AIをよりアクセシブルに:Databricks上のMeta Llama 3.3で最大80%のコスト削減!
Mosaic AI Model ServingでのMeta Llama 3.3の利用開始を発表
Summary
- 80%のコスト削減: 新しいLlama 3.3モデルと価格の引き下げにより、大幅なコスト削減を実現します。
- 高速な推論速度: 40%高速なレスポンスとバッチ処理時間の短縮により、より良い顧客体験と迅速な洞察を実現します。* 新しいMeta Llama 3.3モデルへのアクセス: Mosaic AIは、Llamaモデルのデプロイメントと管理に最も包括的なプラットフォームです。
企業が高品質なAIアプリを提供するエージェントシステムを構築するにつれて、私たちはお客様に最高のコスト効率を提供するための最適化を続けています。Meta Llama 3.3モデルがDatabricks Data Intelligence Platformで利用可能になったことを発表することを嬉しく思います。また、Mosaic AIのModel Servingの価格と効率性に大幅な更新が加えられました。これらの更新により、推論コストが最大80%削減され、AIエージェントを構築したり、バッチLLM処理を行っている企業にとって、以前よりも大幅にコスト効率が向上します。
- コスト削減80%:新しいLlama 3.3モデルと価格の引き下げにより、大幅なコスト削減を実現します。
- 推論速度の向上:レスポンスが40%速くなり、バッチ処理時間が短縮されることで、より良い顧客体験と迅速な洞察を実現します。
- 新しいMeta Llama 3.3モデルへのアクセス: Metaの最新技術を活用して、品質とパフォーマンスを向上させます。
Mosaic AIとLlama 3.3を使用してエンタープライズAIエージェントを構築する
Metaとのパートナーシップを誇りに思います。Llama 3.3 70BをDatabricksに導入します。このモデルは、指示に従う能力、数学、多言語、コーディングタスクにおいて、大規模なLlama 3.1 405Bと競合しながら、ドメイン特化型のチャットボット、インテリジェントエージェント、大規模ドキュメント処理にコスト効率の良い解決策を提供します。
Llama 3.3は、オープンファウンデーションモデルの新たな基準を設定していますが、本番環境で使用可能なAIエージェントを構築するには、強力なモデルだけでは不十分です。Databricks Mosaic AIは、Llamaモデルをデプロイし、管理するための最も包括的なプラットフォームであり、企業データを理解することができる安全でスケーラブル、信頼性の高いAIエージェントシステムを構築するための強力なツールセットを提供します。
- 統一APIでLlamaにアクセス: OpenAIやAnthropicを含む主要な基盤モデルを、Llamaとともに単一のインターフェースから簡単にアクセスできます。最大限の柔軟性を確保するために、モデルを自由に実験、比較、切り替えることができます。
- AIゲートウェイでトラフィックを安全に監視: Mosaic AI Gatewayを使用して使用状況とリクエスト/レスポンスを監視しながら、PII検出や有害コンテンツのフィルタリングなどの安全ポリシーを強制し、安全でコンプライアンスを満たしたインタラクションを実現します。
- リアルタイムエージェントの高速構築: 高品質なリアル�タイムエージェントの作成を40%高速な推論速度、関数呼び出し機能、手動または自動のエージェント評価のサポートで実現します。
- 大規模なワークフローをバッチ処理: LLMを簡単に適用し、シンプルなSQLインターフェースを使用して、40%高速な処理速度とフォールトトレランスを持つガバナンスデータ上で直接大規模なデータセットに適用します。
- モデルをカスタマイズして高品質を得る: Llamaを微調整し、独自のデータを使用してドメイン固有の高品質なソリューションを構築します。
- 自信を持ってスケールアップ: SLAに基づくサービング、セキュアな設定、および自動的にスケールアップするエンタープライズの進化する要求に対応したコンプライアンス対応のソリューションで、デプロイメントを拡大します。
新しい価格設定でGenAIをより手頃な価格に:
我々は、推論スタック全体で独自の効率改善を展開しており、これにより価格を下げ、GenAIをより多くの人々に利用可能にすることができます。新しい価格変更の詳細を見てみましょう:
トークンごとの課金価格の削減:
- ラマ3.1 405Bモデル:入力トークン価格が50%削減、出力トークン価格が33%削減。
- Llama 3.1 70Bモデル: 入力と出力のトークンの両方で50%削減。
プロビジョニングスループットの価格削減:
- Llama 3.1 405B: 処理されるトークンあたりのコストを44%削減。
- Llama 3.3 70BとLlama 3.1 70B: 処理されたトータルトークンあたりのドルで49%削減。
展開総コストを80%削減
より効率的で高品質なLlama 3.3 70Bモデルと価格の引き下げを組み合わせることで、総TCOを最大80%削減することが可能になりました。
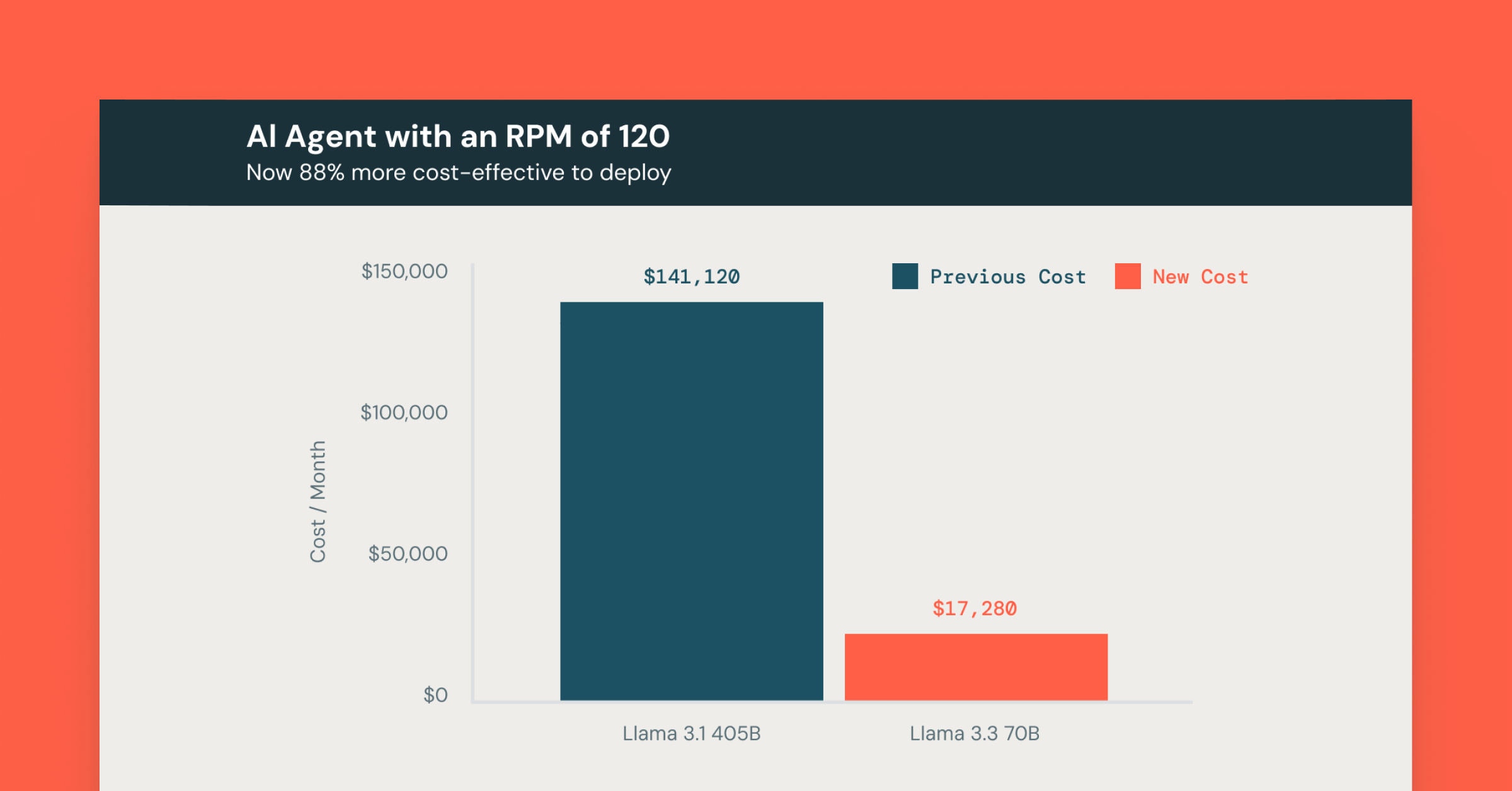
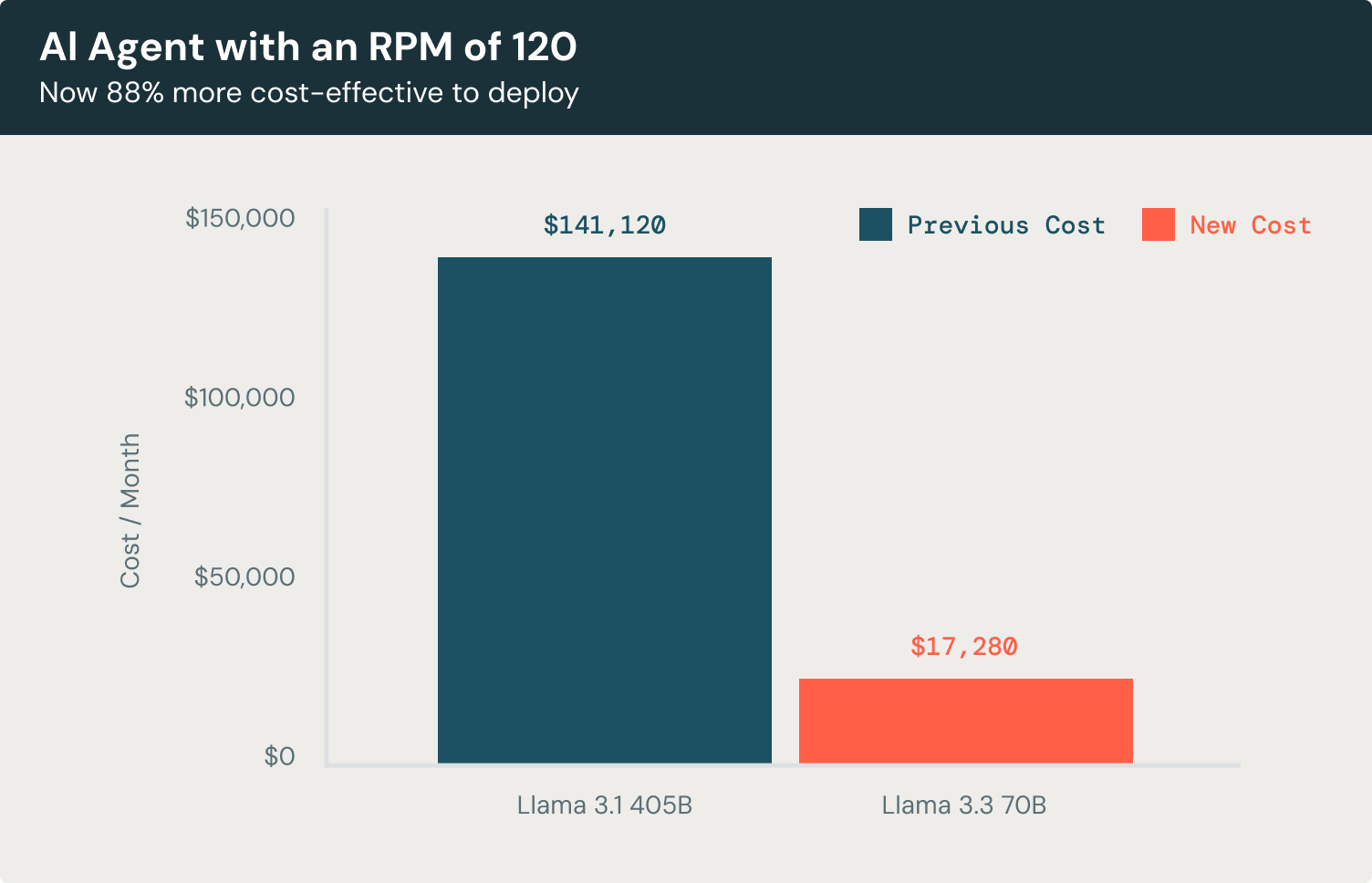
具体的な例を見てみましょう。例えば、1分間に120リクエスト(RPM)を処理するカスタマーサービスのチャットボットエージェントを構築しているとします。このチャットボットは、平均で3,500の入力トークンを処理し、1回のインタラクションごとに300の出力トークンを生成し、ユーザーに対して文脈に富んだ応答を作成します。
Llama 3.3 70Bを使用すると、このチャットボットの運用コストは、LLMの使用に焦点を当てた場合、Llama 3.1 405Bと比較して88%低く、主要なプロプライエタリモデルと比較して72%コスト効率が良いとなります。
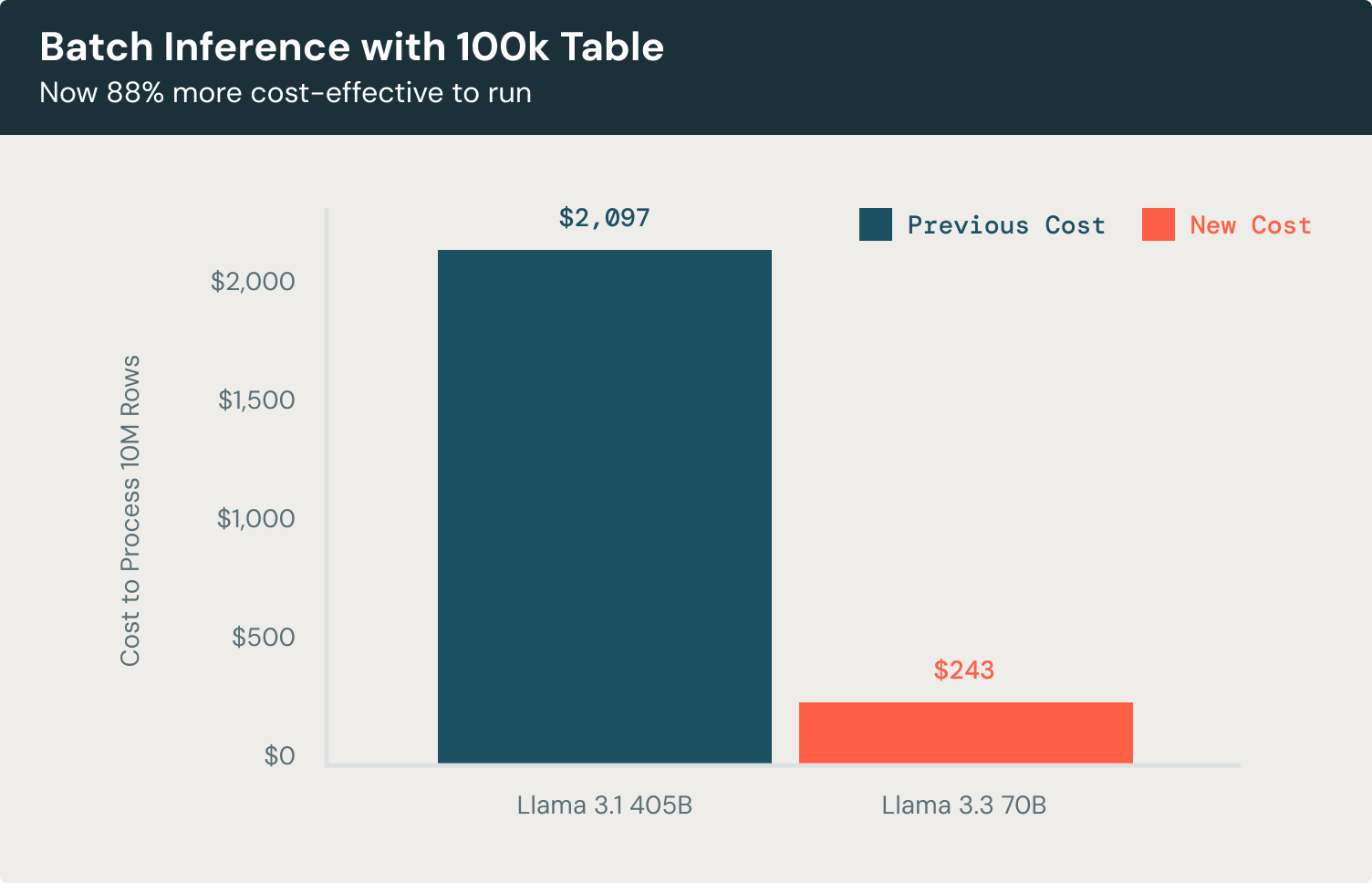
さて、バッチ推論の例を見てみましょう。100Kレコードのデータセットでのドキュメント分類やエンティティ抽出のようなタスクでは、Llama 3.3 70Bモデルは、Llama 3.1 405Bに比べて驚くほど効率的です。3500の入力トークンと300の出力トークンを持つ行を処理しながら、モデルは同じ高品質の結果を達成し、コストを88%削減し、それは主要なプロプライエタリモデルを使用するよりも58%コスト効率が良いことを意味します。これにより、過度な運用費用をかけずに、ドキュメントを分類し、キーエンティティを抽出し、スケールで行動可能な洞察を生成することが可能になります。
無料トライアル
こちらをAIプレイグラウンド訪れて、ワークスペースから直接ラマ3.3を試してみてください。詳細については、以下のリソースを参照してください:
- モデルサービングの詳細は、こちらを参照してください。
- 大量のデータに対してLLMを適用するバッチLLM推論
- エージェンティックとRAGアプリを製品品質で構築する エージェントフレームワークと評価
- Mosaic AI Foundation Model Servingをご覧ください価格

