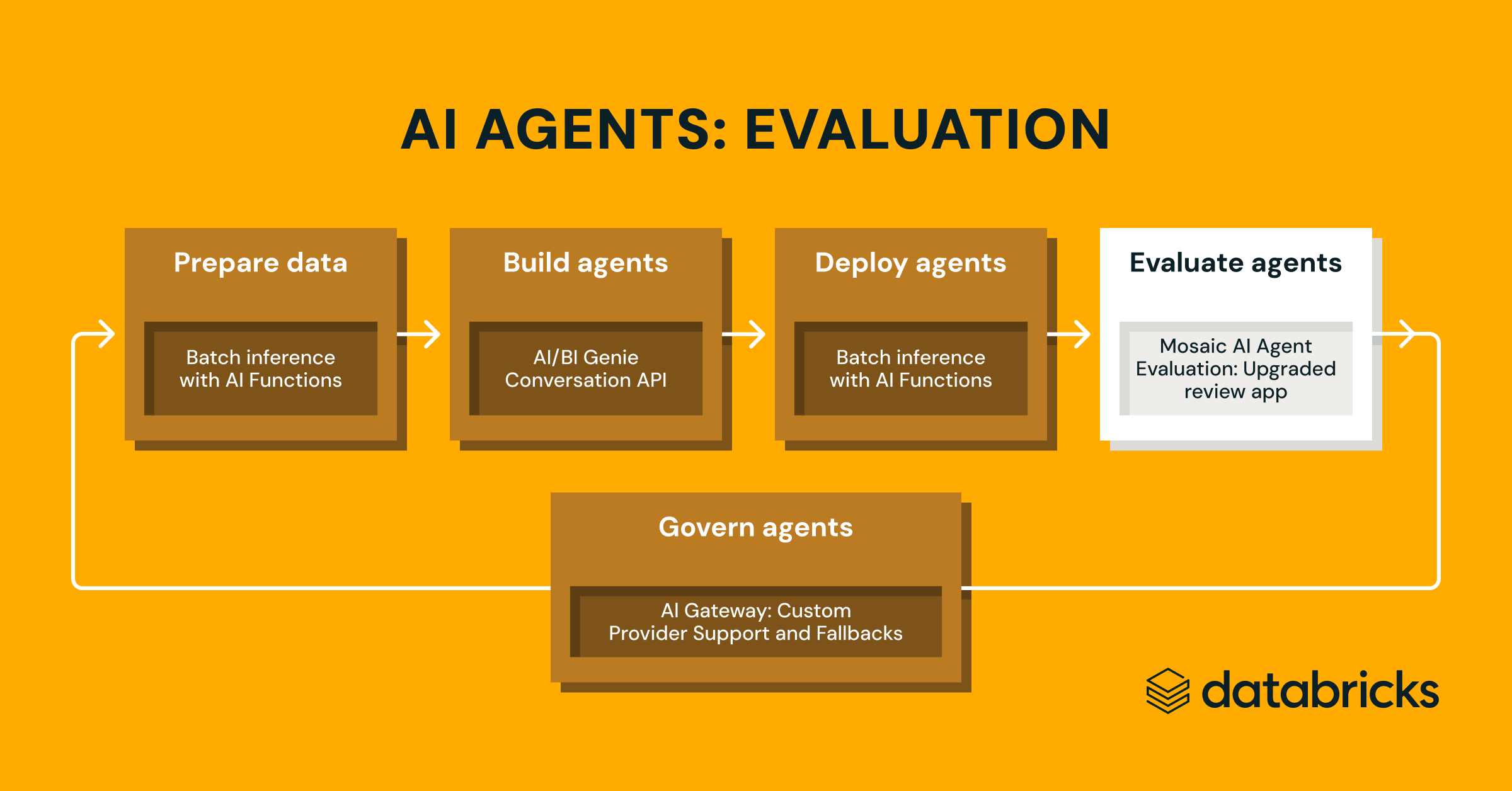
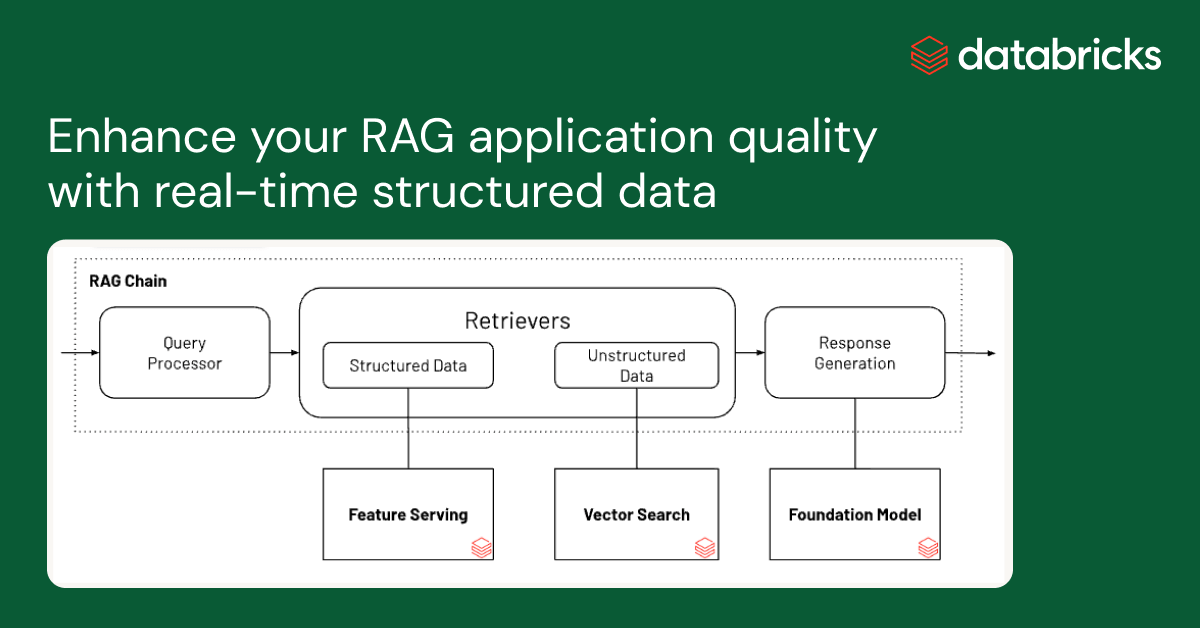
お知らせ
March 12, 2025/6分で読めます
生成 AI
December 9, 2024/2分で読めます
データサイエンス・ML
July 2, 2024/3分で読めます
March 11, 2024/2分で読めます
December 8, 2023/2分で読めます