Unity Catalog ボリュームの一般提供を開始しました!
テーブル形式以外のあらゆるデータの発見、管理、クエリ、共有
公開日: February 22, 2024
によって アドリアナ・イスパス、エイドリアン・イオネスク、ボグダン・ラドゥカヌ、イナ・コレワ、サチン タクール、ジェフ・フレッチャー、ショーン・スミス による投稿
本日 、Unity Catalog ボリュームが AWS、Azure、GCPで一般利用可能になったことを発表 します。 Unity Catalogは、 Databricks Data Intelligence Platformにネイティブに組み込まれた、データおよびAI向けの統合ガバナンスソリューションを提供します。 Unity Catalog ボリュームを使用することで、データおよびAIチームは、表データやMLモデルだけでなく、非構造化データ、半構造化データ、構造化データなど、あらゆる種類のデータのカタログ化、セキュア化、管理、共有、リネージ追跡を一元的に行うことができます。
このブログでは、Unity Catalog ボリュームのコア機能を概説し、さまざまなファイルタイプからデータをロードするスケーラブルなAIおよびインジェストアプリケーションを作成するためにUnity Catalog ボリュームをどのように使用できるかの実用的な例を提供し、GAリリースで導入された機能強化について説明します。
Unity Catalog ボリュームによるテーブル形式以外のデータの管理
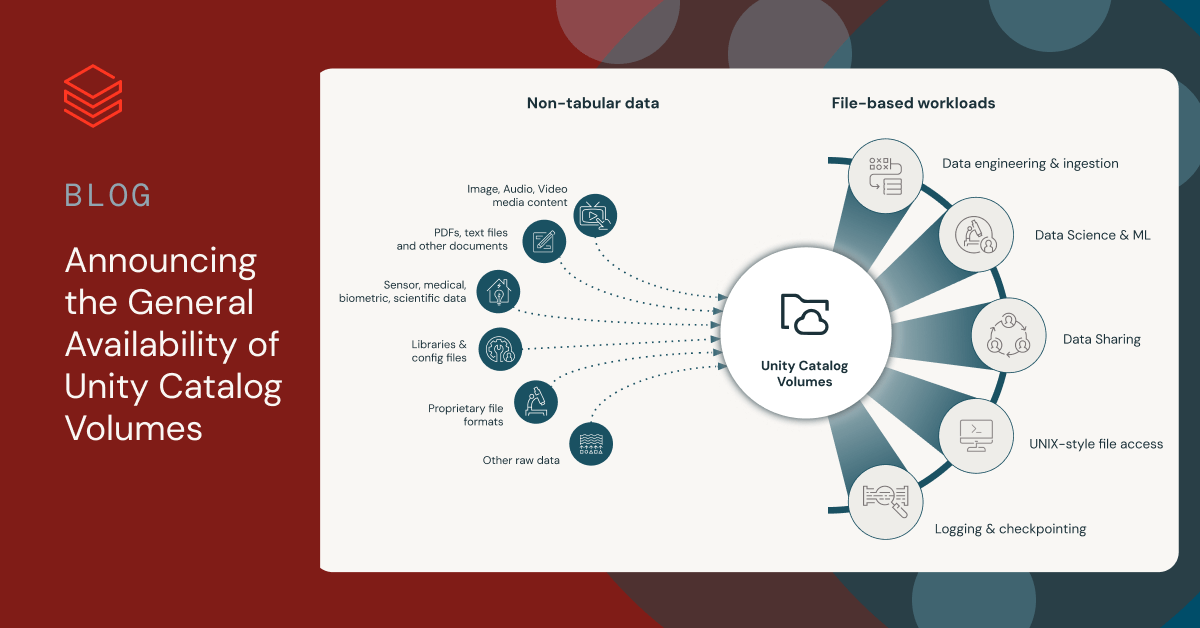
ボリュームは、非テーブル形式データのガバナンスと管理のために設計された Unity Catalog のオブジェクトの一種です 。各ボリュームは、Unity Catalog内のディレクトリとファイルのコレクションであり、クラウド オブジェクト ストレージの場所の論理ストレージユニットとして機能します。 構造化、半構造化、非構造化を問わず 、 あらゆる形式のデータをアクセス、保存、管理する機能を提供します。
レイクハウスアーキテ��クチャでは、アプリケーションは通常ファイルからデータをインポートすることから始めます。 これには、ディレクトリの読み込み、既存ファイルのオープンと読み込み、新規ファイルの作成と書き込みに加え、各ユースケースに特化したさまざまなツールやライブラリを使用したファイルコンテンツの処理が含まれます。
ボリュームを使用すると、形式に関係なく、クラウドストレージのパフォーマンスで非テーブル形式データの広範なコレクションを読み込んで処理する、さまざまなファイルベースのアプリケーションを作成 できます。 Unity Catalog ボリュームでは、DatabricksワークスペースUI、Spark API、Databricksファイルシステムユーティリティ(dbutils.fs)、REST API、Pythonの os モジュールなどの言語ネイティブなファイルライブラリ、SQLコネクタ、Databricks CLI、Databricks SDK、Terraformなど、お好みのツールを使用してファイルを操作できます。
"データ民主化への道のりにおいて、ユーザーが利用できるツールの合理化は極めて重要なステップです。 Unity Catalog ボリュームのおかげで、Databricks ボリュームを介してのみ、ユーザーが非構造化データにアクセスする方法を簡素化できました。 Unity Catalog ボリュームを使用することで、ストレージアカウントへのアクセスに対する複雑なRBACアプローチを、Unity Catalogを使用した構造化データと非構造化データの統一アクセスモデルに置き換えることができました。 ユーザーは、多くのクリックとアクセス方法から、より洗練されたシンプルなUXを保証し、リスクを軽減し、環境全体を強化する、単一の直接アクセスモデルへと移行しました。 " — Sergio Leoni, Head of Data Engineering & Data Platform, Plenitude
パブリック プレビューのブログ投稿では、ボリュームの詳細な概要と、ボリュームによって実現されるユースケースについて説明しました。 以下では、GA リリースで利用可能になった新機能を含む、ボリュームのさまざまな機能を紹介します。ここでは、ファイルからデータをロードする 2 つの実際のシナリオを紹介します。このステップは、AI アプリケーションの構築やデータの取り込みに不可欠です。
AIアプリケーションのためのボリュームの使用
AIアプリケーションは、PDF、画像、動画、音声ファイル、その他の文書など�、大量の非テーブル形式データを扱うことがよくあります。 これは特に、コンピュータビジョンや自然言語処理などの機械学習シナリオに当てはまります。 生成的AIアプリケーションもこのカテゴリーに属し、RAG(Retrieval Augmented Generation:検索拡張生成)のような技術が、表形式ではないデータソースから洞察を抽出するために使用されます。 これらの洞察は、チャットボットインターフェース、カスタマーサポートアプリケーション、コンテンツ作成などを強化する上で非常に重要です。
ボリュームの使用は、AIアプリケーションに以下のような様々なメリットをもたらします:
- 表形式および非表形式AIデータセットの統一ガバナンス:ボリュームで管理される 非テーブル形式データであれ、テーブル形式データであれ、AIアプリケーションに関わるすべてのデータが、同じUnity Catalogの傘下にまとめられます。
- AIアプリケーションのエンドツーエンドのリネージ:AIアプリケーションのリネージは、Unity Catalog ボリュームやテーブルとして整理されたエンタープライズのナレッジベースから、データパイプライン、モデルの微調整、その他のカスタマイズを経て、モデルサービングエンドポイントや生成AIでRAGチェーンをホストするエンドポイントにまで拡張されます。これにより、完全なトレーサビリティ、監査可能性、AIアプリケーションの根本原因分析の加速が可能になります。
- 簡素化された開発者エクスペリエンス:多くの AI ライブラリやフレームワークは、クラウドオブジェクトストレージ API をネイティブサポートしておらず、ローカルファイルシステム上のファイルを想定しています。ボリュームは FUSE をビルトインでサポートしている ため、ユーザーはこれらのライブラリをシームレスに活用しながら、使い慣れた方法でファイルを操作できます。
- AI アプリケーションの応答とソースデータセットの同期の合理化:ジョブファイル到着トリガーやAuto Loaderのファイル検出などの機能が、ボリュームをサポートするように強化されました。ボリュームに追加された最新のファイルでAIアプリケーションの応答を自動的に更新して、最新の状態に保つことができます。
例として、RAGアプリケーションを考えてみましょう。このようなAIアプリケーションに企業データを組み込む場合、初期段階の1つはドキュメントのアップロードと処理です。このプロセスは、ボリュームを使用することで簡素化されます。 生ファイルがVolumeに追加されると、ソースデータは小さなチャンクに分解され、エンベッディングによって数値フォーマットに変換され、ベクターデータベースに格納されます。 ベ�クトル検索と大規模言語モデル(LLM)を使用することで、 RAGアプリケーションはユーザがデータを照会した際に適切な応答を提供します。
以下では、コンピュータにローカルに保存されたPDFファイルのコレクションから始めて、RAGアプリケーションを作成する最初のステップを示します。完全なRAGアプリケーションについては、関連するブログ記事とデモを参照して ください。
まずはPDFファイルをzipファイルに圧縮してアップロードします。 REST APIやDatabricks SDKのような他のツールを使用しても同様の手順を実行できますが、簡単のためにCLIを使用してPDFをアップロードします。 まずボリュームをリストアップしてアップロード先を決め、次にファイル用のディレクトリを作成し、最後にアーカイブをこの新しいディレクトリにアップロードします:
ここで、Databricksノートブックからアーカイブを解凍します。ボリュームのビルトイン FUSE サポートにより、ボリューム内のファイルがある場所で直接コマンドを実行することができます:
PythonのUDFを使って、PDFのテキストを抽出し、チャンク化し、埋め込みを作成します。 gen_chunks UDFはボリュームのパスを受け取り、テキストチャンクを出力します。 gen_embedding UDFはテキストチャンクを処理してベクトル埋め込みを返します。
次に、Auto Loaderと組み合わせてUDFを使用し、以下のようにチャンクをDeltaテーブルにロードします。 このDeltaテーブルは、 RAGアプリケーションに不可欠なコンポーネントであるVector Searchインデックスとリンクする必要が あります。 簡潔にするために、インデックスを設定するために必要な手順については、関連するチュートリアルを参照してください。
本番環境では、RAGアプリケーションは多くの場合、常に変化する非構造化データの広範な知識ベースに依存しています。 したがって、アプリケーションの応答を最新に保ち、データの重複を防ぐには、最新のデータでVector Searchインデックスを自動更新することが極めて重要です。 これを実現するには、前述したように、コードロジックを使用してソースファイルの処理を自動化するDatabricksワークフローパイプラインを作成できます。ファイル到着トリガーの監視場所としてボリュームを追加設定すると、ボリュームに追加された新しいファイルがパイプラインによって自動的に処理されます。 これらのファイルを定期的にアップロードするには、CLIコマンド、UI、REST API、またはSDKなど、さまざまな方法を使用できます。
社内データだけでなく、企業では、キュレーションされたデータセットやパートナーやベンダーから購入した��データなど、外部から提供されたデータも活用することができます。 Volume Sharingを使用することで、このようなデータセットをRAGアプリケーションに組み込むことができます。Volume Sharingのデモをご覧ください。
インジェスト・パイプラインの最初にボリュームを使用
前節では、ボリュームに格納された非構造化ファイルフォーマットからデータをロードする方法を示しました。 ボリュームは、JSON や CSV のような半構造化形式、または Parquet のような構造化形式からのデータ読み込みにも使用できます。
ボリュームを使用して、Auto Loader、Delta Live Tables(DLT)、COPY INTO、または CTAS コマンドを実行するなど、お好みの取り込みツールを使用してテーブルにデータをロード できます。さらに、ジョブファイル到着トリガーやAuto Loaderファイル検出などの機能を活用することで、新しいファイルがボリュームに追加されたときに、テーブルが自動的に更新されるように することができます。 ボリュームを含むインジェスションワークロードは、DatabricksワークスペースまたはSQLコネクタから実行できます。
CTAS、COPY INTO、DLTコマンドでVolumesを使用する例をいくつか紹介します。 Auto Loaderの使い方は、前のセクションで取り上げたコードサンプルとよく似ています。
また、新しく導入されたボリュームのテーブル作成ウィザードを使用して、ボリュームのデータを UI からテーブルにすばやくロードすることもできます。 これは、コードを書く必要なくUIを使って素早くテーブルを作成したい場合、アドホックなデータサイエンス作業に特に役立ちます。 下のスクリーンショットがそのプロセスです。

Unity Catalog ボリューム GA リリースの概要
ボリュームの一般提供リリースには、いくつかの新機能と機能強化が含まれています。
要約すると、GAリリースの内容は以下の通りです:
- Databricks MarketplaceのDelta SharingとVolumesによるボリューム共有:Delta Sharingでボリュームを共有できるようになりました。これにより、PDF、画像、ビデオ、オーディオファイル、その他のドキュメントやアセット、テーブル、ノートブック、AIモデルなど、表形式ではないデータの広範なコレクションを、クラウド、リージョン、アカウント間で安全��に共有することができます。また、ビジネスユニットやパートナー間のコラボレーションや、新しいコラボレーターのオンボーディングも簡素化します。 さらに、お客様はDatabricks MarketplaceでVolumes Sharingを活用することができ、データプロバイダーはデータコンシューマーと表形式以外のデータを簡単に共有することができます。ボリューム共有は現在 AWS、Azure、GCPでパブリックプレビュー中です。
- お好みのツールを使用したファイル管理:Databricks CLI (AWS | Azure | GCP)、Files REST API (AWS | Azure | GCP) - 現在パブリックプレビュー中、および Databricks SDKs for (AWS | Azure | GCP)、さらにPython、Go、Node.js、および JDBC Databricks SQL コネクタは、ボリューム (AWS | Azure | GCP) に保存されたファイルのアップロード、ダウンロード、および削除を可能にする PUT、GET、および REMOVE SQL コマンドを提供します。
- ScalaおよびPython UDFとScala IOにおけるボリュームのサポート:すべてのコンピュートアクセ�スモード(AWS | Azure | GCP)において、UDFからボリュームのパスにアクセスし、ScalaでIOオペレーションを実行できるようになりました。
- ボリューム用のジョブファイル到着トリガーのサポート: 新しいファイルがボリュームに追加されたときに複雑なパイプラインをトリガーする便利な方法です。
- クラウドストレージ URI を使用してファイルにアクセス:Databricksのボリュームパス (AWS | Azure | GCP) に加えて、クラウドストレージURIを使用して外部ボリュームのデータにアクセスできるようになりました。これにより、ボリュームの採用を開始する際に既存のコードを使用しやすくなります。
- ボリュームのクラスタライブラリ、ジョブ依存関係、およびinitスクリプトのサポート:UIとAPIの両方から、クラスタライブラリ、ジョブ依存関係、およびinitスクリプトのソースとしてボリュームがサポートされるようになりました。 詳細はこの関連 ブログ記事を参照してください。
- タグの検出:UI、SQLコマンド、informationスキーマ(AWS | Azure | GCP)を使用して、ボリュームレベルのタグ付けを定義および管理できるようになりました。
- ボリュームUIの強化:ボリュームUI がアップグレードされ、ファイルからのテーブル作成、複数ファイルの一括ダウンロードと削除など、さまざまなファイル管理操作がサポートされました。また、アップロードとダウンロードの最大ファイルサイズを 2 GB から 5 GB に引き上げました。
ボリューム入門
ボリュームを使い始めるには、包括的��なステップバイステップガイドに従って、ボリュームの主な機能のクイックツアーをご覧ください。 最初のボリューム(AWS | Azure | GCP )を作成する詳細な手順については、当社のドキュメントを参照してください。 ボリュームを作成したら、カタログエクスプローラー(AWS | Azure | GCP)を活用してその内容を調べたり、SQL構文を使用してボリュームを管理したり(AWS | Azure | GCP )、他の共同作業者とボリュームを共有したりできます(AWS | Azure | GCP)。また、ボリュームを最大限に活用するために 、ベストプラクティス(AWS | Azure | GCP)を確認することをお勧めします。