生成AIモデルのファインチューニングが簡単に!Databricks Model Trainingが登場
本日、Mosaic AIモデルトレーニングによる生成AIモデルの微調整サポートがパブリックプレビューで利用可能になったことをお知らせできることを嬉しく思います。Databricksでは、汎用LLM(大規模言語モデル)の知能と企業データの知識を結びつけること、すなわち「データインテリジェンス」が高品質な生成AIシステムを構築する鍵であると考えています。ファインチューニングにより、モデルは特定のタスクやビジネスコンテキスト、専門知識に特化でき、RAG(再利用可能な生成)と組み合わせることで、より正確なアプリケーションが可能になります。これにより、企業データを取り入れて生成AIを独自のニーズに適応させるための重要な柱となる「データインテリジェンスプラットフォーム�戦略」が形成されます。
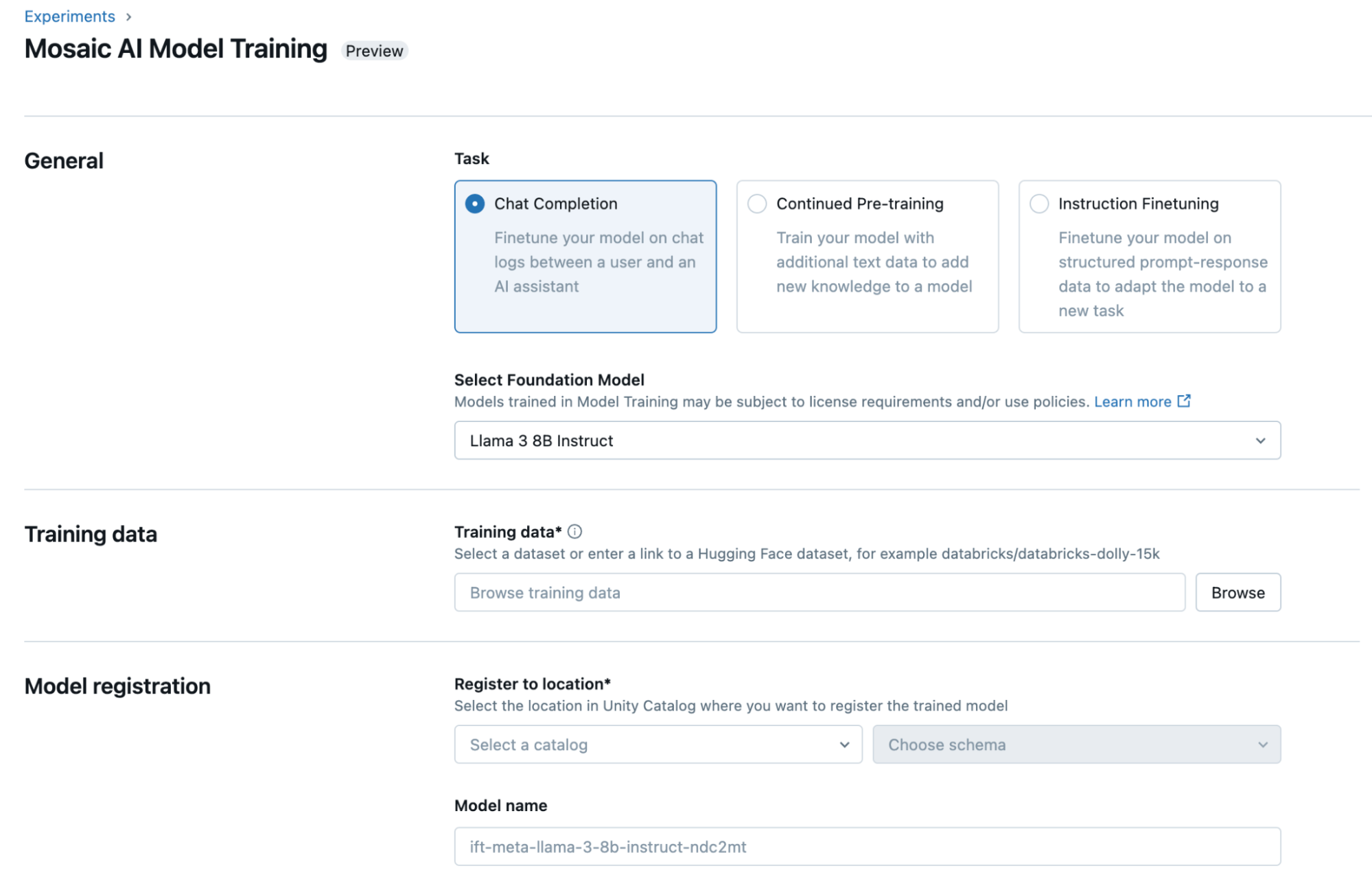
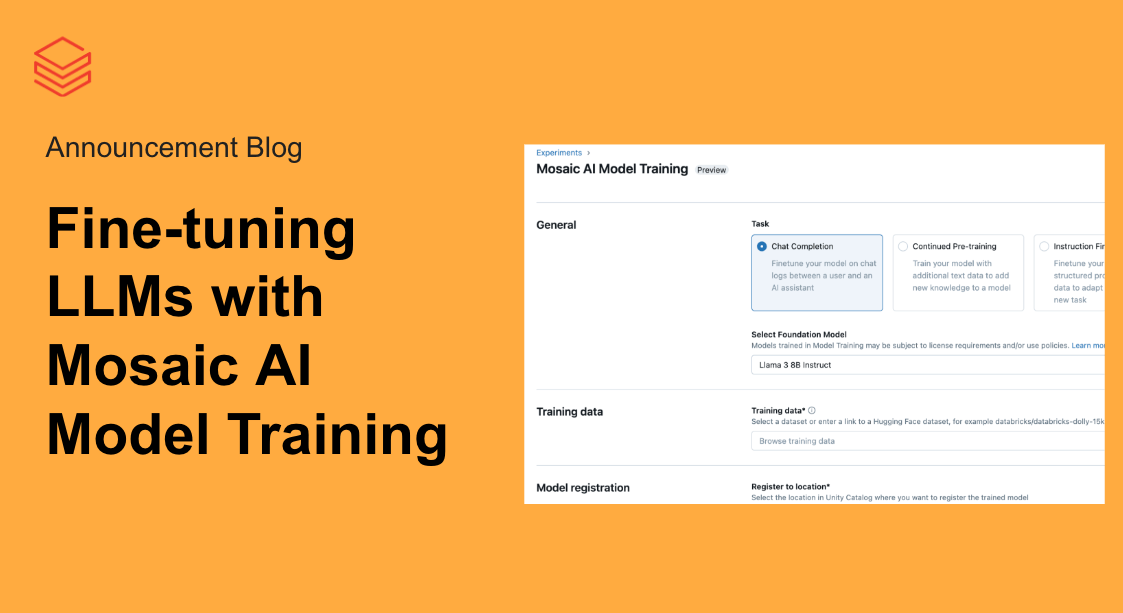
モデルトレーニング
私たちの顧客は昨年、20万以上のカスタムAIモデルをトレーニングしており、その経験を基にDatabricks Model Trainingという完全マネージドサービスを開発しました。Llama 3、Mistral、DBRXなど、幅広いモデルを企業データでファインチューニングまたは事前トレーニングできます。生成されたモデルはUnity Catalogに登録され、モデルとその重みに対する完全な所有権と制御が提供されます。さらに、Databricks Model Servingを使えば、モデルをワンクリックで簡単にデプロイできます。
Databricks Model Trainingは次のように設計されています:
- シンプル: ベースモデルとトレーニングデータセットを選択し、すぐにトレーニングを開始できます。GPUや効率的なトレーニングの複雑さは私たちが処理するので、モデリングに専念できます。
- 高速: 独自のトレーニングスタックによって、オープンソースの2倍の速さでトレーニングを行い、迅速にモデルを構築できます。数千の例でのファインチューニングから、数十億のトークンでの継続的な事前トレーニングまで、私たちのトレーニングスタックはスケールに応じて対応します。
- 統合: Databricksプラットフォーム上でデータを簡単に取り込み、変換し、前処理を行い、トレーニングに直接取り込むことができます。
- 調整可能: 学習率やトレーニング期間といった主要なハイパーパラメータを迅速に調整し、最高品質のモデルを構築します。
- 主権性: モデルとその重みの完全な所有権を持ちます。あなたは権限を制御し、リネージにアクセスし、トレーニング データセットと下流の消費者を追跡します。
「Experian では、オープンソース LLM のファインチューニングの分野で革新を行っています。 Mosaic AIモデルのトレーニングにより、モデルの平均トレーニング時間が大幅に短縮され、GenAI 開発サイクルを 1 日に複数回の反復に加速することができました。最終的には、私たちが定義した方法で動作し、私たちのユースケースでは商用モデルよりも優れたパフォーマンスを発揮し、運用コストが大幅に削減されるモデルが完成しました。」 ---- James Lin, Head of AI/ML Innovation, Experian
メリット
Databricks Model Trainingは、オープンソースモデルを企業の特化したタスクに適応させ、高品質なパフォーマンスを実現します。
メリットには以下が含まれます:
- 高品質: 要約、チャットボットの挙動、ツールの利用、多言語の会話など、特定のタスクや機能に合わせてモデルの品質を向上させます。
- 低コストで��低遅延: 大規模な汎用モデルは、運用時にコストが高く、遅延が大きいことがあります。多くの顧客は、ファインチューニングされた小規模モデル(<13Bパラメータ)が、品質を維持しながら遅延とコストを大幅に削減できると実感しています。
- 一貫した、構造化されたフォーマットやスタイル: エンティティ抽出や複合AIシステムでのJSONスキーマの作成など、特定のフォーマットやスタイルに従った出力を生成します。
- 軽量で管理しやすいシステムプロンプト: 多くのビジネスロジックやユーザーフィードバックをモデル自体に統合します。エンドユーザーのフィードバックを複雑なプロンプトに組み込むのは難しく、小さなプロンプトの変更が他の質問に対して退行を引き起こす可能性があります。
- ナレッジベースの拡充: 継続的な事前トレーニングにより、特定のトピックや内部文書、言語、またはモデルの元々の知識カットオフ以降の最新イベントなど、モデルのナレッジベースを拡充します。継続的な事前トレーニングのメリットについては、今後のブログでお伝えしていきますので、ご期待ください!
「 Databricksでは、LLM を使用して 1 日あたり 100 万件以上のファイルを処理して、物件記録から取引データとエンティティ データを抽出することで、面倒な手作業を自動化できました。Meta Llama3 8b をファインチューニングし、 Databricks Model Servingを使用することで、精度の目標を超えました。大規模で高価な GPU フリートを管理する必要なく、この操作を大幅に拡張できました。」 - Prabhu Narsina、データおよびAI担当副社長、First American
MLOps のビッグブック

RAGとファインチューニング
お客様からよく聞かれる質問は、「企業データを組み込むには、RAG を使用するか、モデルをファインチューニングするべきでしょうか?」ということです。検索拡張ファインチューニング ( RAFT ) を使用すると、その両方を組み合わせることができます。たとえば、当社のお客様である Celebal Tech は、生成モデルを微調整して取得したコンテキストからの要約品質を向上させ、ハルシネーションを減らして品質を向上させることで、高品質のドメイン固有の RAG システムを構築しました (�下の図を参照)。
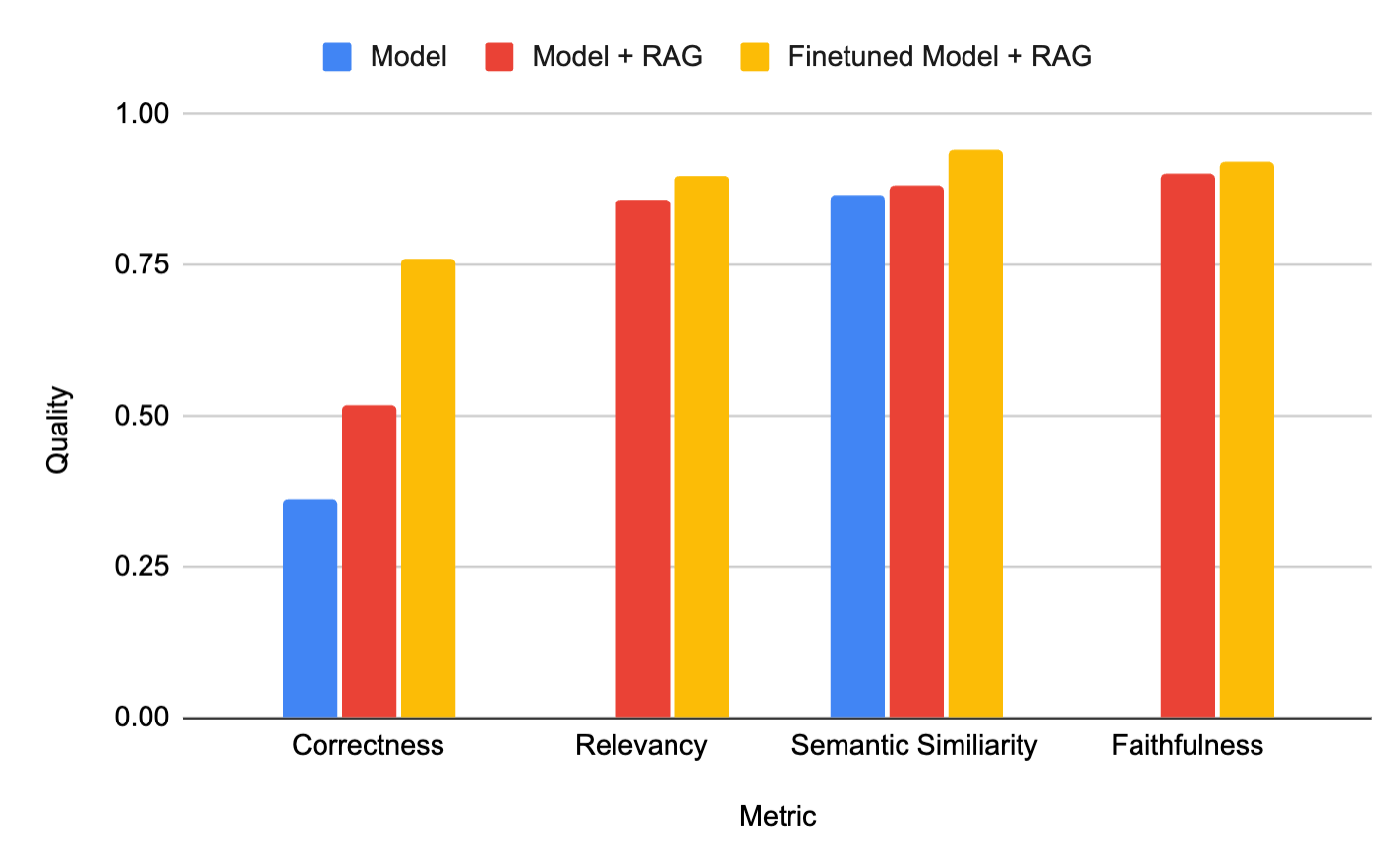
図 1:微調整されたモデルと RAG (黄色) を組み合わせることで、顧客 Celebal Tech 向けに最高品質のシステムが実現しました。同社のブログから引用。
私たちはRAGに限界を感じていました。たくさんのプロンプトや指示を書かなければならず、手間がかかりました。そこで、ファインチューニング+RAGに移行したところ、Databricks Model Trainingがとても簡単にしてくれました!このツールは、データ言語学とドメインにモデルを適応させただけでなく、幻覚(ハルシネーション)を減らし、RAGシステムの速度を向上させました。DatabricksでファインチューニングしたモデルをRAGシステムと組み合わせた結果、トークンの使用量を減らしながら、より優れたアプリケーションと精度を得ることができました。 ---- Anurag Sharma、AVP データサイエンス、Celebal Technologies
評価
評価方法は、ファインチューニング実験中にモ�デルの品質やベースモデルの選択を改善するために重要です。視覚的な検査チェックから「LLM-as-a-Judge」まで、Databricks Model Trainingは、Databricks内の他のすべての評価システムとシームレスに連携するよう設計されています。
- プロンプト: トレーニング中に監視するプロンプトを最大10個追加できます。定期的にモデルの出力をMLflowダッシュボードにログとして記録し、トレーニング中のモデルの進捗を手動で確認できます。
- プレイグラウンド: ファインチューニングされたモデルをデプロイし、プレイグラウンドで手動のプロンプトテストや比較を行います。
- LLM-as-a-Judge: MLFlow Evaluationを使用して、別のLLMを用いて既存またはカスタムメトリクスの範囲でファインチューニングされたモデルを評価します。
- ノートブック: ファインチューニングされたモデルをデプロイした後、エンドポイントでカスタム評価コードを実行するためのノートブックやカスタムスクリプトを作成します。
無料トライアル
DatabricksのUIを通じて、またはPythonでプログラム的にモデルをファインチューニングできます。始めるには、Unity Catalog内のトレーニングデータセットの場所またはHugging Faceの公開データセットを選択し、カスタマイズしたいモデルを指定し、1クリックでデプロイできるようにモデルを登録する場所を選んでください。
- Mosaic AI モデルトレーニングに関する データと AI サミットの プレゼンテーションを ご覧ください
- ドキュメント( AWS 、 Azure )を読んで、価格ページをご覧ください。
- dbdemo をMosaic AI 試して 、 モデル トレーニングで高品質のモデルを取得する方法をすぐに確認してください。
- チュートリアル を受講する