
私たちは最近、DBRXという最新の汎用LLM(大規模言語モデル)を発表しました。DBRXは、Mosaic AI Trainingを使用してトレーニング、ファインチューニング、および評価されました。トレーニングは3072台のNVIDIA H100を使用してスケーリングされ、処理したトークン数は12兆を超えました。
LLMのトレーニング、特にDBRXのようなMoE(専門家の集合)モデルのトレーニングは難しいです。これには、多くのインフラ、パフォーマンス、科学的な課題を克服する必要があります。Mosaic AI Trainingはこれらの課題に対応するために意図的に構築され、DBRX 、 MPTシリーズのモデル、およびOla の Krutrim 、 AI2 の OLMo 、 Dynamo AIの Dynamo 8B 、 Refuel のLLM -2など、多くのLLMのトレーニングを通じて実戦で試されてきました。
Mosaic AI Trainingは、Databricksの顧客向けに提供されており、企業のデータに基づいたカスタムモデルを構築し、特定のビジネスコンテキスト、言語、ドメインに適合させることができます。これによ��り、重要なビジネスユースケースを効率的にサポートできます。
これらのカスタムモデルは、特定のドメイン(例:法律、金融など)や、リソースの少ない言語を処理するためにトレーニングされた場合に特に有用です。顧客は、独自のビジネスユースケースに対応するために、カスタムモデルを事前トレーニングするか、オープンソースモデルを使って大規模な追加トレーニングを行うことが多く見受けられます。今後も多くの顧客が自社のLLMをトレーニングし、所有するのを支援することを楽しみにしています。
このブログ投稿では、Mosaic AI Trainingの主要な機能と、それがDBRXの成功したトレーニングにどのように貢献したかについて詳述しています。企業のデータを活用したDBRXクラスのカスタムLLMの構築を始めるには、Mosaic AIトレーニング 製品 ページをチェックするか、今すぐお問い合わせください。
「 Mosaic AIトレーニング インフラストラクチャは、OLMo やその他の真にオープンな大規模言語モデルのトレーニングに不可欠です。」 -アレン人工知能研究所主席ソフトウェアエンジニア、Dirk Groenveld 氏。
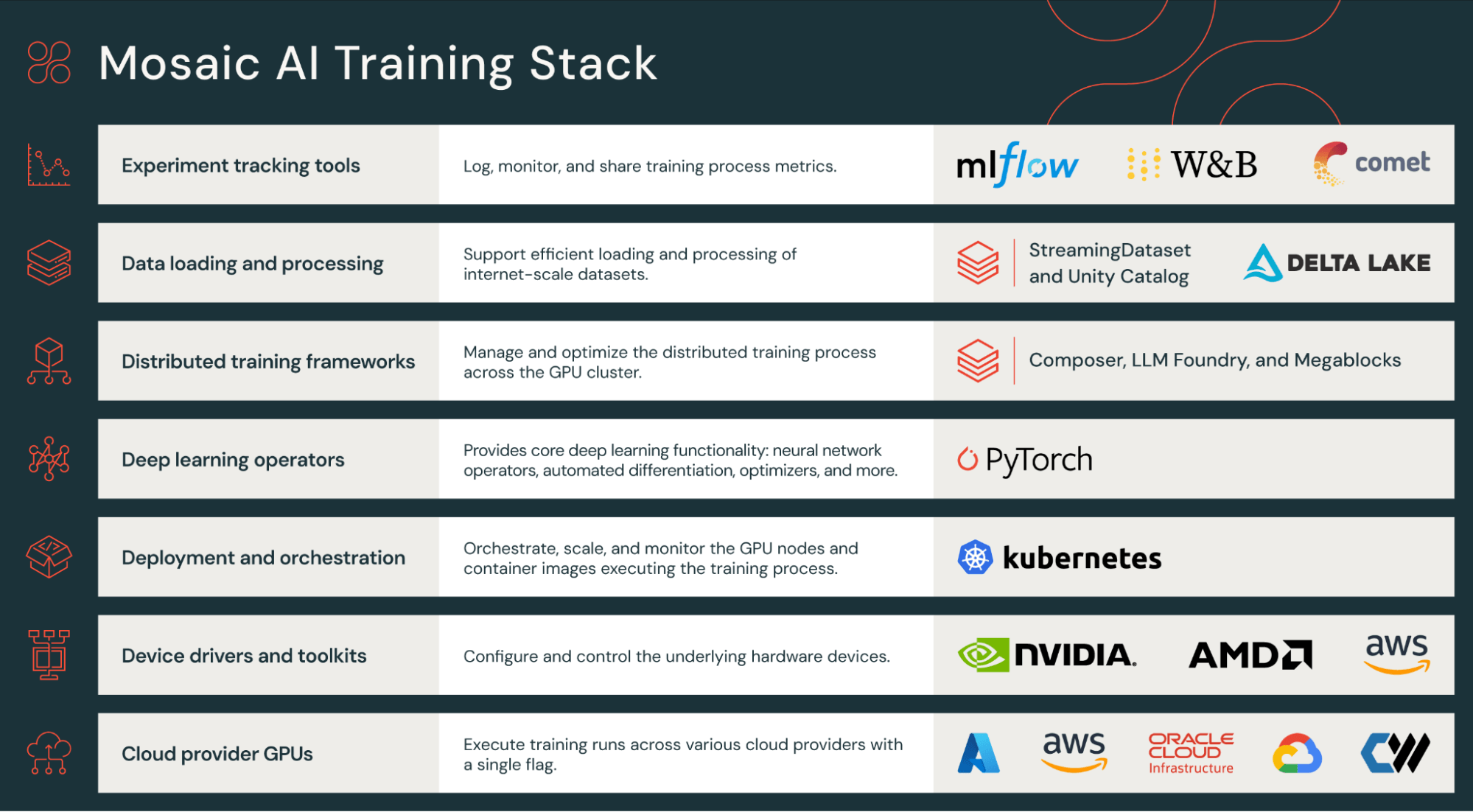
Mosaic AI Trainingスタック
LLMや他の大規模AIモデルをトレーニングするには、ハードウェアのデバイスドライバーからジョブオーケストレーション、さらにはニューラルネットワークのトレーニングループに至るまで、多くのコンポーネントの統合が必要です。このプロセスは複雑であり、幅広い専門知識が求められます。例えば、ネットワークドライバーの設定ミスのような単純な間違いでも、訓練速度が5倍遅くなることがあります。
この複雑さを簡素化し、「そのまま使える」ようにするために、Mosaic AI Trainingは大規模分散トレーニングのすべての側面を処理する最適化されたトレーニングスタックを提供しています。このスタックは、複数のGPUクラウドプロバイダー(AWS、Azure、OCI、Coreweaveなど)をサポートし、最新のGPUドライバー(NVIDIA CUDAおよびAMD ROCmを含む)で構成されています。また、PyTorch 、 MegaBlocks 、 Composer、Streamingなどのコアニューラルネットワークおよびトレーニングライブラリが含まれています。最後に、LLMのトレーニング��、ファインチューニング、および評価のための実績あるスクリプトがLLMFoundryに用意されており、顧客は自分のLLMをすぐにトレーニングし始めることができます。
「Refuel では、特定のユースケース向けに特別に構築されたカスタム LLM の価値を認識しています。新しくリリースされたモデルRefuelLLM-2は、 Mosaic AIトレーニングインフラストラクチャでトレーニングされ、非構造化データからハードウェアデバイスドライバー、トレーニングライブラリ、ジョブオーケストレーションまで、多数のコンポーネントを1つの使いやすいリソースで調整できるようになりました。 」 - ニヒト・デサイ、Refuel 共同創設者兼 CTO
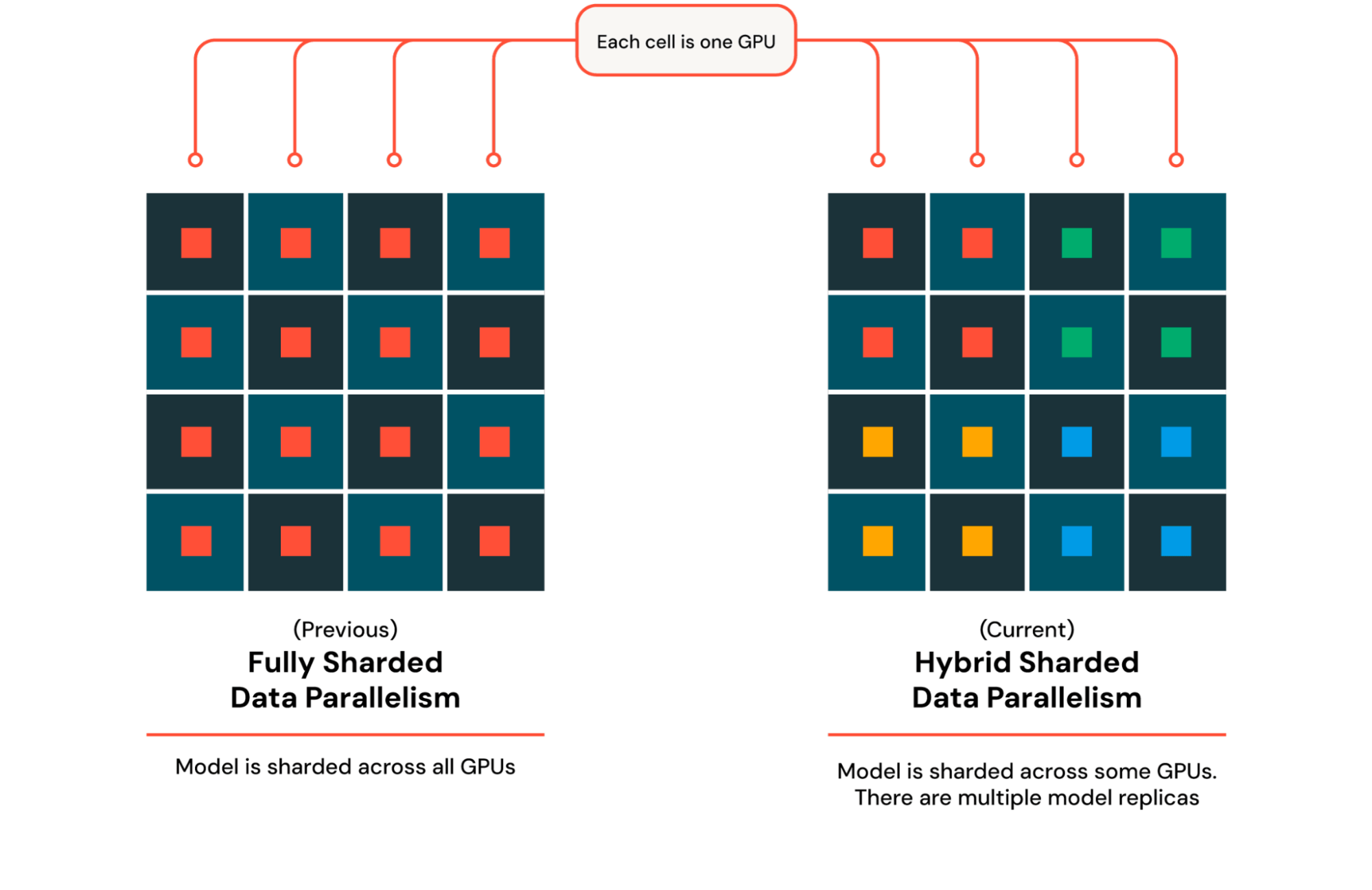
分散学習
数千の GPU でモデルをトレーニングするために、 Mosaic AIはDTensor を�活用します。これは、テンソルがどのようにシャードおよび複製されるかを記述するPyTorchのシンプルなフレームワークです。モデルを 1 つの GPU から複数の GPU に拡張する場合、多くの場合、モデルとオプティマイザーを異なる GPU 間で複製することに依存する Distributed Data Parallel (DDP) を活用します。DBRX の場合のように、単一の GPU のメモリに収まらないモデルをトレーニングする場合は、代わりに Fully Sharded Data Parallel (FSDP) を使用します。この場合、モデルとオプティマイザーは複数の GPU 間でシャードされ、行列乗算などの操作のために収集されます。複数の GPU 間での収集とシャーディングを伴う各操作は、マシンの数が増えるにつれて遅くなるため、Hybrid Sharded Data Parallel (HSDP) を使用します。これは、モデルとオプティマイザーを固定のレプリカ サイズ間でシャードし、このレプリカを複数回コピーしてクラスター全体を埋めます (図 3)。 DTensor を使用すると、テンソルがどのように分割および複製されるかを記述するデバイス メッシュを構築し、それをPyTorchのFSDP実装に渡すことができます。DBRX などの MoE モデルの場合、異なるエキスパートを異なる GPU に配置するエキスパート並列処理を含めるように並列処理を改善しています。パフォーマンスを向上させ�るために、エキスパート並列処理の効率的な実装であるMegaBlocksを活用しています。さらに、長いコンテキストをサポートするためにシーケンス長並列処理を適用し、検索拡張生成 (RAG) などの主要なユース ケースのサポートを大幅に改善しています。これらすべてのテクノロジを、並列処理を内部で処理するオープンソース ライブラリであるComposerに統合し、ユーザーがモデルとデータに集中できるようにシンプルでクリーンなインターフェイスを提供しています。
効率的な並列処理設定が与えられた場合、オープンソースのストリーミングライブラリを利用して、トレーニング中にデータをオンザフライで取得します。ストリーミングは、1 分未満の起動オーバーヘッドとトレーニング オーバーヘッドなしで、数千台のマシン間で確定的なシャッフルを保証します。ハードウェア障害が発生した場合、ストリーミングは中断したところから確定的に瞬時に再開できます。この確定性は、ハードウェアの問題や再起動に関係なく、再現可能な結果を保証するために重要です。データ シャッフル以外にも、最新の LLM トレーニングでは、カリキュラム トレーニングと呼ばれるプロセスで複数の段階のトレーニングが行われることが多く、トレーニングの終わりに向けて重要な高品質のデータがアップサンプリングされます。いくつかのパラメーターをオーバーライドするだけで、ストリーミングはこれらのような高度な機能をネイティブにサポートし、後でトレーニングでデータセットの混合を自動的に更新します。
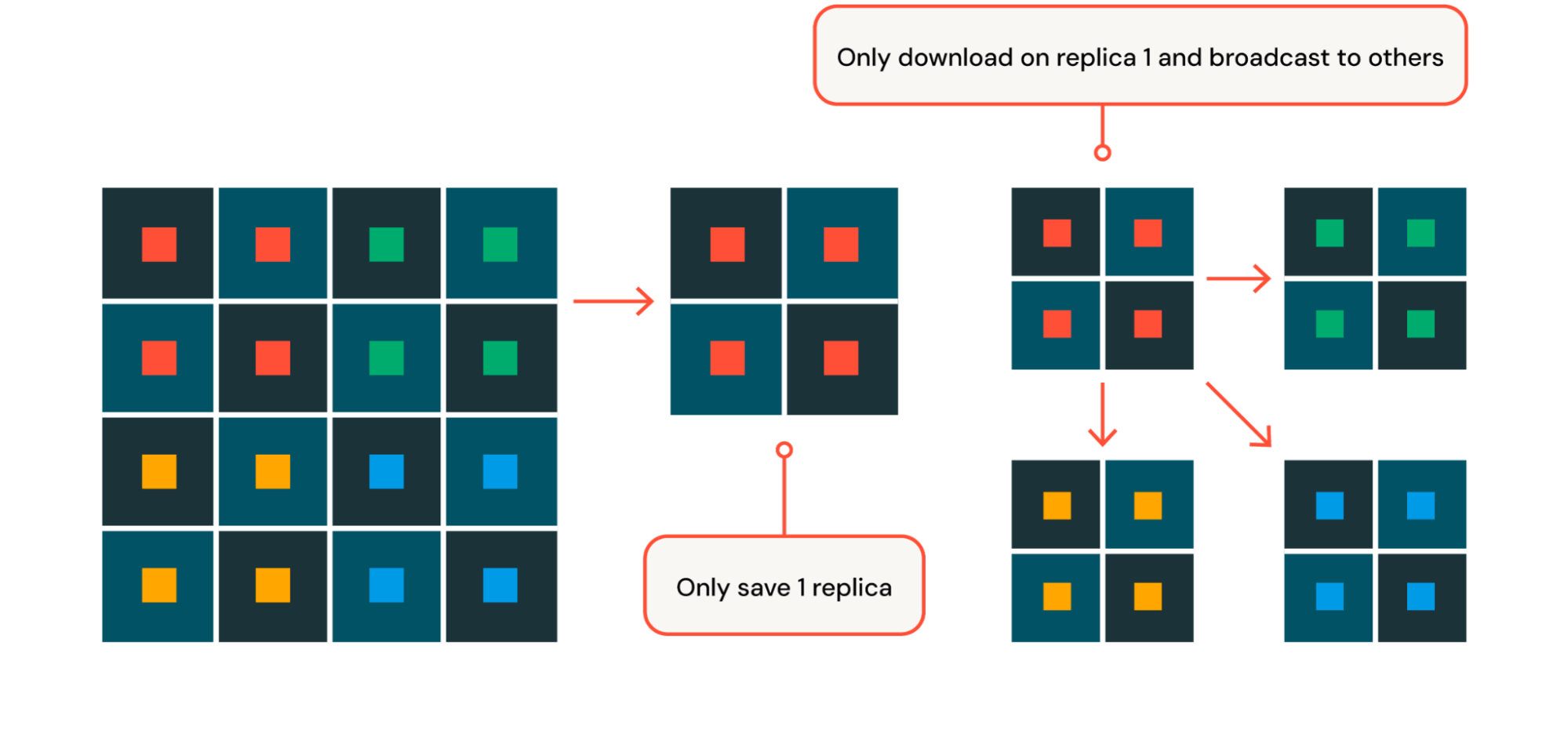
分散チェックポイント処理
ハードウェア障害からの迅速な回復を確実にするために (ハードウェア障害についてはこのブログ記事の後半で詳しく説明します)、 Mosaic AIトレーニングでは、高度に最適化されたチェックポイントの保存と読み込みを実装しています。 事前トレーニング時には、各 GPU がモデル ボディとオプティマイザーの状態のシャード部分のみを保存または読み込むシャー��ド チェックポイントを活用します。 保存と読み込みの作業を数百台のマシンに分散することで、DBRX のように数千億のサンプルと数テラバイトのチェックポイントを持つモデルをトレーニングする場合でも、保存と読み込み中のブロック時間を 30 秒未満に最小限に抑えます。 HSDPでは、最初のレプリカ内でチェックポイントを保存してロードし、必要に応じて他のすべてのレプリカにブロードキャストすることで、このプロセスをさらに最適化します(図4)。
トレーニングパフォーマンスの最適化
LLMトレーニング中に可能な限り最高のパフォーマンスを達成することは、トレーニング時間とコストの両方を最小限に抑えるために非常に重要です。特にLLMのトレーニングスケールが非常に大きく、数千台の高価なハイエンドGPUを使用する場合です。例えば、DBRXの訓練では、3072台のH100 GPUを使用して3ヶ月にわたって行われました。Mosaic AI トレーニングは、メモリ使用量と計算を積極的に最適化することで、このような最先端(SOTA)のトレーニング効率を実現しています。
トレーニング LLM のメモリ使用量には、モデル パラメーター、オプティマイザーの状態、勾配、およびアクティベーションが含まれます。 これらは実行可能なトレーニング バッチ サイズを制限し、モデルが拡張されるにつれて重大なパフォーマンスのボトルネックになる可能性があります。 バッチ サイズが大きいほど行列乗算が大きくなり、GPU 使用率が高くなることに注意してください。 モデルの引数、オプティマイザーの状態、および勾配に対処するために、前述のようにPyTorch FSDP と HSDP を活用します。 活性化メモリに対処するために、選択的活性化チェックポイントと圧縮を組み合わせて使用します。 アクティベーションチェックポイントは、これらの中間テンソルの一部を保存する代わりに再計算し、追加の計算を犠牲にしてメモリを節約します。 この追加メモリにより、DBRX トレーニングでより大きなバッチ サイズが可能になります。 アクティベーションチェックポイントを効率的に適用するために、設定可能な方法でアクティベーションのチェックポイントをサポートしており、モデルの粒度(フルブロック、アテンションなど)と範囲(例:first-nレイヤー、range(m、k)レイヤー)を簡単に指定できます。 アクティベーションチェックポイントに加えて、アクティベーションを圧縮するためのカスタムの低レベルカーネルを開発しました。 すべてのアクティベーションを 16 ビット精度で保存する代わりに、これらのアクティベーションをカスタムの低精度形式に圧縮することで、モデル品質への影響を最小限に抑えながら、アクティベーション メモリを大幅に削減します。 これらのメモリ最適化により、DBRX などの大規模モデルのメモリ使用量が約 3 倍削減されます。
Mosaic AIトレーニングは計算も最適化し、GPUが可能な限り最大FLOPSで実行されるようにします。まず、 CUDA PyTorchとカスタムベンチマークを使用して、モデルの詳細なイベントプロファイル(CPU、CUDAカーネル、NCCLなど)を生成します。これらの結果はさらなる改善の大きな動機となり、常に最も重要なボトルネックをターゲットにすることができます。たとえば、 FlashAttention 2 、MegaBlocks、その他のカスタムカーネルの高性能オペレーターを活用して、DBRXの主要レイヤーのCPUとメモリのボトルネックを回避します。高速でドロップレスなMoEを有効にするために、GPUとCPUのイベントを並べ替えて、 CUDAカーネルがデバイスの同期によってブロックされないようにし、CPUのボトルネックをさらに回避します。通信のボトルネックを回避するために、GPUあたりのフロップを最大化するその他の最適化を採用しています。まとめると、この作業により、さまざまなスケールで標準的なトランスフォーマーとほぼ同じ速度で高度なMoEアーキテクチャをトレーニングできるようになります。
GPU フォールト トレランス
LLM のトレーニングには、数百の��ノードにわたる数千の GPU のオーケストレーションが含まれ、インフラストラクチャのスケーリングと信頼性の課題が生じます。 この規模では、ノードの障害が非常に一般的です。 私たちの成功を可能にしたMosaic AIトレーニングの主要な機能について説明します。
デバイスレベルの問題を迅速に検出して修正するために、Mosaic AI トレーニングには、 ECC修正不可能なエラーや再マッピングエラー、GPUの切断、GPU ROM障害などの 一般的なGPUエラー( XID エラー)を検出する NVIDIAのPrometheusメトリックスエクスポーター( DCGMエクスポーター ) を活用した堅牢なGPUアラートセットが付属して います。GPUスロットリングを監視して、GPUから報告される熱違反や電力違反などの追加のGPUパフォーマンス問題を特定するように、DCGMオペレーター構成を拡張しています。
Mosaic AIトレーニングでは、トレーニング中にモデル FLOP 使用率 (MFU) が事前設定されたしきい値を下回った場合など、特定の構成可能な条件が満たされた場合に、より小さな診断ワークロードで自動クラスター スイープもトリガーします。診断テストが失敗すると、Mosaic AI トレーニング は滞留しているノードを遮断し、 Composer の 自動再開 機能と分散チェックポイント を使用して、最新のチェックポイントから 実行を自動的に再開します 。
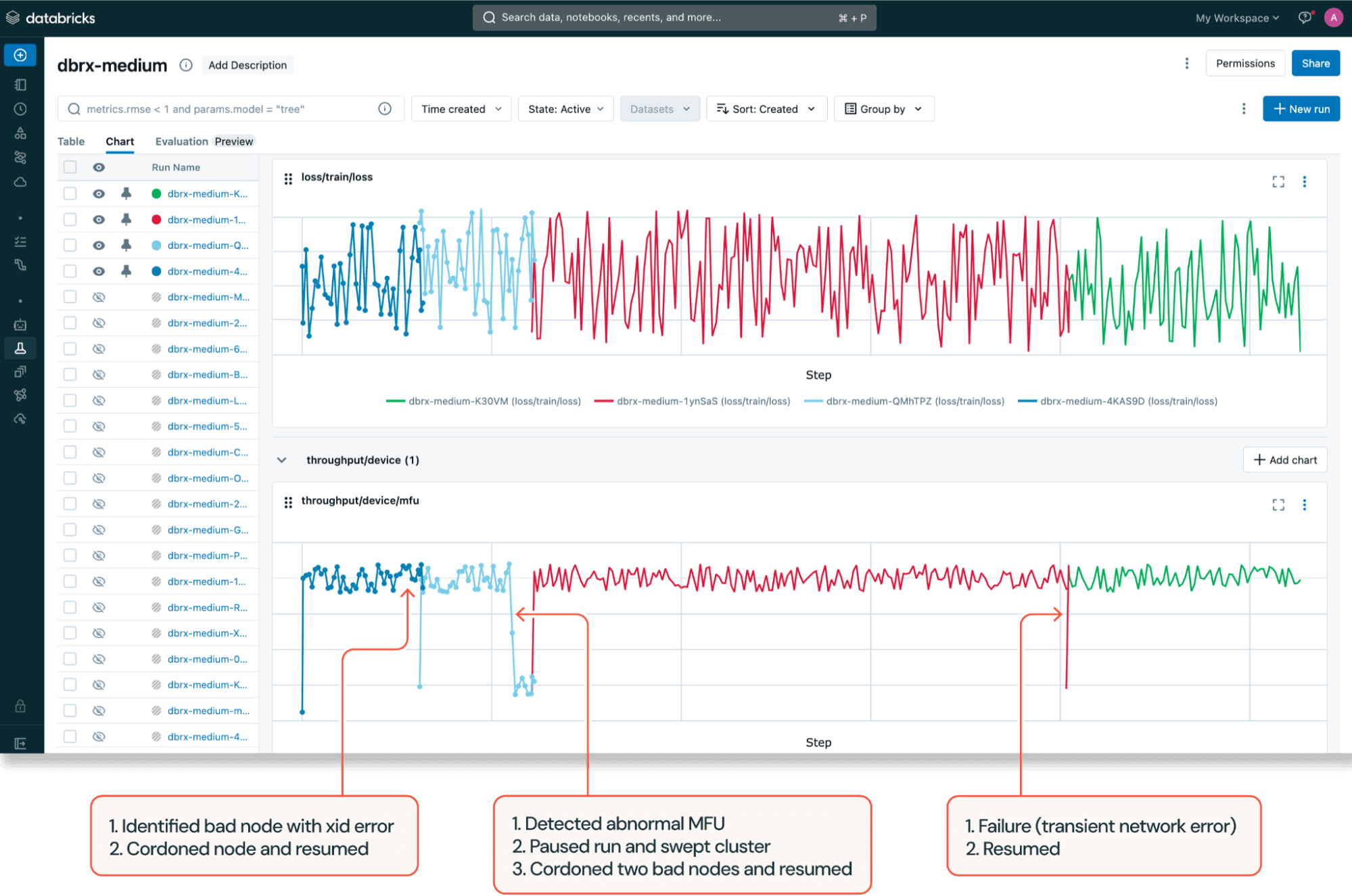
これらのフォールト トレランス機能を組み合わせることで、DBRX トレーニングに非常に役立ちました。GPU 容量が限られているため、使用可能なノード数がわずかに減少しただけでも、スケジュール グッドプット (トレーニングジョブの実行に必要なすべてのリソースが使用可能な時間の割合を表すGoogle の造語) に大きな影響が及ぶ可能性があります。弊社のアラートおよび修復システムは、さまざまな GPU エラーを識別し、実行がスケジュールされる前に不良ノードをリサイクルすることで、高いスケジュール グッドプットを確保しました。
ネットワークファブリックのフォールトトレランス
Mosaic AI トレーニングは、スイッチ ポート障害やスイッチ全体の障害など、GPUDirect リモート ダイレクト メモリ アクセス (GDRDMA) ファブリック内の特定の問題を正確に特定する機能を提供します。
これらのメトリックを収集するために、 Mosaic AIトレーニングは、一連の高速実行ブロッキング ヘルス チェックを定期的にスケジュールします。これらは、コンピュートと通信の両方のベンチマークを収集するためにノードのセットをストレス テストするカナリア デプロイメントです。コンピュート テストには、GPU が最大限に活用されたワー��クロードで最適に実行されるかどうかを確認するためのマルチ GPU CUDAストレス テストが含まれています。通信テストには、NVIDIA nccl-test方法論を使用した隣接ノード間の all-reduce NCCL テストが含まれます。次に、 Mosaic AIトレーニングは、さまざまな NCCL ペイロード サイズに対するこれらのテストからのメトリックを消費し、異常または障害のあるクラスター ノードを遮断します。
DBRX をトレーニングする際、これらのネットワーク ファブリック チェックにより、3 か月のトレーニング期間中に発生した複数のスイッチの問題が特定されました。 これにより、スイッチが停止している間に、より小さなノードのパーティションで実行を再開できるようになりました。
図 6 は、ネットワーク ファブリック チェックがどのように調整されたかの大まかな概要を示しています。
- Mosaic AI ヘルス チェック API は、チェックの準備が整ったターゲット ノードを追跡して待機します。
- APIが分散トレーニングを生み出す NCCL を�実行するプロセスはすべてテストを削減します。
- 集団通信とコンピュートメトリックスを使用したヘルスチェックAPIへの RPC コールバック。
- ヘルス チェックAPI異常なメトリックを持つノードを遮断します。
実験の追跡
アラートと GPU ヘルスのモニタリングに加えて、 Mosaic AIトレーニングはMLflowやその他のエクスペリメント トラッカーと統合して、トレーニング メトリクス、トレーニングの進行状況、システム メトリクス、評価結果のリアルタイム トラッキングを提供します。これらを使用して、初期の実験、ヘルス チェック、最終的な大規模なトレーニング実行など、DBRX トレーニングのすべてのフェーズで進行状況を監視しました (図 5 を参照)。
DBRX トレーニングの進行状況と最終的なモデルの品質を概算するために、モデルがトレーニングされた 12 兆トークン全体にわたって、 Mosaic Evaluation Gauntletを使用してトレーニングされた 1 兆トークンごとに評価タスクの完全なスイープを実行します。中間チェックポイントと微調整されたチェックポイントをMLflow Model Registryに保存することで、 Databricksモデル サービングを使用して、モデルの複数のバージョンを簡単に管理し、評価およびデプロイできるようになりました。
「 Databricks Mosaic AIエンタープライズコンプライアンスと顧客のための責任あるAIに重点を置いた、業界をリードする基盤モデルである Dynamo8B をトレーニングできるようになりました。」構成されたコンテナイメージとすぐに使える トレーニング スクリプトにより、開発時間を数週間節約できました。また、 Mosaic AIトレーニング の ��組み込み のスピードアップとオンデマンドのGPU可用性により、8台のマシンを事前トレーニングするのにわずか10日しかかかりませんでした。 -billion のメンバー multilingual LLM ." - Eric Lin、Dynamo AI応用AI部門長
独自のカスタムLLMのトレーニングを開始する
エンタープライズ データを活用する独自の DBRX グレードのカスタムLLMの構築を開始するには、 Mosaic AIトレーニングの製品ページをご覧いただくか、詳細についてはお問い合わせください。