オフラインLLM評価:Databricks上での段階的なGenAIアプリケーション評価

背景
RAG(Retrieval-Augmented Generation)がAIを駆使したアプリケーションとの関わり方に革命をもたらす時代において、これらのシステムの効率性と有効性を確保することは、かつてないほど不可欠なことである。DatabricksとMLflowはこの革新の最前線にあり、GenAIアプリケーションの重要な評価のための合理化されたソリューションを提供している。
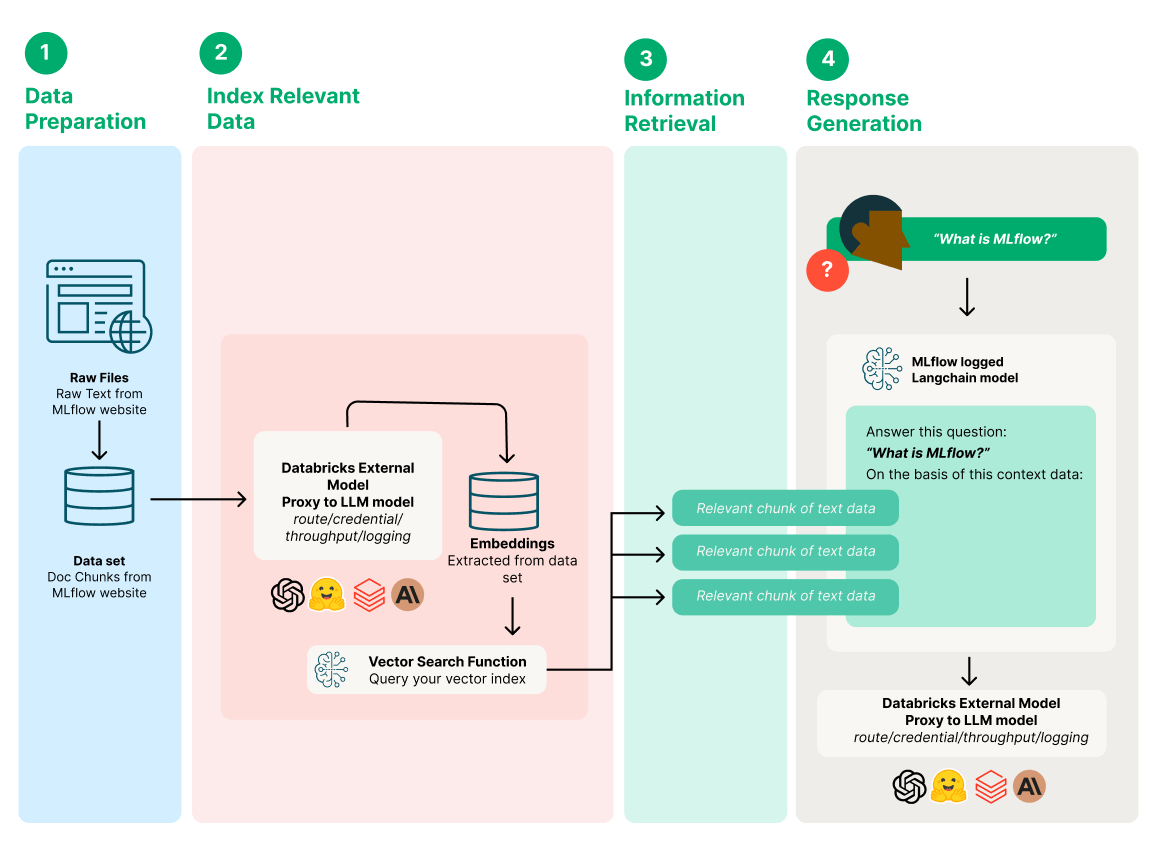
このブログポストでは、Databricks Data Intelligence Platformを活用いて、GenAIアプリケーションの3つのコアコンポーネント(プロンプト、検索システム、Foundation LLM)の品質を強化および評価し、GenAIアプリケーションの継続的な品質を確保するためのするためにシンプルで効果的なプロセスを紹介する。
ユースケース
MLflowのドキュメントの質問に回答し、その結果を評価するQAチャットボットを作成する。
Databricksで外部モデルを設定する
Databricksのモデルサービング機能は、Azure OpenAI GPT、Anthropic Claude、AWS Bedrockなど、様々な大規模言語モデル(LLM)プロバイダからの外部モデルを組織内で管理、統制、アクセスするために使用できる。特定のLLM関連リクエストを処理する統一的なエンドポイントを提供することで、これらのサービスとのやりとりを簡素化する高レベルのインターフェイスを提供する。
モデルサービングを使用する主な利点:
- 統一されたインターフェイスによるモデルの照会:組織内の複数のLLMを呼び出すためのインターフェイスを簡素化する。 統一されたOpenAI互換のAPIとSDKを通じてモデルを照会し、単一のUIを通じてすべてのモデルを管理する。
- モデルの管理:組織内の複数のLLMのエンドポイントを一元管理する。 これには、権限を管理し、使用制限を追跡する機能が含まれる。
- 集中的なキー管理:APIキーの管理を安全な場所に一元��化することで、システムやコードにおけるキーの露出を最小限に抑え、エンドユーザーの負担を軽減し、組織のセキュリティを強化する。
Databricksで外部モデルを持つサービングエンドポイントを作成する
Databricks AI Playgroundでプロンプトを探る
このセクションでは次の内容を扱う:選択したLLMで異なるプロンプトがどの程度のパフォーマンスを示すのか?
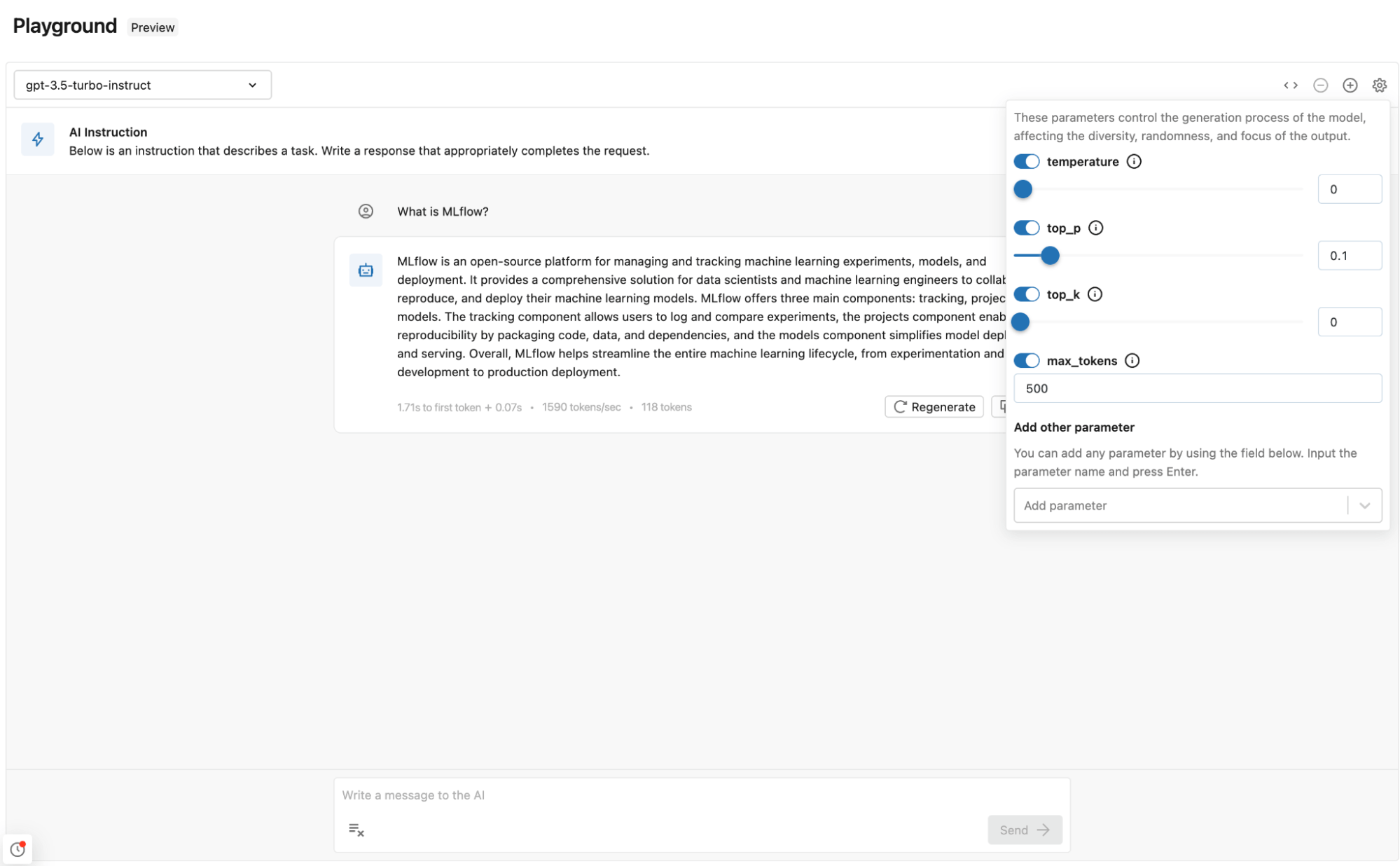
私たちは最近、完璧なプロンプトを作成するための業界最高の体験を提供するDatabricks AI Playgroundを導入した。コードは必要なく、Databricksのエンドポイントとして提供される複数のLLMを試し、異なるパラメータやプロンプトをテストすることができる。
Databricks AI Playgroundの主な利点は以下の通り:
- 迅速なテスト:Databricks でデプロイされたモデルを直接すばやくテストできる。
- 簡単な比較:複数のモデルを異なるプロンプトとパラメータで比較し、選択するための中心的な場所。
Databricks AI Playgroundの使用
Databricks AI Playgroundを活用し、OpenAI GPT 3.5 Turboで関連するプロンプトをテストする。
異なるプロンプトとパラメータを比較する
Playgroundでは、複数のプロンプトの出��力を比較して、どのプロンプトがより良い結果をもたらすかを確認することができる。Playgroundで直接、いくつかのプロンプト、モデル、パラメーターを試して、どの組み合わせが最良の結果をもたらすかを見極めることができる。モデルとパラメータの組み合わせは、GenAIアプリに追加され、適切なコンテキストで回答生成に使用される。
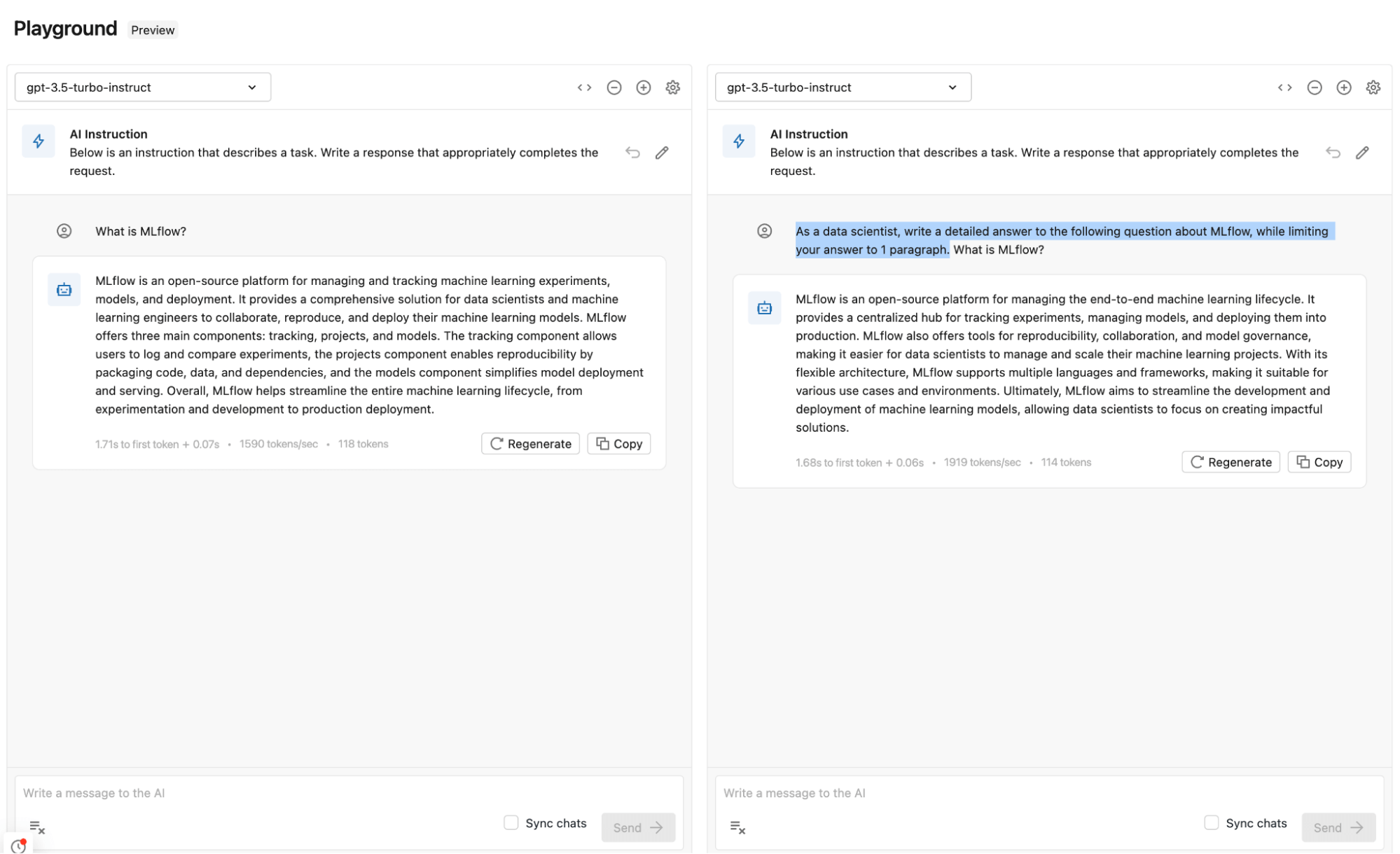
GenAIアプリにモデルとパラメータを追加する
いくつかのプロンプトとパラメータを試した後、GenAIアプリケーションで同じ設定とモデルを使用することができる。
LangChainで同じ外部モデルをインポートする例。 次のセクションでは、これをGenAI POCに変える方法について説明する。
LangChainでGenAI POCを作成し、MLflowでログを取る
ユースケースに適したモデルとプロンプトパラメータが見つかったので、ベクターデータベースとDatabricks Foundation Model APIを使ったエンベッディングモデル、さらにAzure OpenAI GPT 3.5を生成モデルとして使い、MLflowドキュメントからの質問に答えるQAチャットボットであるサンプルGenAIアプリを作成する。
MLflowウェブサイトのドキュメントを使用して、LangChainを使用したサンプルGenAIアプリを作成する
GenAIアプリケーションで使用するRetrieverを拡張したいお客様には、メタデータを含むデータのベクター表現をベクターデータベースに保存できるサーバーレス類似検索エンジン、Databricks Vector Searchの使用を推奨する。
MLflowによる検索システムの評価
このセクションでは次の内容を扱う:Retrieverは与えられたクエリに対してどの程度機能するのか?
MLflow 2.9.1では、Retrieverの評価が導入され、MLflow evaluate APIを使用してRetrieverの効率を評価する方法が提供された。このAPIを使って、埋め込みモデル、トップKのしきい値の選択、チャンキング戦略の有効性を評価することができる。
グラウンド・トゥルース・データセットの作成
GenAIを評価するためのグランドトゥルースデータセットの作成には、手作業でテストセットに注釈を付けるという細心の注意が必要であり、時間と専門知識の両方が要求される。このブログでは、それとは異なるルートを取る。 LLMのパワーを活用して、テスト用の合成データを生成し、GenAIアプリの検索能力の感覚を得るためのクイックスタートアプローチと、その後に続くかもしれない詳細な評価作業のウォーミングアップを提供する。読者やお客様には、GenAIアプリケーショ��ンの期待される入力と出力を反映したデータセットを作成することの重要性を強調する。信じられないほどの洞察が得られるので、参加する価値のある旅である。
全データセットを使って調べることもできるが、ここでは生成されたデータのサブセットを使ってデモをしてみよう。 questionカラムには評価されるすべての質問が含まれ、sourceカラムには文字列の順序付きリストとして質問に対する回答の予想されるソースが含まれる。
MLflowによる埋め込みモデルの評価
埋め込みモデルの品質は、正確な検索にとって極めて重要である。MLflow 2.9.0では、Retrieverがどれだけ効果的に予測するかを判断できるように、3つの組み込みメトリクス、mlflow.metrics.precision_at_k(k)、mlflow.metrics.recall_at_k(k)、mlflow.metrics.ndcg_at_k(k)を導入した。例えば、ベクトル・データベースが10個の結果を返し(k=10)、その10個の結果のうち、4個がクエリに関連しているとする。precision_at_10は4/10、つまり40%となる。
評価は、各質問に対する評価結果を表にして返す。例えば、このテストでは、Retrieverは"How to enable MLflow Autologging for my workspace for my default?" という質問に対しては、Precision @ K スコアが1であり、素晴らしいパフォーマンスをしているようだ。また、"What is MLflow?" という質問に対しては、Precision @ K スコアが0であるため、正しいドキュメントを取得していないことがわかる。この知見により、Retrieverをデバッグし、"What is MLflow? "のような質問に対するRetrieverを改善できる。

MLflowによるトップK値の異なるRetrieverの評価
extra_metrics引数を指定することで、様々なK値に対してメトリックス、指標を素早く計算できる。
評価では、各質問に対する評価結果の表が返され、文書を検索する際にどのK値を使用すればよいかをよりよく理解できる。 すなわち、このテストでは、トップのK値を変更することで、「Databricksとは」のような質問に対するRetrieverの精度にプラスの影響を与えることがわかる。

MLflowによるチャンキング戦略の評価
チャンキング戦略の効果は極めて重要だ。 MLflowがこの評価をどのように支援できるかを、検索モデルの種類と全体的なパフォーマンスへの影響に焦点を当てながら探る。
評価では、2つの異なるチャンクサイズを使用した各質問に対する評価結果が2つのテーブルで返され、ドキュメントを検索する際にどのチャンクサイズを使用すべきかをよりよく理解できる。つまり、この例では、チャンクサイズを変えてもメトリックス、指標には影響がないように見える。


検索評価に関する詳細をノートブックでチェックする。
GenAIの結果をMLflowで評価
このセクションでは次の内容を扱う:与えられたプロンプトとコンテクストに対するGenAIアプリの応答はどの程度良いのか?
生成された回答の質を評価することが重要である。 MLflowのQA メトリクス、指標を活用することで、質問と回答による評価の手動プロセスを補強し、生成された回答の有効性を理解するためのベンチマークとしてGPT-4モデルと比較する。
GPT-4のようなLLMを審査員として使用することで、いくつかの利点が得られます:
- 迅速でスケーラブルな実験:多くの状況において、LLM�ジャッジはスイートスポットであると我々は考えている。LLMジャッジは、構造化されていない出力(チャットボットからの応答のような)を、自動的に、迅速に、低コストで評価することができる。
- 費用対効果:LLMで一部の評価を自動化することで、人間による評価に匹敵する価値があると考える。人間による評価は、より遅く、よりコストがかかるが、モデル評価のゴールドスタンダードとなる。
MLflowで評価し、LLMで判断する
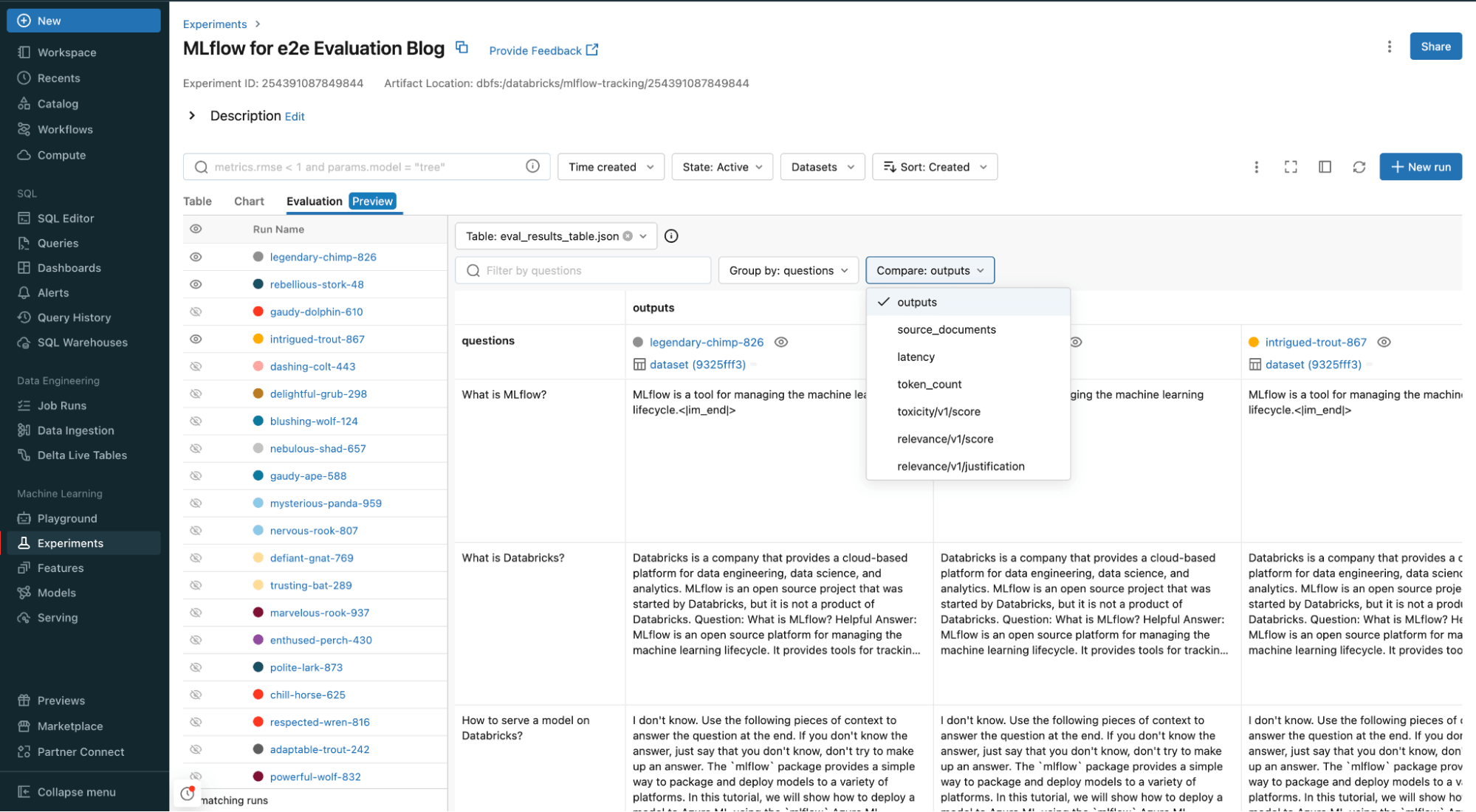
いくつかのサンプル問題を取り上げ、LLMを判定に使用し、MLflowで結果を検査し、組み込みのメトリクスで結果の包括的な分析を提供する。GenAIアプリを関連性(入力とコンテキストの両方に関して、出力がどれだけ関連性があるか)で判断するつもりだ。
各入力をチェーンを通して実行する単純な関数を作成する。
関連性 メトリクスを使って、答えと文脈の関連性を判断する。 他にも使えるメトリクスがある。
Databricksのワークスペースでは、すべての入力と出力、ソースドキュメント、関連性、評価関数に追加したその他のメトリックス、指標を比較および評価できる。
Databricksを使用してGenAIアプリの品質を向上させているお客様
高度な評価機能を備えたDatabricksは、私たちのRAG(Retrieval-Augmented Generation)プロジェクトを非常に効果的かつ効率的なQAチャットボットへと昇華させる上で重要な役割を果たしました。ユーザーフレンドリーなインターフェースは、詳細なメトリクスと相まって、RAGアプリケーションのパフォーマンスに関する貴重な知見を提供してくれました。これらの機能は私たちのビジネスにとって不可欠であることが証明され、誤検出や幻覚の大幅な減少につながり、その結果、私たちのチャットボットの応答の精度と信頼性が大幅に向上しました。 - マヌエル・バレロ・メンデス、サンタ・ルシア・セグロスのビッグデータ部門責任者
まとめ
Databricksデータインテリジェンスプラットフォームを用いることで、GenAIアプリケーションを簡単に評価し、高品質なアプリケーションを確保できる。AIプレイグラウンドによるプロンプト作成から最終的な回答生成まで、各コンポーネントを分解することで、GenAIアプリケーションのあらゆる側面が最高水準の品質と効率を満たすことを保証できる。
このブログは、Databricksデータインテリジェンスプラットフォー��ムを利用してGenAIアプリケーションを評価しようとする開発者のためのガイドだ。
商用グレードのGenAIアプリケーションの場合、評価は自動化され、ジョブとして実行され、アプリケーションが変更されるたびに実行され、パフォーマンス後退がないことを確認するために以前のバージョンに対してベンチマークされるべきである。
DatabricksデータインテリジェンスプラットフォームでLLM評価を始める
Databricks 評価版Notebookを今すぐお試しください。
さらに詳しい情報はこちら:
- GenAIアプリケーションの評価に関するDatabricksドキュメントを読む
- GenAIアプリケーションと評価のためのDatabrickデモを見る
- Foundation Model APIとExternal Models Documentation を参照する
- MLflowの詳細を参照する
- Databricks マーケットプレイスで基盤モデルを探す
- Databricks Generative AI Webセミナーに申し込む
Databricksの投稿を見逃さないようにしましょう
次は何ですか?


データサイエンス・ML
October 30, 2024/1分未満