リアルタイムの構造化データでRAGアプリケーションの応答品質を向上
公開日: December 8, 2023
によって マニ・パルケ、アクラティ・タラティ、Sue Ann Hong(スー・アン・ホン)、クレイグ・ワイリー、Chenen Liang、葛 明陽 による投稿
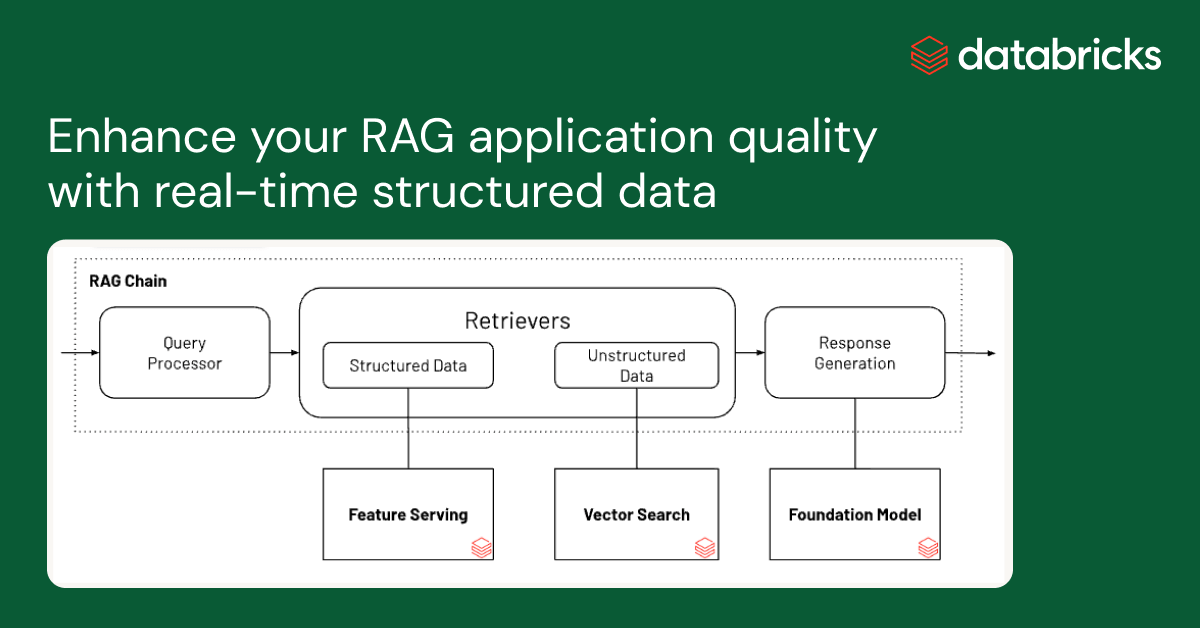
Retrieval Augmented Generation(RAG)は、Gen AIアプリケーションのコンテキストとして関連データを提供する効率的なメカニズムです�。 ほとんどのRAGアプリケーションは、通常、ドキュメントやWiki、サポートチケットなどの非構造化データから関連するコンテキストを検索するためにベクトルインデックスを使用します。 昨日、私たちはDatabricks Vector Search Public Previewを発表しました。 しかし、これらのテキストベースのコンテキストを、関連性のあるパーソナライズされた構造化データで補強することで、Gen AIの応答品質をさらに向上させることができます。 小売業のウェブサイトで、顧客が"最近の注文はどこですか?" と問い合わせる、Gen AIツールを想像してみてください。 このAIは、クエリが特定の購買に関するものであることを理解し、LLMを使用して応答を生成する前に、注文品目の最新の出荷情報を収集しなければなりません。 このようなスケーラブルなアプリケーションを開発するには、構造化データと非構造化データの両方を扱う技術とGen AIの機能を統合する、多大な労力が必要となります。
Databricks Data Intelligence Platformから構造化データを提供する低遅延のリアルタイムサービスである、Databricks Feature & Function Servingのパブリックプレビューを発表できることを嬉しく思います。Unity Cataloから任意のPython関数を呼び出すことで、事前に計算されたMLの特徴(フィーチャー)に即座にアクセスしたり、 リアルタイムデータ変換を実行したりできます。 検索されたデータは、リアルタイムのルールエンジン、古典的なML、およびGen AIアプリケーションで使用できます。
構造化データに対してFeature and Function Serving (AWS)(Azure) を、非構造化データに対してDatabricks Vector Search (AWS)(Azure) と連携して使用することで、Gen AIアプリケーションの実用化が大幅に簡素化されます。ユーザーはこれらのアプリケーションをDatabricksで直接構築・展開し、既存のデータパイプライン、ガバナンス、その他のエンタープライズ機能を利用することができます。Databricksの様々な業界のお客様は、これらの技術をオープンソースのフレームワークと共に使用し、以下の表のような強力なGen AIアプリケーションを構築しています。
| 業種 | ユースケース |
| 小売・消費財 |
|
| 教育 |
|
| 金融サービス |
|
| 旅行・ホスピタリティ |
|
| 医療・ライフサイエンス |
|
| 保険会社 |
|
| テクノロジー・製造 |
|
| メディア・エンターテイメント |
|
構造化データをRAGアプリケーションに提供する
構造化データがどのようにGen AIアプリケーションの品質を高めるのに役立つかを示すために、旅行計画チャットボットの例を使用します。 この例では、ユーザーの嗜好(例:"オーシャンビュー" または"ファミリーフレンドリー" )と、ホテルに関する非構造化情報をペアにして、マッチするホテルを検索する方法を示しています。 通常、ホテルの価格は需要や季節によってダイナミックに変化します。 Gen AIアプリケーションに内蔵された価格計算機能により、ユーザーの予算内で推奨商品が提供されます。 ボットを動かすGen AIアプリケーションは、Databricks Vector SearchとDatabricks Feature and Function Servingをビルディングブロックとして使用し、LangChainのエージェントAPIを使用して、必要なパーソナライズされたユーザー嗜好、予算、ホテル情報を提供します。
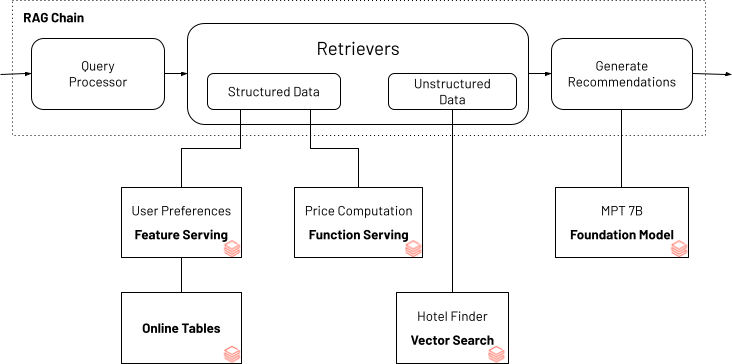
*ユーザーの好みと予算を考慮した旅行計画ボット
このRAGチェーン・アプリケーションのNotebookです。このアプリケーションは、Notebook内でローカルに実行することも、チャットボットのユーザー・インターフェースからアクセス可能なエンドポイントとしてデプロイすることもできます。
リアルタイムのエンドポイントとしてデータや機能にアクセスする
Unity CatalogのFeature Engineeringでは、すでにプライマリキーを持つ任意のテーブルを使用して、トレーニングやサービングのために特徴(フィーチャー)を提供することができます。 Databricks Model Servingは、Python関数を使用してオンデマンドでフィーチャーを計算することをサポートしています。 Databricks Model Servingと同じ技術を使用して構築されたフィーチャーエンドポイントとファンクションエンドポイントは、事前に計算されたフィーチャーにアクセスしたり、オンデマンドで計算したりすることができます。 簡単な構文で、有向非巡回グラフを計算してRESTエンドポイントとしてフィーチャーを提供するためにエンコードできるfeature spec functionをUnity Catalogで定義できます。
このfeature spec functionは、RESTエンドポイントとしてリアルタイムで提供することができます。 すべてのエンドポイントは、機能、機能、カスタムトレーニングモデル、基礎モデルを含む、左のナビゲーションタブからアクセスできます。 このAPIを使ってエンドポイントをプロビジョニングします。
エンドポイントは、以下のようにUIワークフローを使用して作成することもできます。
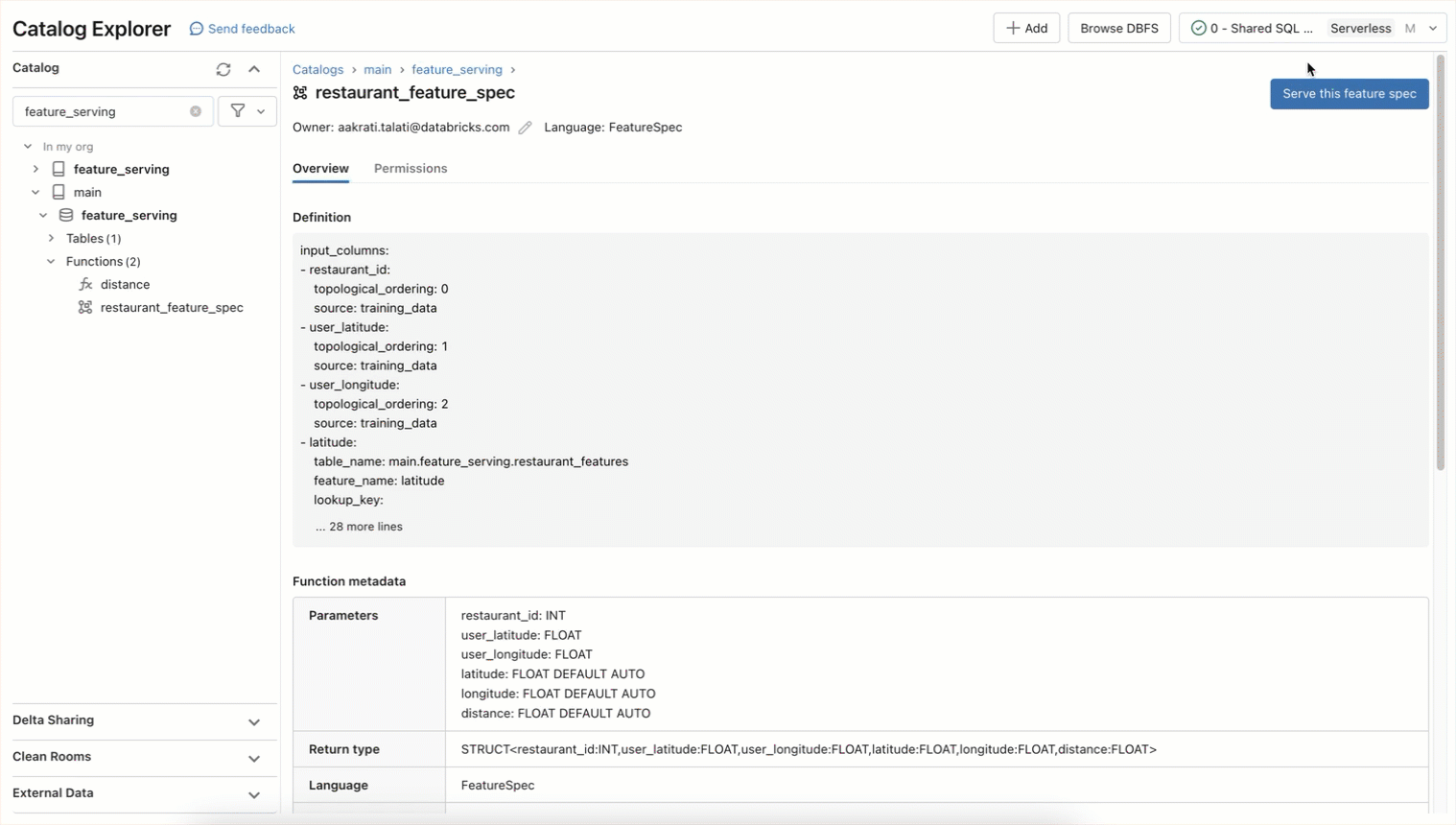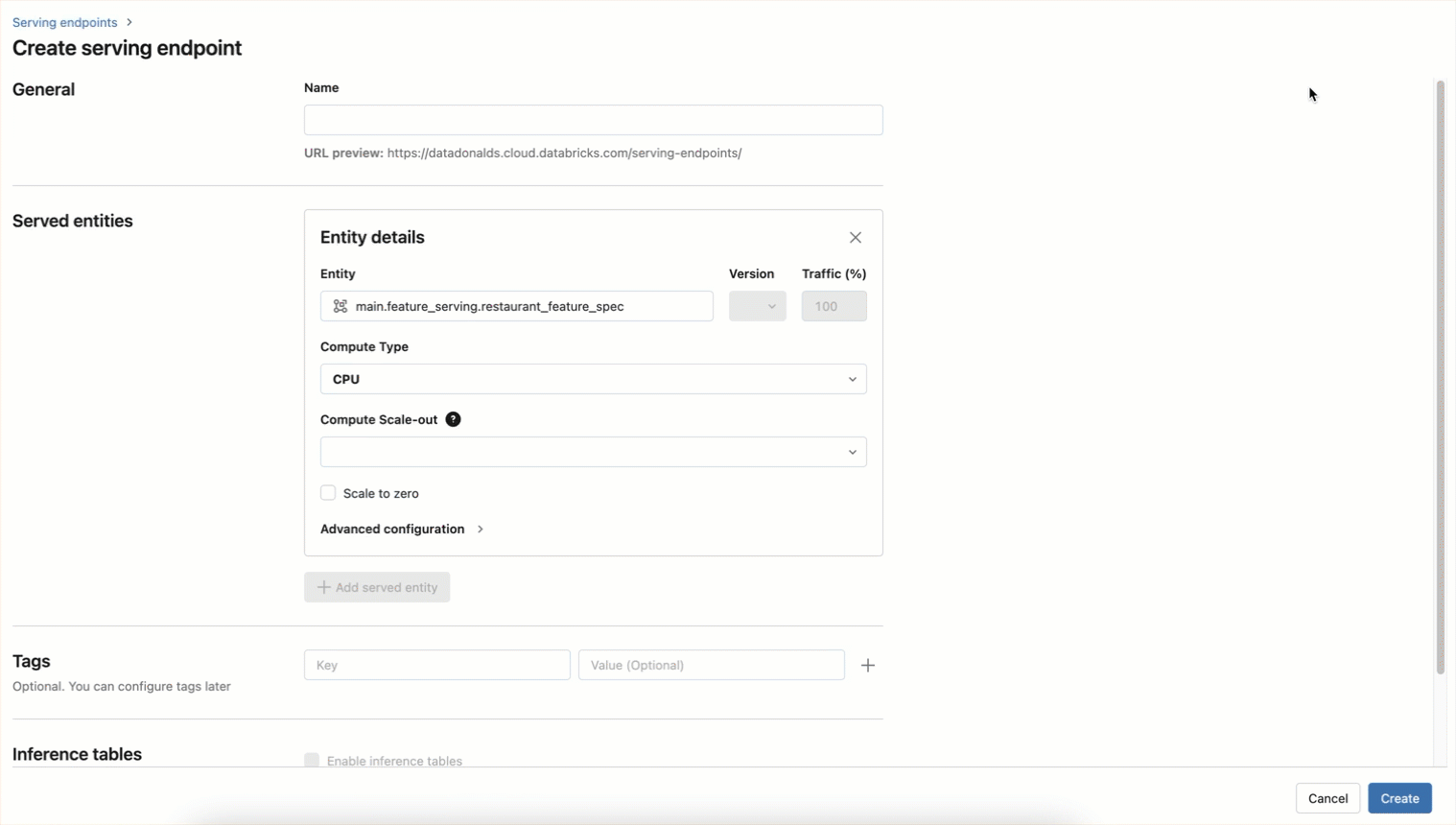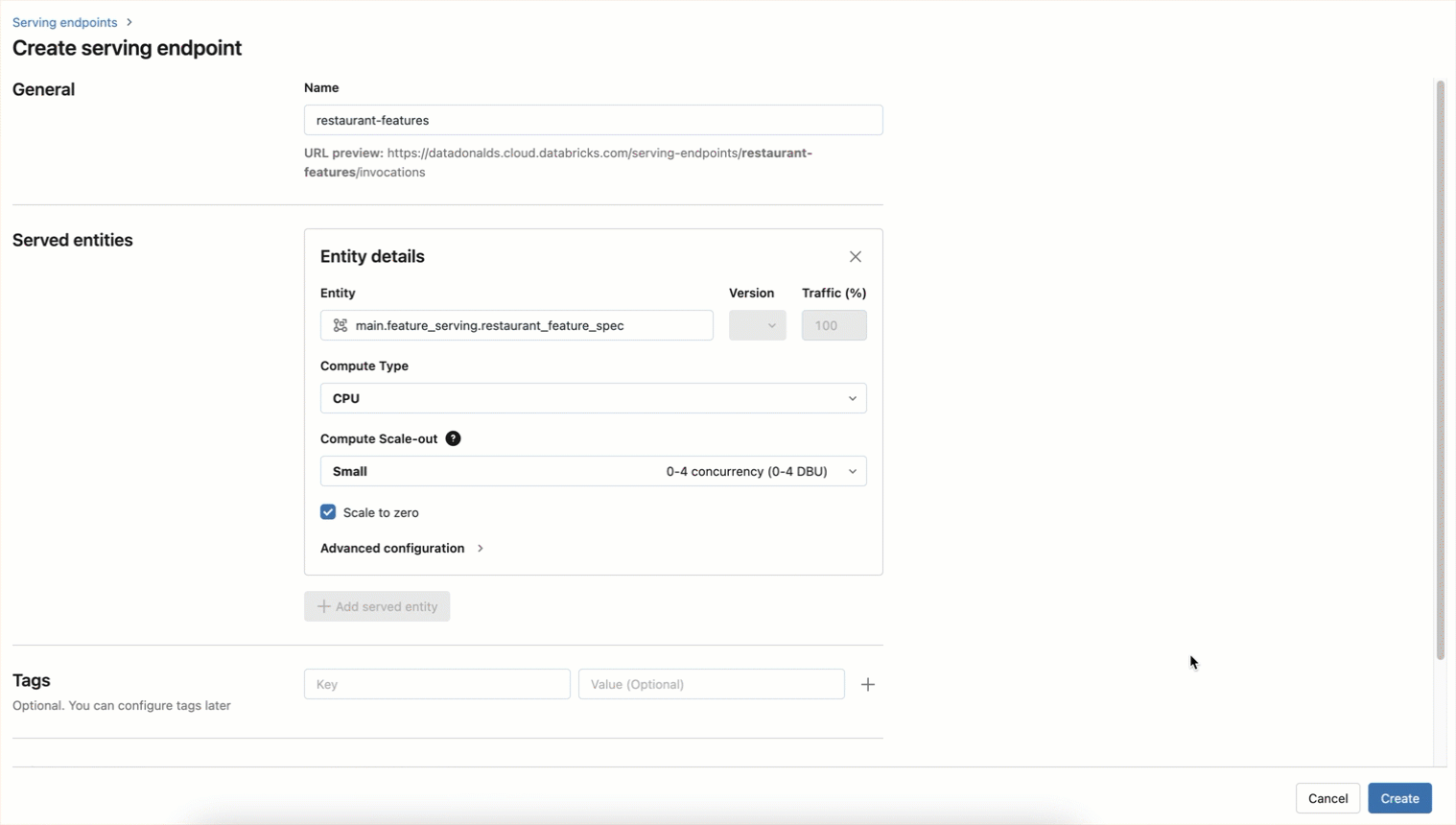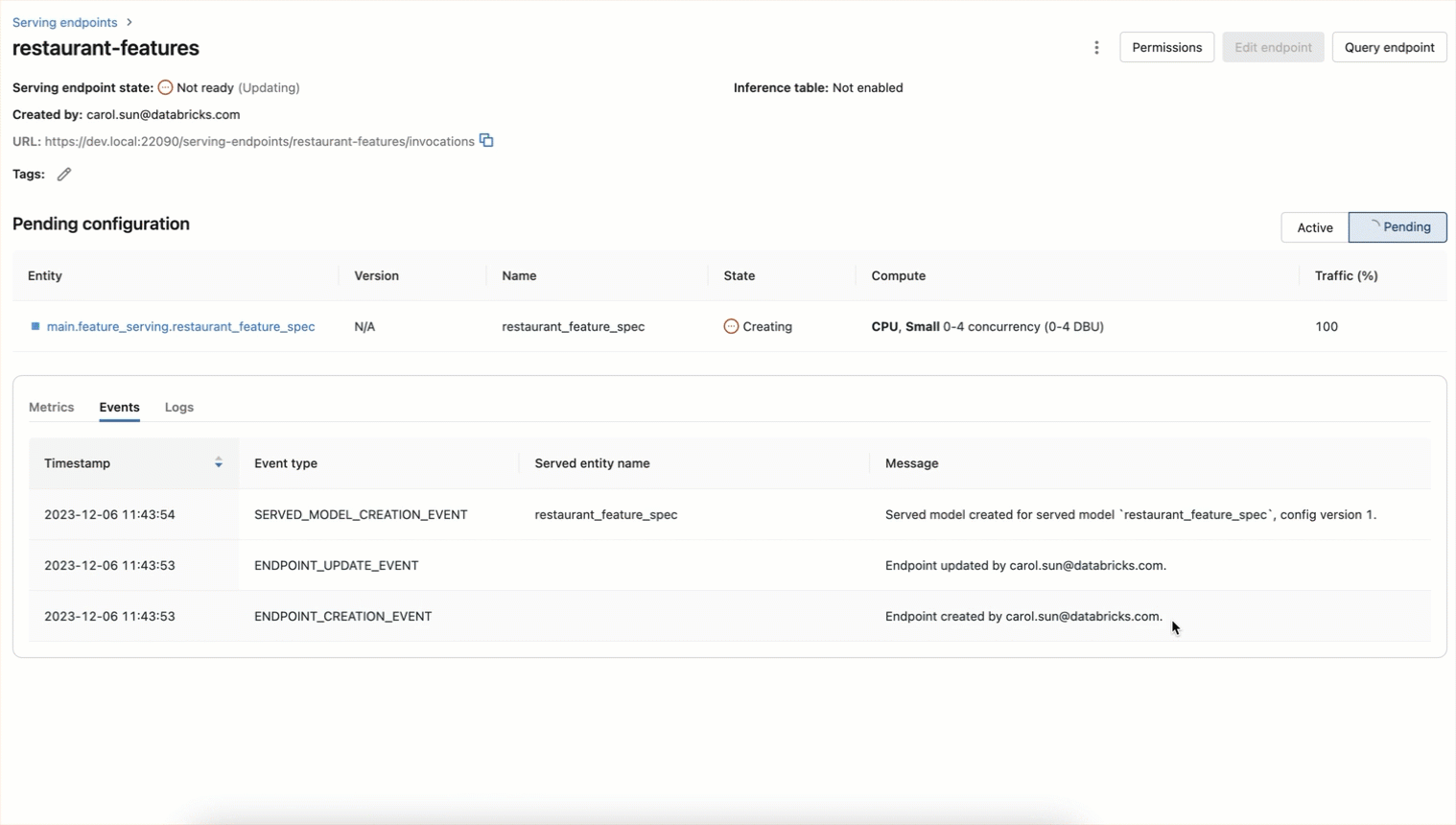
エンドポイントに問い合わせることで、リアルタイムで機能にアクセスできるようになりました:
リアルタイムのAIアプリケーションに構造化データを提供するには、事前に計算されたデータを運用データベースに展開する必要がある。 例えば、DynamoDBやCosmos DBは、Databricks Model Servingでフィーチャーを提供するために一般的に使用されています。 Databricks Online Tables (AWS) (Azure) は、低レイテンシのデータ検索に最適化されたデータ形式への事前計算機能の同期を簡素化する新機能です。 主キーを持つ任意のテーブルをオンライン・テーブルとして同期させることができ、システムは自動パイプラインを設定してデータの鮮度を確保します。
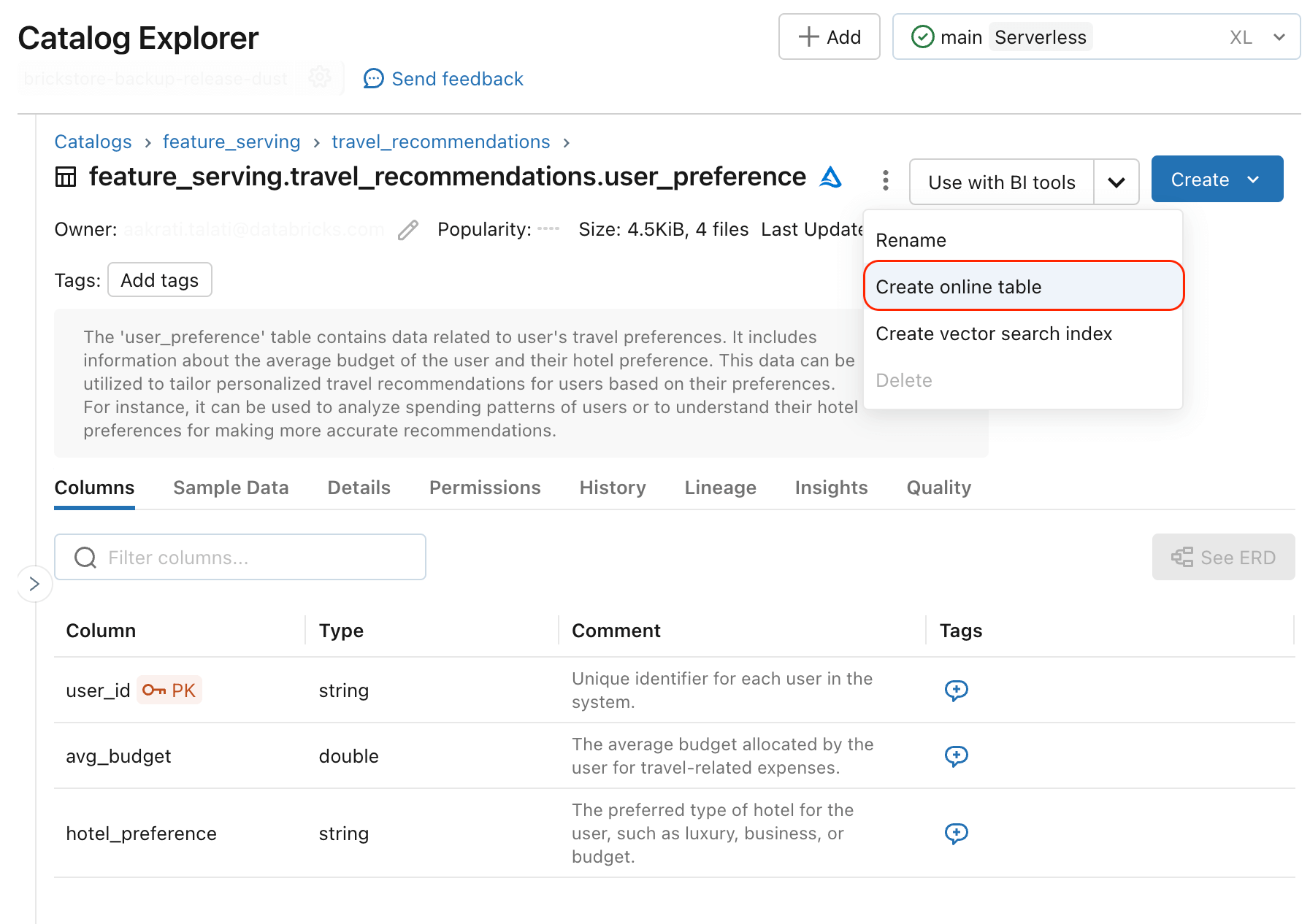
Databricks Online Tablesを使用することで、主キーを持つUnity Catalog テーブルをGen AIアプリケーションのフィーチャーに使用することができます。
次のステップ
上記のNotebook の例を使用して、RAG アプリケーションをカスタマイズしてください。
Databricks Generative AI Webセミナーにお申し込みください。
Feature & Function Serving (AWS)(Azure) はパブリック・プレビューで利用可能です。 APIドキュメントと追加例を参照ください。
Databricks�オンラインテーブル (AWS)(Azure) はGated Public Previewとして利用可能です。 有効化のお申し込みは、こちらのフォームをご利用ください。
今週初めに行われた概要発表(質の高いRAG申請を行う)
Databricksと共有したいユースケースをお持ちですか? [email protected]までお問い合わせください。
Databricksの投稿を見逃さないようにしましょう
次は何ですか?


データサイエンス・ML
October 30, 2024/1分未満