Databricks が 2024 年 Gartner ® Magic Quadrant ™のデータサイエンスおよび機械学習プラットフォーム部門のリーダーの1社として評価されました

Gartner 社がDatabricks を 2024 Gartner® Magic Quadrant™ のデータサイエンスおよび機械学習プラットフォームのリーダーの1社して評価したことを発表いたします。 リーダーは、市場の需要を満たす成熟した製品を提供し、要件の進化に応じて市場での地位を維持するために必要なビジョンを示しています。 Gartner は、データサイエンスおよび機械学習プラットフォームを、ライフサイクルのすべての段階を通じてデータサイエン�ティストがビジネスおよびIT部門の担当者と連携することをサポートするライブラリとツールの統合セットと定義しています。 これらの段階には、ビジネスの理解、データへのアクセスと準備、実験とモデルの作成、知見の共有が含まれます。 リーダーに選ばれたことに加えて、実行能力で最高のベンダーとして認められたことを嬉しく思います
レポートの無料コピーはこちらからダウンロードできます。
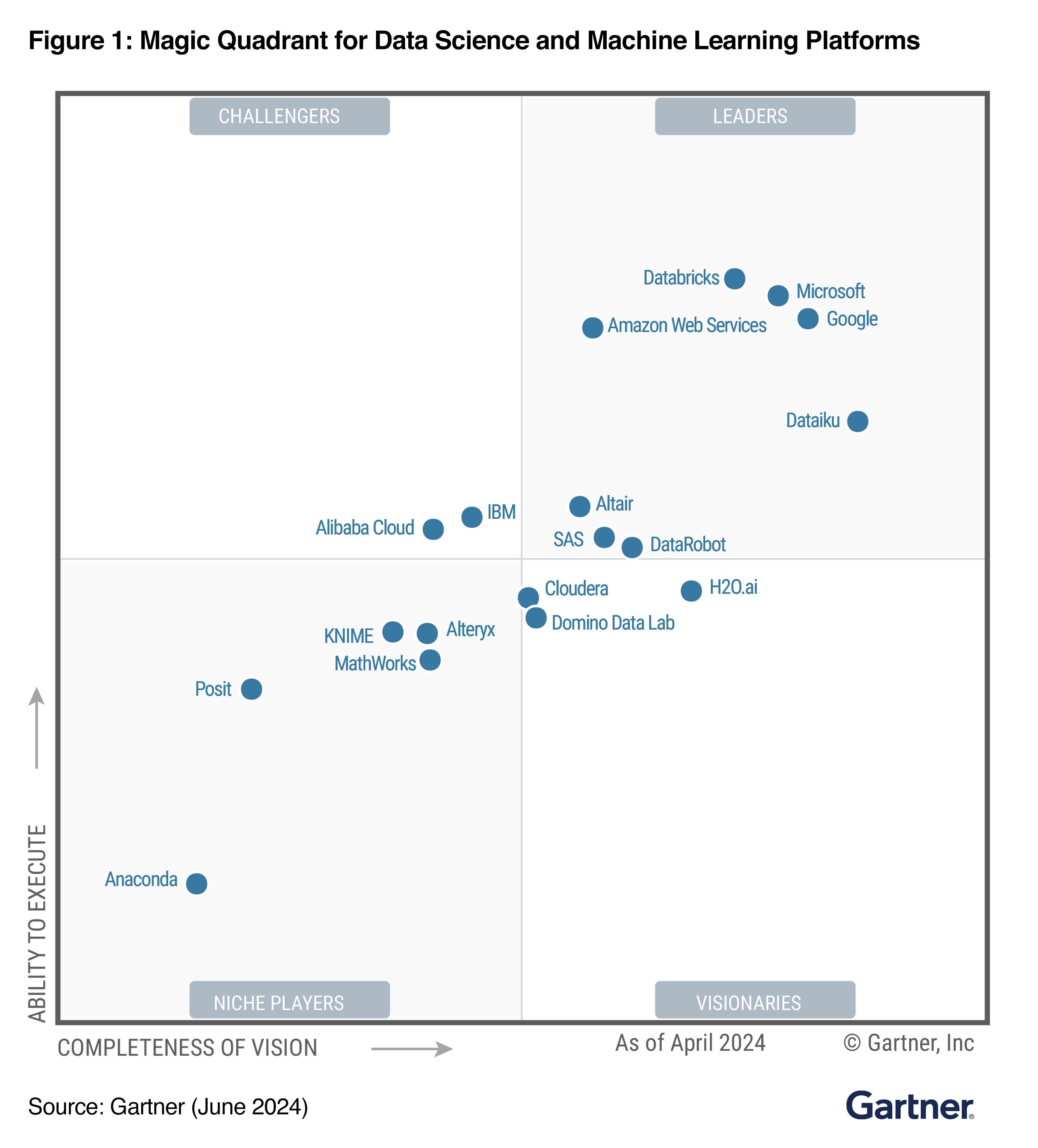
図 1: データサイエンスと機械学習プラットフォームのマジッククアドラント
2021 年のマジック クアドラントと 2024 年のマジック クアドラントの間で発生した重要な変更は、生成AIが含まれたことです。 これは、全体的なデータサイエンスおよび機械学習プラットフォームの一部として、カスタム大規模言語モデルを使用、微調整、および構築する機能を考慮しています。 ガートナーのマジッククアドラントにランクインした理由の1つは、DatabricksがGenAIと従来のデータサイエンス��および機械学習の両方に注力すべきだと考えていることです。
Databricks では、顧客へのこだわりとイノベーションが製品ロードマップの原動力となっています。当社は、 データ + AI を真に民主化するために、 データ インテリジェンス プラットフォーム を急速に拡張してきました。Databricks Mosaic AI は、予測モデルの構築から最新の GenAI や大規模言語モデル (LLM) まで、AI および ML ソリューションを構築、展開、監視するための統合ツールを提供します。Databricks データ インテリジェンス プラットフォーム上に構築された Mosaic AI により、組織は企業データを AI ライフサイクルに安全かつコスト効率よく統合できます。
- モデルとデータに対する完全な所有権: 独自の機械学習および生成AIモデルを安全に構築およびカスタマイズし、データと IP を社外に送信せずに、ビジネスの意味を理解したモデルを強化できます。
- 本番運用品質: Mosaic AI安全で正確で、ガバナンスが行き届いた本番運用品質の GenAI アプリケーションの導入を支援します。Mosaic AI にはアクセス制御とガバナンス機能があり、権限のないユーザーがデータにアクセスできないようにします。安全でないコンテンツを識別し、そのようなリクエストへの応答を防ぐガードレールがあります。すべての出力は、有害で安全でないコンテンツの有無やエラーの診断など、慎重に監視されます。Unity Catalogを利用したネイティブガバナンスにより、すべてのデータとAIアセットを管理および追跡できます。
- コスト: Mosaic AIを使用すると、オープン モデルを提供することも、独自のカスタム大規模言語モデルをゼロからよりコスト効率よく構築することもできます。プレミアム料金がかかる独自のモデルを使用する代わりに、 Mosaic AI Model Servingを使用して展開されたオープン LLM は、最大 5 倍のコスト効率で展開できます。また、特定のドメインに合わせて完全にカスタマイズされた独自の大規模言語モデルを構築したい組織の場合、 Mosaic AI基盤モデル トレーニング を使用すると、最大10分の1のコストで、数日で数十億規模の新しい LLM を構築できます。
次のステップへ
実行能力の最高スコアを獲得したリーダーとして当社が認められたことは、Databricks の成功と、データ チームを結集し、品質、スピード、俊敏性を備えた次世代のデータ��および AI アプリケーションの作成を可能にする当社の能力の証であると考えています。 Gartner のクラウド データベース管理システム のマジック クアドラント におけるリーダーとしての位置付けと相まって、 Databricksは現在、両方の マジック クアドラント レポートでリーダーとして認められた唯一のクラウドネイティブ ベンダーです。 これら 2 つのレポートで当社がリーダーとして位置付けられたことは、Databricks のデータ インテリジェンス プラットフォームにとって決定的な瞬間であり、データと AI を民主化するという当社のビジョンを裏付けるものであると考えています。
この成果がどのくらいすばらしいかは、これがどのように達成されたかにあると私たちは考えています。ベンダーが毎年、多くの分野にわたって複数のマジック クアドラントに掲載されることは珍しくありません。ただし、レポートの特定の基準を個別に達成するポートフォリオ内の異なる製品に基づいて評価されます。 Databricksの結果は、1 つのデータコピー、1 つの処理エンジン、すべてのクラウドにわたる OSS とオープン スタンダードに基づいて構築された 1 つの管理およびガバナンス アプローチを使用して、データ + AIへの統合アプローチでリーダーになれることを明確に示しています。単一のソリューションで、データウェアハウスとデータサイエンス/機械学習の両方のワークロードに対してクラス最高の成果を実現できます。私たちは、 MLと GenAI がデータ プラットフォームを変革し�続けると信じており、私たちと一緒にこの道を歩んでくださるお客様とパートナーに感謝します。
詳しく見る
Mosaic AI の詳細については、当社のWeb サイトにアクセスし、 @Databricksをフォローして最新のニュースや更新情報を入手してください。また、 Data + AI Summit 2024のセッションのリプレイを視聴することもできます。
データサイエンスと機械学習プラットフォームに関する Gartner Magic Quadrant を お読みください 。
ガートナー、データサイエンスおよび機械学習プラットフォームのマジッククアドラント、Afraz Jaffri、Aura Popa、Peter Krensky、Jim Hare、Raghvender Bhati、Maryam Hassanlou、Tong Zhang、2024 年 6 月 17 日
GARTNER は、Gartner, Inc. または米国内外の同社関連会社の登録商標およびサービスマークであり、MAGIC QUADRANT は、Gartner, Inc. または同社関連会社の登録商標です。本ページでは同社の許可のもとにこれを使用しています。無断転用は禁止されています。
ガートナーは、ガートナー・リサーチの発行物に掲載された特定のベンダー、製品またはサービスを推奨するものではありません。また、最高のレーティングまたはその他の評価を得たベンダーのみを選択するようテクノロジーの利用者に助言するものではありません。ガートナーは、ガートナー・リサーチの発行物に掲載された特定のベンダー、製品またはサービスを推奨するものではありません。また、最高のレーティングまたはその他の評価を得たベンダーのみを選択するようテクノロジーの利用者に助言するものではありません。ガートナーは、明示または黙示を問わず、本リサーチの商品性や特定目的への適合性を含め、一切の保証を行うものではありません。
掲載の図は、ガートナーが調査資料の一部として公表したものであり、資料全体の文脈において評価されるべきものです。ガートナーのレポートは、リクエストに応じて Databricks から提供されます。

