State Reader APIの発表:新しい "Statestore" データソース
によって Craig Lukasik 、 Jungtaek Lim による投稿
Databricks Runtime 14.3には、構造化ストリーミングの内部ステートデータへのアクセスと分析を可能にする新しい機能、State Reader APIが含まれています。 State Reader APIは、JSON、CSV、Avro、Protobufなどのよく知られたSparkデータフォーマットとは一線を画しています。 その主な目的は、ステートフルな構造化ストリーミングワークロードの開発、デバッグ、トラブルシューティングを効率化し、迅速なトラブルシューティングを実現することです。 Apache Spark 4.0.0(今年後半にリリース予定)には、State Reader APIが含まれます。
新しいAPIはどのような課題に対応しているのか?
Apache Spark™ の構造化ストリーミングは、様々なステートフル機能を提供します。 これらについて詳しく知りたい場合は、「構造化ストリーミングにおける Multiple Stateful Operators」を読むことから始めてください。この本では、ステートフルオペレーター、透かし(ウォーターマーク)、ステート管理について説明しています。
State Reader APIを使用すると、ステートデータとメタデー��タを照会できます。 このAPIは開発者にとっていくつかの問題を解決します。 開発者は、開発中にステートストアを理解することが困難なため、デバッグのために過剰なロギングに頼ることが多く、プロジェクトの進行が遅くなります。 テストの課題は、イベント時間の処理の複雑さや信頼性の低いテストから生じます。 本番環境では、アナリストはデータの不整合やアクセス制限に悩まされ、緊急の問題を解決するために時間のかかるコーディングによる回避策が必要になることもあります。
2つのAPI
State Reader APIを構成する2つの新しいDataFrame形式オプションは、state-metadata と statestoreです。 state-metadataデータフォーマットは、ステートストアに何が格納されているかについてのハイレベルな情報を提供するのに対し、statestoreデータフォーマットは、キーバリューデータそのものを詳細に見ることができます。 本番環境での問題を調査する場合、state-metadataフォーマットから始めて、使用されているステートフルオペレーター、関連するバッチID、およびデータのパーティショニング方法を大まかに理解することができます。 その後、statestoreフォーマットを使用して、実際のステートキーと値を検査したり、ステートデータに対して分析を実行したりできます。
State Reader APIの使い方は簡単で、慣れ親しんでいるはずです。 どちらの形式でも、ステートストアのデータが永続化されるチェックポイントの場所へのパスを指定する必要があります。 新しいデータフォー�マットの使い方をご紹介します:
- ステートストアの概要:
spark.read.format("state-metadata").load("<checkpointLocation>") - 詳細なステートデータ:
spark.read.format("statestore").load("<checkpointLocation>")
オプションの設定と返されるデータの完全なスキーマの詳細については、Databricks の構造化ストリーミングのステート情報の読み取りに関するドキュメントを参照してください。 Databricks Runtime 14.2以上で実行された構造化ストリーミングクエリのステートメタデータ情報を読み取ることができます。
State Reader APIの使い方の詳細に入る前に、ステートフルな操作を含むストリームの例を設定する必要があります。
例:リアルタイム広告課金
あなたの仕事は、ストリーミングメディア企業の広告主への請求プロセスを支援するパイプラインを構築することだとします。 このサービスを利用する視聴者には、様々な広告主からの広告が定期的に表示されるとします。 ユーザーが広告をクリックした場合、媒体社はその事実を収集し、広告主に請求し、広告クリックの適切なクレジットを取得できるようにする必要があります。 他の前提もあります:
- 視聴セッションの場合、1分以内の複数のクリックは「重複排除」し、1クリックとしてカウントする必要があります。
- 5分間のウィンドウは、集計カウントが広告主�のターゲットDeltaテーブルに出力される頻度を定義します。
- ストリーミングメディアアプリケーションのユーザーは、イベントデータに含まれる
profile_idによって一意に識別されると仮定します。
この記事の最後に、偽のイベント・ストリームを生成するためのソース・コードを提供します。 とりあえず、ソースコードに注目しましょう:
- ストリームを消費
- イベントクリックの複製
- 各
advertiser_idの(ユニークなprofile_idによる)広告クリック数を集計 - 結果をDeltaテーブルに出力
ソースデータ
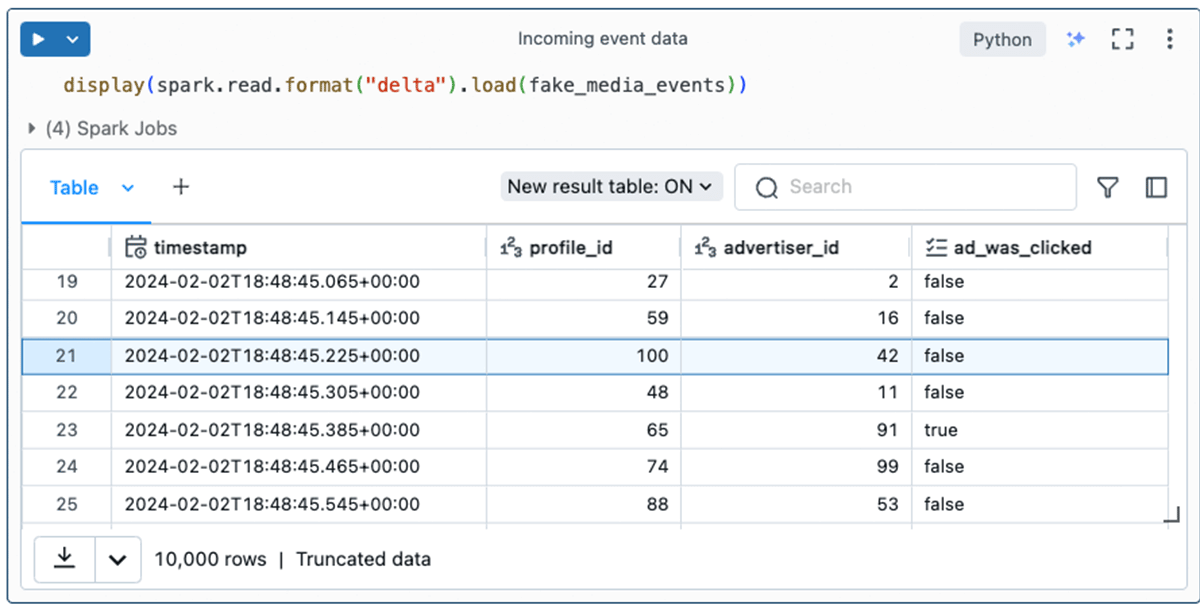
まず、イベントデータを見てみましょう。 このデータを生成するために使用したコードは、この記事の付録にあります。
profile_idは、メディアアプリからストリーミングしているユニークなユーザーを表していると考えてください。 イベントデータは、あるタイムスタンプでどの広告がユーザー(profile_id)に表示されたか、そしてその広告をクリックしたかどうかを伝えます。
レコードの重複排除
ストリーミングパイプラインのベストプラクティスです。 これは、例えば、素早くクリックしたクリックが2回カウントされないようにする��ために意味があります。
withWatermarkメソッドは、重複したレコード(同じprofile_idと advertiser_idのレコード)がストリーム内でそれ以上移動しないように削除される時間のウィンドウを指定します。

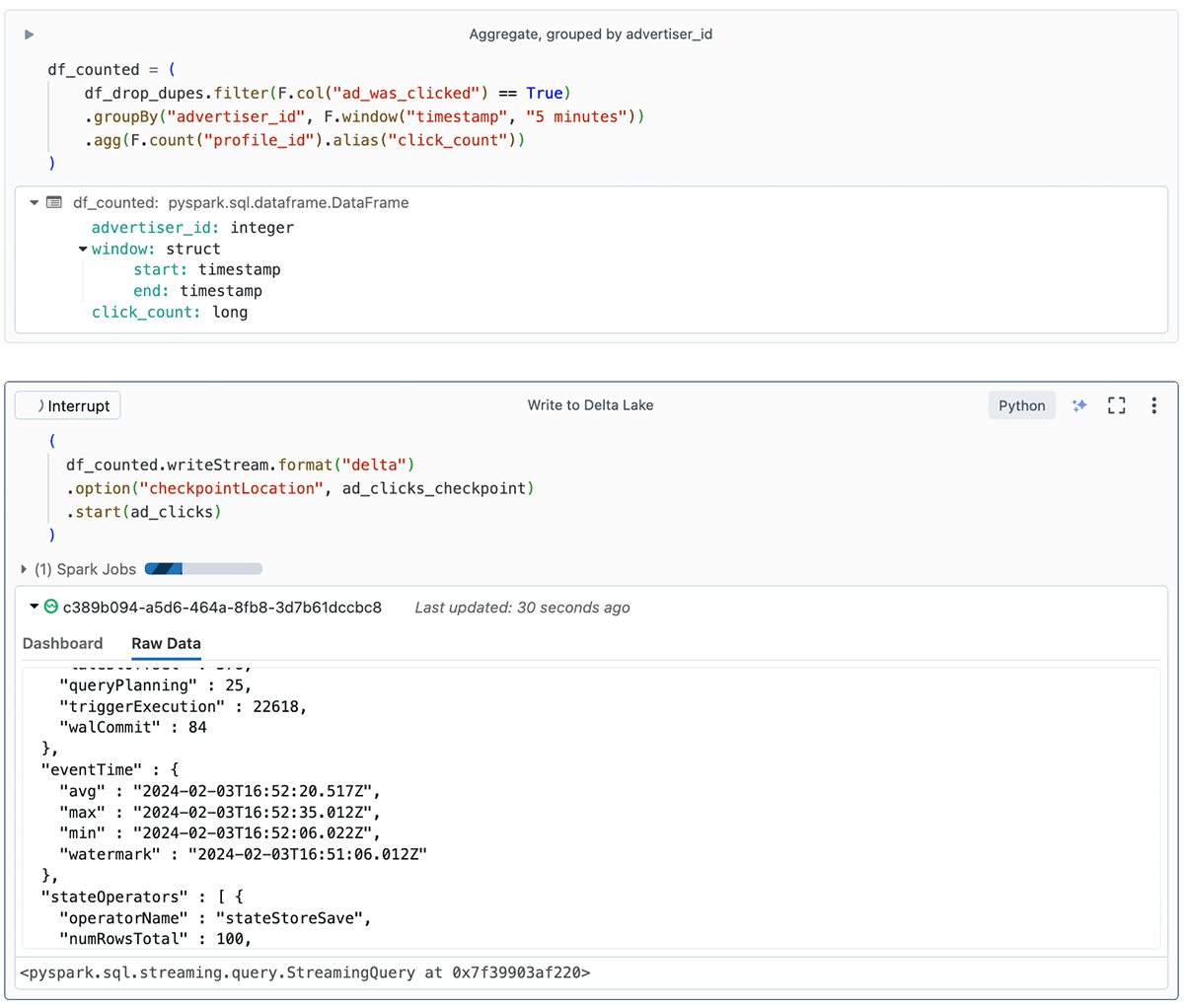
記録の集計と結果の書き込み
広告課金を追跡する最後のステップは、各5分間のウィンドウの広告主ごとのクリック数の合計を永続化することです。
要約すると、このコードは5分間隔(タンブリングウィンドウ)でデータを集約し、各ウィンドウ内の広告主ごとのクリック数をカウントしています。
スクリーンショットでは、"Write to Delta Lake" (Delta Lakeへの書き込み)セルが、"Raw Data(生データ)"タブにストリームに関する有用な情報を表示していることにお気づきでしょう。 これには、ウォーターマークの詳細、ステートの詳細、numFilesOutstandingやnumBytesOutstandingなどの統計が含まれます。 これらのストリーミングメトリクスは、開発、デバッグ、トラブルシューティングに非常に役立ち、本番環境でのトラブルシューティング効率を大きく向上させます。
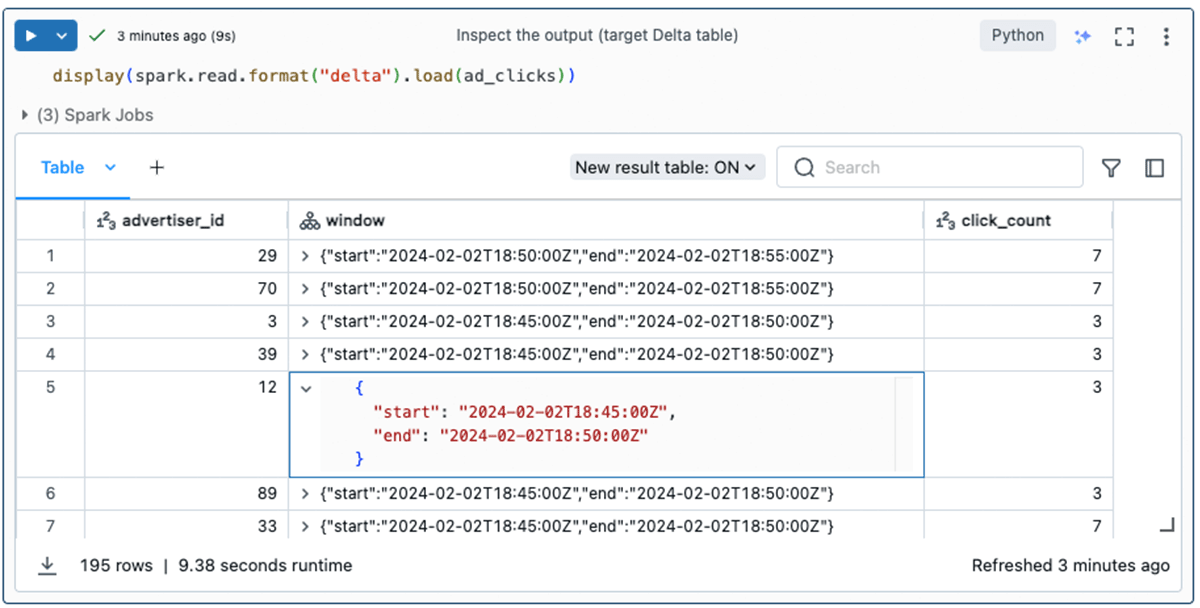
最後に、永続化先のDeltaテーブルに、advertiser_id、広告のクリック数(click_count)、イベントが発生した時間枠(window)が入力されます。
State Reader APIの使用
さて、ここまで実際のステートフルなストリーミングジョブを見てきましたが、State Reader API がどのように役立つかを見てみましょう。 まず、stateデータの全体像を把握するために、state-metadataデータフォーマットを調べてみましょう。 次に、statestoreデータフォーマットを使ってより詳細な情報を取得する方法を説明します。
state-metadataによる高レベルの詳細
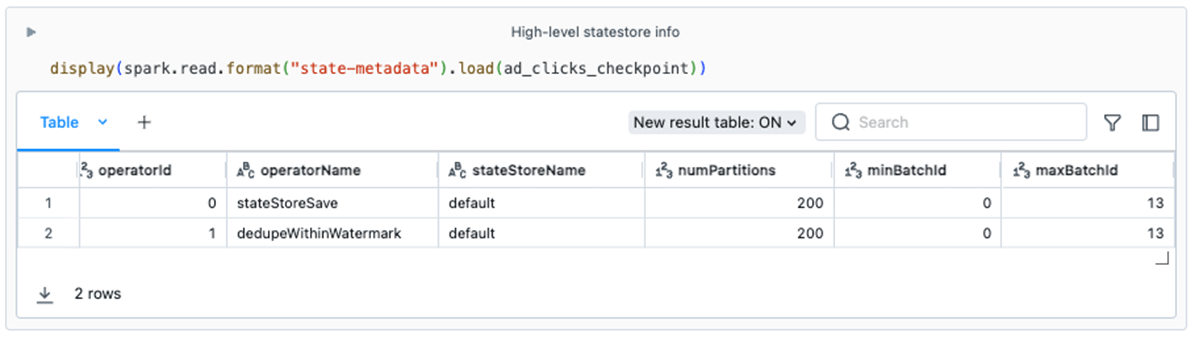
この例のstate-metadataからの情報は、いくつかの潜在的な問題を発見するのに役立ちます:
- ビジネスロジック:このストリームには2つのステートフルオペレーターがあることにお気づきでしょう。 この情報は、開発者がストリームがステートストアをどのように使用しているかを理解するのに役立ちます。 例えば、開発者の中には
dedupeWithinWatermark(PySparkのメソッドdropDuplicatesWithinWatermarkの基礎となるオペレーター)がステートストアを利用していることに気づいていない人もいるかもしれません。 - ステートの保持:理想的には、ストリームが時間と共に進行するにつれて、ステートデータはクリーンアップされていきます。 これは、いくつかのステートフルなオペレーターでは自動的に起こるはずです。 しかし、任意のステートフルな操作(
FlatMapGroupsWithStateなど)を行うには、開発者がステートデータを削除したり失効させたりするロジックを意識してコーディングする必要があります。minBatchIdが時間とともに増加しない場合、これはステートデータのフットプリントが無制限に増加し、最終的にジョブの劣化や失敗につながる可能性があることを示す赤信号である可能性があります。 - パラレリズム:
spark.sql.shuffle.partitionsのデフォルト値は200です。 この設定値は、クラスタ全体で作成されるステートストアインスタンスの数を指定します。 一部のステートフルなワークロードには、200は適さないかもしれません。
statestoreによる詳細
statestoreデータフォーマットは、ステートストアデータベースの各ステートフル操作に使用されるキーと値の内容を含む、きめ細かなステートデータを検査および分析する方法を提供します。 これらはDataFrameの出力ではStructsとして表現されます:
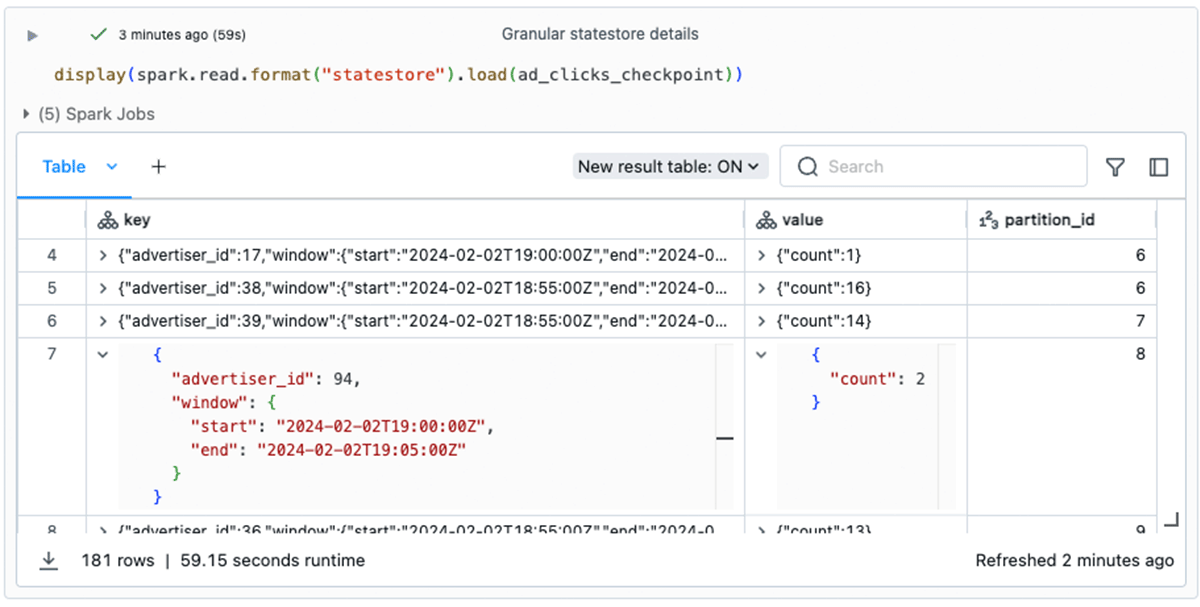
このきめ細かなステートデータにアクセスすることで、コード全体にデバッグメッセージを含める必要がなくなり、ステートフルストリーミングパイプラインの開発が加速します。 また、本番環境の問題を調査する上でも非常に重要です。 例えば、特定の広告主のクリック数が大幅に増加しているという報告を受けた場合、ステートストア情報を検査することで、コードのデバッグ中に調査を指示することができます。
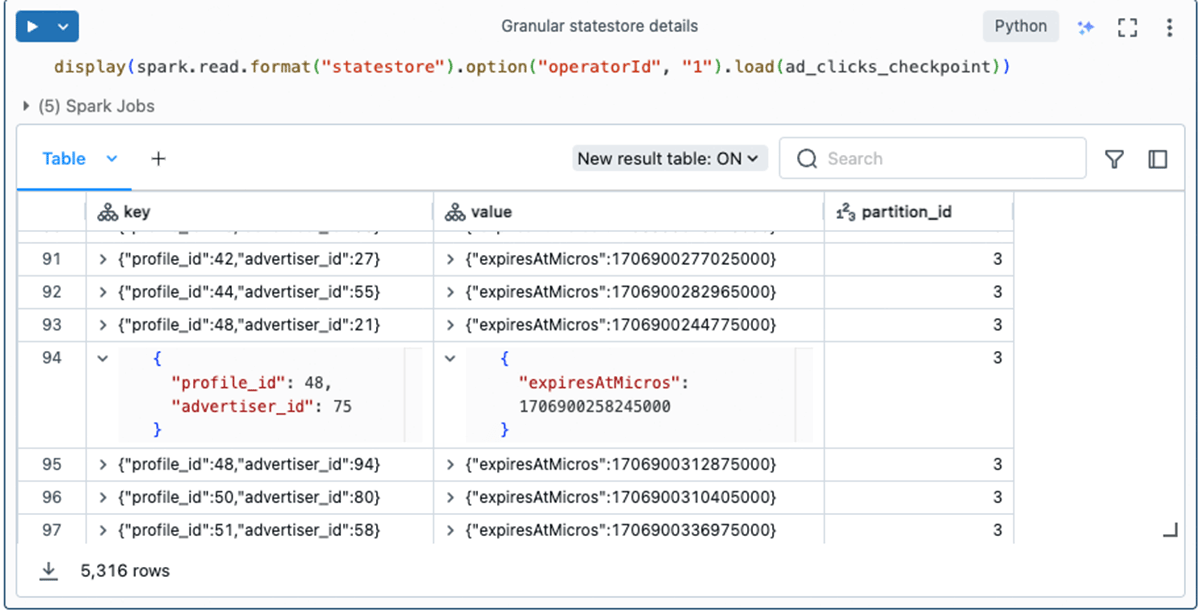
複数のステートフルオペレータがある場合、operatorIdオプションを使用すると、各オペレータの詳細情報を調べられ、効率的なトラブルシューティングにつながります。 前のセクションで見たように、operatorIdは state-metadata出力に含まれる値の1つです。 たとえば、ここでは特にdedupeWithinWatermarkのステートデータをクエリします:
分析の実行(スキューの検出)
State Reader APIによって表示されたDataFramesに対して分析を実行するには、使い慣れたテクニックを使用できます。 この例では、次のようにスキューをチェックできます:
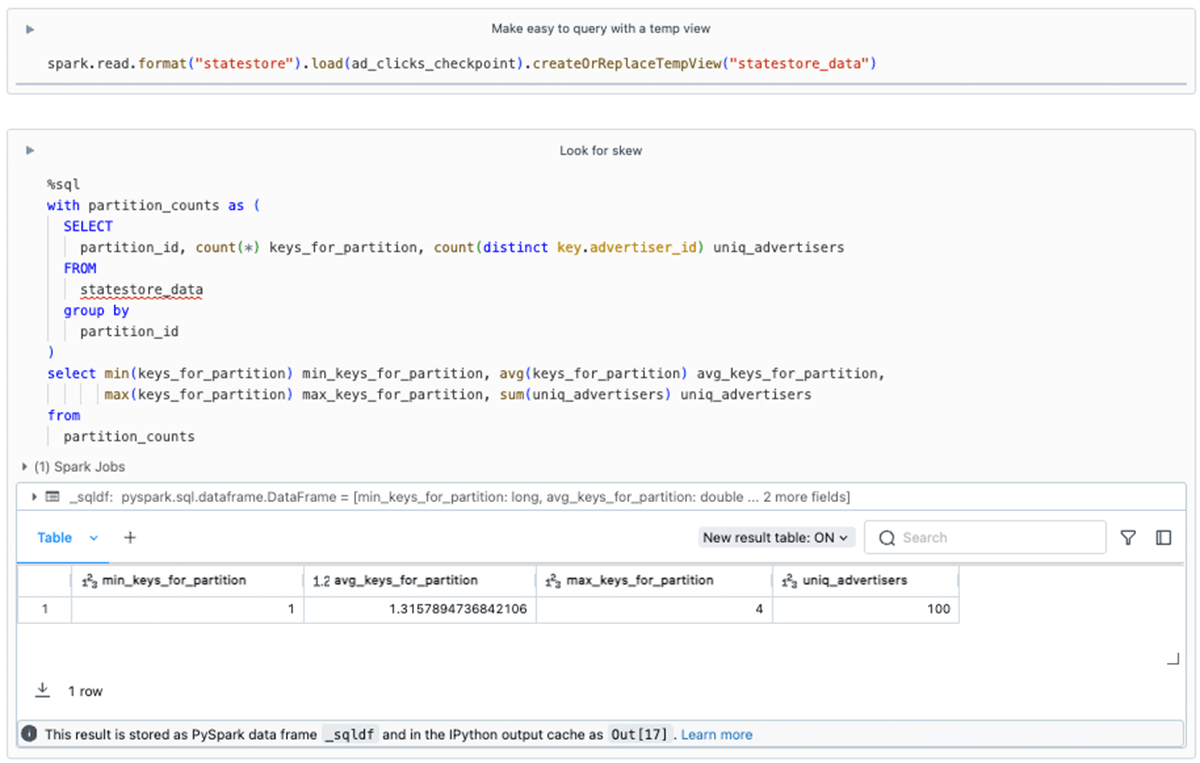
state-metadata APIの使用から得た知見と組み合わせると、パーティションは200個あることがわかります。 しかし、100のユニークな広告主のうち、たった3つしか状態が維持されていないパーティションがあることがわかります。 この簡単な例では心配する必要はありませんが、大規模なワークロードでは、パフォーマンスやリソースの問題につながる可能性があるため、スキューの証拠を調査する必要があります。
State Reader APIを使用するタイミング
開発とデバッグ
新しいAPIは、ステートフルストリーミングアプリケーションの開発を大幅にシンプル化します。 以前は、開発者はビジネスロジックを検証するために、デバッグプリントメッセージに頼ったり、エクゼキュータログを調べたりしなければなりませんでした。 State Reader APIを使用すると、ステートを直接表示し、新しいレコードを入力し、再度ステートを照会し、反復テストを通じてコードを改良することができます。
例えば、何百万台ものセットトップケーブルボックスの診断を追跡するために、ステートフルなアプリケーションでflatMapGroupsWithStateオペレータを使用しているDatabricksの顧客を例にとってみましょう。 このタスクのビジネスロジックは複雑で、さまざまなイベントを考慮する必要があります。 ケーブルボックスIDは、ステートフル・オペレーターのキーとなります。 新しいAPIを採用することで、開発者はストリームにテストデータを入力し、各イベントの後に状態をチェックし、ビジネスロジックが正しく機能することを確認することができます。
APIはまた、開発者が期待することの一部として、ステート・ストアの内容を検証する、より堅牢なユニットテストやテストケースを含めることを可能にします。
並列度とスキューを見る
どちらのデータ形式も、ステートストアのインスタンス間のキーの分布に関する洞察を開発者やオペレータに提供します。 state-metadataのフォーマットは、ステートストアのパーティション数を明らかにします。 開発者は、大規模クラスタであっても、デフォルト設定のspark.sql.shuffle.partitions(200)に固執することがよくあります。 ただし、ステートストアのインスタンス数はこの設定によって決定されるため、ワークロードが大きい場合は200パーティションでは不十分な場合があります。
statestoreフォーマットは、この記事の前半で示したように、スキューを検出するのに便利です。
本番ワークロードに関する問題の調査
データ分析パイプラインにおける調査は、さまざまな理由で行われます。 アナリストはレコードの出所や履歴を追跡しようとするかもしれませんし、本番環境のストリームでは、ステートストアデータを含む詳細なフォレンジック分析が必要なバグに遭遇するかもしれません。
State Reader APIは、常時オンコンテキストでの使用を意図していません(ストリーミングソースではありません)。 しかし、開発者はノートブックをワークフローとして積極的にパッケージ化することで、先に示したようなテクニックを使って、ステートのメタデータの取得とステートの分析を自動化することができます。
まとめ
State Reader APIは、ステートフルストリーミングプ�ロセスに必要な透明性、アクセシビリティ、使いやすさを提供し、トラブルシューティングの信頼性を強化します。 この記事で実証されているように、APIの使用法と出力は簡単でユーザーフレンドリーであり、複雑な調査作業を簡素化します。
State Reader APIは、SPARK-45511の一部としてApache Spark 4.0.0に含まれています。 Databricksドキュメント Read Structured Streaming state information にAPIのオプションと使い方が説明されています。
付録
ソースコード
以下は、この記事で説明する使用例のソースコードです。 ".py" として保存できます。 ファイルを作成し、Databricks にインポートします。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。