Lakehouse AI: Generative AIアプリケーション構築のためのデータ中心アプローチ

翻訳: Masahiko Kitamura
オリジナル記事: Lakehouse AI: a data-centric approach to building Generative AI applications
ジェネレーティブAIは、あらゆるビジネスに変革をもたらすでしょう。Databricksは10年にわたりAIイノベーションのパイオニアとして、AIソリューションを提供するために何千ものお客様と積極的に協力し、月間1,100万ダウンロードを誇るMLflowのようなプロジェクトでオープンソースコミュニティと協力してきました。Lakehouse AIとそのユニークなデータ中心アプローチにより、私たちはお客様がスピード、信頼性、完全なガバナンスでAIモデルを開発・展開できるよう支援します。本日開催されたData and AI Summitでは、Lakehouse AIがお客様のジェネレーティブAI制作の旅を加速させる最高のプラットフォームとなるよう、いくつかの新機能を発表しました。これらのイノベーションには、Vector Search、Lakehouse Monitoring、LLMに最適化されたGPU搭載Model Serving、MLflow 2.5などが含まれます。
ジェネレーティブAIソリューション開発の主な課題
モデル品質の最適化: データはAIの心臓部である。不十分なデータは、バイアス、幻覚、有害な出力につながる可能性がある。ラージ・ランゲージ・モデル(LLM)は、客観的なグランド・トゥルース・ラベルを持つことがほとんどないため、効果的に評価することが難しい。このため、組織は、重要なユースケースにおいて、監視なしでモデルを信頼できるタイミングを理解するのに苦労することが多い。
企業データを使ったトレーニングのコストと複雑さ: 企業は、自社のデータを使ってモデルを訓練し、それをコントロールしたいと考えている。MPT-7BやFalcon-7Bのようなインストラクションチューニングされたモデルは、良いデータがあれば、より小さなファインチューニングされたモデルでも良いパフォーマンスが得られることを実証している。しかし、組織は、どれだけのデータ例があれば十分なのか、どのベースモデルから始めるべきか、モデルの訓練と微調整に必要なインフラの複雑さを管理し、コストについてどのように考えるべきか、苦慮している。
プロダクションにおけるモデルの信頼性: 技術的な状況が急速に進化し、新しい機能が導入される中、これらのモデルを本番稼動させることはより困難になっている。これらの機能は、ベクターデータベースのような新しいサービスに対するニーズという形でもたらされることもあれば、ディーププロンプトエンジニアリングサポートやトラッキングの�ような新しいインターフェースという形でもたらされることもあります。堅牢でスケーラブルなインフラストラクチャーと、モニタリングのために完全に計装化されたスタックなしには、本番でモデルを信頼することは難しい。
データ・セキュリティとガバナンス: 組織は、データ漏洩を防止し、対応が規制に適合していることを確認するために、サードパーティに送信され、保存されるデータを管理したいと考えている。今日、チームが無制限の慣行を行っているためにセキュリティやプライバシーが損なわれていたり、データ利用のためのプロセスが煩雑であるためにイノベーションのスピードが妨げられているケースも見受けられる。
Lakehouse AI - 生成AIに最適化されたAI
前述の課題を解決するため、当社は、組織がデータ・セキュリティとガバナンスを維持し、概念実証から本番稼動までの道のりを加速するのに役立つLakehouseのAI機能をいくつか発表できることを嬉しく思います。
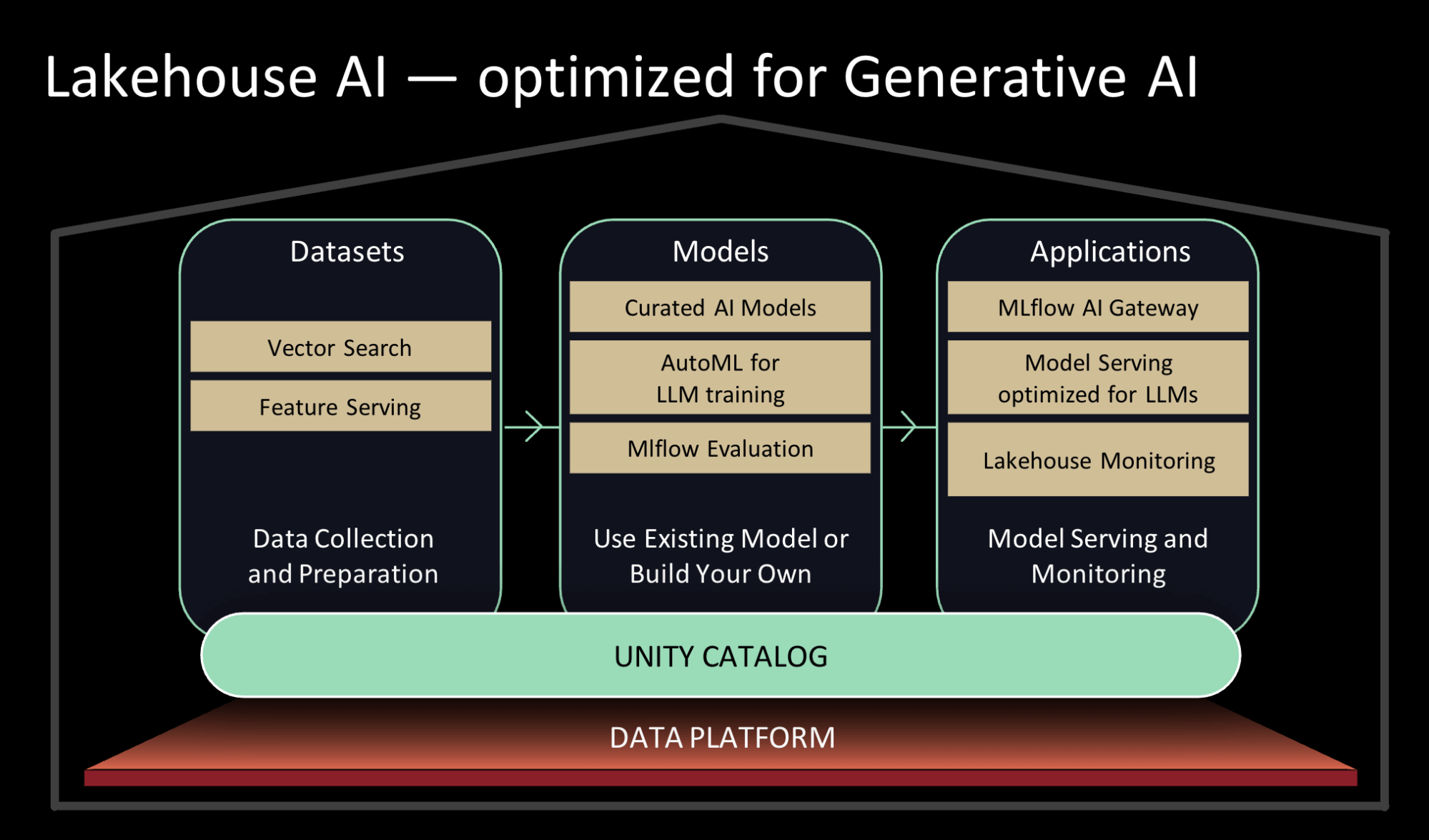
既存のモデルを使用するか、お客様のデータを使用して独自のモデルをトレーニングします。
- インデックス作成のためのベクトル検索: Vector Embeddingsを使用することで、組織は、組織の知識コーパス全体によるカスタマーサポートボットから、顧客の意図を理解する検索やレコメンデーション体験まで、多くのユースケースでGenerative AIとLLMのパワーを活用することができます。当社のベクトル・データベースは、チームが組織のデータを埋め込みベクトルとして迅速にインデックス化し、リアルタイムの展開で低レイテンシのベクトル類似性検索を実行するのに役立ちます。Vector Searchは、ガバナンスのためのUnity Catalogや、データとクエリをベクトルに変換するプロセスを自動的に管理するModel Servingなど、Lakehouseと緊密に統合されています。プレビューのお申し込みはこちら(here)から。
- 最適化されたモデルサービングに支えられたキュレートされたモデルで、高いパフォーマンスを実現します: ユースケースに最適なオープンソースのジェネレーティブAIモデルの調査に時間を費やすよりも、Databricksのエキスパートが一般的なユースケース向けにキュレートしたモデルに頼ることができます。私たちのチームは、モデルの状況を常に監視し、品質や速度など多くの要素について新しいモデルをテストしています。私たちは、Databricks Marketplaceでベストオブブリードの基礎モデルを利用できるようにし、デフォルトのUnityカタログでタスク固有のLLMを利用できるようにしています。モデルがUnityカタログに掲載されると、データを直接使用したり、微調整したりすることができます。これらのモデルごとに、Lakehouse AIのコンポーネン��トをさらに最適化します。例えば、モデル提供の待ち時間を最大10倍短縮します。
- LLMのAutoMLサポート: AutoMLの提供を拡大し、テキスト分類のための生成AIモデルの微調整や、データへの埋め込みモデルの微調整をサポートします。 AutoMLを使用することで、技術的なバックグラウンドを持たないユーザーでも、組織のデータをポイント&クリックで簡単にモデルの微調整を行うことができ、技術的なバックグラウンドを持つユーザーが同じことを行う際の効率も向上します。プレビューのお申し込みはこちら(here)から.
モデルとプロンプトのパフォーマンスを監視、評価、記録する
- レイクハウス・モニタリング: データ資産とAI資産の品質を同時に追跡できる、初の統合データ・AIモニタリングサービス。このサービスでは、資産のプロファイルとドリフトメトリクスを維持し、プロアクティブなアラートを設定し、品質ダッシュボードを自動生成して組織全体で可視化および共有し、データ品質アラートをリネージグラフ全体で関連付けることで根本原因の分析を容易にします。Unity Catalog上に構築されたLakehouse Monitoringは、データとAI資産に対する深い洞察をユーザーに提供し、高い品質、正確性、信頼性を保証します。プレビューのお申し込みはこちらから(here)。
- 推論テーブル: データ中心のパラダイムの一環として、サービングエンドポイントへの受信リクエストと送信レスポンスは、UnityカタログのDeltaテーブルに記録されます。この自動ペイロードロギングにより、チームはほぼリアルタイムでモデルの品質を監視することができます。また、このテーブルを使用して、エンベッディングやその他のLLMを微調整するために次のデータセットとして再ラベルが必要なデータポイントを簡単にソースすることができます。
- MLflow for LLMOps (MLflow2.4 and MLflow2.5): MLflow の評価 API を拡張し、LLM のパラメータとモデルを追跡することで、LLM のユースケースに最適なモデル候補をより簡単に特定できるようになりました。ユースケースに最適なプロンプト・テンプレートを特定するためのプロンプト・エンジニアリング・ツールを構築しました。評価された各プロンプトテンプレートは、MLflow によって記録され、後で検証または再利用することができます。
モデル、特徴、機能をリアルタイムで安全に提供
- GPUを搭載し、LLMに最適化されたモデル・サービング: GPUモデルサービングを提供するだけでなく、オープンソースのトップLLM向けにGPUサービングを最適化しています。当社の最適化により、クラス最高のパフォーマンスが実現し、Databricks上にデプロイされたLLMの実行速度が桁違いに速くなります。これらのパフォーマンス向上により、チームは推論時のコストを削減できるだけでなく、エンドポイントがトラフィックを処理するために迅速にスケ��ールアップ/ダウンできるようになります。プレビューのお申し込みはこちらから(here)。
「Databricks Model Servingに移行したことで、推論のレイテンシが10倍短縮され、適切で正確な予測をより迅速に顧客に提供できるようになりました。 データが存在し、モデルをトレーニングするのと同じプラットフォーム上でモデルサービングを行うことで、デプロイメントを加速し、メンテナンスを削減することができました。" - エレクトロラックス、データサイエンス責任者、ダニエル・エドスゲルド氏
- 特徴と機能の提供: 組織は、フィーチャーとファンクションの両方を提供することで、オンラインとオフラインのスキューを防ぐことができます。Feature and Function Servingは、REST APIエンドポイントの背後で低レイテンシーのオンデマンド計算を実行し、機械学習モデルを提供し、LLMアプリケーションを強化します。Databricks Model Servingと組み合わせて使用すると、入力された推論リクエストにフィーチャーが自動的に結合され、シンプルなデータパイプラインを構築できます。プレビューのお申し込みはこちらから(here).
- AI Functions: データアナリストやデータエンジニアは、インタラクティブなSQLクエリやSQL/Spark ETLパイプライン内でLLMやその他の機械学習モデルを使用できるようになりました。AI Functionsを使用すると、アナリストは、UnityカタログとAI Gatewayで権限が付与されていれば、センチメント分析やトランスクリプトの要約を実行できます。 同様に、データエンジニアは、コールセンターのすべての新規コールをトランスクライブするパイプラインを構築し、LLMを使用してさらに分析を実行し、これらのコールから重要なビジネスインサイトを抽出することができます。プレビューのサインアップはこちらから(here)
データとガバナンスの管理
- 統一されたデータとAIガバナンス: Unityカタログを強化し、単一の統一されたエクスペリエンスで、データとAIアセットの両方の包括的なガバナンスとリネージトラッキングを提供します。これは、モデルレジストリとフィーチャーストアがUnityカタログに統合され、チームがワークスペース間でアセットを共有し、AIと一緒にデータを管理できるようになったことを意味します。
- MLflow AI Gateway: OpenAIや他のLLMプロバイダーを活用する権限を従業員に与えるにつれ、企業はレート制限や認証情報の管理、急増するコスト、外部へ送信されるデータの追跡といった問題に直面しています。MLflow 2.5 の一部である MLflow AI Gateway は、ワークスペース・レベルの API ゲートウェイであり、組織がルートを作成および共有することを可能にします。
- Databricks CLI for MLOps: Databricks CLIのこの進化により、データチームはinfra-as-codeでプロジェクトをセットアップし、統合されたCI/CDツールで本番環境に迅速に移行できる。組織は、Databricks Workflowsを使用してAIのライフサイクルコンポーネントを自動化する「バンドル」を作成できます。
このジェネレーティブAIの新時代において、私たちは、私たちがリリースしたこれらすべての革新的技術に興奮しています!

