Mosaic AI Agent Framework および Agent Evaluation の発表
本番運用品質のエージェント型および検索型拡張生成アプリの構築

Databricks は、Data + AI Summit 2024 で、生��成 AI クックブックとともに、Mosaic AI Agent Framework および Agent Evaluation のパブリック プレビューを発表しました。
これらのツールは、Databricksデータインテリジェンスプラットフォーム上で高品質なエージェントおよび RAG アプリケーションを構築および展開できるように設計されています 。
高品質な生成AIアプリケーションの構築における課題
生成 AI アプリケーションの概念実証を構築するのは比較的簡単ですが、高品質のアプリケーションを提供することは、多くの顧客にとって困難であることが判明しています。 顧客向けアプリケーションに必要な品質基準を満たすには、AI 出力が正確で安全であり、管理されている必要があります。 このレベルの品質に到達するために、開発者は次のことに苦労しています
- アプリケーションの品質を評価するために適切なメトリクスを選択する
- 人間からのフィードバックを効率的に収集し、アプリケーションの品質を測定する
- 品質問題の根本原因を特定する
- 本番展開前に、アプリケーションの品質を迅速に改善するための反復を行う
Mosaic AI Agent Framework および Agent Evaluation の紹介
Mosaic Research チームとのコラボレーションにより、Agent Framework と Agent Evaluation は、これらの課題に対処するために特別に構築されたいくつかの機能を提供します。
人間によるフィードバックを迅速に取得 - Agent Evaluation を使用すると、組織全体の専門家を招待してアプリケーションをレビューし、Databricks ユーザーでなくても応答の品質に関するフィードバックを提供できるため、生成 AI アプリケーションに対する高品質の回答がどのようなものか定義できます。
GenAI アプリケーションを簡単に評価 - Agent Evaluation は、Mosaic Research と共同で開発された一連のメトリクスを提供し、アプリケーションの品質を測定します。人間による応答とフィードバックが評価テーブルに自動的に記録され、結果をすばやく分析して潜在的な品質の問題を特定できます。システムが提供する AI 審査員は、正確性、幻覚、有害性、有用性などの一般的な基準に基づいてこれらの応答を評価し、品質の問題の根本原因を特定します。これらの審査員は、主題の専門家からのフィードバックを使用して調整されますが、人間のラベルなしで品質を測定することもできます。
その後、Agent Framework を使用してアプリケーションのさまざまな構成を実験および調整し、これらの品質の問題に対処し、各変更がアプリの品質に与える影響を測定できます。 品質しきい値に達したら、Agent Evaluation のコストとレイテンシのメトリックを使用して、品質/コスト/レイテンシの最適なトレードオフを決定できます。
高速でエンド�ツーエンドの開発ワークフロー - Agent Framework はMLflowと統合されており、開発者は log_model や mlflow.evaluate などの標準 MLflow API を使用して生成 AI アプリケーションをログに記録し、その品質を評価できます。品質に満足したら、開発者は MLflow を使用してこれらのアプリケーションを本番運用にデプロイし、ユーザーからフィードバックを得て品質をさらに向上させることができます。Agent Framework と Agent Evaluation は MLflow およびデータ インテリジェンス プラットフォームと統合されており、生成 AI アプリケーションを構築およびデプロイするための完全に舗装されたパスを提供します。
アプリのライフサイクル管理 - Agent Framework は、権限の管理から SDK を使用した展開まで、エージェント アプリケーションのライフサイクルを管理するための簡素化された Mosaic AI Model Serving を提供します。
Agent Framework と Agent Evaluation を使用して高品質のアプリケーションの構築を開始できるようにするために、生成 AI クックブックは、POC から本番運用までアプリを移行するためのすべての手順を示し、アプリケーションの品質を向上できる最も重要な構成オプションとアプローチを説明する決定的なハウツー ガイドです。
高品質の RAG エージェントの構築
これらの新しい機能を理解するために、Agent Framework を使用して高品質のエージェント アプリケーションを構築し、Agent Evaluation を使用してその品質を向上させる例を見てみましょう。この例の完全なコードと、より高度な例はこちらにある生成 AI クックブックで確認できます。
この例では、事前に作成されたベクターインデックスから関連するチャンクを取得し、クエリへの応答として要約する単純な RAG アプリケーションを構築してデプロイします。 RAG アプリケーションは、ネイティブ Python コードを含む任意のフレームワークを使用して構築できますが、この例では Langchain を使用しています。
最初に行うことは、MLflow を活用してトレースを有効にし、アプリケーションをデプロイすることです。 これは、アプリケーションコード(上記)に 3 つの単純な行を追加することで実現でき、Agent Framework がトレースを提供し、アプリケーションを監視およびデバッグする簡単な方法を提供します。
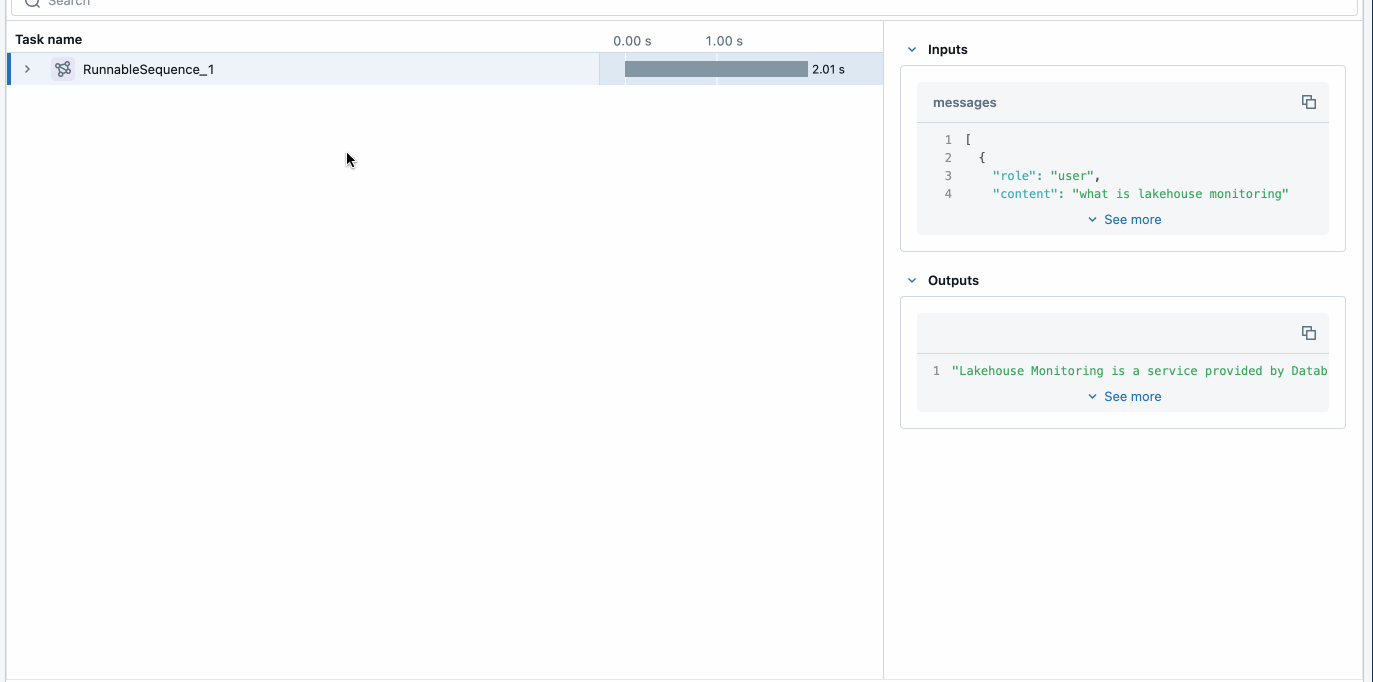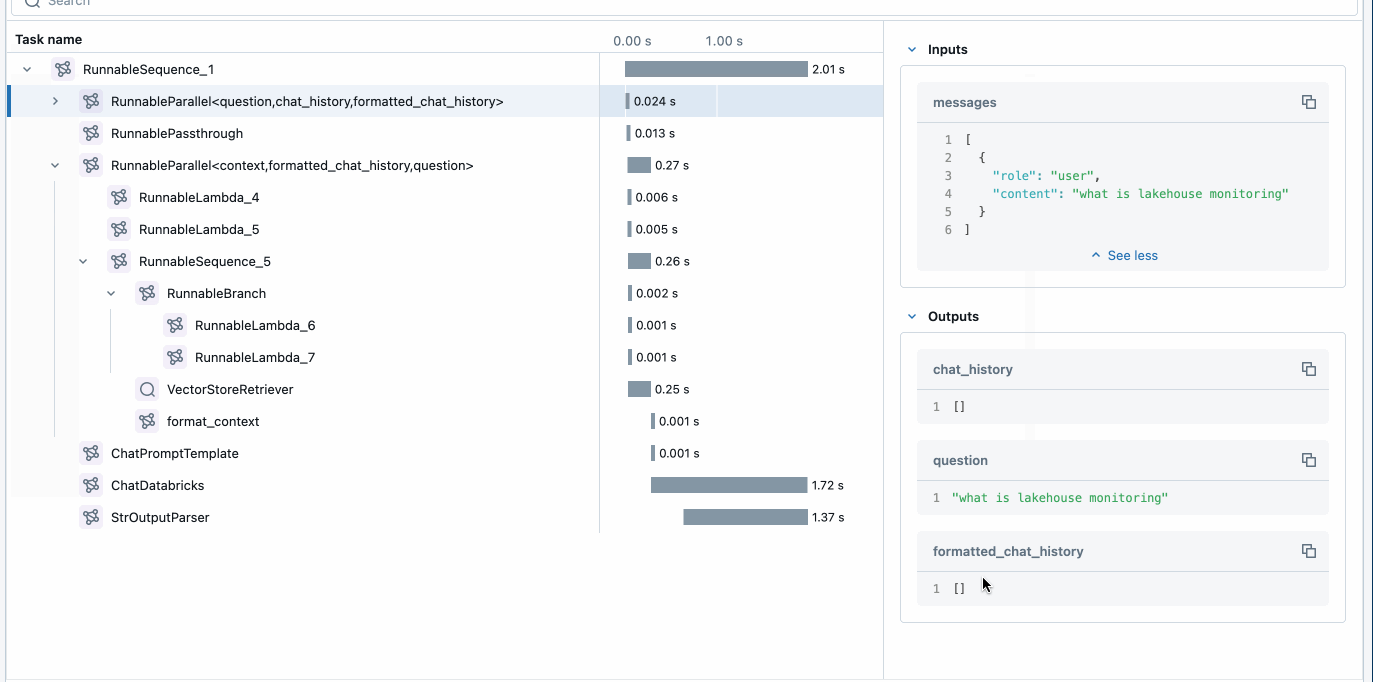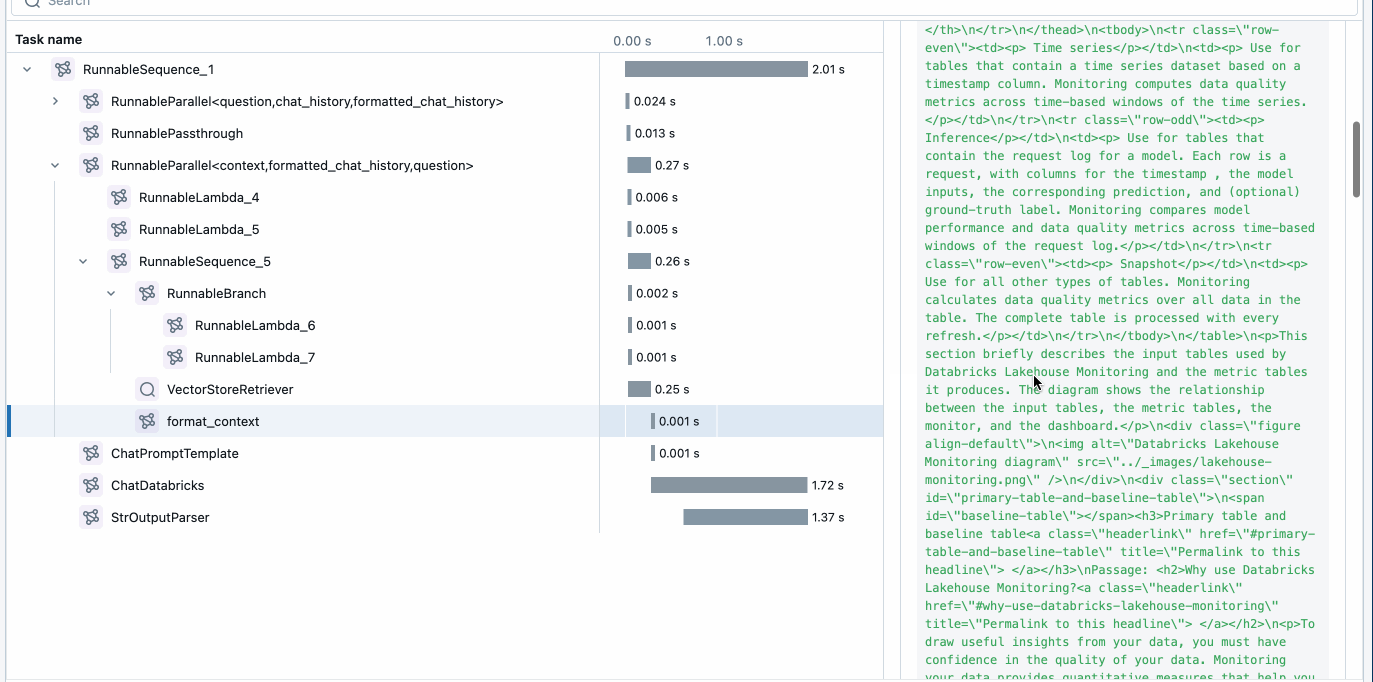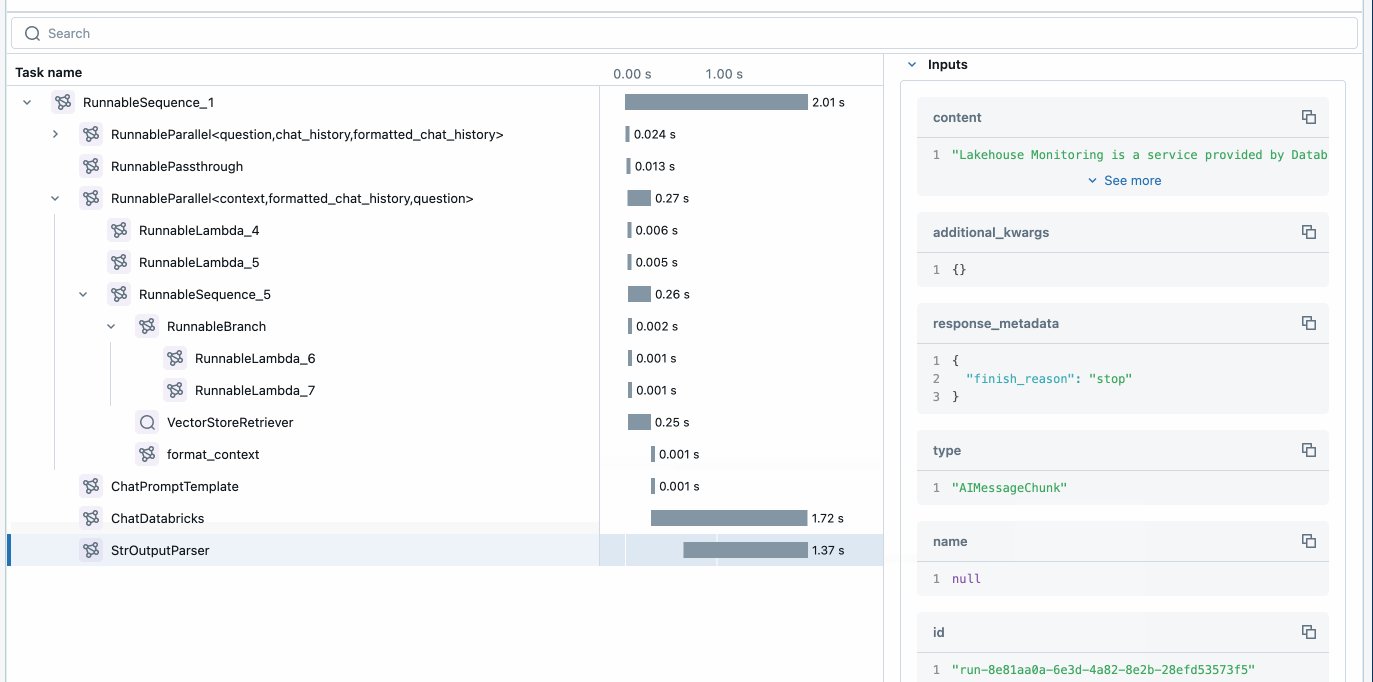
MLflow Tracing は、開発中および本番運用中にアプリケーションの監視を可能にします。
次のステップは、生成 AI アプリケーションを Unity Catalog に登録し、概念実証としてデプロイして、Agent Evaluation のレビューアプリケーションを使用して関係者からフィードバックを得ることです。
ブラウザのリンクを関係者と共有して、すぐにフィードバック��を受け取ることができます。 フィードバックは Unity Catalog に Delta テーブルとして保存され、評価データセットの構築に使用できます。
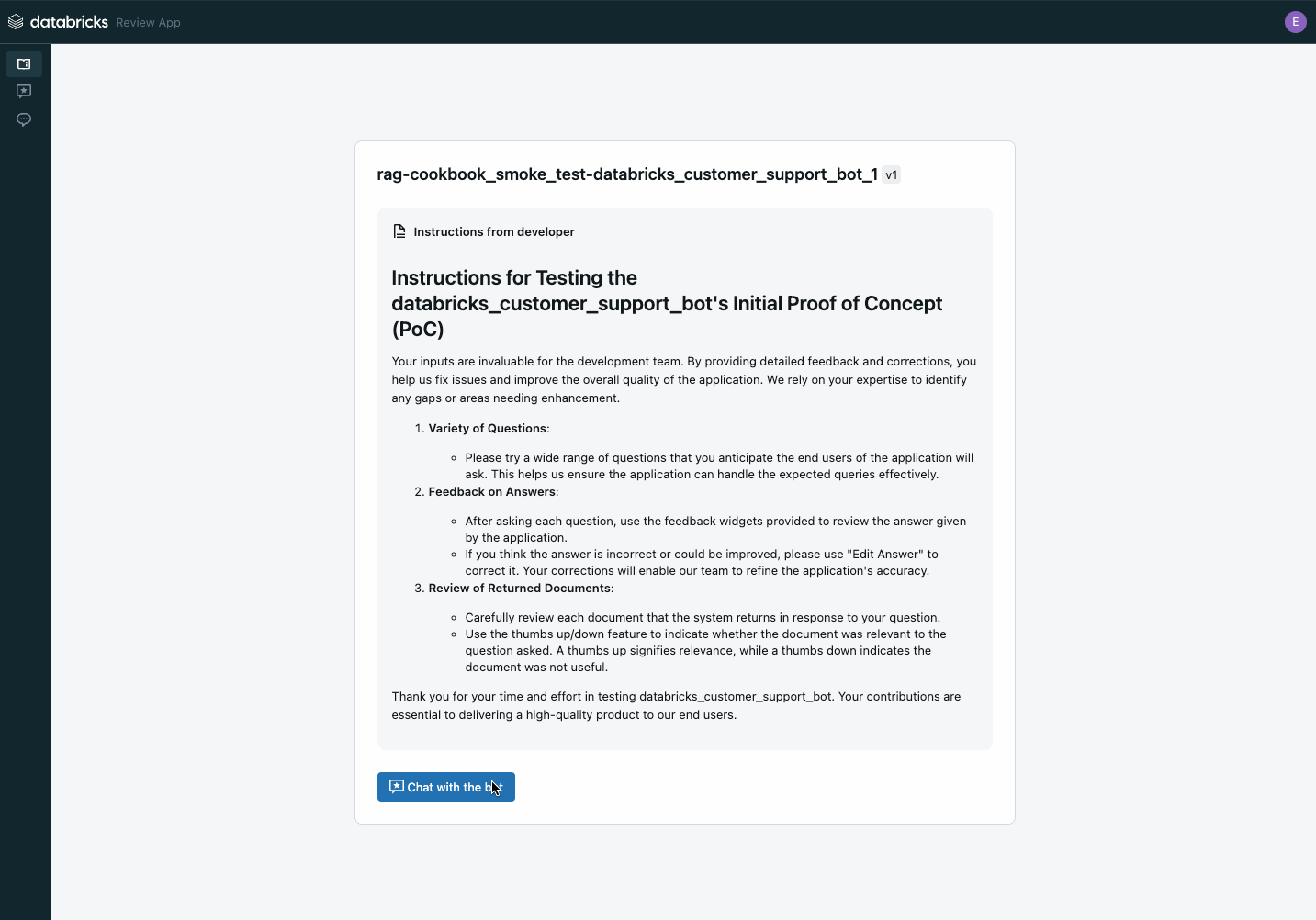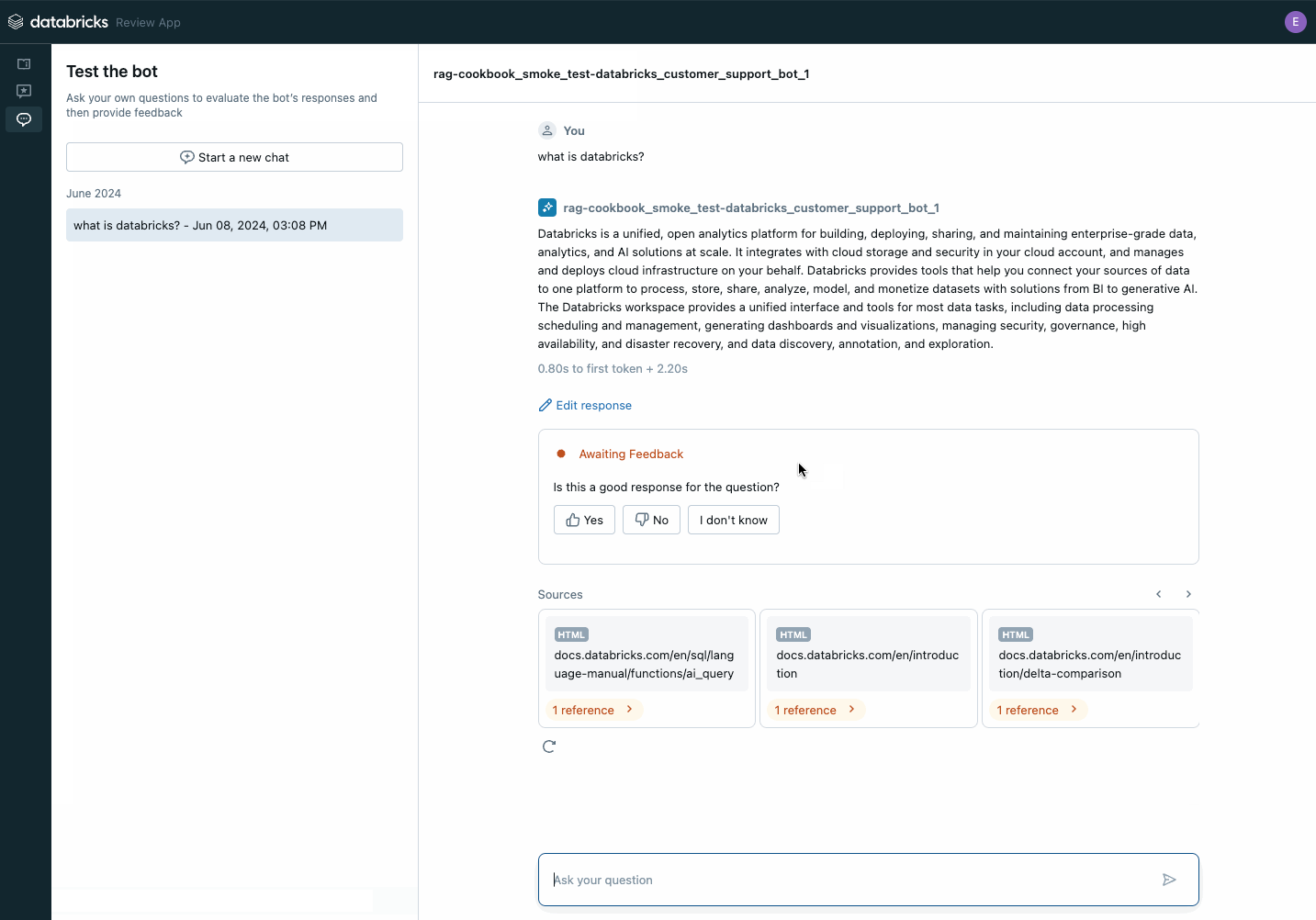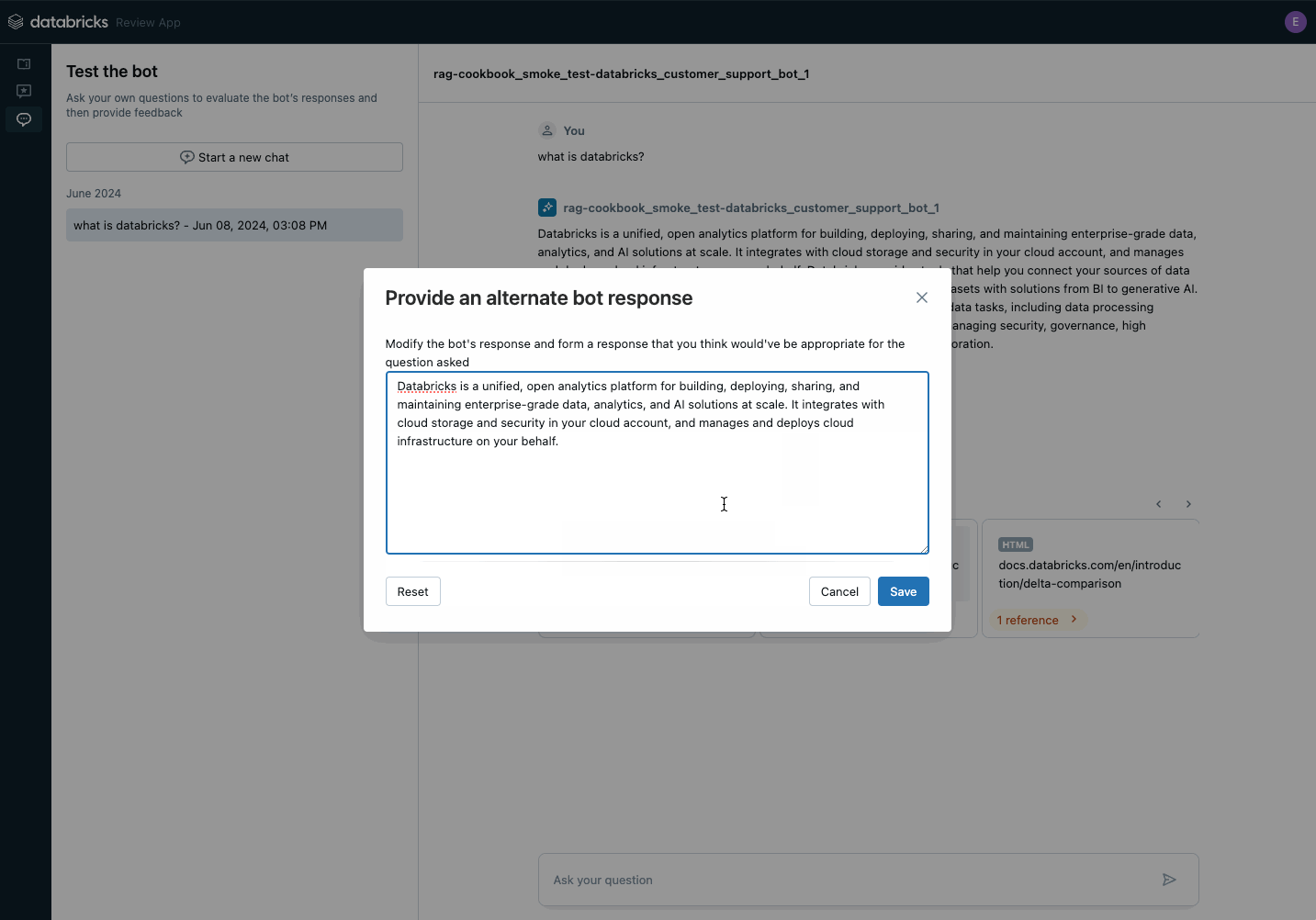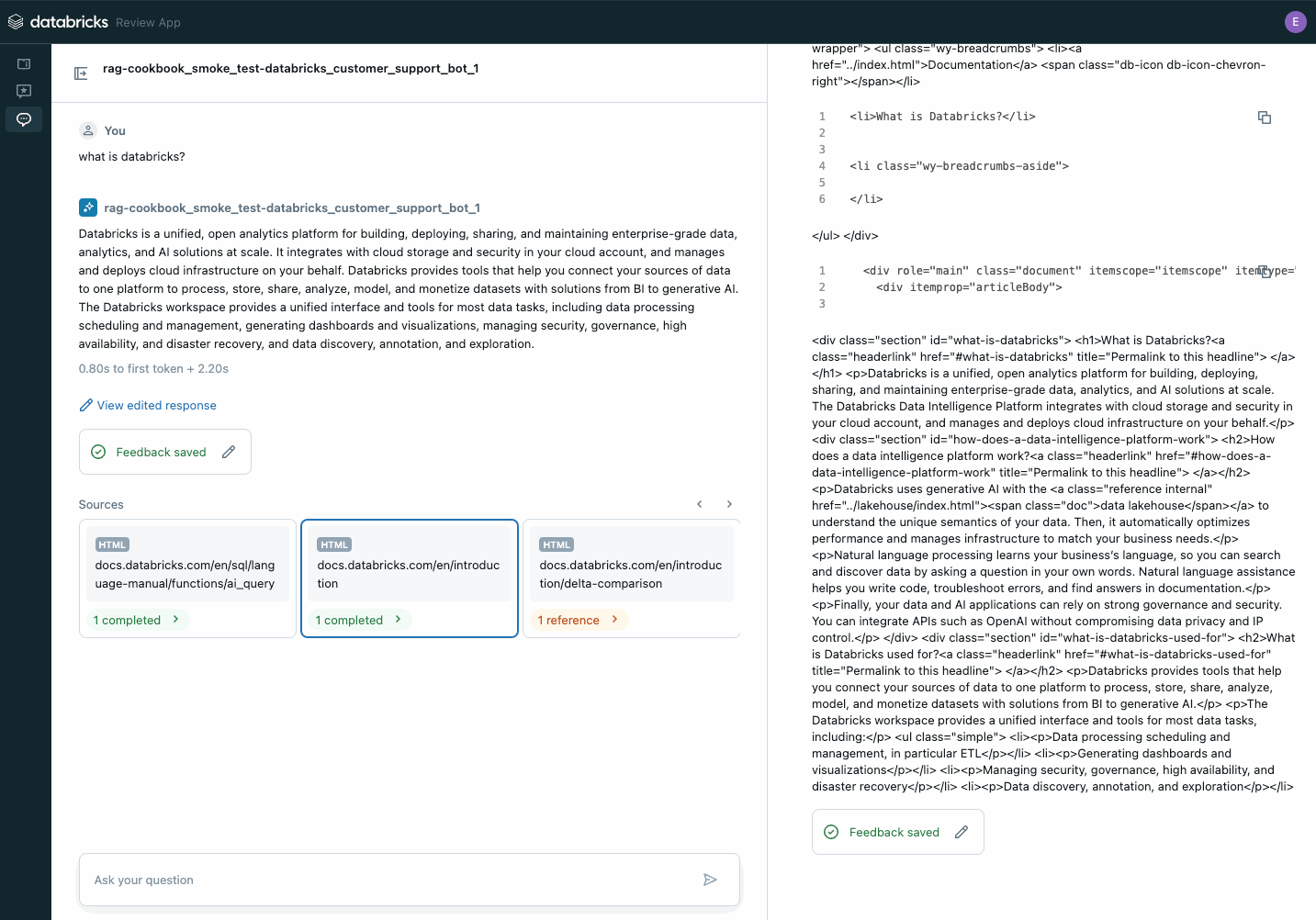
レビュー アプリケーションを使用して、POC に関する利害関係者のフィードバックを収集します
Corning は材料科学企業です。当社のガラスおよびセラミック技術は、多くの産業および科学アプリケーションで使用されているため、当社のデータを理解し、それに基づいて行動することが不可欠です。当社は、Databricks Mosaic AI Agent Framework を使用して AI 研究アシスタントを構築し、米国特許庁データを含む数十万のドキュメントをインデックス化しました。LLM を利用したアシスタントが質問に高い精度で応答することは、当社にとって非常に重要でした。これにより、研究者は作業中のタスクを見つけて、さらに進めることができます。これを実装するために、当社は Databricks Mosaic AI Agent Framework を使用して、米国特許庁データで拡張された Hi Hello Generative AI ソリューションを構築しました。Databricks データ インテリジェンス プラットフォームを活用することで、検索速度、応答品質、精度が大幅に向上しました。
- Denis Kamotsky 氏、Principal Software Engineer、Corning
評価データセットを作成するためのフィードバックを受け取り始めると、Agent Evaluation と組み込みのAI審査員が、事前に構築されたメトリックを使用して、一連の品質基準に照らして各応答を確認できます。
- 回答の正確性 - アプリの回答は正確ですか?
- 根拠 - アプリの応答は、取得したデータに基づいているのか、それともアプリが幻覚を見ているのか。
- 検索の関連性 - 取得したデータはユーザーの質問に関連していますか?
- 回答の関連性 - ユーザーの質問に対するアプリの応答はトピックに沿っていますか?
- 安全性 - アプリの応答に有害なコンテンツが含まれているか?
評価セット内の各質問の集計されたメトリクスと評価は、 MLflowに 記録されます。LLM を利用した各判断には、その理由を記述した根拠が付けられます。この評価の結果を使用して、品質問題の根本原因を特定できます。詳細なウォークスルーについては、クックブックの「 POC の品質を評価する」および「品質問題の根本原因を特定する」セクションを参照してください。
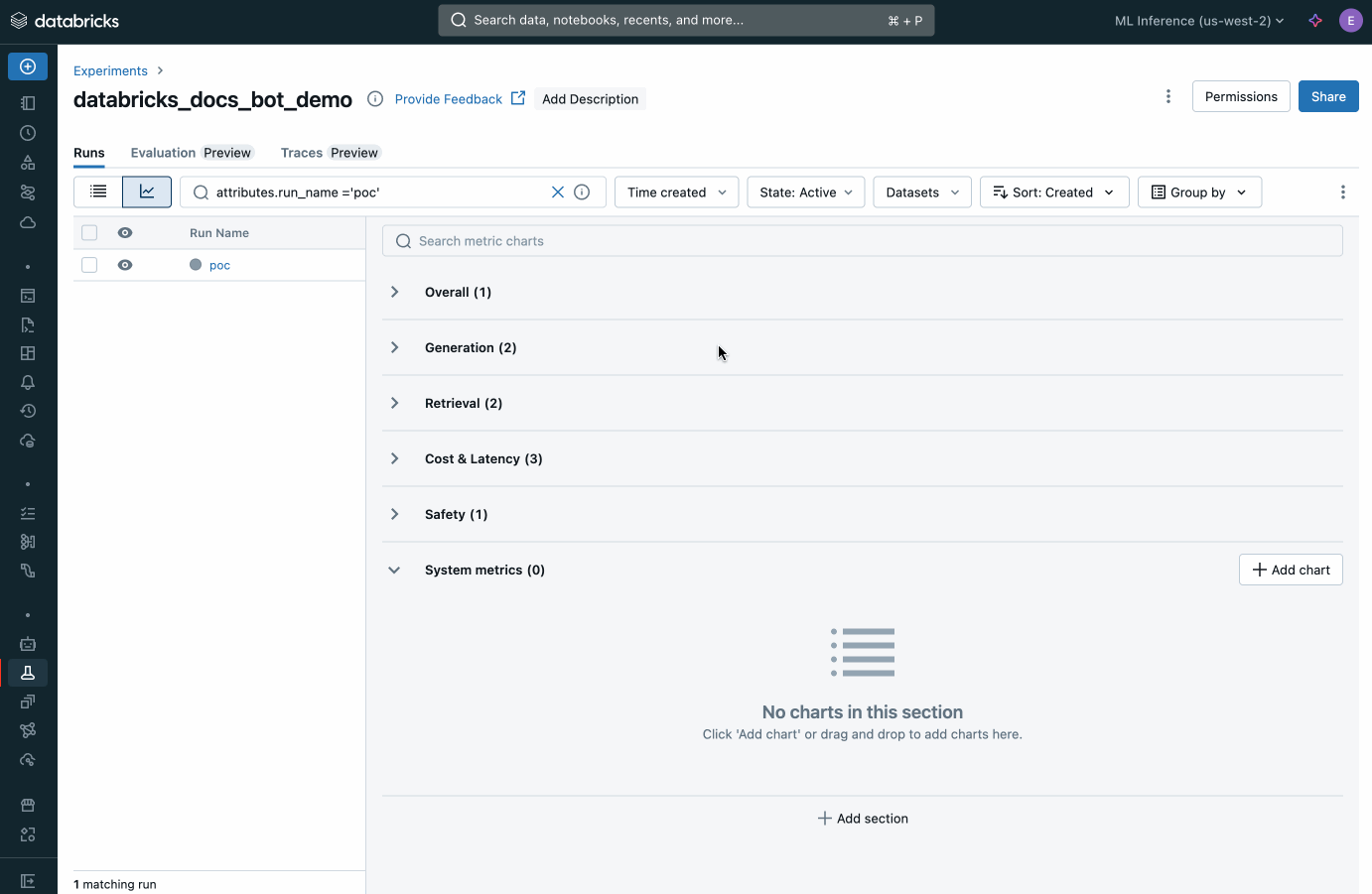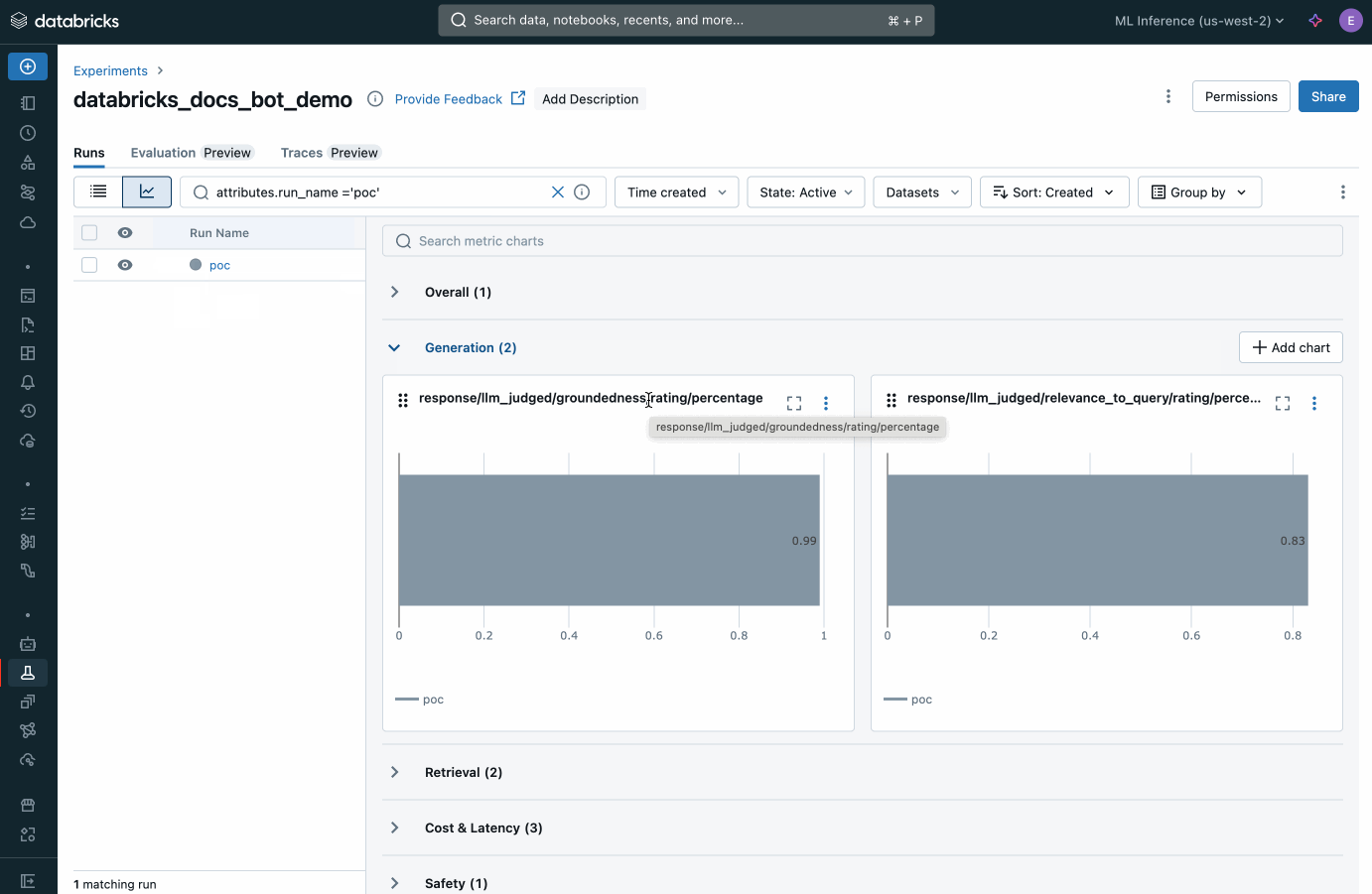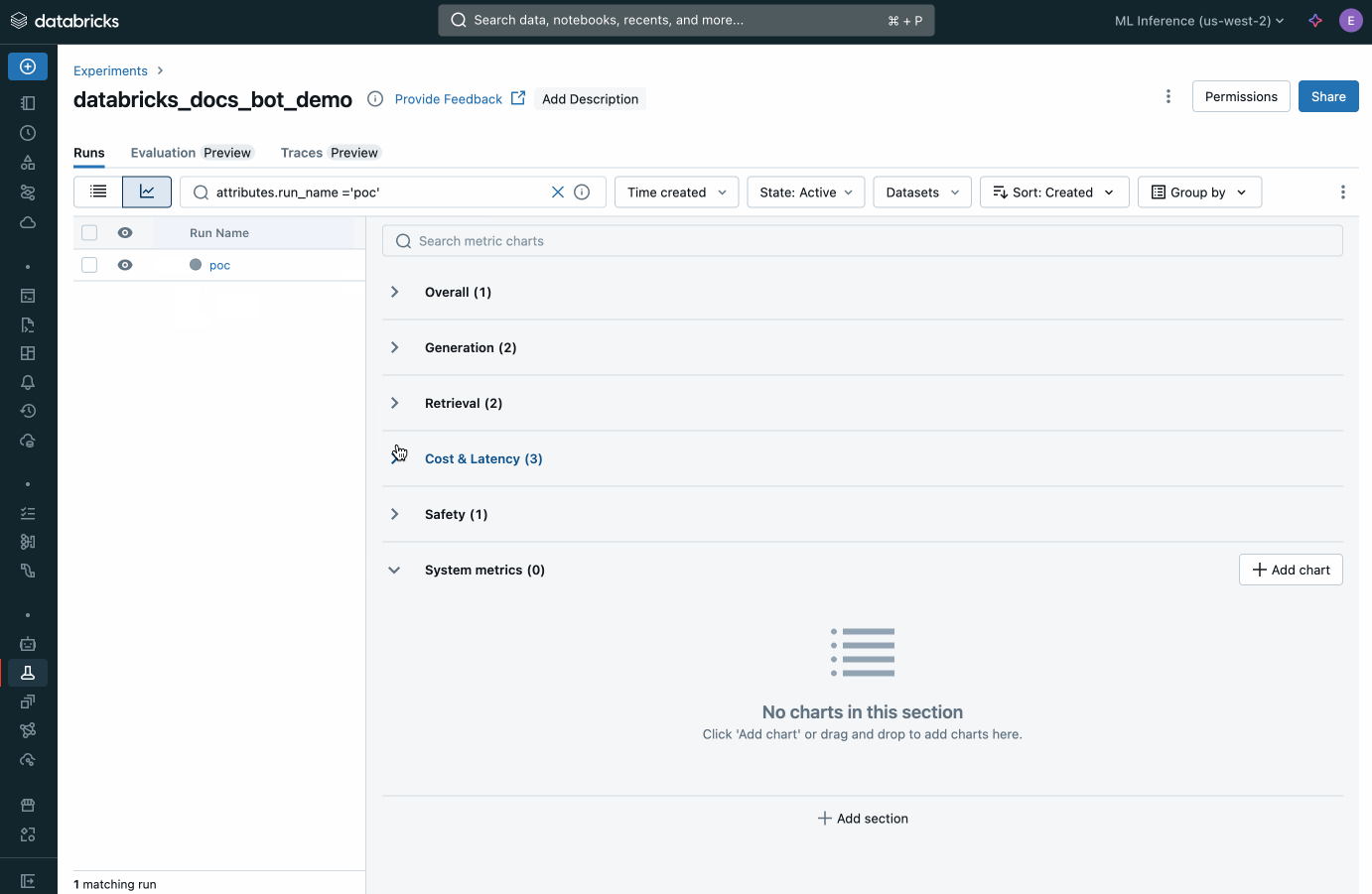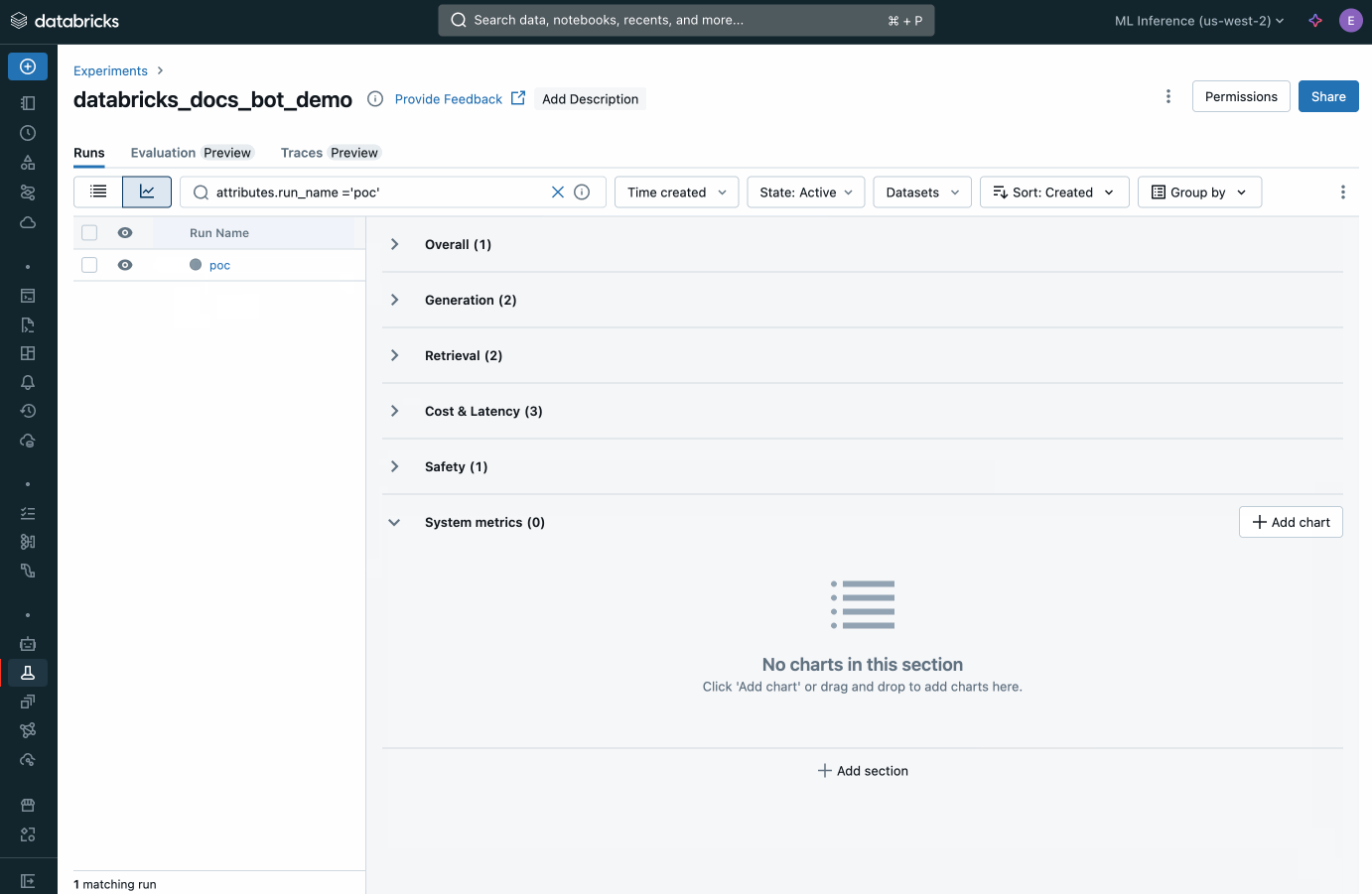
MLflow 内の Agent Evaluation からの集計メトリックを表示します。
世界をリードするメーカーとして、Lippert はデータと AI を活用して、高度にエンジニアリングされた製品、カスタマイズされたソリューション、最高のエクスペリエンスを構築しています。Mosaic AI Agent Framework は、データ ソースを完全に制御しながら、GenAI アプリケーションの結果を評価し、出力の精度を実証できるため、当社にとって画期的なものでした。Databricks Data Intelligence Platform のおかげで、自信を持って本番環境に展開できます。— Kenan Colson 氏、VP Data & AI、Lippert
また、評価データセット内の個々のレコードを検査して、何が起こっているかをよりよく理解したり、MLflow トレースを使用して潜在的な品質の問題を特定したりすることもできます。
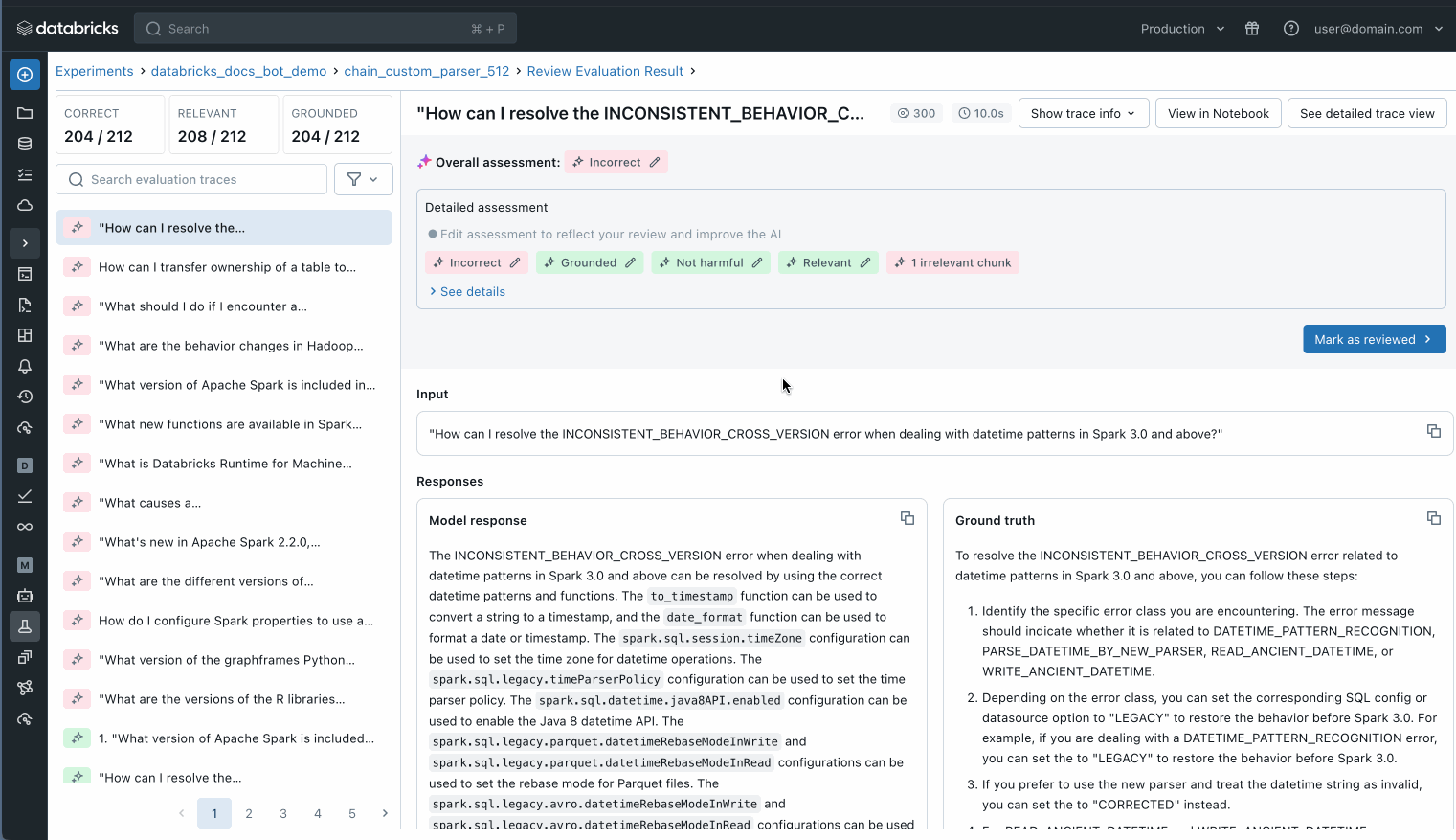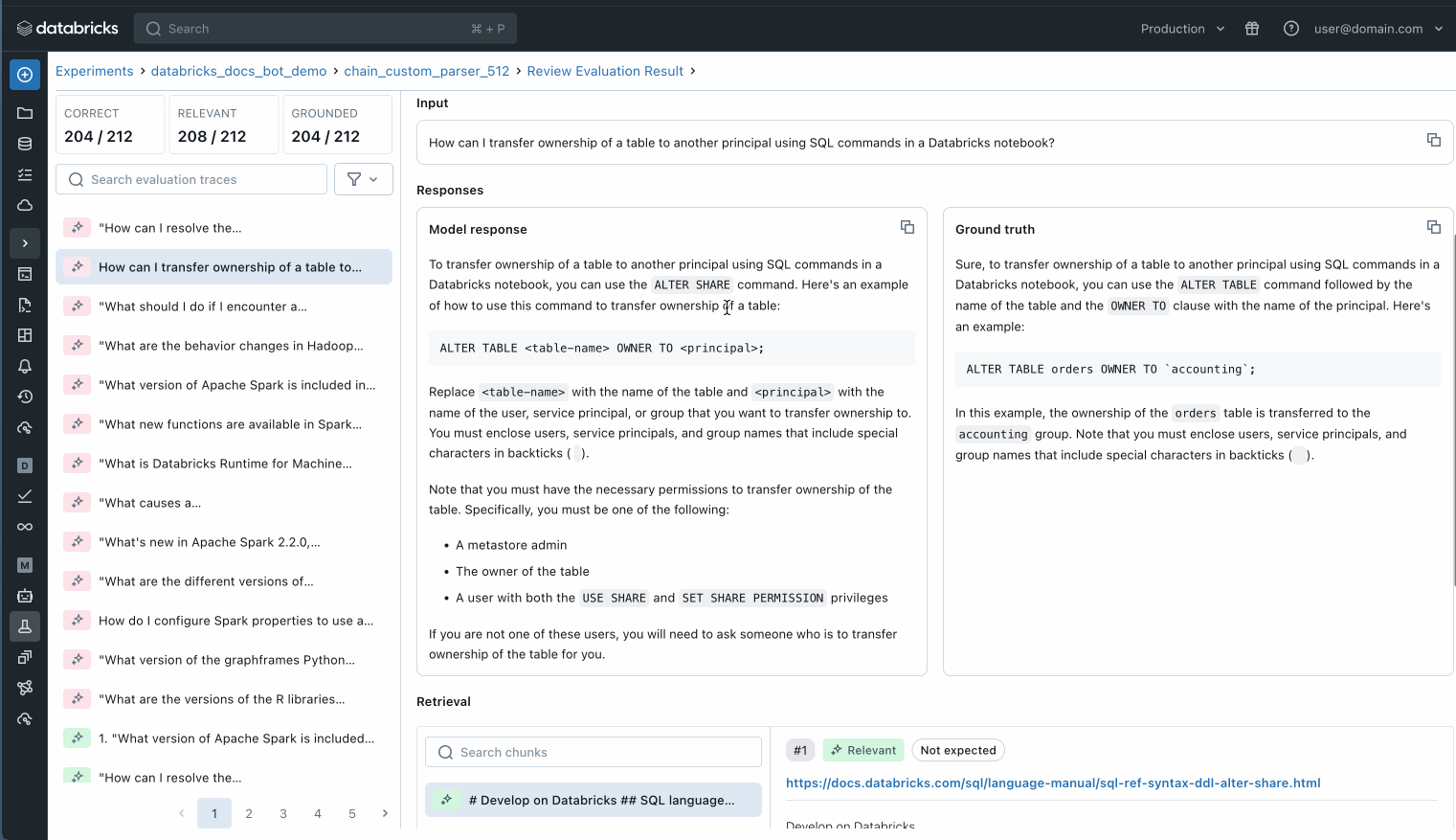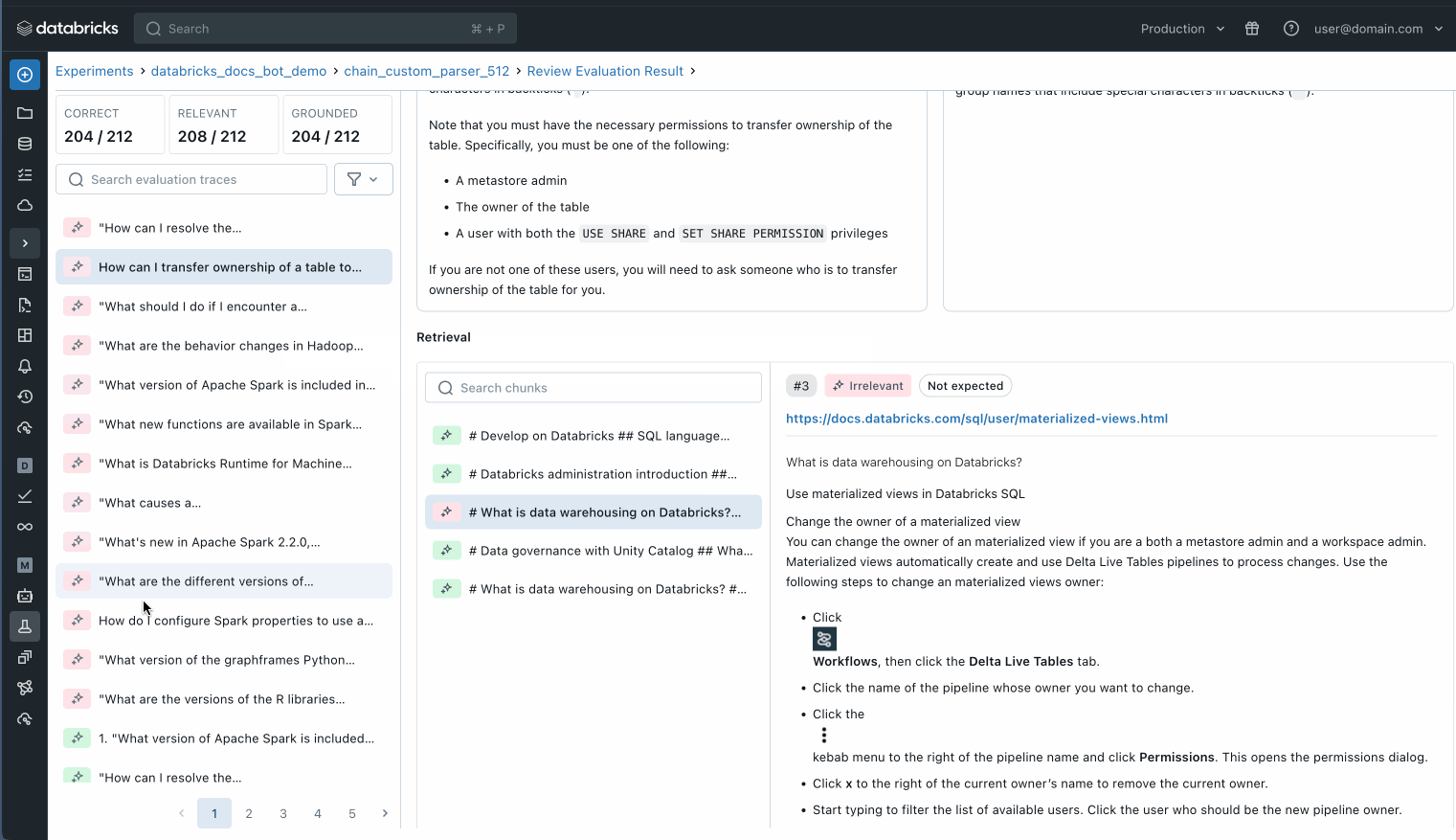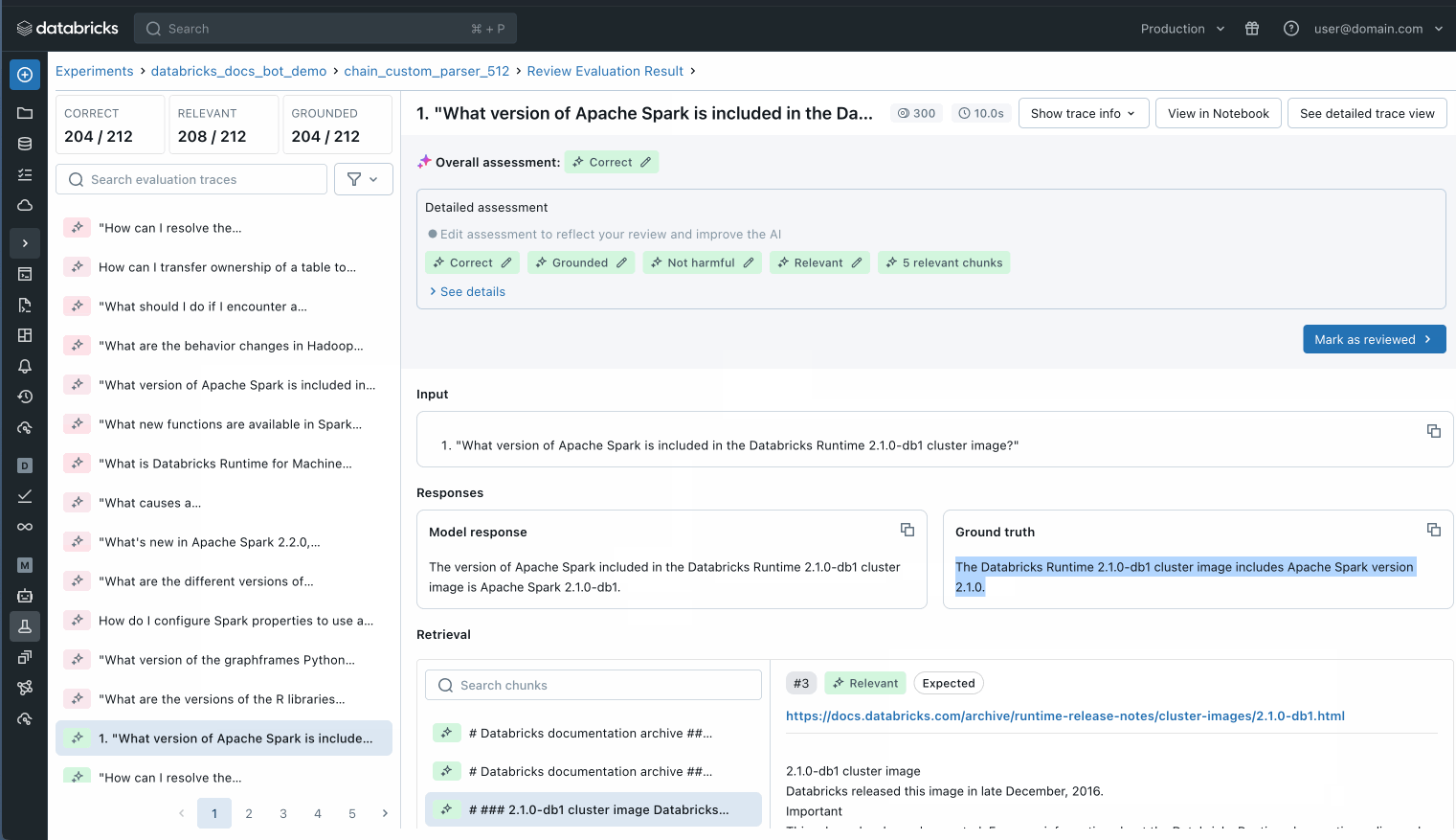
評価セット内の個々のレコードを調べて、何が起こっているかを理解します
品質を反復して満足のいく品質になったら、アプリケーションはすでに Unity Catalog に登録されているため、最小限の労力でアプリケーションを本番運用ワークスペースにデプロイできます。
Mosaic AI Agent Framework により、プライベート データが当社の管理下にあるという安心感を持って、拡張 LLM を迅速に実験できるようになりました。MLflow および Model Serving とのシームレスな統合により、当社の ML エンジニアリング チームは複雑さを最小限に抑えながら POC から本番環境まで拡張できます。— Ben Halsall 氏、Analytics Director、Burberry
これらの機能は、ガバナンスを提供するための Unity Catalog、リネージとメタデータ管理を提供するための MLflow、安全性を提供するための LLM Guardrails と緊密に統合されています。
Ford Direct は、自動車業界のデジタル変革の最先端にいます。当社は Ford と Lincoln のディーラーのデータ ハブであり、ディーラーがパフォーマンス、在庫、傾向、顧客エンゲージメントの指標を評価できるように、統合チャットボットを作成する必要がありました。Databricks Mosaic AI Agent Framework により、独自のデータとドキュメントを RAG を使用する生成 AI ソリューションに統合できました。Mosaic AI を Databricks Delta Tables および Unity Catalog と統合することで、ソース データが更新されると、デプロイされたモデルに触れることなく、ベクター インデックスをリアルタイムでシームレスに実行できるようになりま��した。— Tom Thomas 氏、VP of Analytics、FordDirect
ご利用料金
- Agent Evaluation – 審査リクエストごとの価格設定
- Mosaic AI Model Serving – エージェントにサービスを提供します。料金はMosaic AI Model Serving 料金に基づきます。
詳細については、当社の価格サイトを参照してください。
次のステップ
Mosaic AI Agent Framework および Agent Evaluation は、本番運用品質のエージェントおよび RAG アプリケーションを構築するための最良の方法です。 より多くのお客様にお試しいただき、フィードバックをいただければ幸いです。 開始するには、次のリソースを参照してください。
- エージェント フレームワークのドキュメント ページ ( AWS | Azure )
- エージェント フレームワークとエージェント評価のデモ ノートブック
- AI クックブックの生成
- データと AI サミットのブレイクアウト セッションのリプレイ
- Data + AI Summit における生成 AIの発表
これらの機能をアプリケーションに組み込むのに役立つように、生成 AI クックブックには、Mosaic AI Agent Framework および Agent Evaluationを使用して評価主導の開発手順に従ってアプリを POC から本番運用に移行する方法を示すサンプル コードが用意されています。さらに、クックブックでは、アプリケーションの品質を向上させるために最も関連性の高い構成オプションとアプローチについても概説しています。
デモ ノートブック を実行するか、クックブックに従って データを使用してアプリを構築して、今すぐ Agent Framework と Agent Evaluation をお試しください 。

