Mixtral 8x7B と Databricks モデルサーヴィングのご紹介

reviewed by saki.kitaoka
本日、DatabricksはモデルサーヴィングでMixtral 8x7Bをサポートすることを発表します。Mixtral 8x7BはスパースなMixture of Experts(MoE)オープン言語モデルで、多くの最先端モデルを凌駕するか、あるいはそれに匹敵します。最大32kトークン(約50ページのテキスト)の長いコンテキストを処理する能力を持ち、そのMoEアーキテクチャはより高速な推論を提供するため、RAG(Retrieval-Augmented Generation)やその他の企業ユースケースに理想的です。
Databricks Model Servingは、プロダクショングレードのエンタープライズ対応プラットフォーム上で、オンデマンド価格でMixtral 8x7Bへの即時アクセスを提供します。毎秒数千のクエリをサポートし、シームレスなベクターストア統合、自動化された品質モニタリング、統合ガバナンス、アップタイムのSLAを提供します。このエンド・ツー・エンドの統合により、GenAI Systemsを本番環境に導入するための迅速なパスが提供されます。
エキスパート混合モデル (MoE) とは?
Mixtral 8x7BはMoEアーキテクチャを採用しており、これはLlama2などのモデルで使用されているGPTライクな高密度アーキテクチャを大きく進化させたものと考えられています。GPTのようなモデルでは、各ブロックはアテンション層とフィードフォワード層で構成されています。MoEモデルのフィードフォワード層は、それぞれが「エキスパート」と呼ばれる複数の並列サブレ�イヤーで構成され、どのエキスパートにトークンを送信するかを決定する「ルーター」ネットワークが前面にあります。MoEモデルのすべてのパラメータが与えられたトークンに対してアクティブになるわけではないため、MoEモデルは「スパース」アーキテクチャとみなされます。下図は、switch transformersに関する実用的な論文で示されたそれを絵的に示したものです。研究コミュニティでは、各エキスパートがデータの特定の側面や領域の学習に特化していることが広く受け入れられています[Shazeer et al.]。
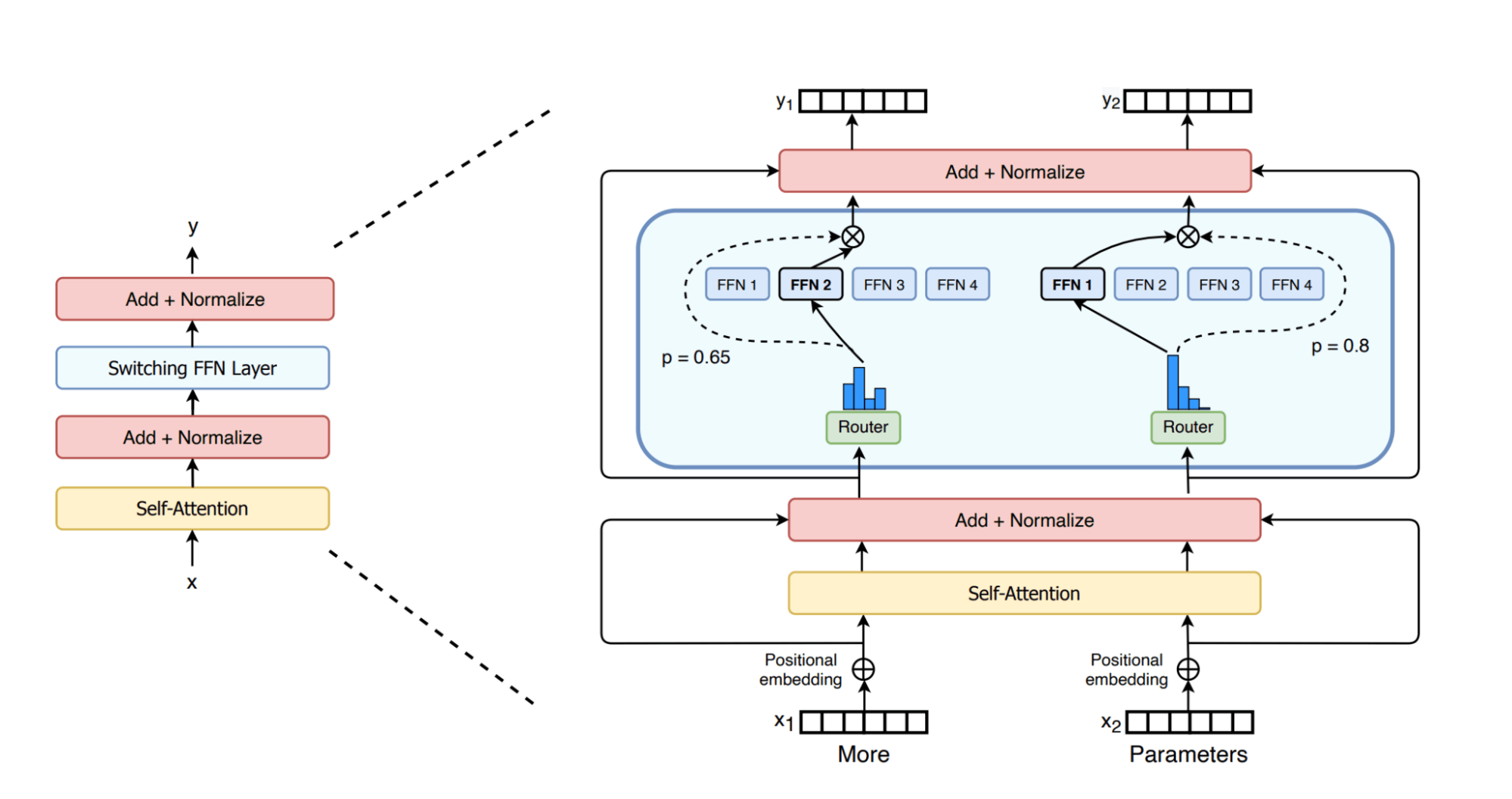
MoE アーキテクチャの主な利点は、密なモデルに必要な推論時間の計算を比例して増加させることなく、モデルサイズを拡張できることです。MoEモデルでは、各入力トークンは利用可能なエキスパートのうち選択されたサブセット(例えばMixtral 8x7Bでは各トークンに対して2つのエキスパート)のみによって処理されるため、学習と推論中に各トークンに対して行われる計算量を最小限に抑えることができます。また、MoEモデルはフィードフォワード層のみをエキスパートとして扱い、残りのパラメータは共有するため、「Mistral 8x7B」��はその名前から想像される560億ではなく、470億のパラメータを持つモデルとなります。しかし、各トークンは、ライブ・パラメータとも呼ばれる約130億個のパラメータでしか計算しません。同等の47Bの高密度モデルは、フォワードパスで94B(2*#params)FLOPを必要としますが、Mixtralモデルはフォワードパスで26B(2 * #live_params)演算しか必要としません。つまり、Mixtralの推論は13Bのモデルと同程度の速度で実行でき、かつ47B以上の高密度なモデルと同程度の品質で実行できるということです。
MoEモデルは一般的にトークンあたりの計算量は少ないですが、推論性能のニュアンスはより複雑です。同サイズの密なモデルと比較したMoEモデルの効率向上は、処理されるデータバッチのサイズによって異なります。例えば、Mixtral推論が大きなバッチサイズで計算量に縛られる場合、密なモデルに対して~3.6倍のスピードアップが期待されます。一方、バッチサイズが小さく、帯域幅に制約のある領域では、スピードアップはこの最大比率よりも小さくなります。前回のブログポストでは、これらの概念について詳しく説明し、バッチサイズが小さいほど帯域幅が制限され、大きいほど計算が制限される傾向を説明しました。
Mixtral 8x7BのためのシンプルでプロダクショングレードのAPI
Foundation Model APIでMixtral 8x7Bに即座にアクセス
Databricks Model Serving は、Foundation Model API を介して Mixtral 8x7B に即座にアクセスできるようになりました。Foundation Model API は、トークン単位で利用することができるため、コストを大幅に削減し、柔軟性を高めることができます。Foundation Model API は Databricks インフラストラクチャから提供されるため、データをサードパーティのサービスに転送する必要はありません。
Foundation Model APIはまた、Mixtral 8x7Bモデル用のProvisioned Throughputを備えており、一貫したパフォーマンス保証を提供し、ファインチューニングされたモデルや高QPSトラフィックをサポートします。
Mixtral 8x7Bと他のモデルを簡単に比較できます。
Mixtral 8x7B には、他の Foundation Model と同じ統一された API と SDK でアクセスできます。この統一されたインターフェイスにより、すべてのクラウドとプロバイダでファウンデーションモデルの実験、カスタマイズ、プロダクション化が可能になります。
また、SQL 関数 `ai_query` を使って SQL から直接モデル推論を呼び出すこともできます。 詳しくはai_queryのドキュメントをご覧ください。
Databricks 内でホストされているか Databricks 外でホストされているかにかかわらず、すべてのモデルが 1 つの場所にあるため、権限を一元管理し、使用制限を追跡し、すべてのタイプのモデルの品質を監視することができます。これにより、適切なガードレールが利用できるようにしながら、追加のセ�ットアップコストを発生させたり、継続的なアップデートに負担をかけたりすることなく、新しいモデルリリースの恩恵を簡単に受けることができます。
"DatabricksのFoundation Model APIを利用することで、ボタンを押すだけで、最先端のオープンモデルをクエリできるようになりました。このプラットフォーム上で複数のモデルを使用していますが、これまでのところ、安定性と信頼性に感心しています。" - Sidd Seethepalli, CTO & Founder, Vellum
最適化されたパフォーマンスで最新モデルを提供するDatabricksによって、最先端技術を利用することができます。
Databricksは、お客様が最適化された推論で、最良かつ最新のオープンモデルを利用できるよう尽力しています。 このアプローチにより、それぞれのタスクに最適なモデルを柔軟に選択することができ、利用可能なモデルのスペクトルが拡大し続けている中で、新たな開発の最前線に立ち続けることができます。 当社は、お客様が引き続き低遅延と総所有コスト(TCO)の削減を享受できるよう、最適化のさらなる改善に積極的に取り組んでいます。 これらの進歩に関する最新情報は、来年早々にお届けする予定です。
"Databricks Model Serving は、Databricks 上または Databricks 外でホストされているモデルを含む、複数の SaaS モデルおよびオープンモデルへのセキ��ュアなアクセスと管理を容易にすることで、当社の AI 主導プロジェクトを加速しています。一元化されたアプローチにより、セキュリティとコスト管理が簡素化され、当社のデータチームはイノベーションにより集中し、管理オーバーヘッドを削減することができます。" - Greg Rokita, AVP, Technology at Edmunds.com
Databricks Model ServingでMixtral 8x7Bを使い始めるには
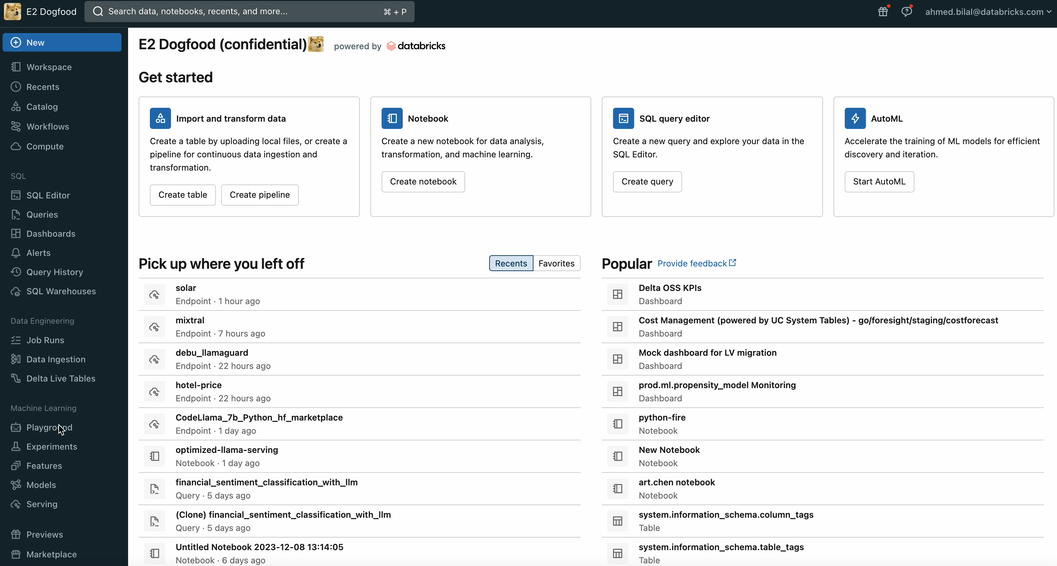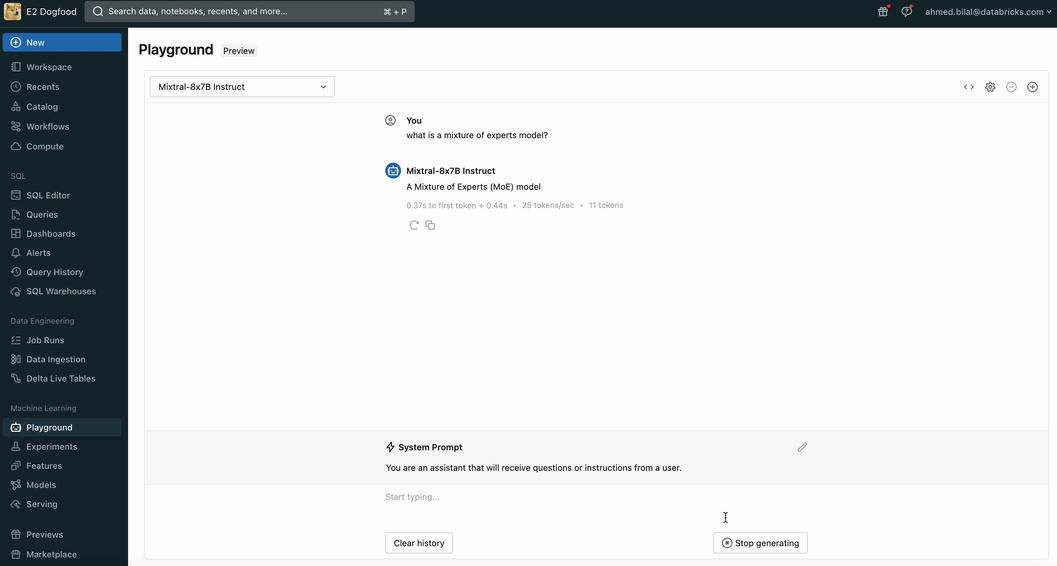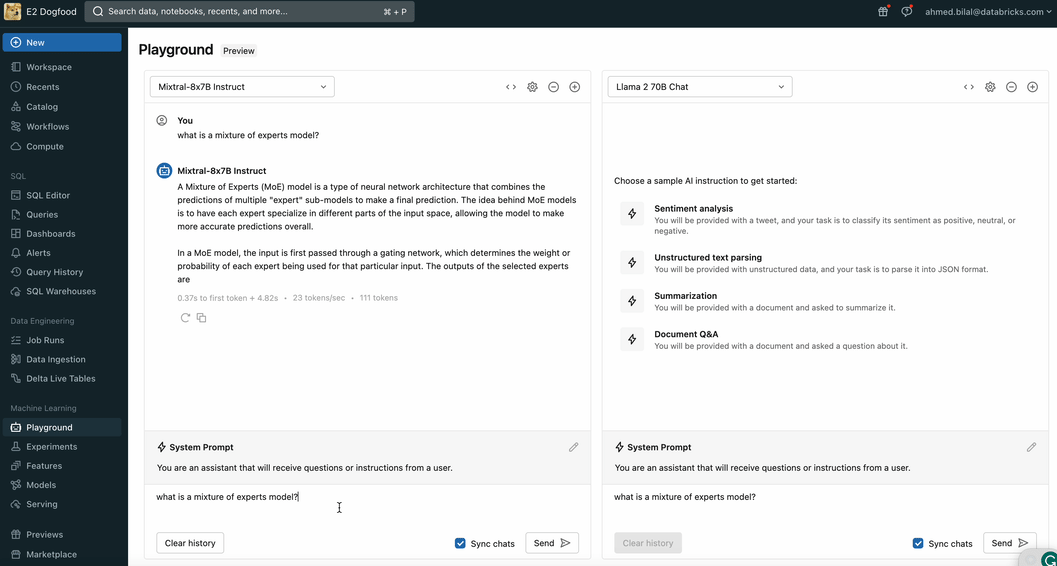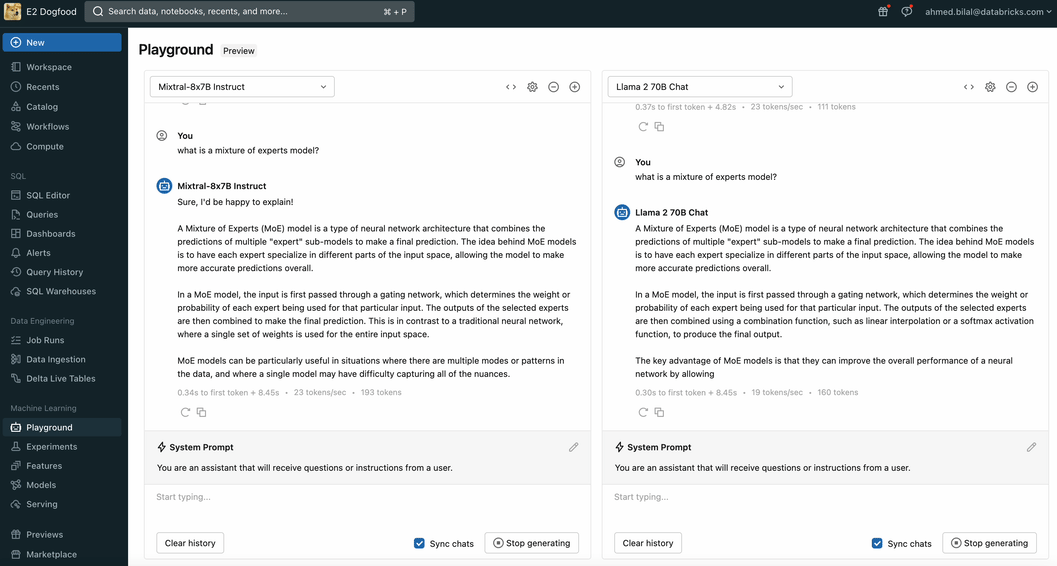
Databricks AI Playgroundにアクセスすると、ワークスペースから直接、生成AIモデルをすばやく試すことができます。
詳細はこちら:
- Foundation Model APIDocumentation を参照してください。
- Databricks Marketplaceで基盤モデルを発見
- Databricks Model Servingのウェブページに移動します。
ライセンス
Mixtral 8x7B はApache-2.0の下でライセンスされています。

