Databricks Lakeflowの登場: データエンジニアリングのための統一されたインテリジェントソリューション
データベース、企業アプリ、クラウドソースからデータを取り込み、バッチおよびリアルタイムストリーミングで変換し、自信を持って本番環境にデプロイおよび運用できます。

Translation Review by saki.kitaoka
本日、私たちはDatabricks Lakeflowを発表します。これは、プロダクションデータパイプラインを構築および運用するために必要なすべてを含む新しいソリューションです。MySQL、Postgres、SQL Server、Oracleなどのデータベースや、Salesforce、Microsoft Dynamics、NetSuite、Workday、ServiceNow、Google Analyticsなどの企業アプリケーション向けの新しいネイティブで高スケーラビリティのコネクタが含まれています。ユーザーは標準SQLおよびPythonを使用して、バッチおよびストリーミングでデータを変換できます�。
さらに、Apache Spark向けのリアルタイムモードを発表し、従来のマイクロバッチよりもはるかに高速なレイテンシでストリーム処理が可能になります。最後に、CI/CDを使用してワークフローをオーケストレーションおよびモニタリングし、本番環境にデプロイできます。Databricks LakeflowはData Intelligence Platformにネイティブに組み込まれており、サーバーレスコンピュートとUnity Catalogによる統一ガバナンスを提供します。

このブログ記事では、Lakeflowがデータチームが信頼性の高いデータとAIの増大する需要に応えるのにどのように役立つか、そしてLakeflow の主要機能が単一の製品エクスペリエンスに統合されている理由について説明します。
信頼性の高いデータパイプラインの構築および運用する際の課題
データエンジニアリング(新鮮で高品質かつ信頼性の高いデータの収集・準備)は、ビジネスにおけるデータとAIの活用を推進する上で不可欠です。しかし、これを実現するには多くの複雑さが伴い、多くの異なるツールを統合する必要があります。
まず、データチームは各システムの形式やアクセス方法に合わせて複数のシステムからデータを取り込む必要があります。これには、データベースや企業アプリケーション用の内部コネクタを構築および維持することが含まれます。企業アプリケーションのAPI変更に対応するだけ�でも、データチーム全体のフルタイムの仕事になることがあります。その後、データをバッチおよびストリーミングで準備する必要があり、トリガーおよびインクリメンタル処理のための複雑なロジックを記述および維持する必要があります。レイテンシの急増や障害が発生すると、通知が鳴り、データ消費者が不満を感じ、ビジネスに支障をきたし、最終的には収益に影響を与えることもあります。最後に、データチームはこれらのパイプラインをCI/CDを使用してデプロイし、データ資産の品質とリネージを監視する必要があります。通常、これにはPrometheusやGrafanaなどの新しいツールをデプロイ、学習、管理する必要があります。
このような理由から、データインテリジェンスに基づいたデータの取り込み、変換、オーケストレーションの統一ソリューションであるLakeflowを構築することにしました。Lakeflowは「Lakeflow Connect」「Lakeflow Pipelines」「Lakeflow Jobs」の3つの主要コンポーネントで構成されています。
Lakeflow Connect:シンプルでスケーラブルなデータ取り込み
Lakeflow Connectは、MySQL、Postgres、SQL Server、Oracleなどのデータベースや、Salesforce、Microsoft Dynamics、NetSuite、Workday、ServiceNow、Google Analyticsなどの企業アプリケーションからのポイント&クリックデータ取り込みを提供します。Lakeflow Connectはまた、SharePointなどのソースからのPDFやExcelスプレッドシートなどの非構造化データの取り込みも可能です。
Lakeflow Connectは、クラウドストレージ(例:S3、ADLS Gen2、GCS)やキュー(例:Kafka、Kinesis、Event Hub、Pub/Subコネクタ)およびパートナーソリューション(例:Fivetran、Qlik、Informatica)の人気のあるネイティブコネクタを拡張します。
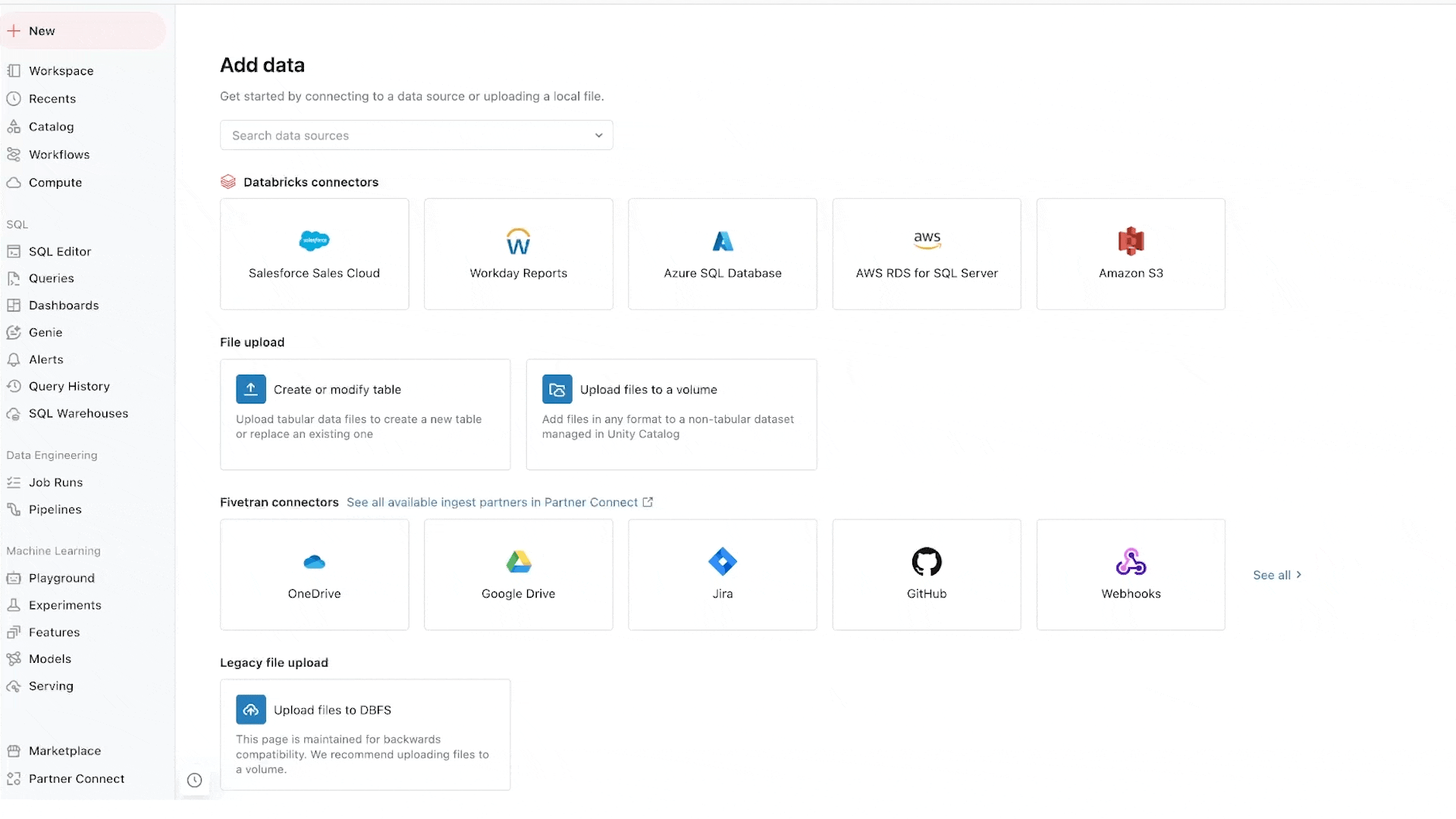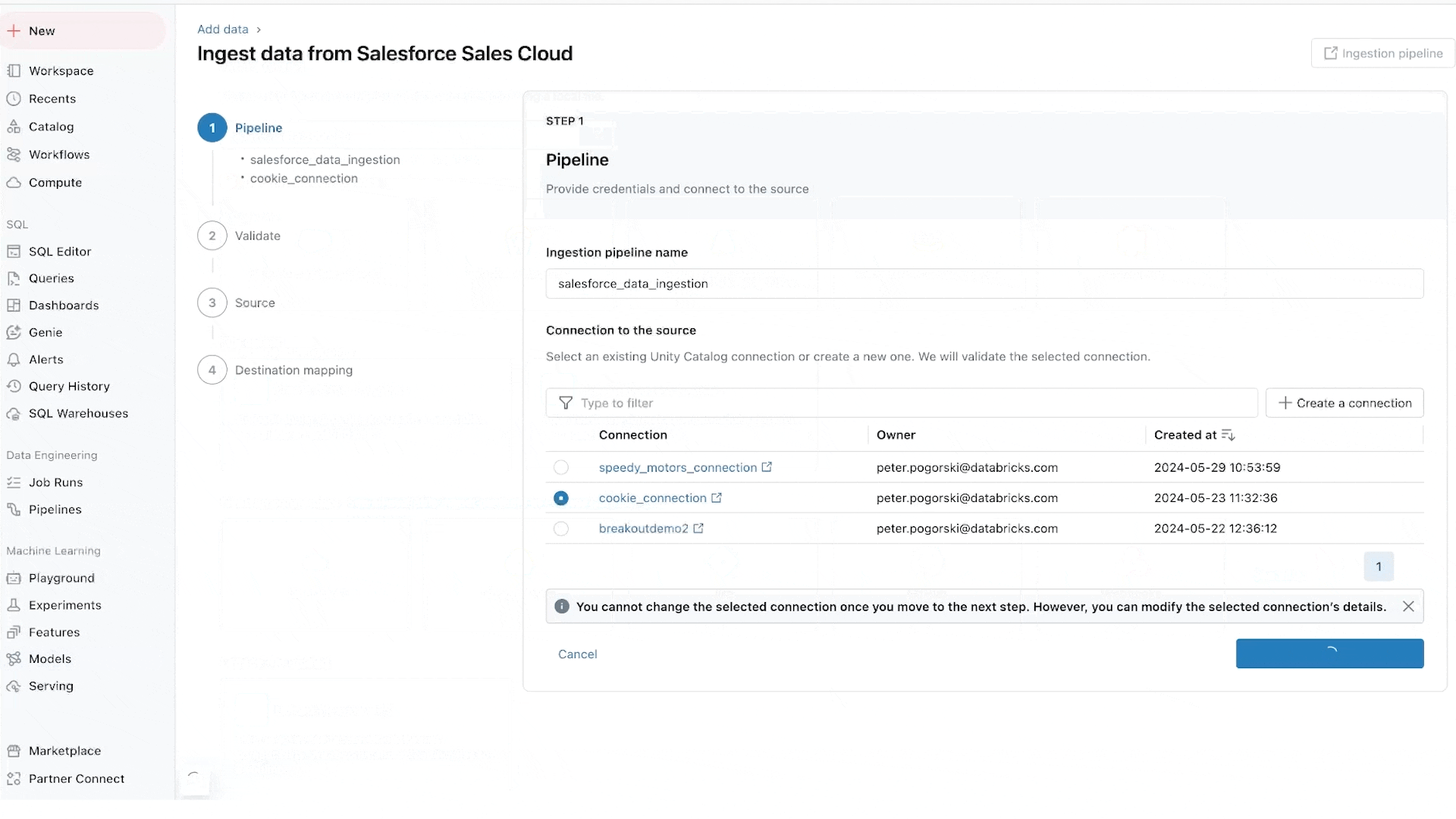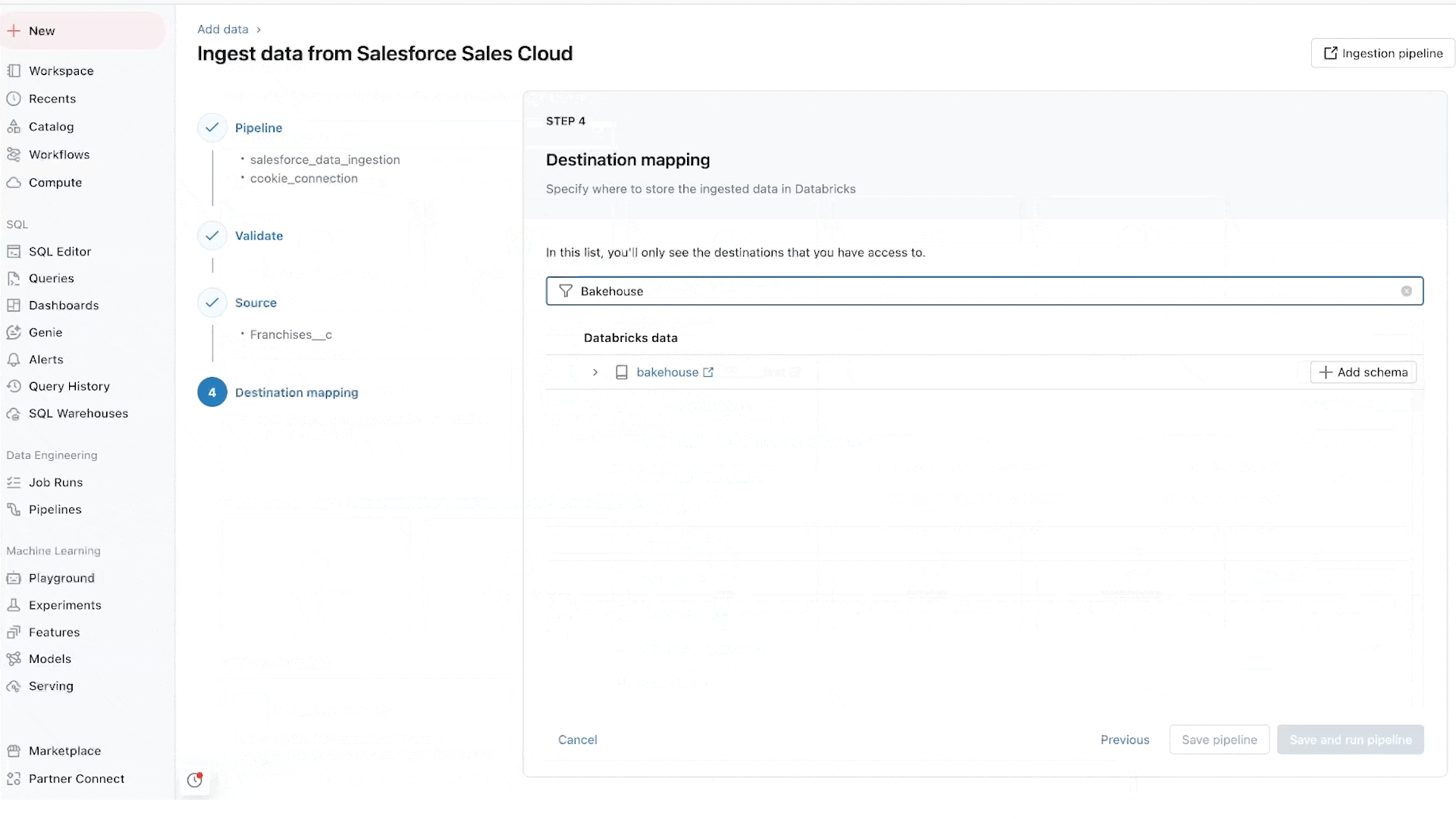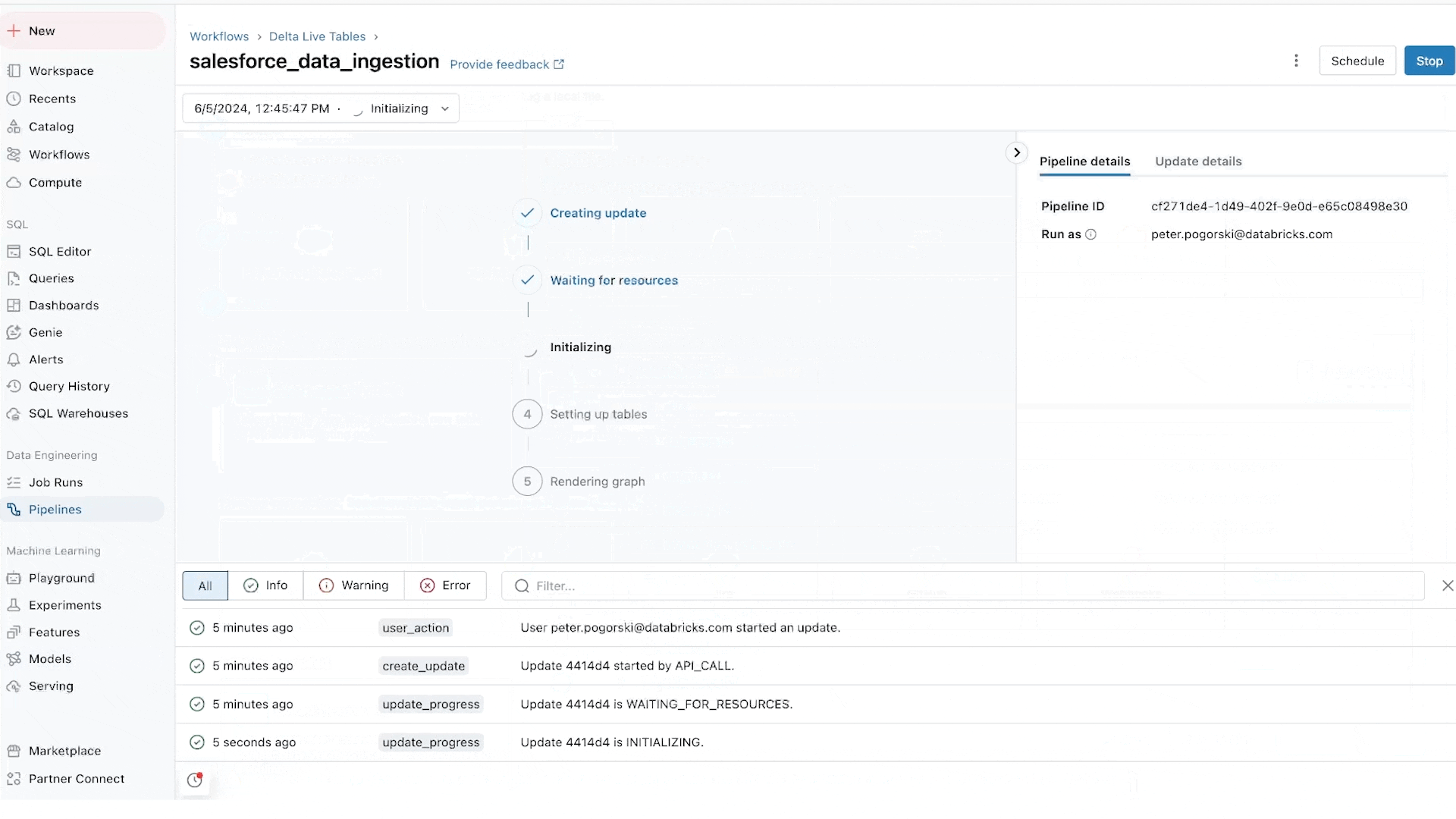
特にデータベースコネクタについては、Arcion 社の買収によって実現されたものであり、多くの貴重なデータが運用データベースに閉じ込められている状況を解消します。運用およびスケーリングの問題を抱えるナイーブなアプローチを取る代わりに、Lakeflowは変更データキャプチャ(CDC)技術を使用して、このデータをレイクハウスにシンプルかつ信頼性高く、効率的に取り込むことができます。
Databricksの顧客は、Lakeflow Connectを使用してシンプルな取り込みソリューションが生産性を向上させ、データからインサイトへの移行を迅速に行えることを発見しています。ウェアラブルインスリン管理システム「Omnipod」のメーカーであるInsuletは、Salesforce取り込みコネクタを使用して、顧客のフィードバックに関連するデータをDatabricks上に構築されたデータソリューションに取り込んでいます。このデータはDatabricks SQLを通じて分析可能になり、品質問題に関する洞察を得て顧客の苦情を追跡できます。Insuletのチームは、Lakeflow Connectの新機能に大きな価値を見出しています。
「Databricksの新しいSalesforce取り込みコネクタにより、脆弱で問題のあるミドルウェアを排除し、データ統合プロセスが大幅に簡素化されました。この改善により、Databricks SQLでSalesforceデータを直接分析できるようになり、データ担当者は最新のインサイトをほぼリアルタイムで提供できるようになり、レイテンシが日単位から分単位に短縮されました。」 — Bill Whiteley, Senior Director of AI, Analytics, and Advanced Algorithms, Insulet
Lakeflow Pipelines:効率的な宣言型データパイプライン
Lakeflow Pipelinesは、効率的なバッチおよびストリーミングデータパイプラインの構築と管理の複雑さを低減します。宣言型Delta Live Tablesフレームワークに基づいて構築されており、ビジネスロジックをSQLとPythonで記述するだけで、Databricksがデータオーケストレーション、インクリメンタル処理、コンピュートインフラの自動スケーリングを自動化します。さらに、Lakeflow Pipelinesは組み込みのデータ品質監視を提供し、リアルタイムモードを使用して、コード変更なしで時間依存のデータセットの一貫して低レイテンシのデリバリーを可能にします。
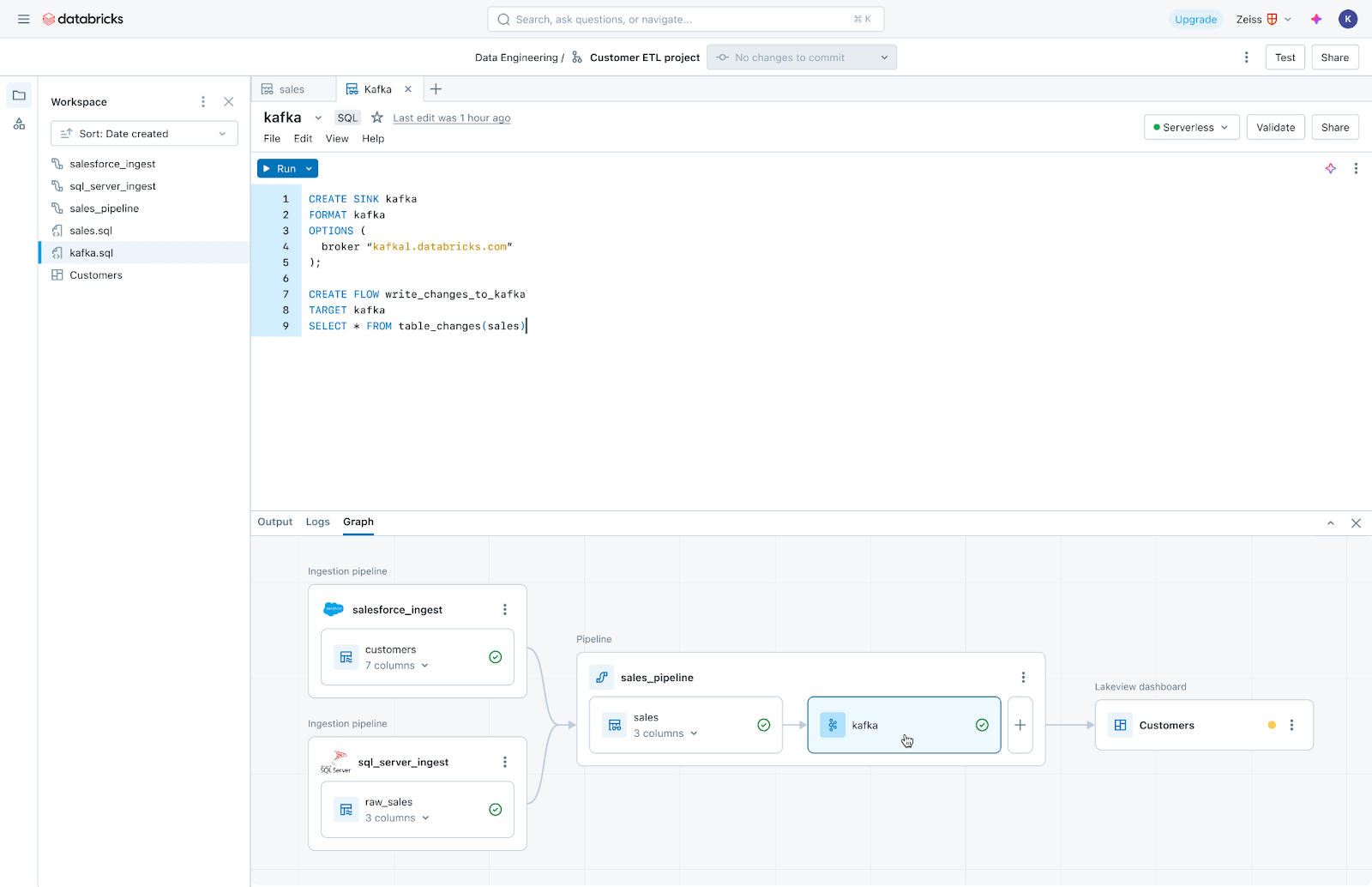
Lakeflow Jobs:あらゆるワークロードに対応する信頼性の高いオーケス��トレーション
Lakeflow JobsはDatabricks Workflowsの高度な機能を基盤に、データ取り込み、パイプライン、ノートブック、SQLクエリ、機械学習モデルのトレーニング・デプロイ・推論など幅広いワークロードをオーケストレーションします。データチームは、トリガー、分岐、ループを活用して、複雑なデータデリバリーのユースケースに対応できます。
Lakeflow Jobsは、データのヘルスチェックとデリバリー状況を理解および追跡するプロセスも自動化および簡素化します。データチームには、取り込み、変換、テーブル、ダッシュボード間の関係を含む完全なリネージュを提供し、データの鮮度と品質を追跡できます。Lakehouse Monitoringを使用してワンクリックでモニターを追加することもできます。
データインテリジェンスプラットフォーム上に構築
Databricks Lakeflowは、次の機能を提供するデータインテリジェンスプラットフォームにネイティブに統合されています:
- データインテリジェンス:AI駆動のインテリジェンスは、Lakeflowの特徴だけでなく、製品のすべての側面に触れる基盤能力です。Databricks Assistantは、データパイプラインの発見、作成、監視を支援し、信頼性の高いデータを構築するための時間を増やします。
- 統一ガバナンス:LakeflowはUnity Catalogと深く統合されており、系譜とデータ品質を強化します。
- サーバーレスコンピュート:スケールに応じてパイプラインを構築およびオー�ケストレーションし、インフラを気にせずに作業に集中できるようにします。
データエンジニアリングの未来はシンプルで統一され、インテリジェントです
私たちは、Lakeflowが顧客に新鮮で、より完全で高品質なデータを提供できるようにすると信じています。Lakeflowはまもなくプレビューを開始し、まずLakeflow Connectからスタートします。アクセスをリクエストする場合は、こちらにサインアップしてください。今後数か月間、追加機能が利用可能になるにつれて、Lakeflow に関するさらなる発表が予定されています。おたのしみに!

