複雑な傾向スコアリング・シナリオをDatabricksで管理する

詳細とノートブックのダウンロードについては、Solution Accelerator for Propensity Scoringをご覧ください。
翻訳:Junichi Maruyama. - Original Blog Link
消費者は、パーソナライズされた方法でのエンゲージメントをますます期待するようになっています。最近の購入を補完する製品を宣伝する電子メールメッセージであれ、よく閲覧するカテゴリの製品のセールを告知するオンラインバナー広告であれ、または表明された (または暗示された) 興味に沿った動画や記事であれ、消費者は個人のニーズや価値観を認識するメッセージングを好むことを実証しています。
ターゲットを絞ったコンテンツ�でこのような嗜好に応えることができる組織は、消費者とのエンゲージメントからより高い収益を生み出す機会がある一方、そうでない組織は、ますます混雑し、分析が高度化する小売業界において顧客離れのリスクを負うことになります。その結果、多くの企業は、他の分野への支出を減速させている経済の不確実性にもかかわらず、パーソナライゼーションに大規模な投資を行っています。
しかし、何から始めればよいのでしょうか?組織が様々なタッチポイントから顧客データを収集し、調和させるプロセスを確立したら、マーケティング担当者はこのデータをどのように活用し、より良いコンテンツを提供できるだろうか。
傾向スコアリングは、ターゲットを絞ったマーケティングキャンペーンを構築するための最も広く採用されているアプローチの1つです。基本的なテクニックは、顧客が指定された期間内に、より大きな商品グループの中から商品を購入するかどうかを予測するために、単純な機械学習モデルをトレーニングすることを伴います。マーケティング担当者は、推定された購入確率を使用して、製品に沿ったキャンペーンで誰をターゲットにするかだけでなく、望ましい結果を促進するために採用するメッセージやオファーを決定す�ることができます。
多数の重複するモデルの管理は複雑さを生む
ほとんどの組織が直面する課題は、特定の傾向モデルを開発することではなく、関与している様々なマーケティングキャンペーンをカバーするために必要な数十、いや数百のモデルをサポートすることです。例えば、ある企業が真夏の焼き肉パーティに関連する食料品に焦点を当てたキャンペーンを実施するつもりだとしよう。プロモーションチームは、ホットドッグ、ポテトチップス、ソーダ、ビールなどの厳選されたブランドで構成される商品グループを定義し、マーケティングチームはその特定のグループのモデルを作成する必要があります。このキャンペーンは、他のいくつかのキャンペーンと同時進行する可能性があり、それぞれのキャンペーンには、独自の、場合によっては重複する商品グループと関連モデルが存在します。企業は最終的に、多数のモデルとワークフローを同時に管理する必要に迫られ、運用の複雑さが急速に増していきます。
外から見ると、この作業はすべて、かなり単純なテーブル構造に反映されています。このテーブルでは、各顧客に対して製品グループ単位で傾向スコアが付与されます(図1)。これらのスコアを使用して、マーケティングチームは特定のキャンペーンやコンテンツに関連付けるオーディエンス/セグメントを定義します。

しかし、これらのスコアが正確で最新のものであることを保証する責任を負うデータサイエンティストやデータエンジニアにとって、この情報を組み立てるには、3つの別々の作業を思慮深く調整する必要がある。
この複雑さは、次の3つの課題によって解決できる
これらのタスクの最初のものは、特徴インプットの導出である。これらの中には、時間の経過とともに徐々に変化するユーザや製品グループに関連する単純な属性もありますが、大部分は一般的にトランザクション履歴から導出されるメトリクスです。新しいトランザクションが発生するたびに、以前に導出されたメトリクスは古くなり、データエンジニアは、これらのメトリクスを再計算するコストと、これらの値の変化が予測精度に与える影響のバランスを取ることがしばしば課題となります。
この最初のタスクと密接に結びついているのが、傾向の再推定タスクです。特徴量を再計算すると、それらが既存モデルに入力され、新しいスコアが生成されます。(このスコアはプロファイルテーブルに記録されます)。ここでの課題は、すべての異なる世帯とアクティブなモデルのスコアを生成するだけでなく、数千とは言わないまでも数百の特�徴入力のうちどれが与えられたモデルによって採用されているかを追跡し続けることである。
最後に、データ・サイエンティストは、顧客の行動が時間とともにどのように変化するかを考慮し、各モデルを定期的に再学習させ、過去データから新たな洞察を学習させ、将来にわたって正確な予測を生成できるようにしなければならない。
Databricksがこれらのタスクの調整を支援
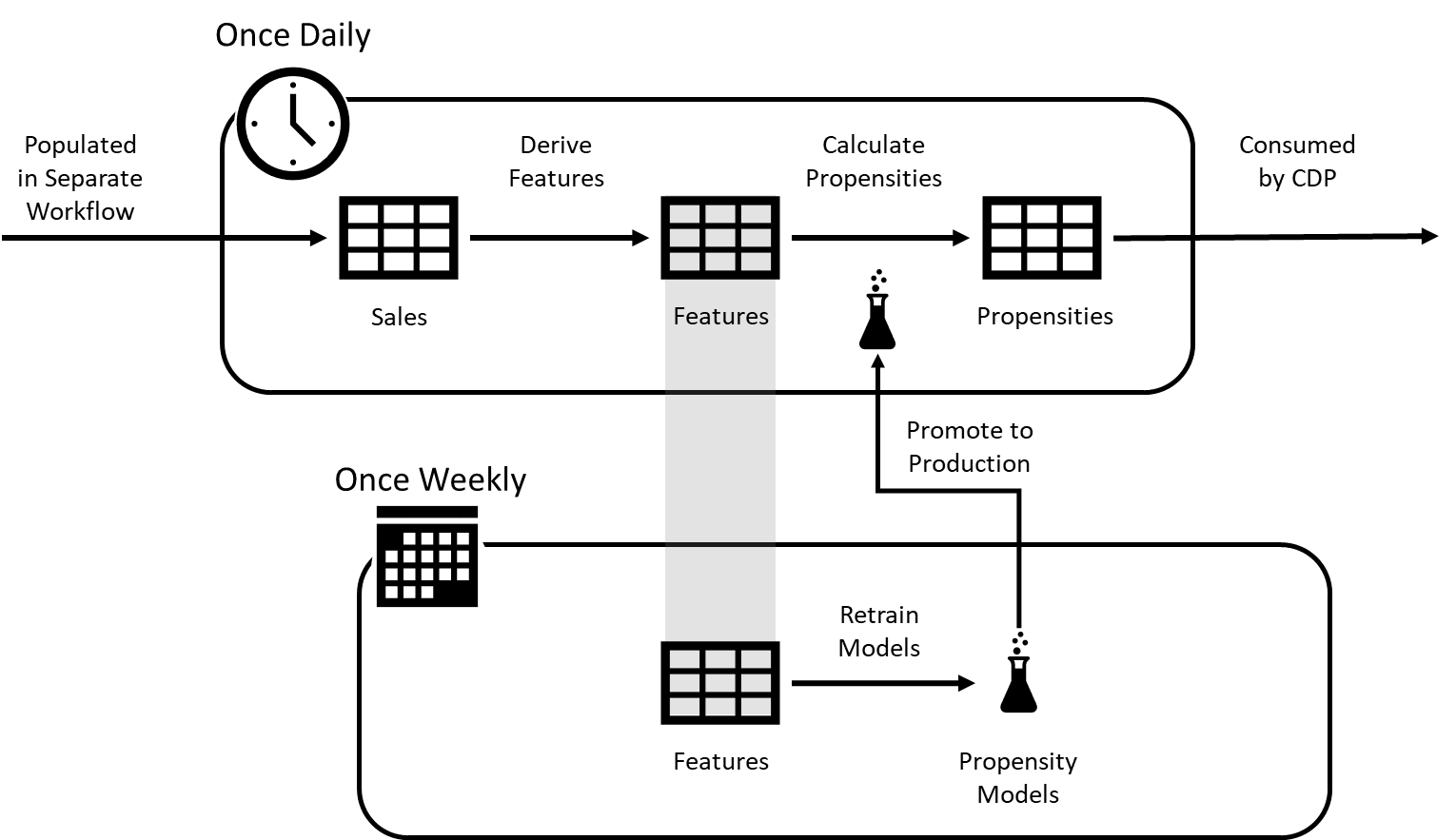
しかし、このプロセスを管理するデータサイエンティストやエンジニアは、これらのタスクを2つの一般的なワークフローの一部として管理し、これらのプロセスを支援することを目的としたDatabricksプラットフォームの主要機能を利用することで、物事を大幅に簡素化することができます(図2)
最初のワークフロー(多くの場合、毎日スケジュールされる)では、バックオフィスチームはフィーチャーとスコアの再計算に集中する。どのフィーチャーを再計算する必要があるかを制御するために、アクティブな商品グルーピングに関する情報が取得され、これらの値がDatabricks feature storeに記録されます。
フィーチャーストアはDatabricksプラットフォーム内の特別な機能で、モデル推論時に最小限の入力で、以前に学習したモデルが依存するフィーチャーを取り出すことができます。傾向スコアリングの場合、スコアリングしたい顧客と商品グループの識別子を提供するだけで、モデルはフィーチャーストアを活用して予測を返すために必要な特定の値を取得します。
ワークフローの 2 番目(多くの場合、週またはそれ以上の頻度でスケジュールされる)では、デー タサイエンスチームが各モデルを定期的に再トレーニングするようスケジュールする。新しくトレーニングされたモデルは、事前に統合された MLflow レジストリに登録されるため、Databricks 環境は各モデルの複数のバージョンを追跡することができます。これにより、Databricks 環境は各モデルの複数のバージョンを追跡することができます。内部プロセスにより、学習済みモデルは十分に検証されるまで本番ワークフローに組み込まれず、安全に評価できます。このステータスが割り当てられると、最初のワークフローはそのモデルを現在アクティブなモデルとして認識し、次のサイクルでモデルのスコアリングに使用する。
各ワークフローは他のワークフローに依存するが、それぞれ異なる頻度で動作する。特徴生成とスコアリングのワークフローは、組織のニーズにもよりますが、通常毎日、場合によっては毎週発生します。モデルの再トレーニングのワークフローは、週単位、月単位、あるいは四半期単位と、発生頻度ははるかに低い。この2つを調整するために、組織は組み込みのDatabricks Workflows機能を活用することができます。
Databricks ワークフローは、単純なプロセススケ�ジューリングの域をはるかに超えています。ワークフローを構成する様々なタスクだけでなく、それらの実行に必要な特定のリソースを定義することができます。モニタリングとアラート機能により、これらのプロセスをバックグラウンドで管理することができ、状態管理機能により、トラブルシューティングだけでなく、失敗したジョブの再開を支援します。
傾向スコアリングを密接に関連する2つの作業の流れとして捉え、Databricksのフィーチャーストア、ワークフロー、および統合されたMLflowモデルレジストリを活用することで、この作業に伴う複雑さを大幅に軽減することができます。これらのワークフローを実際にご覧になりたいですか?Solution Accelerators for Propensity Scoringでは、これらのコンセプトと機能を実際のデータセットに対して実践しています。複数の傾向スコアリングモデルの開発に使用するために、設定可能な製品セットをどのようにリストアップできるか、また、それらのモデルを使用して、さまざまなマーケティングプラットフォームからアクセス可能な最新のスコアをどのように生成できるかを示しています。このリソースが、小売企業が傾向スコアリングの持続可能なプロセスを定義し、初期のパーソナライゼーションの取り組みを促進する一助となることを願っています。


{kind=link}
{kind=link}