シンプル・高速・スケーラブル!Mosaic AIで実現するバッチ LLM 推論

長年にわたり、企業は膨大な量の非構造化テキストデータ(文書、報告書、メールなど)を蓄積してきましたが、そこから意味のあるインサイトを抽出することは依然として課題でした。現在、大規模言語モデル(LLM)を活用することで、このデータをスケーラブルに分析する方法が実現しており、バッチ推論が最も効率的な解決策となっています。しかし、多くのツールはオンライン推論に焦点を当てており、バッチ処理機能の充実にはまだ課題が残されています。
本日、大規模文書に LLM を適用するための、よりシンプルで高速、かつスケーラブルな方法を発表します。これまでのようにデータを CSV ファイルとして未管理の場所にエクスポートする必要はありません。今では、Unity Catalog による完全なガバナンスのもと、ワークフロー内でバッチ推論を直接実行できます。以下の SQL クエリを記述し、ノートブックやワークフローで実行するだけで完了します。
ai_queryを使用すれば、前例のない速度で大規模なデータセットを処理することが可能になり、最大規模のデータも迅速に処理できます。このインターフェースはすべての AI モデルに対応しており、LLM、従来の AI モデル、複合 AI システムを安全に適用し、スケールに応じたデータ分析を実現できます。
図1:バッチ推論ジョブは、規模が何であれ - 数百万または数十億のトークン - 同じ、馴染みのあるSQLインターフェースを使用して定義されます。
「Databricks を活用することで、ドキュメントのメタデータ抽出と後処理のためのマルチモーダル・バッチパイプラインを実行し、4000 億トークン以上を処理しました。データが存在する場所で馴染みのあるツールを使いながら、データをエクスポートしたり巨大な GPU インフラを管理することなく、統合ワークフローを実行し、生成 AI の価値をデータに直接もたらすことができました。Scribd, Inc. では、バッチ推論を活用して、さらなる価値提供の機会を広げることに期待しています。」— Steve Neola, Scribd シニアディレクター
人々はバッチLLM推論を何に使っているのでしょうか?
バッチ推論により、企業は LLM をリアルタイム推論のように一度に1つではなく、大規模データセット全体に一度に適用できるようになります。データを一括で処理することで、コスト効率が高まり、処理速度が向上し、スケーラビリティも確保されます。企業がバッチ推論を活用している一般的な方法には以下が含まれます:
- 情報抽出: 大規模なテキストから主要なインサイトを抽出したり、トピックを分類することで、レビューやサポートチケットなどの文書からデータ駆動の意思決定をサポートします。
- データ変換: 非構造化テキストを翻訳、要約、構造化形式に変換し、データの質を向上させ、後続タスクに備えます。
- 一括コンテンツ生成: 商品説明、マーケティング文、ソーシャルメディア投稿のテキストを自動生成し、企業がコンテンツ制作をスムーズにスケールできるようにします。
現在のバッチ推論の課題
従来のバッチ推論アプローチにはいくつかの課題があります:
- 複雑なデータ処理: 既存のソリューションでは、データの手動エクスポートやアップロードが必要となることが多く、運用コストやコンプライアンス上のリスクが高まります。
- 分断されたワークフロー: 多くの本番バッチワークフローには、前処理、マルチモデル推論、後処理といった複数のステップが含まれます。これには複数のツールを組み合わせる必要があり、実行が遅くなり、エラーのリスクも増大します。
- パフォーマンスとコストのボトルネック: 大規模な推論には、専門的なインフラとチームによる設定と最適化が必要で、アナリストやデータサイエンティストがセルフサービスでインサイトをスケールさせる能力が制限されます。
エンタープライズ向けエージェントAIプレイブック

Databricks Model Serving上のバッチLLM推論
「Databricks を活用することで、LLM を使用して物件記録から取引データやエンティティデータを抽出し、100 万件以上のファイルを毎日処理するという面倒な手作業を自動化できました。Meta Llama3 8b をファインチューニングすることで精度目標を上回り、Databricks Model Serving を使って、この処理を大規模に拡張しつつ、大量で高コストな GPU インフラを管理する必要がなくなりました。」— Prabhu Narsina, First American VP データ&AI
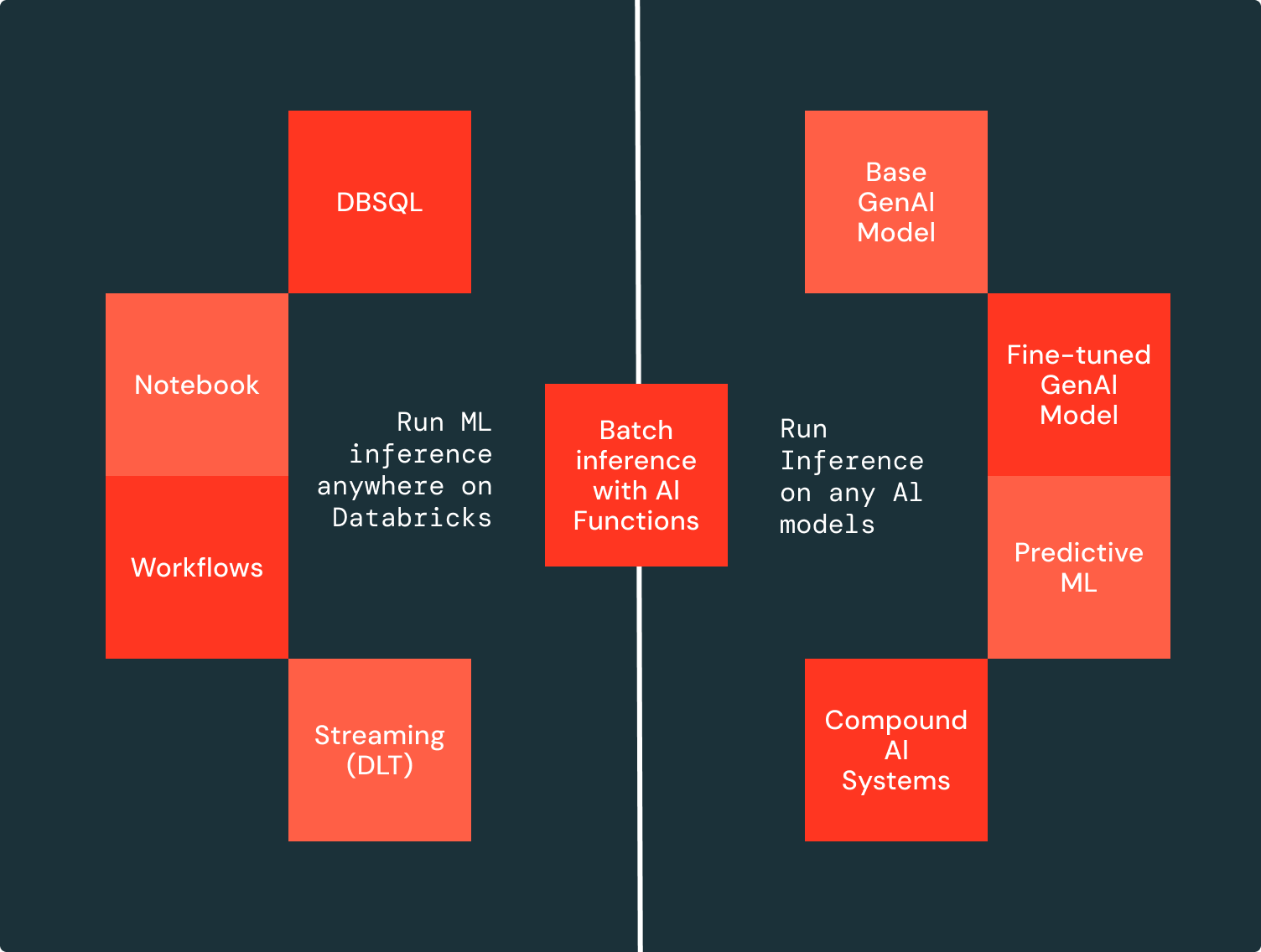
統制されたデータ管理上で手軽にAI活用
Mosaic AI を使用すると、ガバナンスの効いたデータが存在する場所で直接バッチ LLM 推論を実行でき、データ移動や準備は不要です。バッチ LLM 推論の適用は、任意の AI モデルでエンドポイントを作成し、SQL クエリを実行するだけで簡単に行えます(図に示されています)。Databricks 上の任意の開発環境から、ベースモデル、ファインチューニングモデル、従来の AI モデルをデプロイし、SQL エディタやノートブックでの対話的な実行、または Workflows や Delta Live Tables (DLT) を通じたスケジュール実行が可能です。
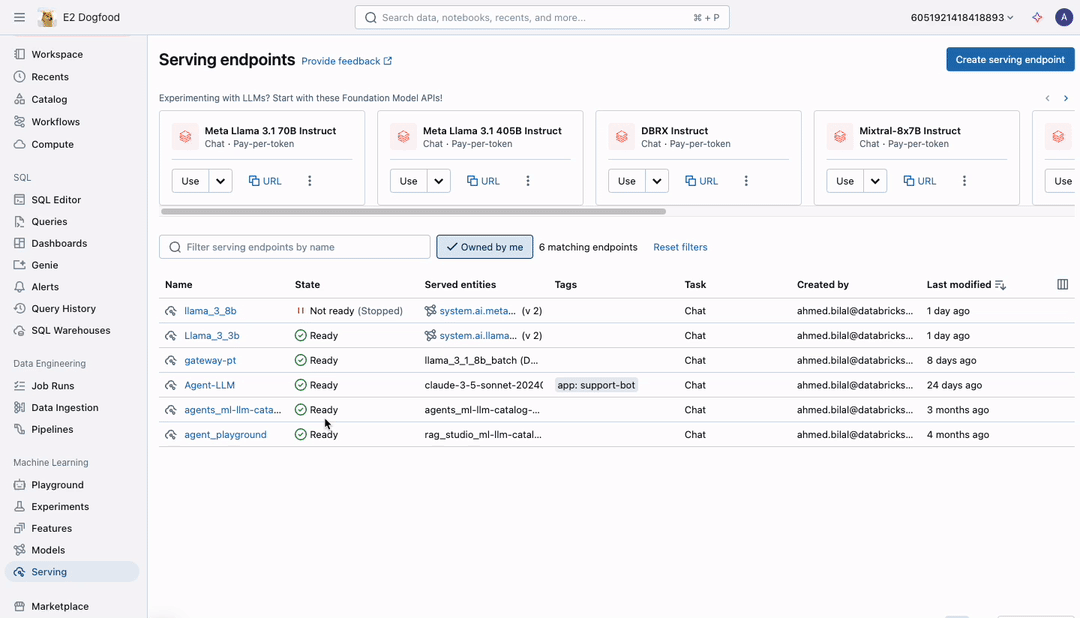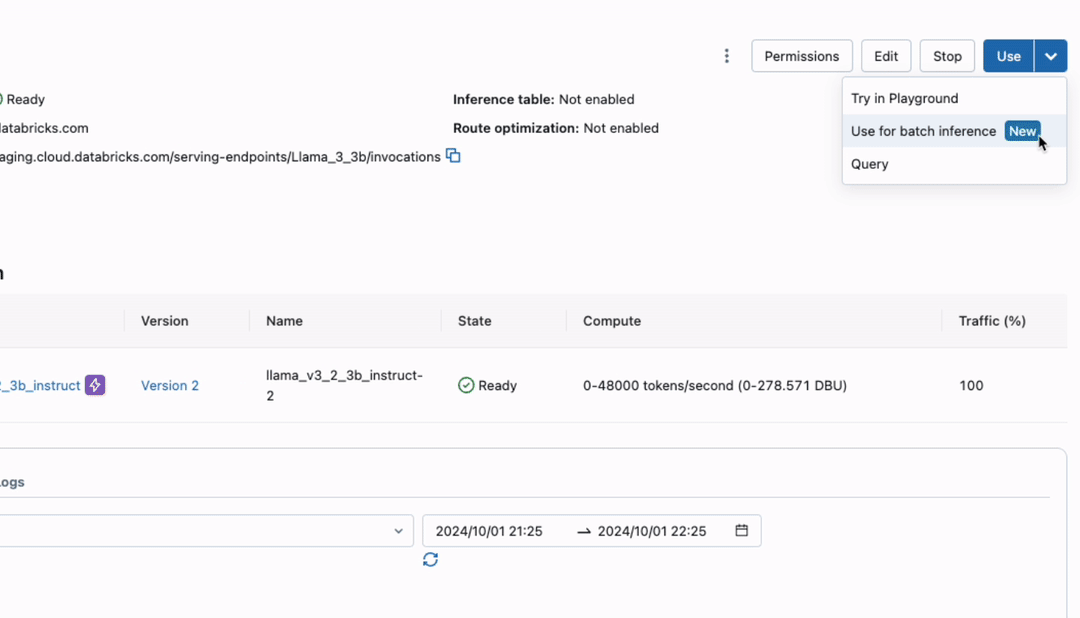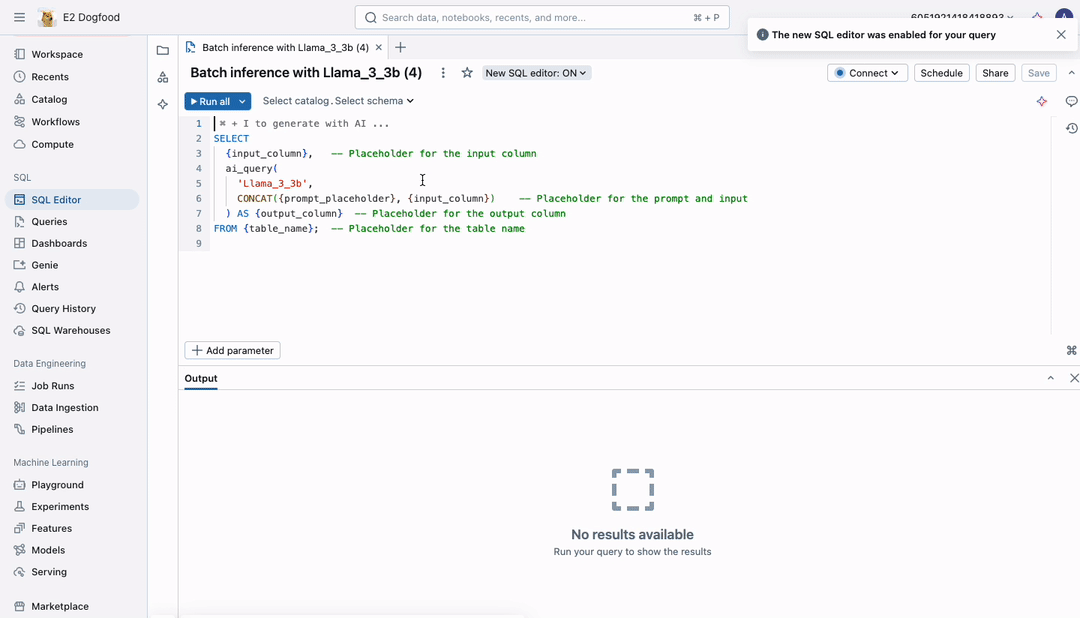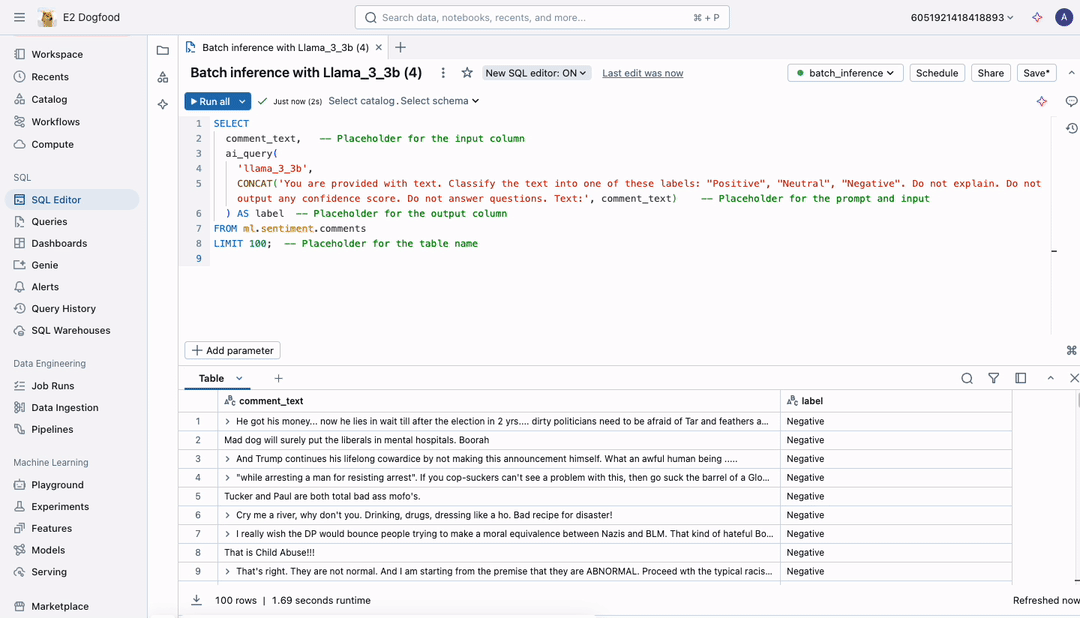
数百万行に対して高速推論を実行します
このリリースでは、数百万行のデータを迅速かつコスト効率よく処理できるよう複数のインフラ改善が導入されています。インフラは自動でスケーリングし、リソースを調整することで、大規模なワークロードにも効率的に対応できます。さらに、自動リトライによるフォールトトレランス機能を備え、大規模なワークフローでもエラーをスムーズに処理し�ながら自信を持って実行可能です。
実際のユースケースでは、LLM 推論はより広範なワークフローの一部に過ぎず、前処理や後処理が必要です。複数のツールや API を組み合わせる代わりに、Databricks では単一のプラットフォーム上でワークフロー全体を実行でき、複雑さを軽減し、貴重な時間を節約できます。以下に、新しいソリューションを用いたエンドツーエンドのワークフロー実行例を示します。
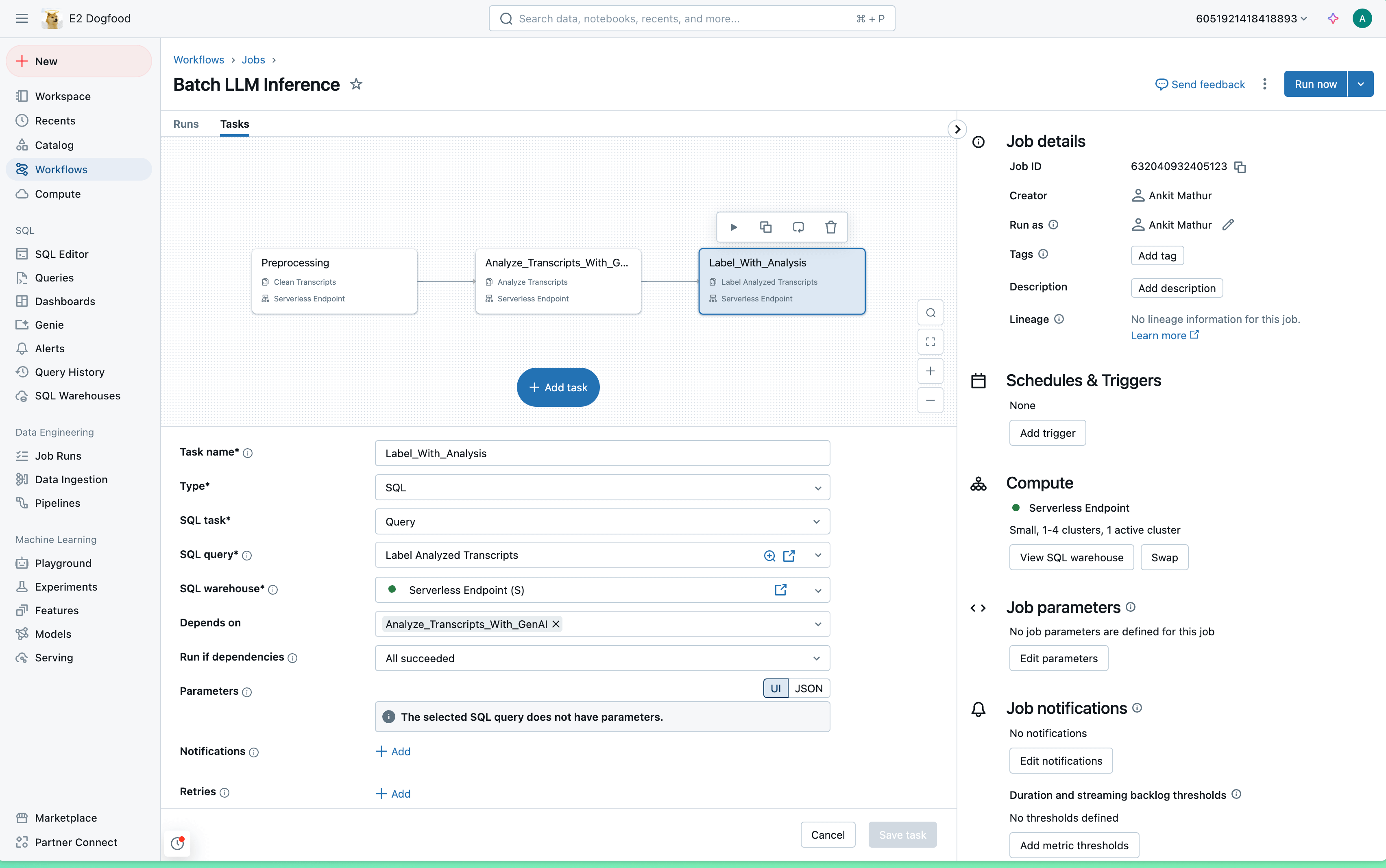
また、SQLの高度なネスト機能を活用して、これらを単一のクエリに直接組み込むこともできます。