Databricksにおけるマルチモデル予測のためのフレームワーク

公開日: 2024年7月26日
によって 吉松 竜太 、Puneet Jain、トリスタン・ニクソン、サティシュ・ガンギチェッティ、マイケル・シュテルマ 、 ブライアン・スミス(Bryan Smith) による投稿
はじめに
時系列予測は、多くの企業における在庫管理や需要管理の基盤となっています。過去のデータと予測される条件を組み合わせて、企業は売上や販売数量を予測し、期待される需要に応じてリソースを配分します。このような基本的な作業であるため、企業は常に予測の精度を向上させる方法を探求しています。これにより、適切なタイミングで適切な場所にちょうど良い量のリソースを配置し、資本の無駄遣いを最小限に抑えることができます。
多くの組織が直面する課題は、利用可能な予測手法の幅広さです。古典的な統計手法、一般化加法モデル、機械学習や深層学習に基づくアプローチ、そして最近では事前学習された生成的AIトランスフォーマーなど、選択肢が非常に多く、シナリオによってはある手法が他の手法よりも優れて��いることがあります。
多くのモデル開発者は、ベースラインのデータセットに対して予測精度の向上を主張しますが、実際にはドメイン知識やビジネス要件によって、選択肢は数種類に絞られます。その上で、実際のデータセットに適用し評価することで、どのモデルが最適かを判断します。そして、「最適な」モデルは、予測対象や時間によっても異なることが多く、組織は常にさまざまな手法を比較評価し、現時点で最も効果的なものを選び続ける必要があります。
このブログでは、予測モデルの比較評価のためのフレームワーク「Many Model Forecasting (MMF)」を紹介します。MMFは、数十万から数百万の時系列データに対して、複数の予測モデルを大規模にトレーニングし、予測を行うことを可能にします。データ準備、バックテスト、クロスバリデーション、スコアリング、デプロイメントをサポートしており、予測チームはコーディングではなく設定に重点を置いて、新しいモデルや機能を導入するための労力を最小限に抑えながら、クラシックモデルから最先端モデルまでを使った完全な予測生成ソリューションを実装することができます。多くの顧客への導入を通じて、このフレームワークが以下の点で効果を発揮することがわかりました。
- 市場投入までの時間を短縮:既に多くの実績あるモデルや最先端のモデルが統合されており、ユーザーは迅速に評価し、ソリューションを展開できます。
- 予測精度の向上:広範な評価と細かいモデル選択を通じて、MMFは精度を高める予測手法を効率的に見つけ出すことを可能にします。
- 本番環境での準備が整う:MLOpsのベストプラクティスに従い、MMFはDatabricks Mosaic AIとネイティブに統合されており、シームレスなデプロイメントが保証されます。
フレームワークを使用して40以上のモデルにアクセス可能
Many Model Forecasting(MMF)フレームワークは、GitHubリポジトリとして提供されており、完全にアクセス可能で、透明性があり、コメント付きのソースコードが含まれています。組織はこのフレームワークをそのまま使用するか、必要に応じて機能を拡張することができます。
MMFには、現在利用可能な人気のあるオープンソース予測ライブラリ(statsforecast、neuralforecast、sktime、r fable、chronos、moirai、momentなど)との統合を通じて、40以上のモデルをサポートする機能が組み込まれています。そして、顧客が新しいモデルを探求する際には、さらに多くのモデルをサポートする予定です。
これらのモデルがすでにフレームワークに統合されているため、ユーザーは各モデルに特有のデータ準備やモデルトレーニングの重複開発を排除し、評価とデプロイメントに集中でき、市場投入までの時間を大幅に短縮できます。これは、限られたリソースを持つデータサイエンティストや機械学習エンジニアのチーム、そして早急な結果を求めるビジネス関係者にとって特に有利です。
MMFを使用すると、予測チームは複数のモデルを同時に評価でき、各時系列に最適なモデルを選択するための組み込みロジックやカスタマイズされたロジックを活用し、予測ソリューション全体の精度を向上させることができます。DatabricksクラスターにデプロイされたMMFは、自動並列処理を通じてモデルのトレーニングと評価を高速化するために、利用可能なすべてのリソースを活用します。チームは、予測作業に使用したいリソースを設定するだけで、残りはMMFが処理します。
モデル出力と比較評価に焦点を当てる
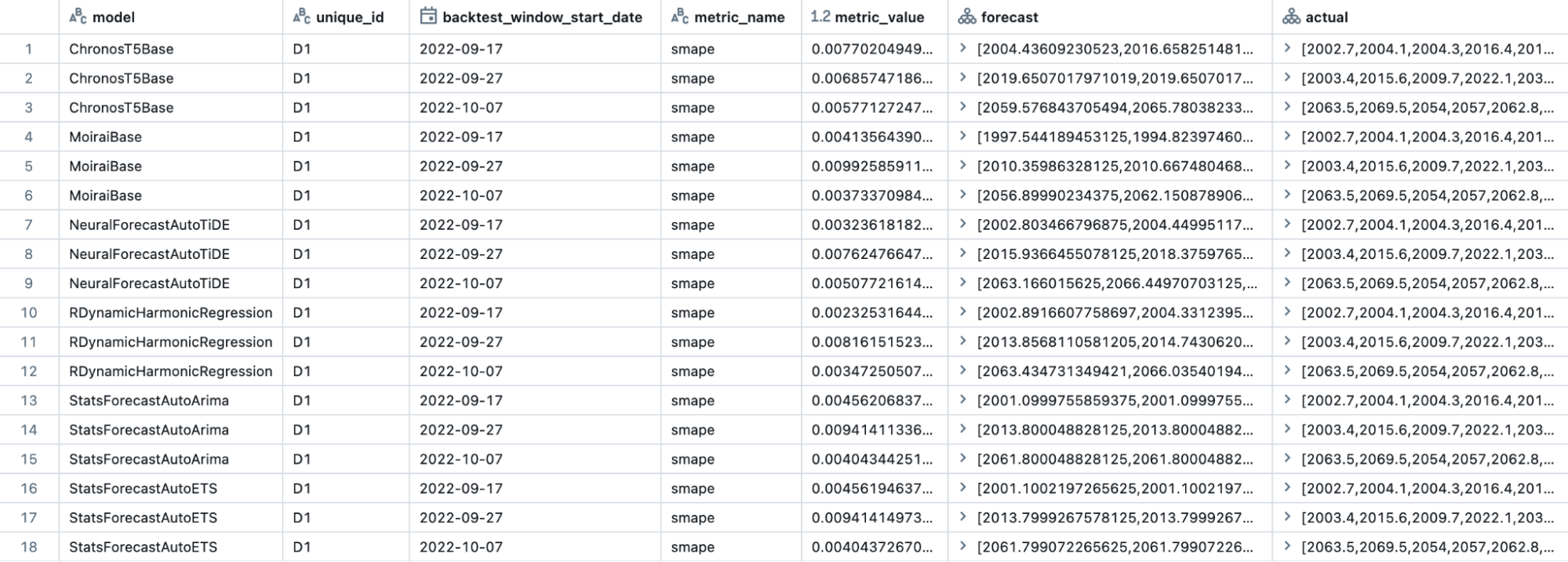
MMFの鍵は、モデル出力の標準化です。予測を実行する際、MMFは「evaluation_output」と「scoring_output」の2つのUCテーブルを生成します。evaluation_outputテーブル(図1)には、すべての時系列とモデルにわたるバックテスト期間中のすべての評価結果が保存されており、各モデルのパフォーマンスを包括的に把握できます。これには、予測結果と実績値が含まれており、ユーザーが特定のビジネスニーズに合わせたカスタムメトリクスを構築することが可能です。MMFには、MAE、MSE、RMSE、MAPE、SMAPEなど、いくつかの標��準メトリクスが用意されていますが、カスタムメトリクスを作成する柔軟性があるため、詳細な評価やモデル選定、またはアンサンブルの作成が可能となり、最適な予測結果を得ることができます。
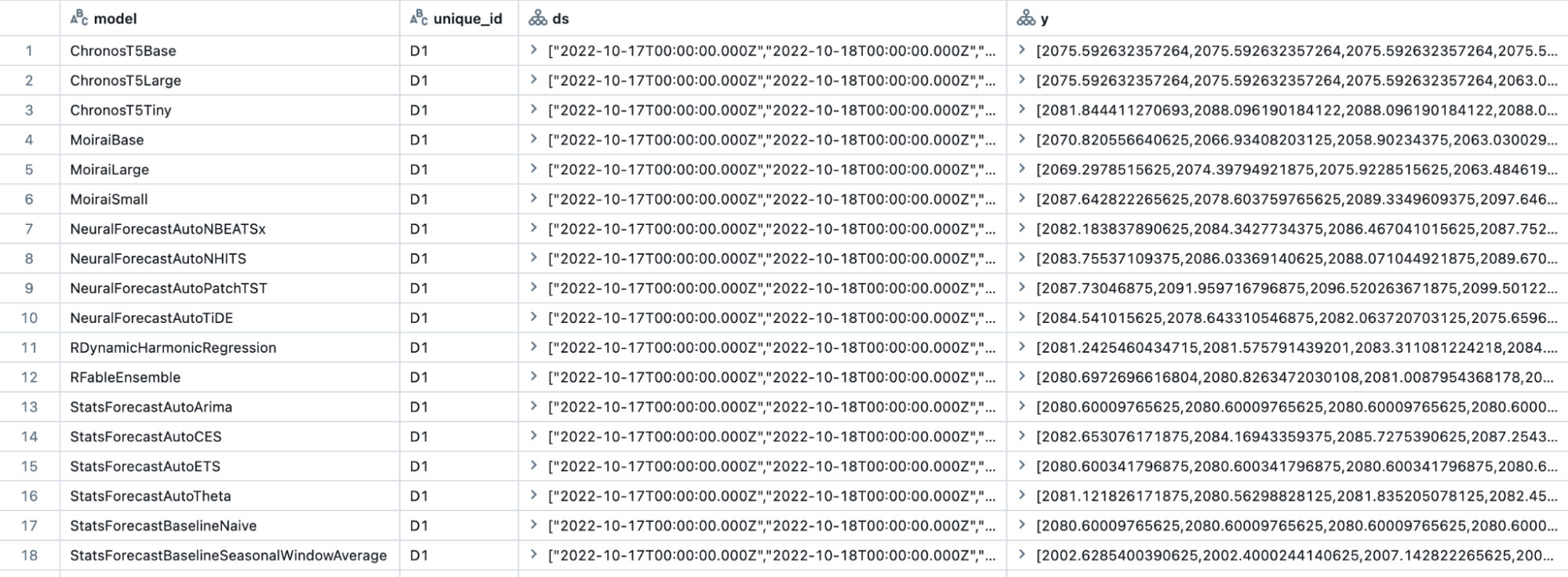
2つ目のテーブルであるscoring_output(図2)には、各モデルによる各時系列の予測が含まれています。evaluation_outputテーブルに保存された包括的な評価結果を使用して、最も優れたモデルや複数のモデルの組み合わせから予測を選択できます。複数の競合するモデルや選択したモデルのアンサンブルから最終的な予測を選ぶことで、単一のモデルに頼るよりも、より高い精度と安定性を達成でき、大規模な予測ソリューション全体の精度と安定性を向上させることができます。
エンタープライズ向けエージェントAIプレイブック

自動化によるモデル管理の簡易化
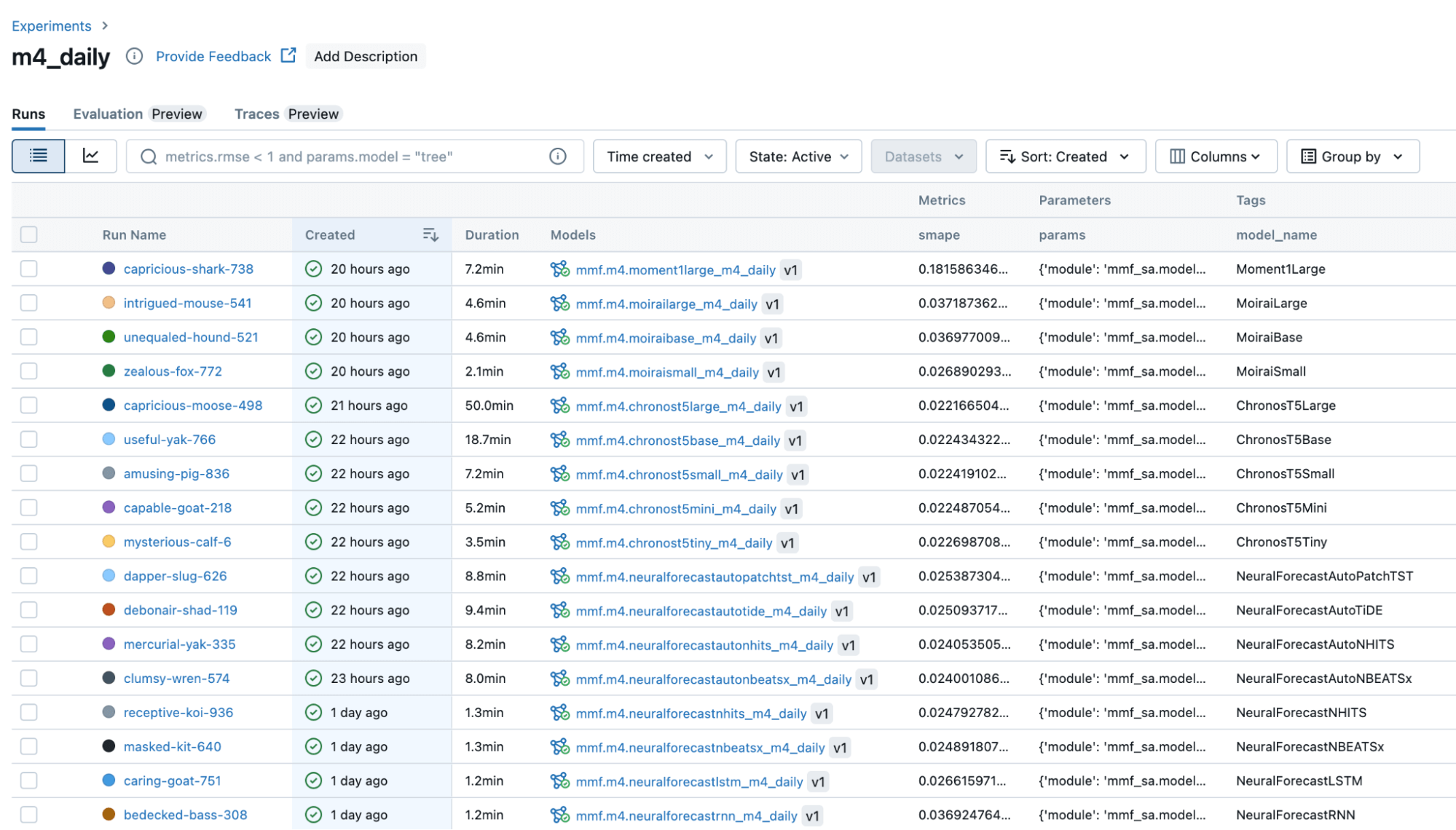
MMFはDatabricksプラットフォーム上に構築されており、Mosaic AI機能とシームレスに統合されています。これにより、パラメータ、集計されたメトリクス、およびモデル(グローバルモデルやファウンデーションモデル)をMLflowに自動的にログすることができます(図3)。DatabricksのUnity Catalogの一部としてセキュアに管理されているため、予測チームはモデルの出力だけでなく、モデルそのものの細かいアクセス制御と適切な管理を行うことができます。
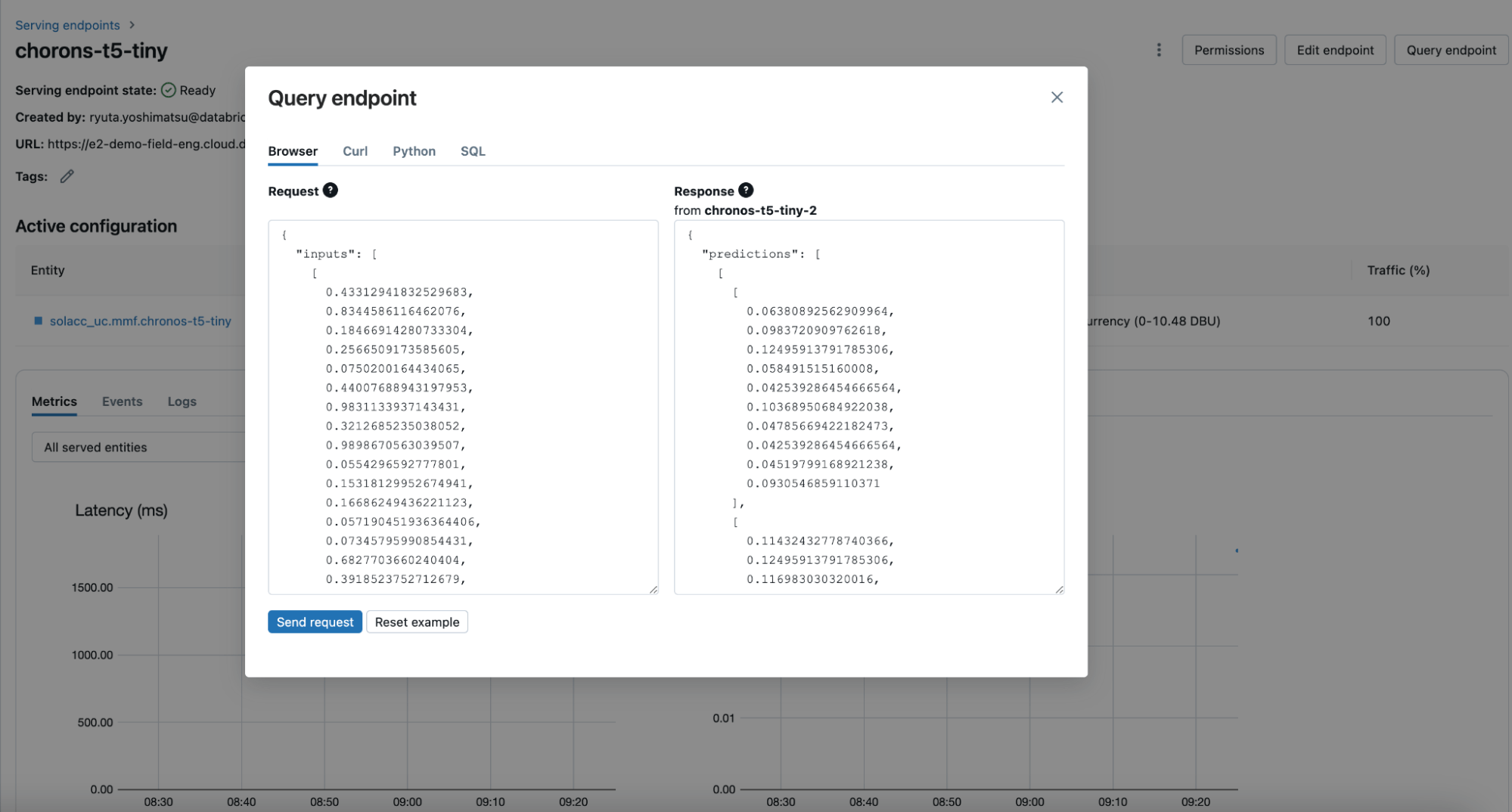
チームがモデルを再利用する必要がある場合(これは機械学習のシナリオでは一般的です)、それらをMLflowのload_modelメソッドを使用してクラスタにロードするか、Databricks Model Servingを使用してリアルタイムエンドポイントの背後にデプロイすることができます(図4)。モデルサービングにホストされた時系列基盤モデルを使用すると、適切な解像度で履歴を提供することで、任意の時間で複数ステップ先の予測を生成することができます。この機能は、オンデマンドの予測、リアルタイムの監視、追跡のアプリケーションを大幅に強化します。
今すぐ始める
Databricksでは、予測生成は最も人気のある顧客ユースケースの一つです。多くのビジネスプロセスの基盤となる予測は、その精度を向上させるために、組織が常に改善を求めています。
このフレームワークを通じて、予測チームが必要とする最もスケーラブルで、堅牢かつ充実した機能に簡単にアクセスできるようになることを目指しています。MMFを活用することで、チームは新しいアプローチの評価や本番環境への準備に必要な開発作業に時間をかけることなく、結果の生成に集中できるようになります。
謝辞
statsforecastやneuralforecast(Nixtla)、r fable、sktime、chronos、moirai、moment、timesfmのチームに感謝します。彼らの貢献により、私たちはオ�ープンソースコミュニティから優れたツールへのアクセスを得ることができました。
MMFリポジトリとサンプルノートブックをチェックして、組織がDatabricks環境内でそれを使用するためのスタート方法を確認してください。

{kind=link}
{kind=link}
{kind=link}
{kind=link}