今すぐ始める。生成AIを使ったチャットボット構築

DATA + AI Summit 2023では多くの生成AIに関するソリューションの発表がありました。Lakehouse IQではお客様毎の環境を理解したLLMが利用できるようになり、LakehouseAIでは、Vector SearchなどのDataset サービスから、AutoML for LLMや MLflow Evaluation などのモデル作成評価そして、Lakehouse Monitoring や GPU Model Serving Endpoint など魅力的な生成AIソリューションの発表があり、徐々にですがPrivate Previewとして利用が開始され始めてきております。
今回は上記のような新しい機能が正式リリースされる前に、今すぐ出来るソリューションとして生成AIを使ったチャットボット構築をご紹介したいと思います。上記のような最新ソリューションの仕組みを理解する上でも、一度自分で生成AIを使ったサービスを構築し利用する事で、サービスの仕組みや有り難みをより深く理解することが出来るようになります。ソースコードも提供しますので、お手元のDatabricks環境で利用してみてください。
Solution 1 : 自然言語によるデータ問い合わせ
最初のソリューションは、自然言語によるDeltaTable内のデータ問い合わせです。従来はSQLやPythonなどのコードを利用したクエリーを投げることでデータを確認出来ました。こちらの仕組みを利用するとユーザーは自然言語を利用してデータに直接問い合わせ出来るようになります。
例えば、以下のように簡単にDatabricks内に保存されたデータを確認することが出来るようになります。

仕組みは以下の通りです。 Langchainの SQLDatabase Chainを使って OpenAIと連携し、ユーザーからの問い合わせをSQLに変換し、Databricksに問い合わせします。またユーザーインターフェース部分はSlack(Teamsや他のアプリなども可)などと連携することで、より広範囲にサービスを届けることが出来ます。
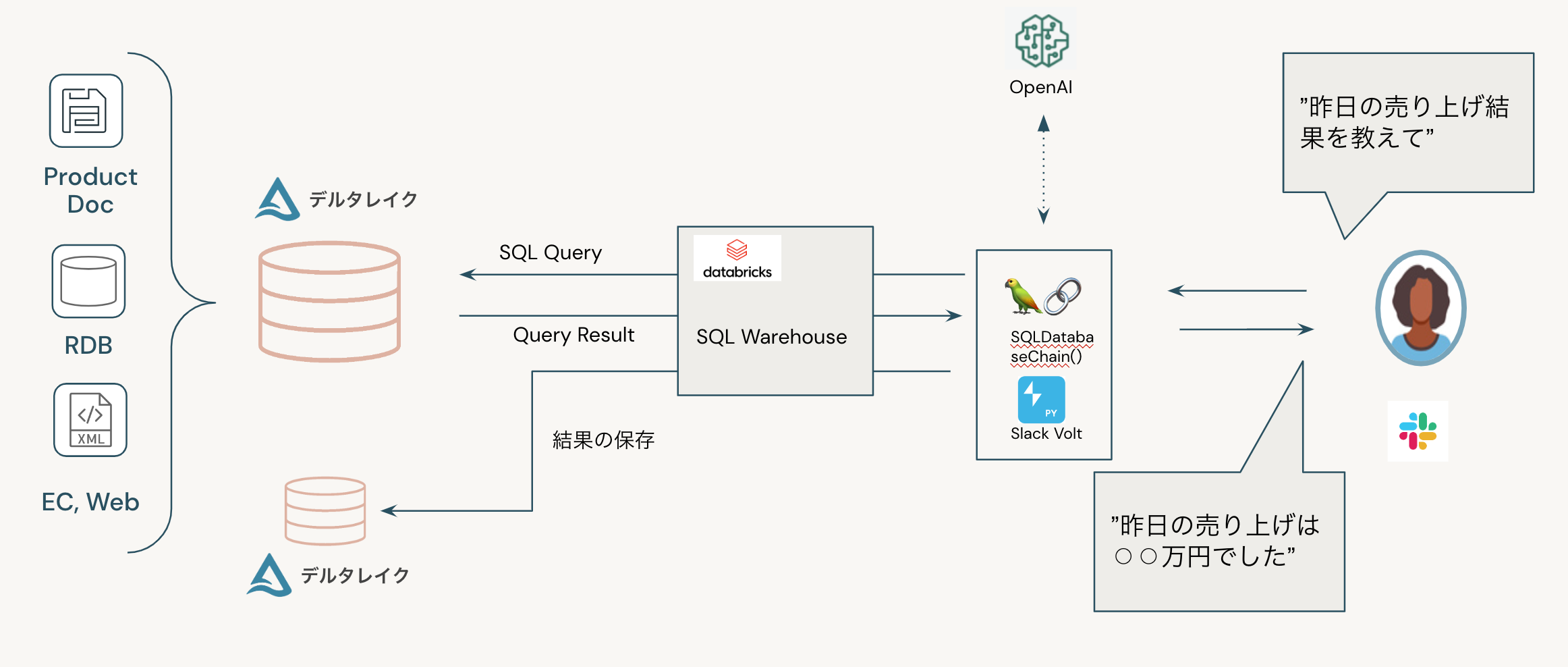
サンプルノートブックを実行する際に準備する情報は以下になります。上記の情報のうち機密性の高い情報については、Databricks Secret機能を利用して予め保存してください。
- SQL Warehouse にアクセスするための情報( Databricks Workspace Host, SQL Warehouse ID, Token)
- OpenAI API Secret Key (Azure OpenAI も可能)
- Slack連携する場合は、Slack AppとBotのKey情報. (詳細の作成・取得方法はこちらをご覧ください)
また検索対象のデータベースやテーブルを指定します。他に Chat LLM(Azure OpenAIも可能) を選択するだけで利用することが出来ます。
ノートブック以外から利用する為に、今回のサンプルノートブックではSlackと連携する方法を記載しております。以下のコードを実行すると、Slack Appと連携するアプリが立ち上がります。
以上で、冒頭に書いたような自然言語によるデータ問い合わせが、Slackなどのアプリと連携しながら利用できるようになります。是非お試しください。
Solution 2: Q&Aチャットボットシステム
2つ目のソリューションはもう少し複雑な仕組みですが、より柔軟にユーザーからの問い合わせを受け付けられるようになります。例えば製品マニュアルやFAQなどのデータを元にユーザーからの問い合わせに柔軟に回答してくれるようなチャットボットを構築できます。
こちらを利用すると以下のように、ユーザーからの特定の分野の問い合わせにデータを元にした回答をしてくれるようになります。

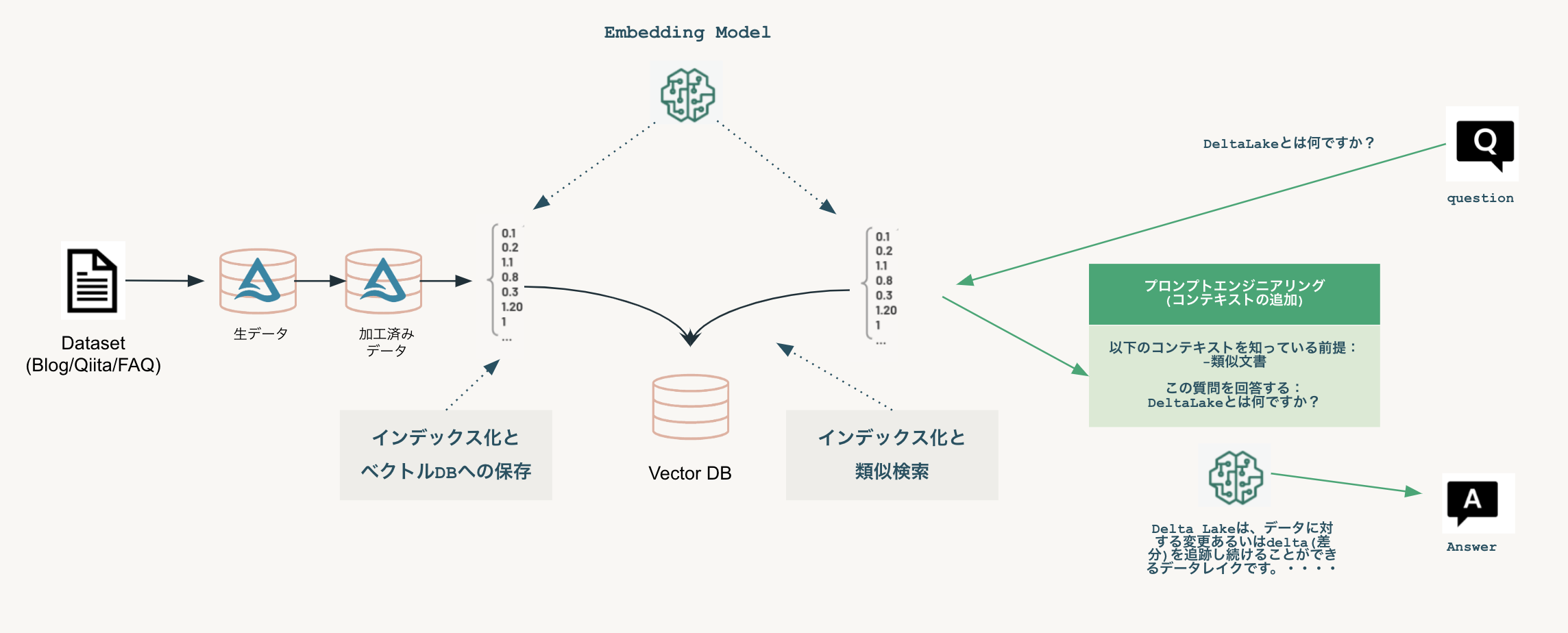
仕組みとしては以下のとおりです。データをベク�トル化することで、類似検索が可能となり関連する情報を元にした回答を生成AIが作成してくれます。
サンプルノートブックでは、最初に util/notebook-config にある初期設定情報を入力した上で、00から順に実行してください。
サンプルノートブックでは、Databricks BlogやFAQを集めたデータセットを元にチャットボットを構築しております。DeltaLakeに保存できればいいので、みなさんのPDFやWord文書からでもデータは収集できます。またこれらをDatabricks WorkflowやDLTを使ってスケジュール実行することで常に最新のデータセットを用意することができます。
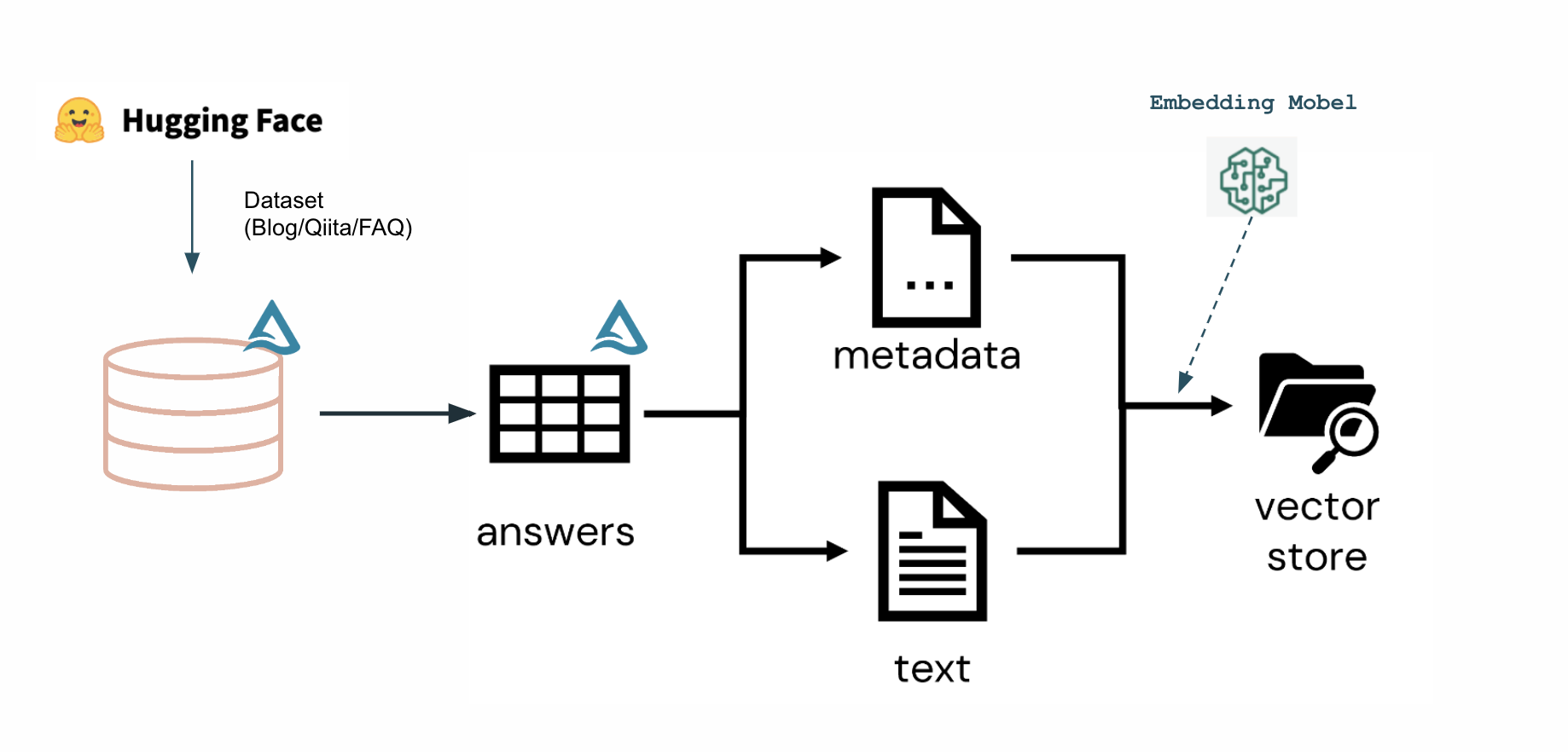
今回はFacebook AI Researchが開発したFAISS Vector Storeを利用しました。
ユーザーからのQAに対してもVector Storeから類似検索を行い、その結果を元に回答するようにします。
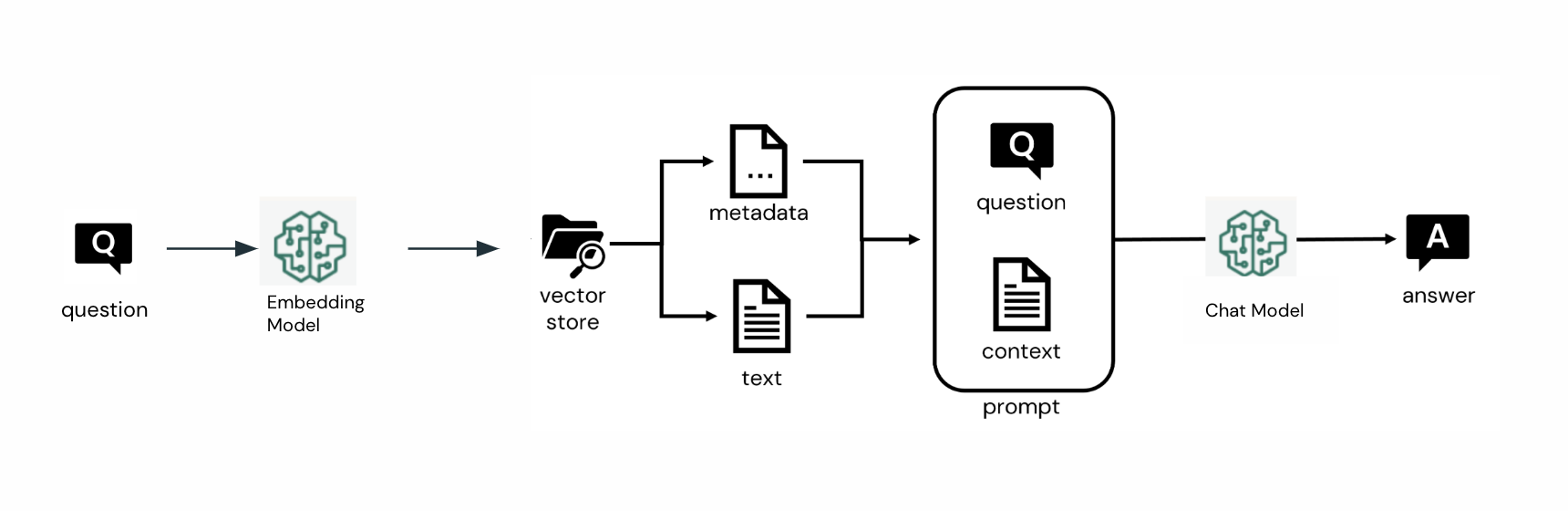
上記のモデルを他のノートブックで利用したり、モデルサービング上にデプロイするためMLflowにパッケージ化します。
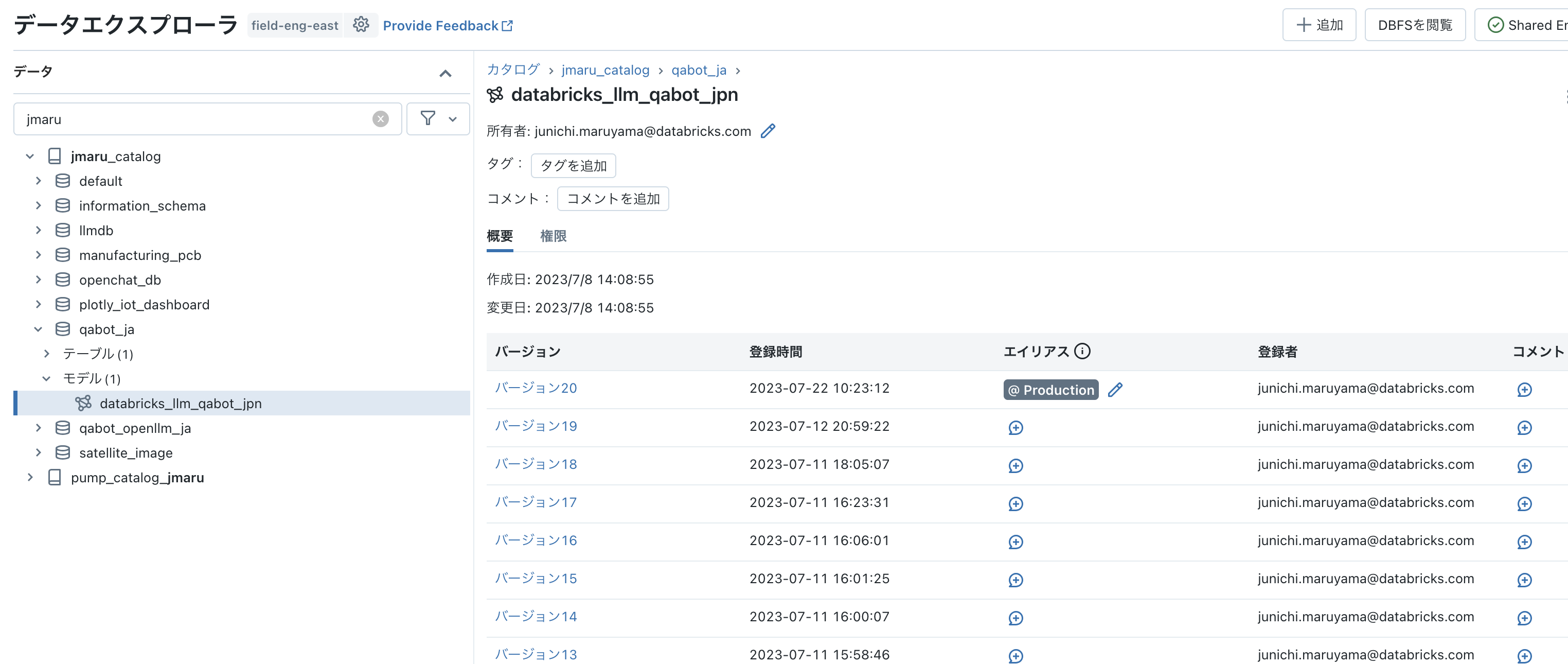
最新のMLflow2.4では、モデルをMLflow Repository以外にもUnityCatalogに保存出来るようになりました。 Unity Catalogに登録すると以下のようにデータエクスプローラーから確認出来るようになり、権限管理やリネージュなども行えるようになります。
次に上記モデルをModel Serving Endpoint にデ�プロイします。ただしLLMをサポートしたMLflowをデプロイする場合、Model Serving v2(Serverless) 機能が必要となります。残念ながらTokyo Regionではまだ(2023/7月時点) Serverless のModel Servingが利用できないため、サンプルノートブックを動かすには US RegionなどサポートされているRegionをご利用ください。

最後のノートブックでは、Slack連携するためのコードをご紹介しております。Solution1と同じくSlackからユーザー問い合わせを受け付けることができます。
始めるには
サンプルノートブックはこちらのレポジトリで公開しております。お手元のDatabricks のReposに登録するとすぐに利用できます。Databricks Runtime (DBR) 13.2ML以降をご利用いただき、初期設定を行った上でノートブックを数字の若い番号から順に実行していきます。実行しながら仕組みを理解されるといいと思います。
またノートブックの使い方なども含め解説しているWebinarがこちらです。今からでも登録してアーカイブをご覧頂けます。
Databricksの投稿を見逃さないようにしましょう
次は何ですか?


ニュース
December 24, 2024/2分で読めます