Apache Spark 構造化ストリーミングにおけるステートフルパイプラインのパフォーマンス改善

イントロダクション
Apache Spark™ の構造化ストリーミングは、Spark SQLエンジン上に構築された、スケーラビリティと耐障害性を提供する人気のオープンソースストリーム処理プラットフォームです。 Databricksレイクハウスプラットフォーム上のほとんどの増分的およびストリーミングワークロードは、Delta Live TablesおよびAuto Loaderを含む構造化ストリーミングを利用しています。 ここ数年、あらゆる業界における多様なユースケースにおいて、構造化ストリーミングの使用と採用が飛躍的に伸びています。 Databricksでは、1週間に1,400万以上の構造化ストリーミングジョブが実行されており、その数は年間2倍以上のペースで増加しています。
ほとんどの構造化ストリーミングのワークロードは、分析ワークロードと運用ワークロードの2つに大別できます。 運用ワークロードは、ビジネスの重要な部分をリアルタイムで実行します。 分析処理とは異なり、運用処理ではデータに対するタイムリーな変換とアクションが重視されます。 運用処理アーキテクチャーにより、企業は受信データを迅速に処理し、業務上の意思決定を行い、データから得られるリアルタイムの洞察に基づいて即座に行動を起こすことができます。
このような運用ワークロードにとって、一貫した低レイテンシは重要な要件です。 このブログでは、構造化ストリー��ミングを使用するステートフルパイプラインのこの要件を達成するために、DatabricksがProject Lightspeedの一部として実装したパフォーマンス改善に焦点を当てます。
当社の性能評価では、これらの機能強化により、Databricks Runtime 13.3 LTS以降で実行される100kイベント/秒以上のスループットを持つワークロードで、ステートフルパイプラインのレイテンシを最大3~4倍改善できることが示されています。 これらの改良は、非常に厳しいレイテンシSLAを持つ、より多様なワークロードへの扉を開くものです。
このブログは2部構成になっており、第1部ではパフォーマンスの改善と向上について掘り下げ、第2部ではパフォーマンスの改善を達成した方法について、包括的な深堀りと高度な洞察を提供します。
このブログ記事は、読者がApache Spark 構造化ストリーミングの基本的な理解を持っていることを前提としていることに注意してください。
背景
ストリーム処理は、ステートレスとステートフルに大別されます:
- ステートレスパイプラインでは、通常、マイクロバッチ間のコンテキストを記憶することなく、各マイクロバッチを独立して処理する必要があります。 例えば、レコード単位でデータを変換する(フィルタリング、分岐、マッピング、反復など)ストリーミングETLパイプラインなどがあります。
- ステートフルパイプラインでは、複数のマイクロバッチに現れるレコードの情報を集約することがよくあります(例えば、時間ウィンドウの平均を計算する)。 このような操作を完了するために、これらのパイプラインはマイクロバッチ間で見たデータを記憶する必要があり、この状態はパイプラインの再起動にも弾力的である必要があります。
ステートフル・ストリーミング・パイプラインは、主に商品やコンテンツのレコメンデーション、不正検知、サービスのヘルスモニタリングなど、リアルタイムのユースケースに使用されます。
ステートとステート管理とは?
Apache Sparkクエリのコンテキストにおけるステートとは、ストリーミングパイプラインのマイクロバッチ間で維持される中間的な永続的コンテキストのことで、キー付きステートストアのコレクションです。 ステートストアは、読み取りと書き込みの両方の操作を提供するバージョン管理されたキーバリューストアです。 構造化ストリーミングでは、ステートストア・プロバイダの抽象化を使用してステートフルなオペレーションを実装します。 組み込みのステート・ストア・プロバイダーの実装は2つあります:
- HDFSにバックアップされたステート・ストア・プロバイダーは、すべてのステート・データをエクゼキューターのJVMメモリーに保存し、HDFS互換ファイルシステムに永続的に保存されたファイルによってバックアップされます。 ストアの更新はすべてトラン��ザクション単位で行われ、更新のセットごとにストアのバージョンがインクリメントされます。 これらのバージョンは、正しいバージョンのストアでアップデートを再実行し、必要に応じてストアのバージョンを再生成するために使用できます。 すべての更新はメモリに保存されるため、このプロバイダはメモリ不足の問題やガベージコレクションの一時停止に定期的に遭遇する可能性があります。
- RocksDBステートストア・プロバイダは、各実行ノードのSparkパーティションごとに1つずつ、RocksDBインスタンス内の状態を管理します。 この場合、状態も分散ファイルシステムに定期的にバックアップされ、特定の状態バージョンをロードするために使用することができます。
Databricksでは、本番ワークロードにはRocksDBステートストア・プロバイダを使用することを推奨しています。 このプロバイダーを使用することで、JVMヒープ関連のメモリー問題や、HDFS状態ストア・プロバイダーによくあるガベージ・コレクションによる速度低下のリスクを回避できます。
ベンチマーク
私たちは、ステートフル・ストリーミング・パイプラインのパフォーマンスと、私たちの改善の効果をよりよく理解するために、一連のベンチマークを作成しました。 テスト用に一定のスループットでソースからデータを生成しました。 生成されたレコードには、レコードがいつ作成されたかという情報が含�まれていました。 すべてのステートフル・ストリーミング・ベンチマークについて、レコード単位でエンド・ツー・エンドの待ち時間を追跡しました。 シンク側では、Apache DataSketchesライブラリを使用して、各レコードがシンクに書き込まれた時刻とソースが生成したタイムスタンプの差を収集しました。 このデータは、ミリ秒単位の待ち時間を計算するために使用されました。
Kafkaベンチマークでは、Kafkaを実行し、Kafkaに供給するデータを生成するために、いくつかのクラスタノードを確保しました。 レコードのレイテンシを計算したのは、レコードがKafka(シンク上)に正常にパブリッシュされた後です。 すべてのテストは、ステートフル・ストリーミング・クエリ用のステート・ストア・プロバイダーとしてRocksDBを使用して実行されました。
以下のテストはすべて、AWSのi3.2xlargeインスタンス(8コア、61GB RAM)で実行しました。 テストは、DBR 12.2 (改良なし) をベースイメージとして、DBR 13.3 LTS (すべての改良を含む) をテストイメージとして、1つのドライバと5つのワーカーノードで実行しました。
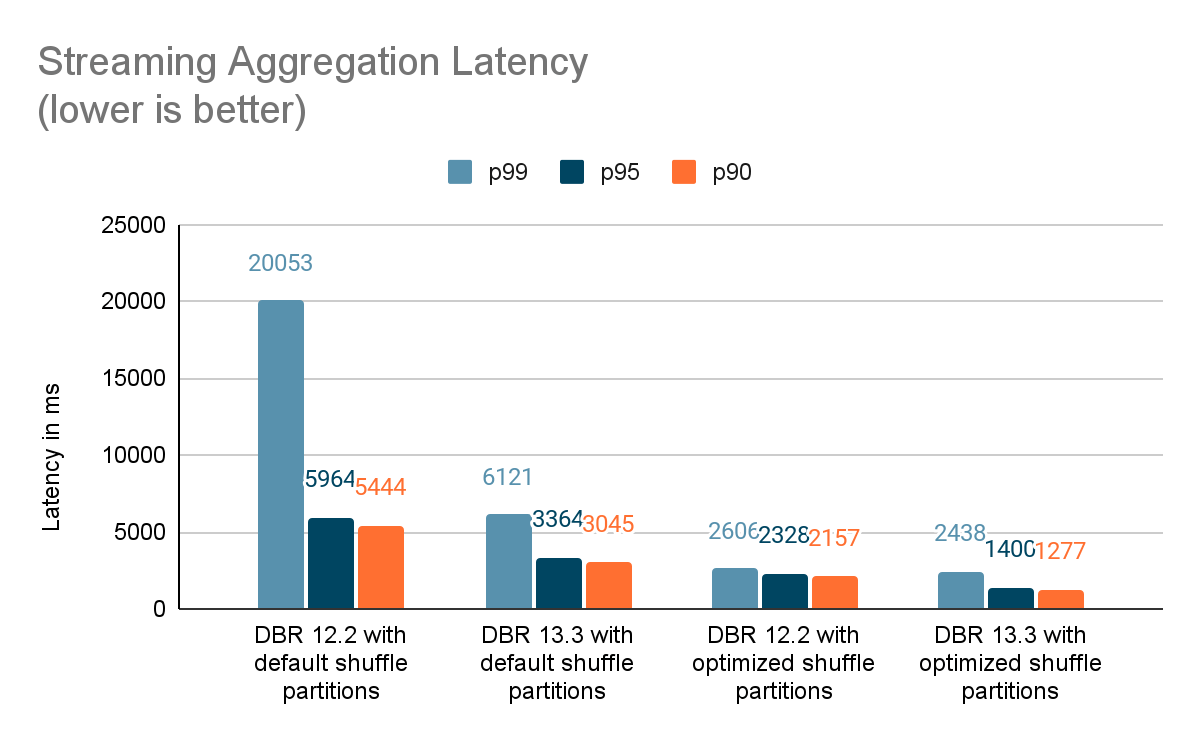
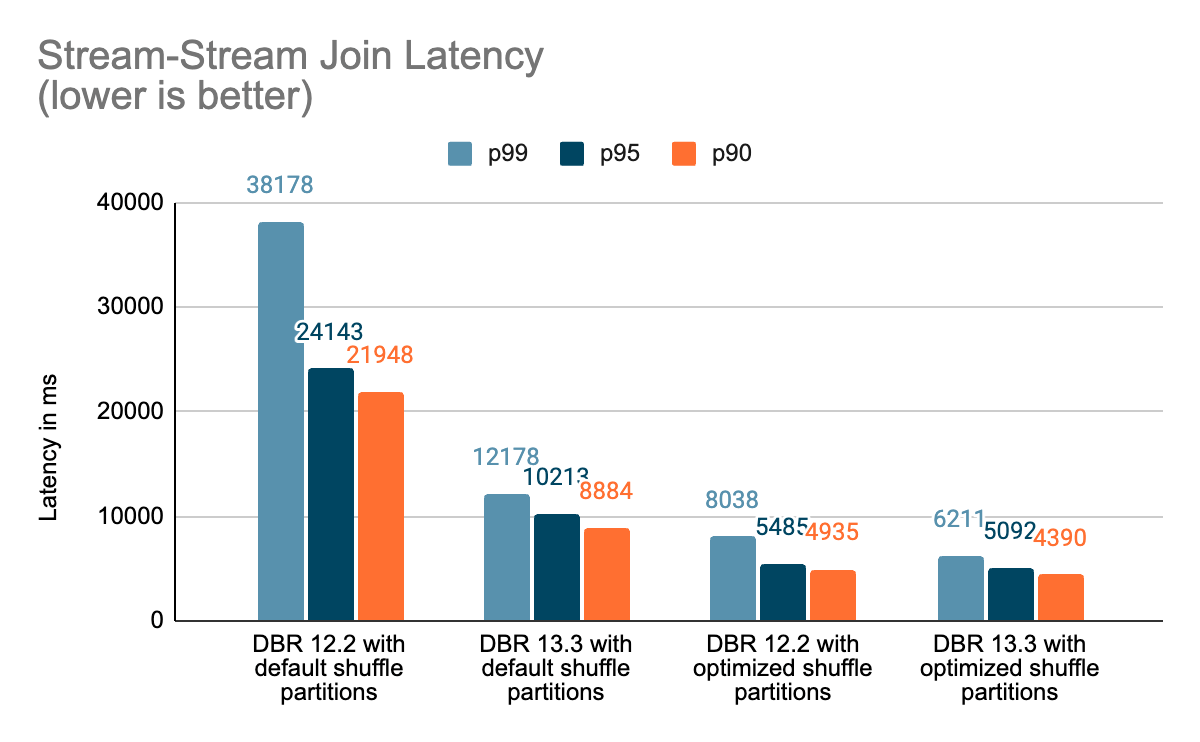
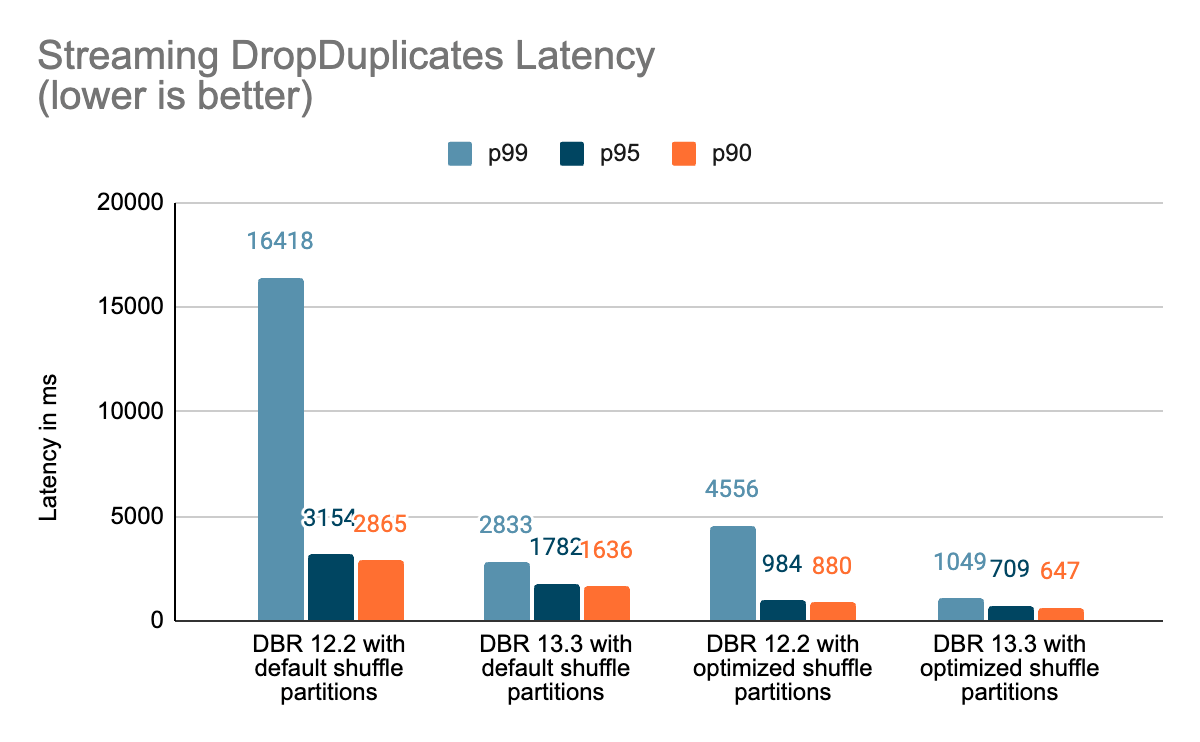
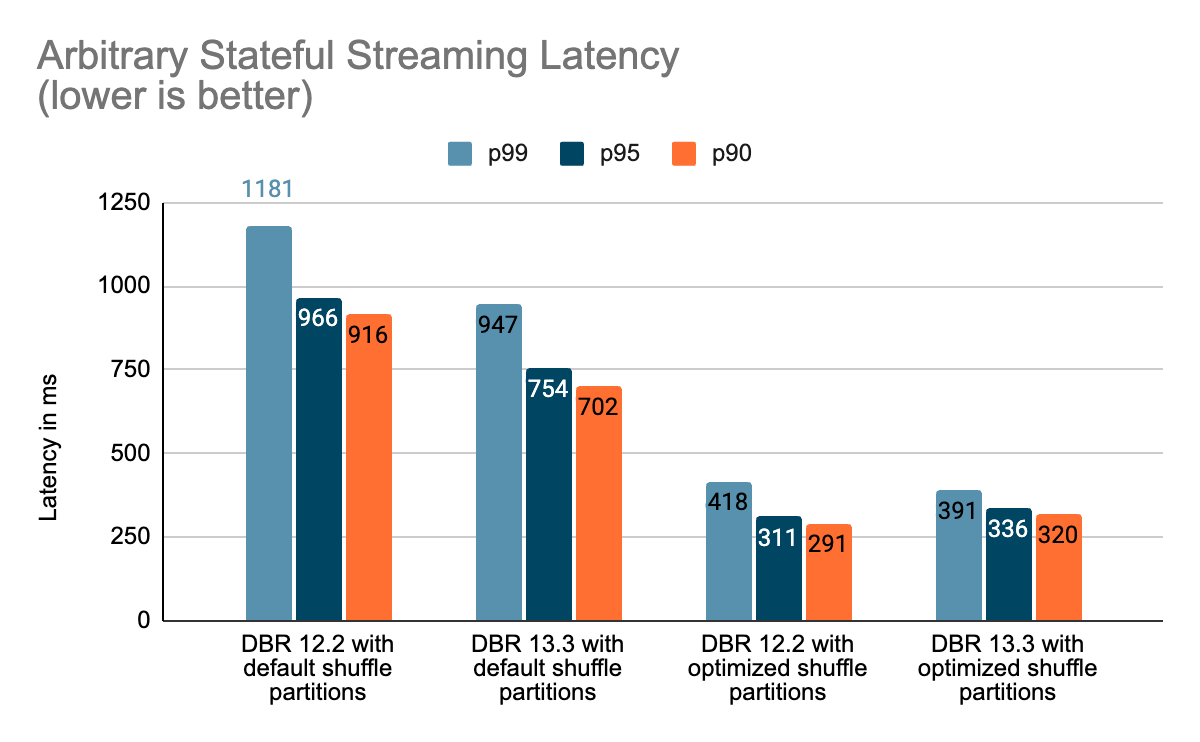
まとめ
このブログでは、Project Lightspeedのアップデートブログで言及されたパフォーマンスの改善を紹介するために実施したベンチマークのハイレベルな概要を提供しました。 ベンチマークが示すように、Databricks上でSpark Structured Streamingを使用してステートフルなパイプラインを実行しているお客様にとって、私たちが追加したパフォーマンスの向上は、多くのスピードと価値を解き放ちます。 ステートフルパイプラインに追加されたパフォーマンス改善については、次のブログポスト" ADeep Dive Into Latest Performance Improvements of Stateful Pipelines in Apache Spark Structured Streaming" で詳しく説明します。
利用
上記の機能はすべてDBR 13.3 LTSリリースから利用可能です。

