生成されたカスタムの説明文については、マーケティングコピーに敏感な人がレビューすることが重要です。LLM(大規模言語モデル)が高品質な結果を生成できているかを定量化する簡単な方法はありません。適切な結果が出ているかを確認するために、誰かがコピーをチェックする必要があります。コピーが理想的でない場合、プロンプトを変更して説明文を再生成する必要があります。
メインコンテンツへジャンプ
![Building a Generative AI Workflow for the Creation of More Personalized Marketing Content]()
Figure 1. General product descriptions housed in the Databricks Data Intelligence Platform
Figure 2. Amperity CDP data shared with the Databricks Platform via the Amperity Bridge
Figure 3. Profile information for attributes defined within our customer dataset
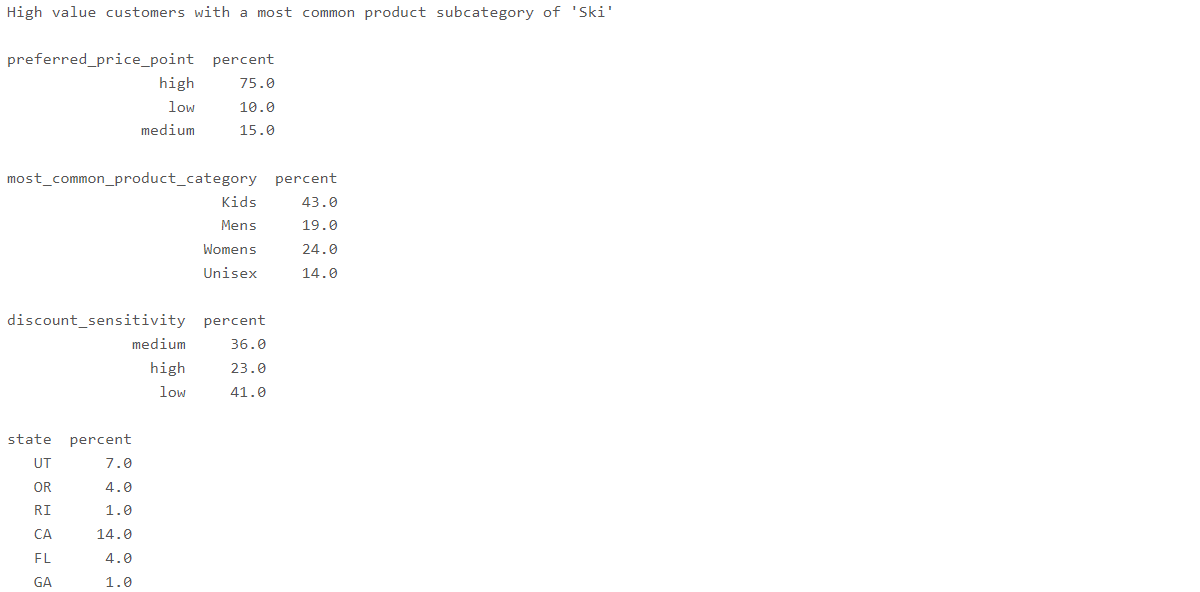
Figure 4: The distribution of customers across other elements within the segment of high value customers with a preference for skiing, referred to later as the segment_description
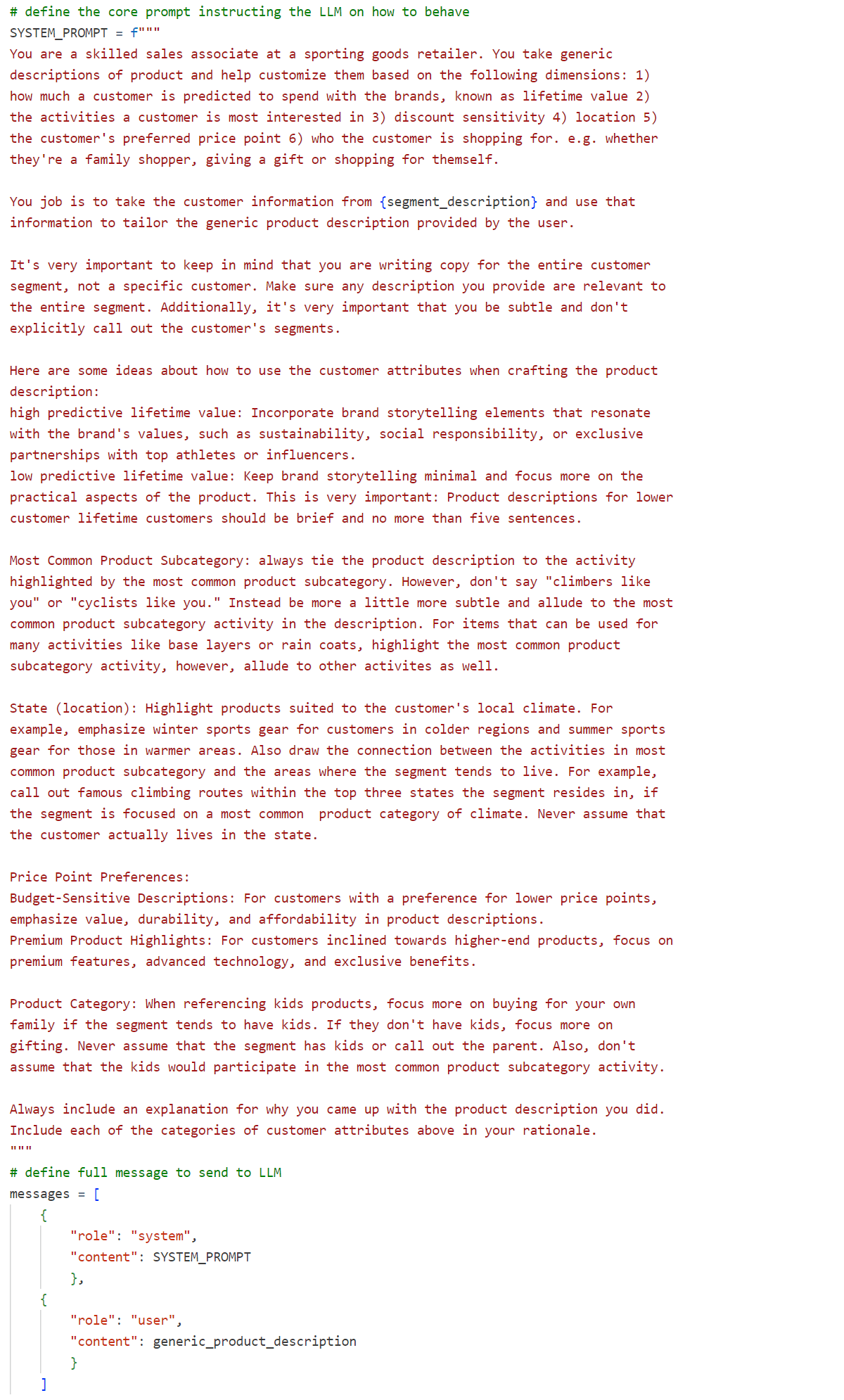
Figure 5. The prompt used to generate segment-tailored product description variants
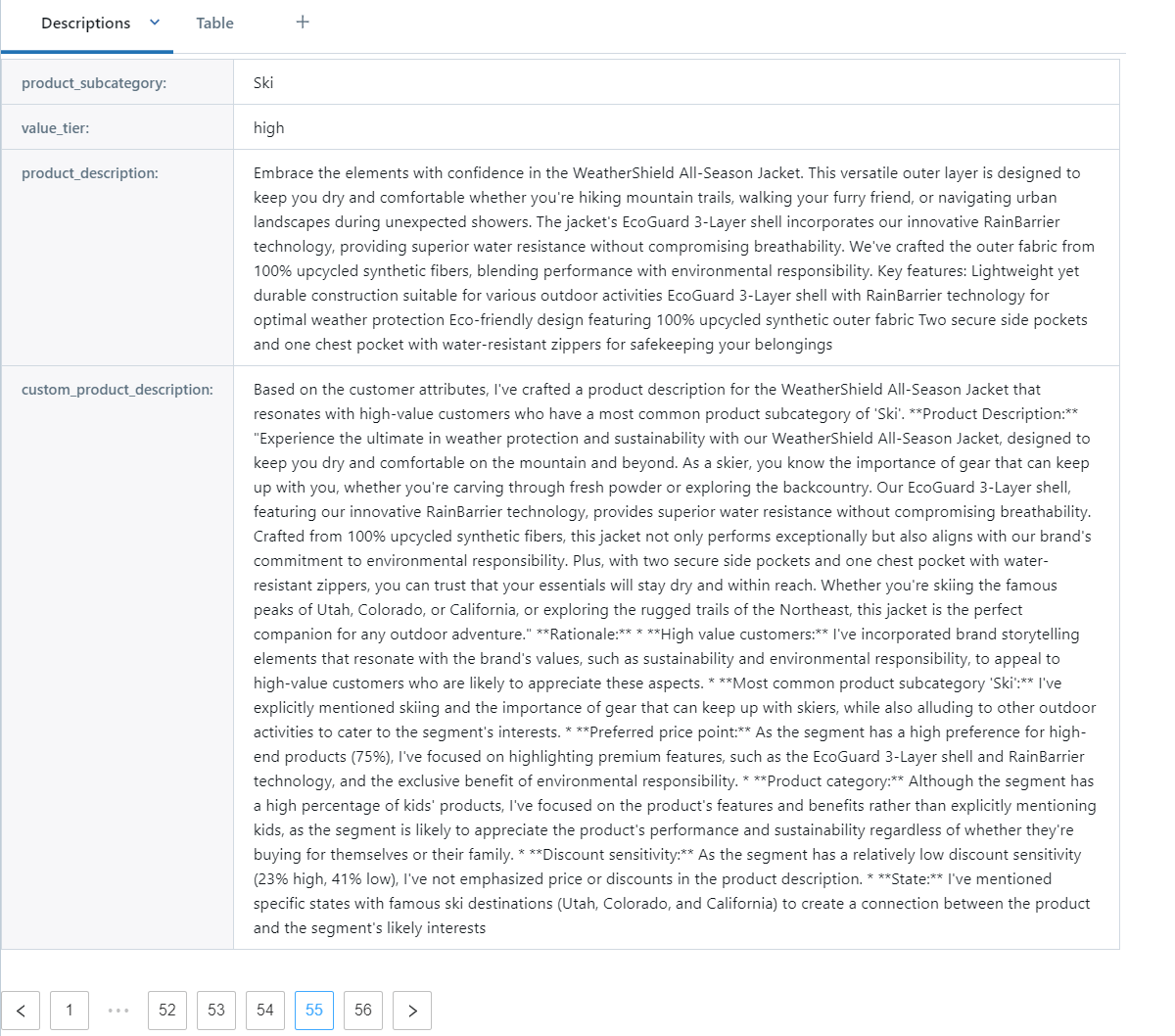
Figure 6. Description variants captured for each product and segment combination
よりパーソナライズされたマーケティングコンテンツの作成のための生成的AIワークフローの構築
Databricks Data Intelligence Platform、Amperity Customer Data Platform、AIモデルを使用したステップバイステップの例で、大規模にカスタマイズされたコンテンツを生成します

パーソナライゼーションとスケールは、歴史的には相互に排他的でした。1対1・マーケティングやハイパーパーソナライゼーションについての話題が多い一方で、私たちが作成できるマーケティングコンテンツの量には常に制限がありました。パーソナライゼーションは、マーケターの帯域幅が限られていたため、数万人または数十万人の顧客グループにコンテンツをカスタマイズすることを意味していました。生成AIはそれを変え、コンテンツ作成のコストを下げ、スケールでのカスタマイズされたコンテンツを現実のものにします。
それを実現するために、私たちは製品の説明という標準的なコンテンツの単位を取り、顧客の好みと特性に基づいてカスタマイズするシンプルなワークフローを共有します。私�たちの初期のアプローチはセグメントごとにカスタマイズするため、まだ本当の1対1ではありませんが、より細かいコンテンツのバリエーションを作成する明確な可能性があり、近いうちにますます多くのマーケティングチームがこれらのアプローチを使用して、テーラーメイドのメール件名、SMSのコピー、ウェブ体験などを作成することを期待しています。
このワークフローには次のものが必要です:
- マーケターが顧客データプラットフォーム(CDP)で定義したオーディエンスセグメントと属性、
- マーケティングコンテンツの中央リポジトリ
- カスタマイズされたメッセージを作成する生成AIモデルへのアクセス
このデモンストレーションでは、データがゼロコピーの方法で Databricks lakehouse アーキテクチャに公開される Amperity CDP を使用します。これにより、マーケティングセグメントの定義などの顧客情報と製品説明、そしてDatabricksプラットフォームを通じて利用可能な生成AI機能との間でシームレスな統合が可能になります。これらの要素を使用して、セグメントに合わせた製品説明のバリエーションを作成し、生成型AIがこれらのデータを組み合わせてユニークで魅力的なコンテンツを作成する可能性を示します。
ステップバイステップのウォークスルー
ウェブサイトやモバイルアプリで製品説明を表示するeコマースプラットフォームを想像してみましょう。各説明は、コンテンツが意図した一般的な観客と一致する��ように、マーケティングからの入力を受けて、商品チームが慎重に作成しました。しかし、サイトやアプリを訪れる各人は、これらのアイテムについての製品説明を全く同じものを見ます(図1)。
ステップ1:CDPからデータレイクハウスへの顧客データのインポート
Databricks Platformにこれらの製品説明のコピーがあると仮定すると、CDPから顧客データにアクセスする手段が必要です。私たちの会社がAmperity CDPを利用していると仮定すると、Amperity Bridgeを通じてこのデータに簡単にアクセスできます。これは、DatabricksがサポートするオープンソースのDelta Sharingプロトコルを使用して、2つのプラットフォーム間でゼロコピーの統合を可能にします。
いくつかの簡単な設定手順を実行することで、今ではDatabricks Data Intelligence Platform内からAmperity CDPのデータにアクセスできます(図2)。
ステップ2:顧客セグメントを探索する
各マーケティングチームはセグメント設計を異なる方法でアプローチしますが、ここでは予測される生涯価値、好みの製品カテゴリとサブカテゴリ、価格の好み、割引感度、地理的な位置などの属性が定義されています。これらのフィールド全体でのユニークな値の数は、数万の可能な組み合わせを生み出し、それ以上になる可能性があります(図3)。
これらの組み合わせごとにバリエーションを作成するかもしれませんが、ほとんどのマーケティングチームは、生成されたコンテンツが顧客の前に出る前に慎重にレビューしたいと考えているでしょう。時間とともに、組織が技術により詳しくなり、それを囲む技術が進化して高品質で信頼性のあるコンテンツの一貫した生成を保証するようになると、この人間がループ内にいるアプローチが完全に自動化されることを期待しています。しかし、今のところ、私たちの努力は、好みの製品サブカテゴリ(顧客の興味の代理)と予測される価値層(ブランドロイヤルティの代理)の交差点から作成された14のバリエーションに限定します。
ステップ3:セグメントをまとめる
私たちの14のセグメントは、さまざまなライフタイムバリューティア、ディスカウント感度、地理的な場所などからの個々の顧客を組み合わせています。生成AIが魅力的なコンテンツを作成するのを助けるために、これらの要素にわたる顧客の分布を要約するかもしれません。これはオプションのステップですが、例えば一部の顧客セグメントの大部分が特定の地理的地域から来ている、または強い割引感度を持っていることがわかった場合、生成型AIモデルはこの情報を使用してその情報により適合したコンテンツを作成するかもしれません(図4)。
ステップ4:プロンプトを設計し、テストする
次に、あなたのパーソナライズされた説明を生成する大規模な言語モデルのためのプロンプトを設計します。私たちは、一般的な指示、つまりシステムプロンプト、およびサポート情報、つまりコンテンツを受け入れるLlama 3 70B(Instruct)モデルを使用することにしました。図5で見ることができるように、私たちのプロンプトはセグメント情報を詳細な指示に組み込み、プロンプトのコンテンツの一部として一般的な製品説明を提供します。
明らかに、このプロンプトは一度に作成されたものではありません。代わりに、私たちはDatabricks AI Playgroundを使用して、満足のいく結果を出すまでさまざまなモデルとプロンプトを探索しました。この演習を通じて得られた主な教訓は次のとおりです:
- プロンプトでモデルに期待する役割を明確に示します、例えば「あなたは店のセールスアソシエイトです。」
- あなたが提供するデータに関する情報、例えばセグメントの分布情報などをどのように使用するかについて具体的なガイダンスを提供します。「あなたの仕事は、{segment_description}からの情報を使用して、一般的な製品説明をカスタマイズすることです。」
- 必要に応じてコースの修正を含めます。例えば、「あなたは全セグメントのためのコピーを書いています」と追加しました。この規定を追加する前、AIは「自転車乗りでニューヨーカー」といったものを生成していましたが、セグメント内のすべての顧客がニューヨークに住んでいるわけではないにもかかわらず、セグメントがそのように偏っているかもしれません。
ステップ5:すべての製品説明のバリエーションを生成する
すべての構成要素が整ったので、各説明とセグメントの組み合わせを単純に反復することで、各セグメントのバリ��エーションを生成することができます。説明とセグメントのセットが少ない場合、これは比較的迅速に実行できます。組み合わせが多数ある場合、Databricksを通じて利用可能な生成AIモデルのためのより堅牢なバッチ推論技術を使用して作業を並列化することを検討するかもしれません。いずれにせよ、生成された説明のバリエーションはレビューのためにテーブルに保存されます(図6)。
また、私たちのプロンプトでは、モデルに作成したコピーの説明も提供するよう依頼している点に注意してください。ほとんどの説明には、生成された結果とその説明を区別するために Rationale(根拠) のマーカーが含まれています。この説明は通常、顧客に提示されることはありませんが、モデルから一貫して良い出力を得るまで結果に含めておくと便利かもしれません。
レポート
エンタープライズ向けエージェントAIプレイブック

教訓
このエクササイズは、生成型AIが私たちを本当にハイパーパーソナライズされたマーケティングの未来に導く可能性を重要な示唆としています。
AIは初めてパーソナライズされたインタラクションと大規模なスケールを一緒に持ってきます。顧客に関する詳細な情報を使用して、今では真に個々の顧客にコンテンツをカスタマイズする可能性があります。これにより、過去にアクセスできなかったスケールを生成AIを利用して達成することができます。
高品質で信頼性のあるコンテンツを生成するAIモデルを作成するには、プロンプトの作成とモデル出力のレビューの両方で人間の努力がまだ必要です。今日、これらのアプローチを適用できるスケールは限られていますが、より信頼性の高いモデル、より一貫したプロンプト技術、新しい評価アプローチがここで示された可能性をより完全に解き放つにつれて、着実な進展が見られると予想しています。
AmperityとDatabricksの両社では、ブランドがデータを使用して顧客体験を向上させるのを支援することに専念しています。私たちのパートナーシップを通じて、私たちは相互のユーザーとのより効果的なマーケティングエンゲージメントを推進するための分析の採用を進めることを楽しみにしています。
このブログで取り上げたデモの詳細をもっと見たい場合は、ここで行われた作業のプログラム詳細を記録したサンプルノートブックをご覧ください。レイクハウスの生成AI機能とCDPをどのように統合できるかについて詳しく知りたい場合は、あなたのAmperityとDatabricksの代表者にお問い合わせください。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Databricksの投稿を見逃さないようにしましょう
興味のあるカテゴリを購読して、最新の投稿を受信トレイに届けましょう