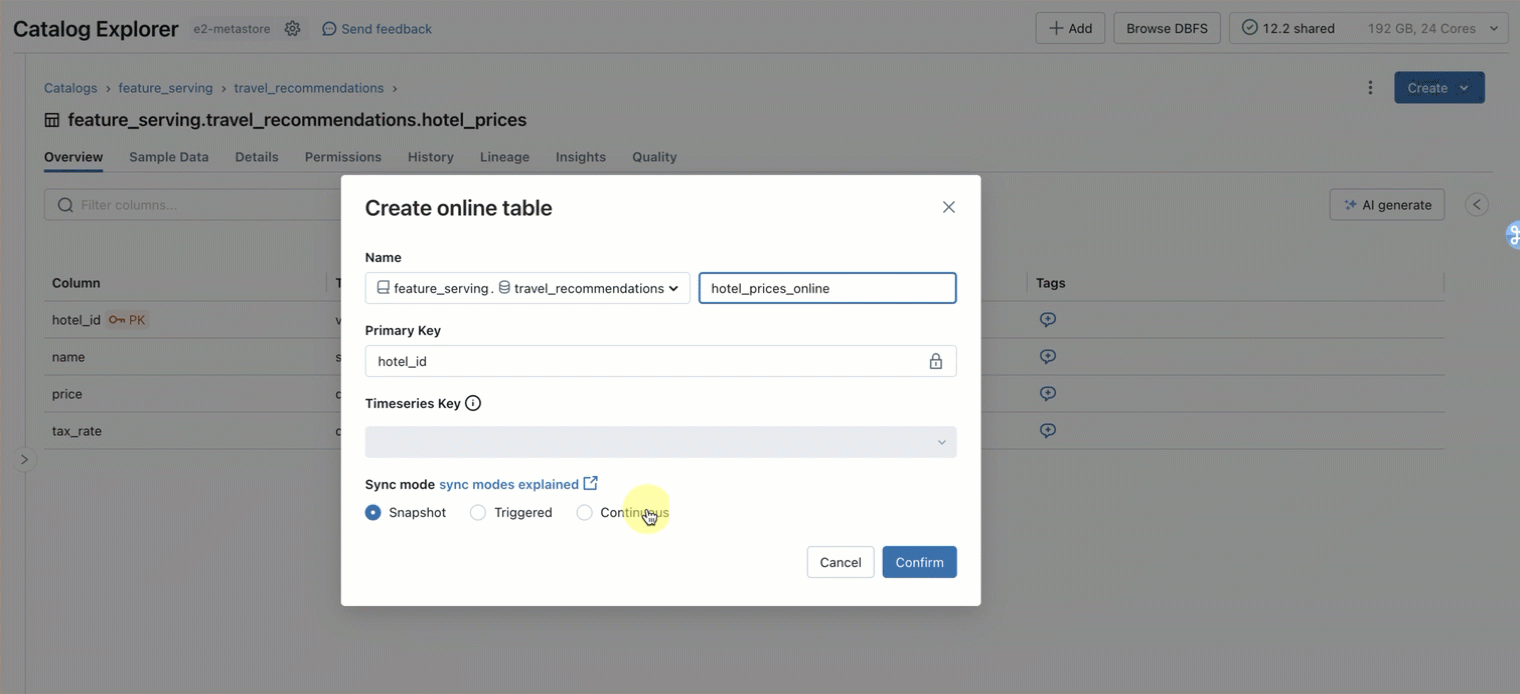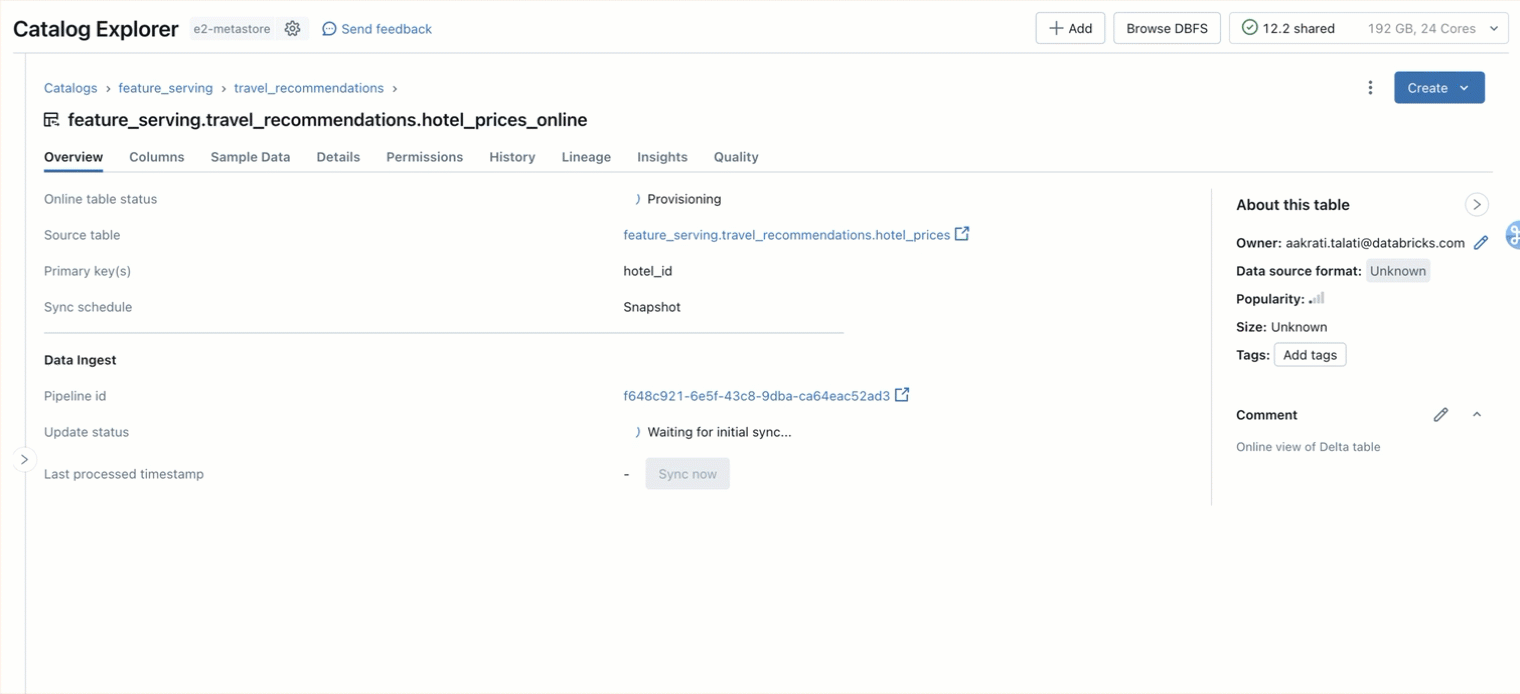
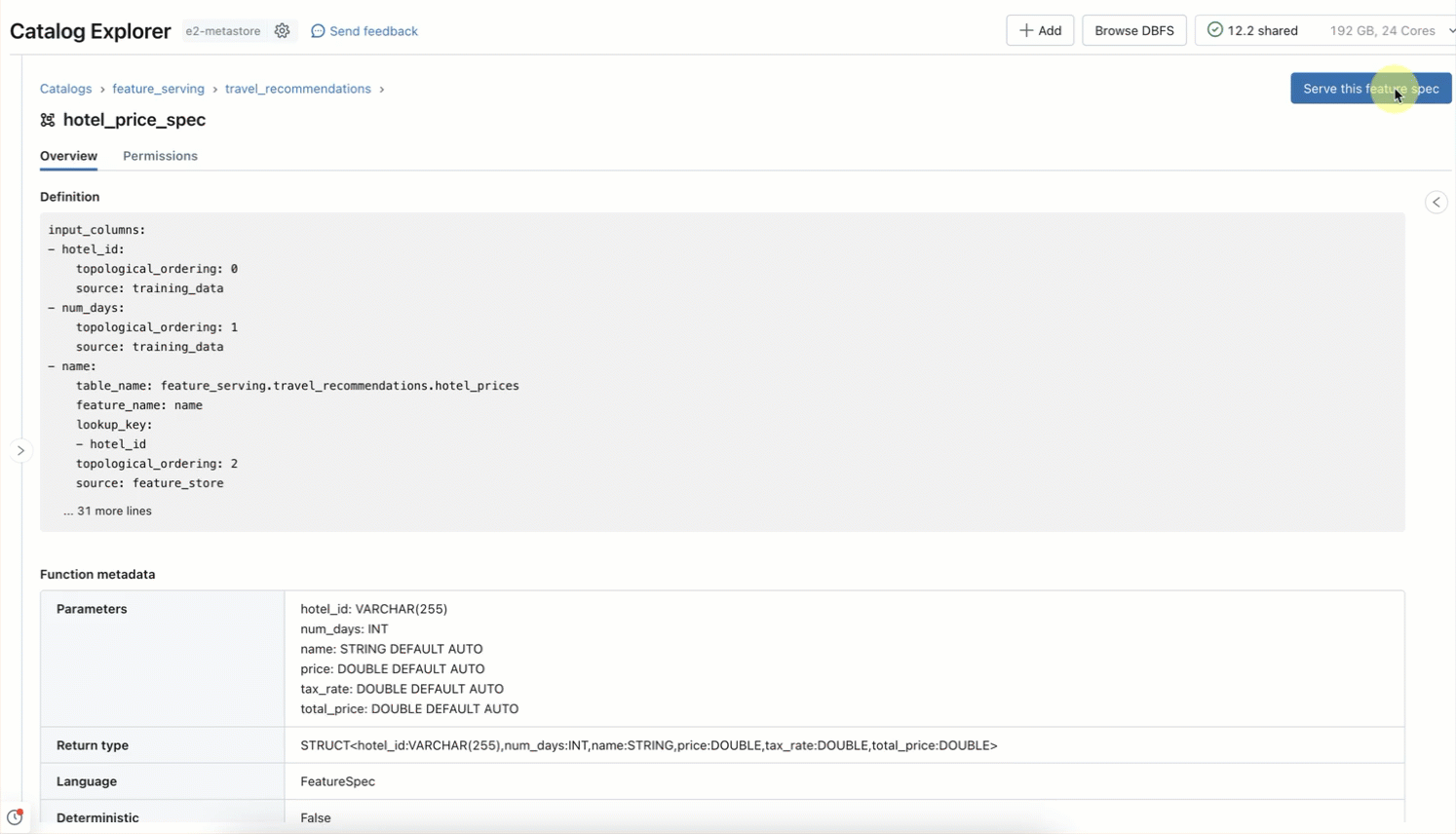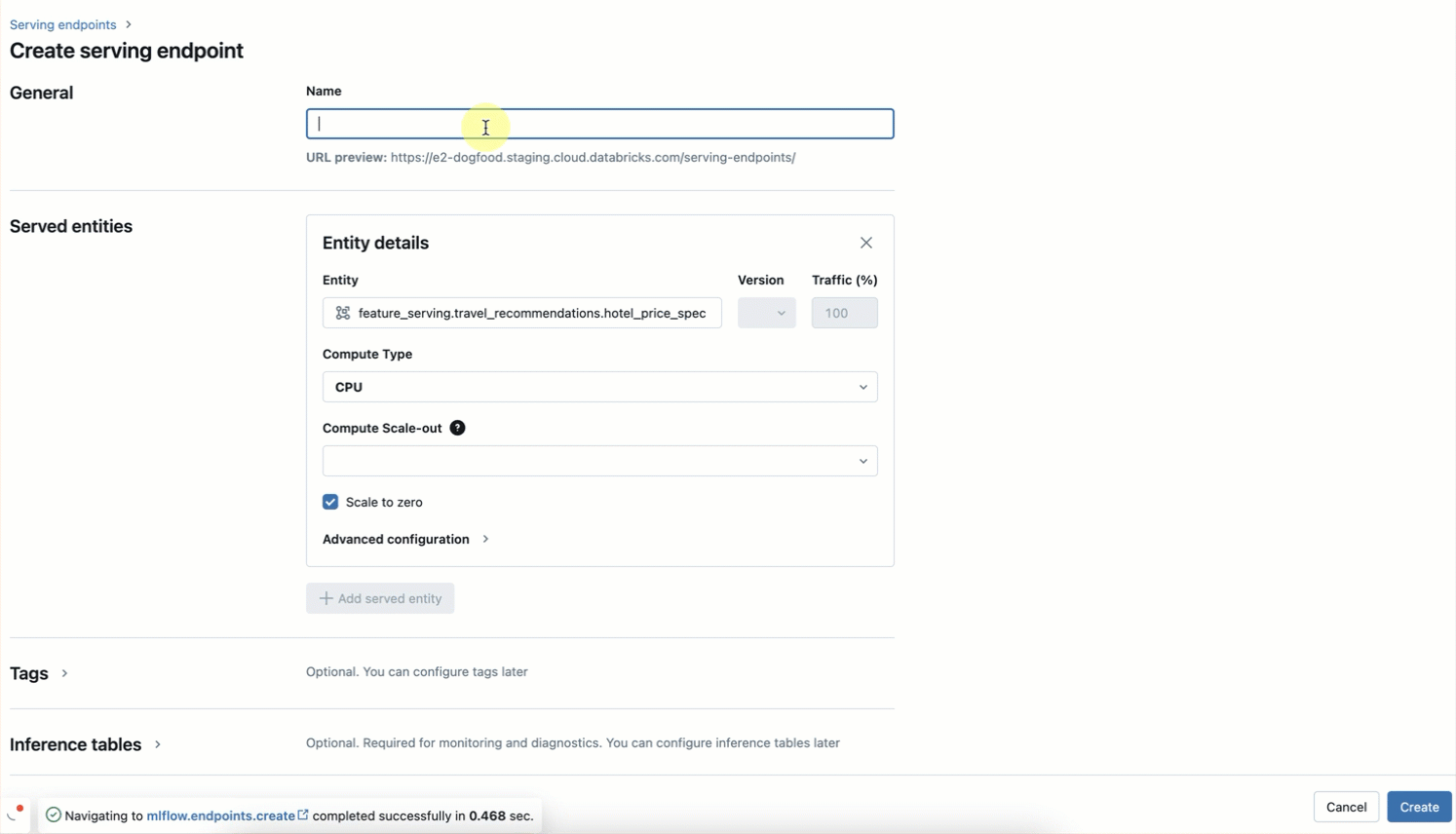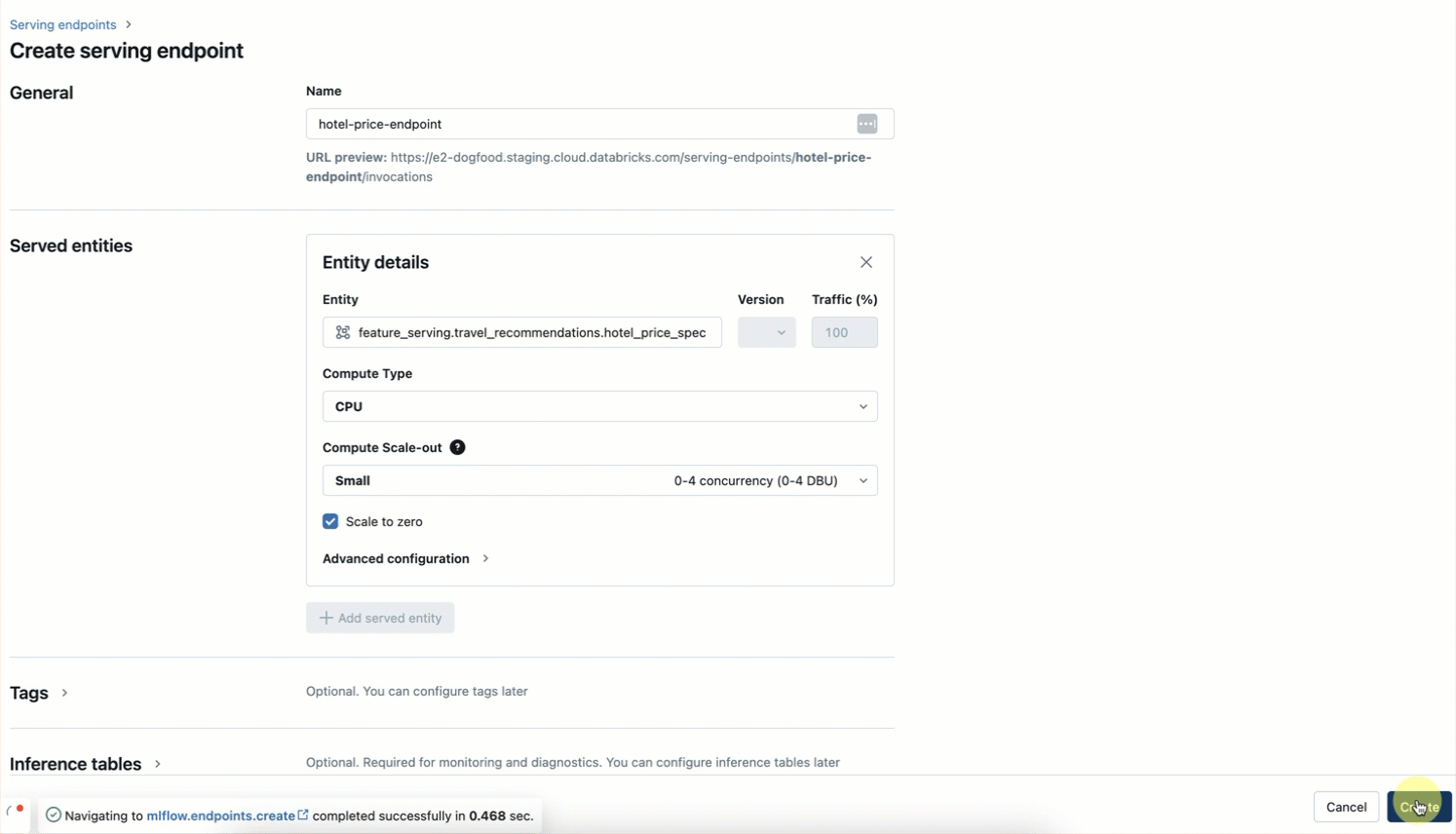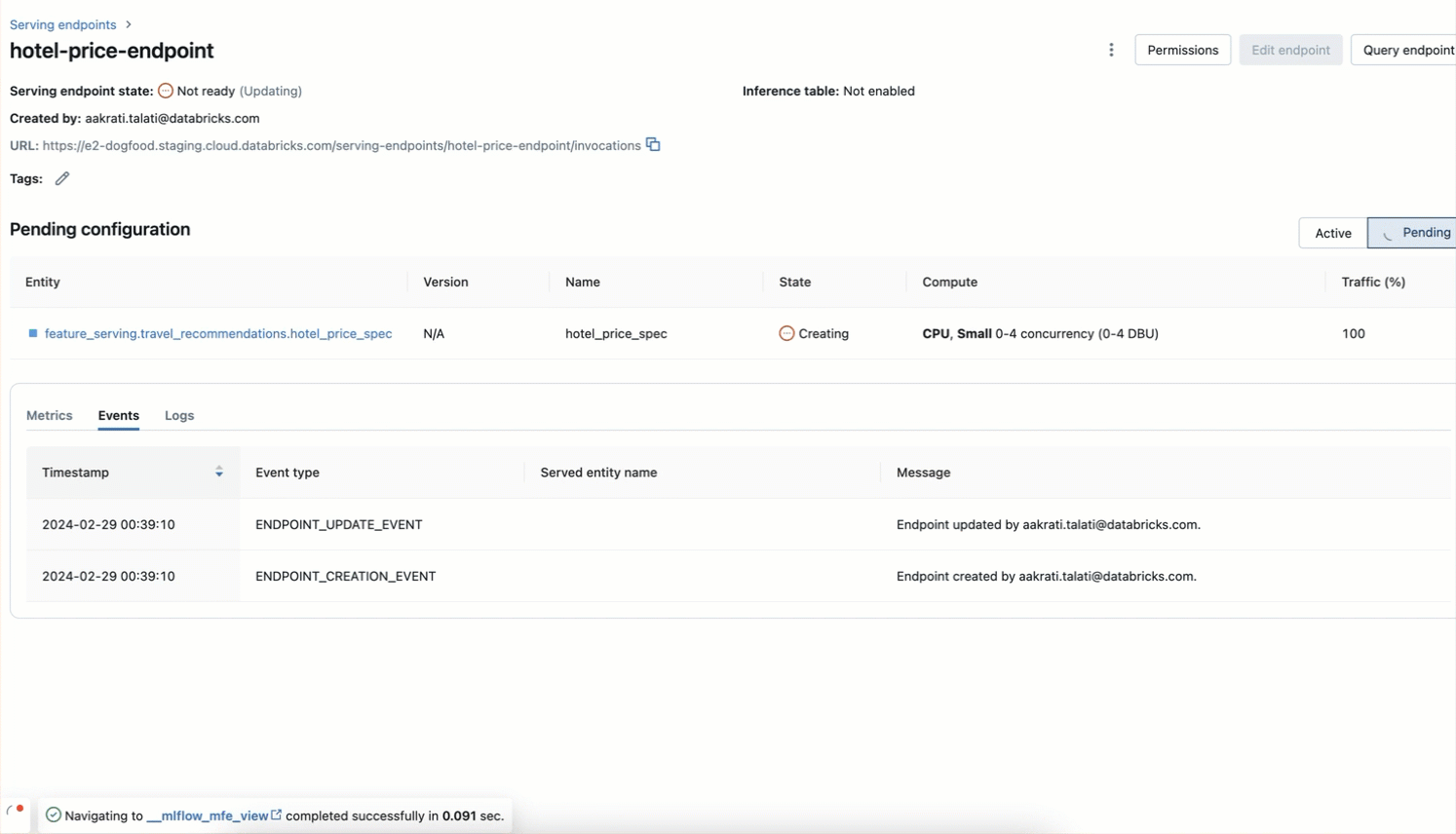
ステップ2. 特徴量サービングのエンドポイント(AWS|Azure)に提供したいMLシグナルを指定してFeatureSpecを作成します。
FeatureSpecは以下のような構成になります:
- 計算済みデータの検索
- オンデマンド機能の計算
- 事前計算とオンデマンド特徴の両方を使用した連鎖的特徴化
ここでは、まず事前に計算されたホテルの価格を調べ、次にユーザーの場所と滞在日数に対する割引に基づいて合計価格を計算することで、連鎖機能を計算したいと思います。

ステップ3. UI または REST API/SDK(AWS | Azure)を使用して、特徴量サービングのエンドポイントを作成します。
当社のサーバーレスインフラストラクチャは、ホテル機能のエンドポイント用にサーバーを管理する必要なく、ワークフローに合わせて自動的にスケールします。 このエンドポイントは、ステップ 2 の FeatureSpec と、ステップ 1 で設定したオンラインテーブルから取得したデータに基づいてフィーチャーを返します。
ステップ4. 特徴量サービングのエンドポイントの準備ができたら、UIまたはREST API/SDKを使用して、プライマリキーとコンテキストデータを使用してクエリを実行できます。
チャットボットがユーザーにパーソナライズされた結果を推奨するのに役立つ合計価格のシグナルを取得することで、複合AIシステムを構築する際に新しい特徴量サービングのエンドポイントを使用できるようになりました。
Databricks 特徴量サービング入門
-
このノートブックの例を使用して、AIアプリケーションにリアルタイム機能を活用してください。
- 特徴量サービングのドキュメント (AWS)(Azure) が一般公開されました。 試してみてください! REST APIとしてML機能のクエリを開始
- Databricks オンラインテーブル (AWS)(Azure) がパブリックプレビューで利用可能になりました。
- Databricksと共有したいユースケースをお持ちですか? [email protected]までお問い合わせください。
2024年のGenAI Payoffにサインアップ:GenAIアプリの構築とデプロイ 3/14開催バーチャルイベント
Databricksの投稿を見逃さないようにしましょう
次は何ですか�?


データサイエンス・ML
October 30, 2024/1分未満