AIエージェント評価が進化!新たな合成データ機能で効率アップ

Summary
- 合成データ生成APIは、顧客独自のデータを活用して評価セットを生成し、エージェントの品質を評価し改善するための手段を提供します。
- APIは、評価データの生成に要する数週間から数か月にわたる専門家(SME)によるラベル付け作業を省略できます。
- APIは、Agent Evaluation、MLflow、Mosaic AI、およびDatabricks Data Intelligence Platform全体と緊密に統合されており、エージェントの応答品質を迅速に評価し改善するためにデータを活用できます。
私たちのお客様は、汎用モデルを用いた大規模プロンプトから、ROIを向上させるために必要な品質を達成する専門的なエージェントシステムへと移行し続けています。今年初め、私たちは Mosaic AI Agent Framework と Agent Evaluation をリリースしました。これらは現在、多くの企業で、企業データを活用した複雑な推論や、サポートチケットの作成、メール対応などのタスクを実行するエージェントシステムの構築に利用されています。
本日、Agent Evaluationにおける大幅な強化として、合成データ生成APIを発表します。合成データ生成とは、実世界のデータを模倣した人工的なデータセットを作成することを指しますが、これは「架空の情報」を作ることではありません。私たちのAPIは、顧客独自のデータを活用し、それに基づいて評価セットを生成します。この評価セットは、顧客のユースケース�に特化したものであり、ソフトウェアエンジニアリングにおけるテストスイートや、従来の機械学習における検証データのような役割を果たし、エージェントの品質を評価し改善するための手段を提供します。
これにより、評価データの生成に要する数週間から数か月にわたる専門家(SME)によるラベル付け作業を省略できます。すでに多くの顧客がこの機能を活用し、生産投入までの時間を短縮すると同時に、エージェントの品質向上と開発コスト削減を実現しています。
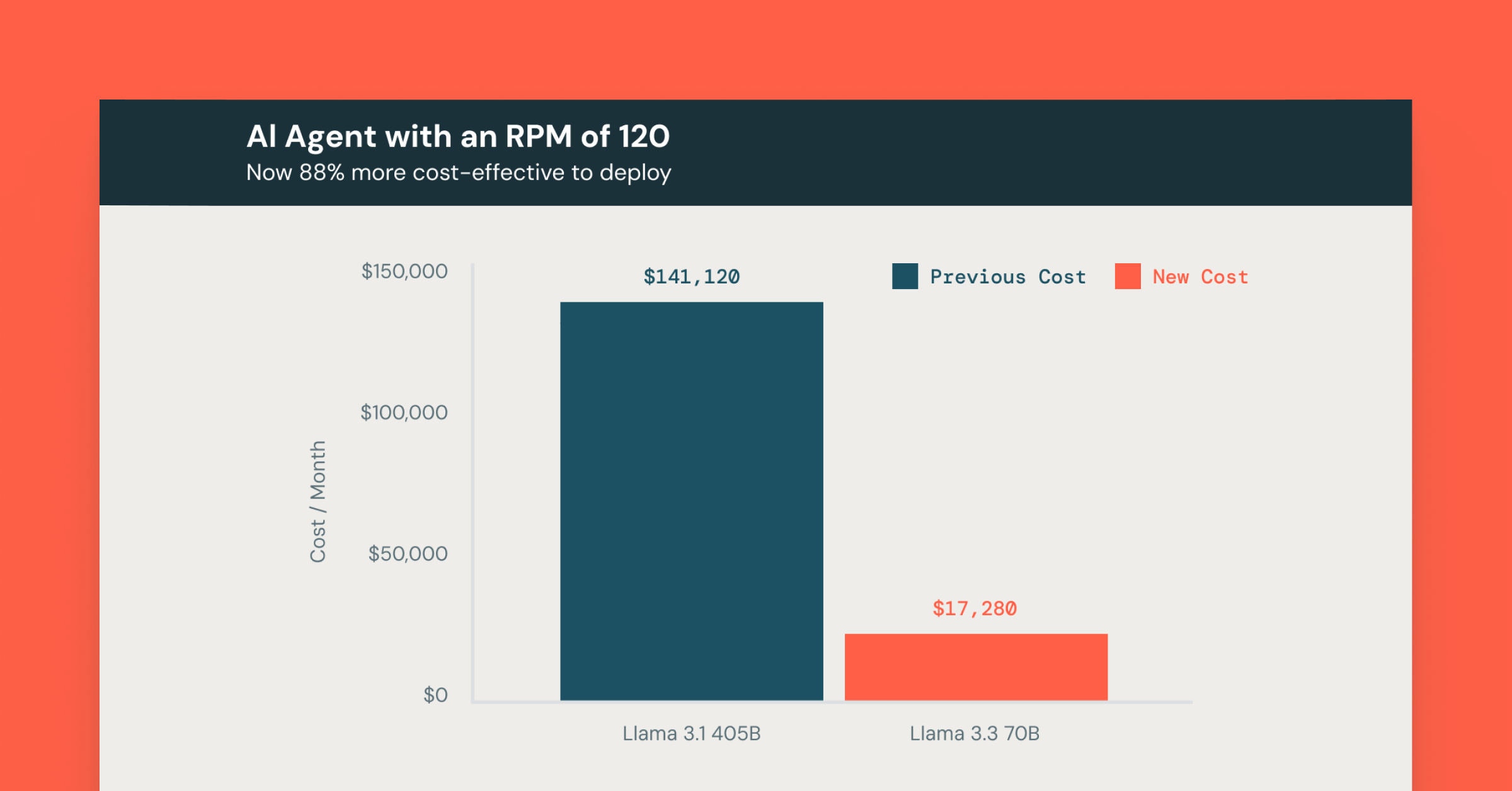
「Mosaic AI Agent Evaluationの合成データ機能により、AIエージェントの応答品質向上プロセスが大幅に加速しました。高品質な合成の質問と回答を事前に生成することで、専門家が評価用データセットを一から作成する時間を最小限に抑え、検証や細かな修正に集中できるようになりました。このアプローチにより、専門家の介入を行う前の段階で、モデルの応答品質を60%向上させることができました。」 — Lippertの人工知能部門ディレクター、Chris Nishnick
合成データ生成APIの紹介
エージェントの品質を評価し、向上させることは、より良いビジネス成果を実現するために不可欠ですが、多くの組織がエージェントを測定・改善するための高品質な評価データセットを作成する際のボトルネックに苦労しています。ラベル付けに時間がかかるプロセスや専門家(SME)の不足�、多様で有意義な質問を生成する難しさが、進捗を遅らせ、イノベーションを妨げる原因となっています。
Agent Evaluationの合成データ生成APIは、これらの課題を解決します。このAPIを利用すれば、開発者は独自のデータに基づいて高品質な評価データセットを数分で作成でき、SMEの入力を待つ必要なくエージェントの品質を評価し、向上させることが可能になります。評価データセットは、従来の機械学習における検証データやソフトウェアエンジニアリングにおけるテストスイートに似た役割を果たします。
この合成データ生成APIは、Agent Evaluation、MLflow、Mosaic AI、およびDatabricks Data Intelligence Platform全体と緊密に統合されており、エージェントの応答品質を迅速に評価し改善するためにデータを活用できます。利用を開始するには、クイックスタートノートブックをご覧ください。

仕組み
このAPIはシンプルに利用できるよう設計されています。以下の入力を使用してAPIを呼び出します:
- エージェントが使用するドキュメントや企業のナレッジを含むSparkまたはPandasのデータフレーム
- 生成する質問の数
- (任意)合成データ生成をガイドするための平易な言語のガイドライン
例: エージェントのユースケース、エンドユーザーのペルソナ、質問の望ましいスタイル など
この入力に基づいて、APIはあなたのデータを元にAgent Evaluationのスキーマで <質問, 合成回答, ソースドキュメント> を生成します。次に、この生成された評価セットを mlflow.evaluate(...) に渡すことで、Agent Evaluationの独自のLLM判定機能がエージェントの品質を評価し、品質問題の根本原因を特定します。これにより、迅速な問題修正が可能になります。
品質分析の結果の確認
MLflow Evaluation UI を使用して品質分析の結果を確認し、エージェントの品質を向上させるための変更を加えます。その後、mlflow.evaluate(...) を再実行することで、改善が正しく機能したかを検証できます。
SMEによるレビュー(オプション)
また、生成された合成データをSME(専門家)と共有し、質問や回答の正確性をレビューすることも可能です。重要なのは、生成された合成回答は質問に答えるために必要な事実のセットであり、LLMによって書かれた応答ではない点です。このアプローチにより、SMEがこれらの事実をレビュー・編集する時間が、完全��な生成応答を確認するよりも大幅に短縮されます。
たった5分でエージェントのパフォーマンスを向上
さらに詳しく知りたい方は、以下の手順でエージェントの品質を改善する方法を示したサンプルノートブックを参照してください:
- 合成評価データセットを生成
- ベースラインエージェントを構築し、評価
- 複数の設定(プロンプトなど)や基盤モデルでベースラインエージェントを比較し、品質、コスト、遅延のバランスを最適化
- エージェントをWeb UIにデプロイして、ステークホルダーがテストを行い、追加のフィードバックを提供できるようにする
これで、エージェントの性能向上プロセスを迅速かつ効率的に実現できます!

Synthetic Data Generation API
エージェントの評価を生成するために、開発者は generate_evals_df メソッドを呼び出して、ドキュメントから代表的な評価データセットを作成できます。
キャプション: 合成デー�タ生成APIの使用例。
カスタマイズと制御
お客様との会話を通じて、開発者は単なるドキュメントのリストを提供するだけでなく、質問生成プロセスをより細かく制御したいと考えていることがわかりました。このニーズに応えるため、APIには以下のオプション機能を追加しました。これにより、特定のユースケースに合わせた高品質な質問を作成できるようになります。
- agent_description: エージェントのタスクを説明するための記述
- question_guidelines: 質問のスタイルや種類を制御するためのガイドライン
キャプション: 例 agent_description と question_guidelines Databricks RAGチャットボットのための。
合成データ生成APIの出力
APIの出力を説明するために、このブログ記事を入力ドキュメントとしてAPIに渡し、以下の質問ガイドラインを指定しました:
- コンテンツに関する質問のみを生成し、コードについては対象外とする
- 質問は、このプロダクトが開発者にとって適切かどうかを理解しようとする人が尋ねるもの
- 質問は短く、検索エンジンで特定の結果を見つけるためのクエリのようなもの
例:
- 「合成データは何に使われるのか?」
- 「合成データをカスタマイズする方法は?」
合成データ生成APIの出力は、Agent Evaluationスキーマに従ったテーブル形式です。このデータセットの各行には1つのテストケースが含まれており、Agent Evaluationの回答正確性判定機能によって、エージェントが質問に対して期待される事実をすべて含む回答を生成できるかどうかが評価されます。
|
フィールド名 |
説明 |
このブログ投稿からの例 |
|
request |
|
合成データAPIで質問生成をどのようにカスタマイズできますか? |
|
|
リクエストとexpected_factsが合成されたソースドキュメントの具体的な文章 |
顧客との会話を通じて、開発者は単にドキュメントのリストを提供するだけでなく、質問生成プロセスに対するより大きなコントロールを求めていることがわかりました。このニーズに対応するため、私たちのAPIには、開発者が特定のユースケースに合わせた高品質な質問を作成することを可能にするオプション機能が含まれています。
|
|
|
expected_retrieved_contextから合成された、正しいエージェントの回答が含むべき事実のリスト |
- |
|
|
このテストケースの出典となったソースドキュメントの一意のID |
https://blog.databricks.com/blog/streamline-ai-agent-evaluation-with-new-synthetic-data-capabilities |
キャプション: 合成評価生成APIの出力フィールドと、このブログの内容に基づいてAPIが生成したサンプル行。
以下に、上記のコードによって生成された他のいくつかの requests と expected_facts のサンプルを含めています。
|
|
|
|
Mosaic AIエージェント評価の合成データ機能を使用することで、顧客はどのような利益を得ることができますか? |
- 生産までの時間を短縮 - エージェントの品質を向上 - 開発コストの削減 |
|
合成データ生成APIを使用するために必要な入力は何ですか? |
- SparkまたはPandasのデータフレームが必要です - データフ��レームにはドキュメントや企業の知識が含まれるべきです - 生成する質問の数を指定する必要があります。 |
|
伝統的な機械学習とソフトウェアエンジニアリングにおける評価セットとは何ですか? |
- 評価セットは、伝統的な機械学習における検証セットと比較されます - 評価セットは、ソフトウェアエンジニアリングのテストスイートと比較されます。 |
キャプション: このブログの内容に基づいてAPIが生成した追加行のサンプル。
MLFlowとエージェント評価との統合
生成された評価データセットは、mlflow.evaluate(..., model_type="databricks-agent") と新しいMLflow Evaluation UIで直接利用できます。簡単に言えば、開発者は以下のプロセスを迅速に実行できます:
- 組み込みおよびカスタムLLM判定機能を使用してエージェントの品質を測定
- MLflow Evaluation UIで品質指標を確認
- 低品質な出力の根本原因を特定し、問題を修正する方法を決定
- 問題を修正��した後、新しいバージョンのエージェントを評価し、MLflow Evaluation UIで前のバージョンと品質を直接比較
これにより、品質改善プロセスを効率的に進めることが可能です。
エージェントフレームワークを介したデプロイメント
ビジネス要件である品質、コスト、遅延を満たすエージェントが完成したら、Agent Framework の agents.deploy(...) を使ったわずか1行のコードで、すぐに本番環境向けのスケーラブルなREST APIとWebベースのチャットUIをデプロイできます。
合成データ生成を始める
- 詳細を学び、デモノートブックを実行するには、Databricksのドキュメンテーションをご覧ください
- ビデオデモをご覧ください。
今後にもご期待ください!
現在、評価データセットの管理やSME(専門家)からのフィードバック収集を支援するための新機能を複数開発中です。
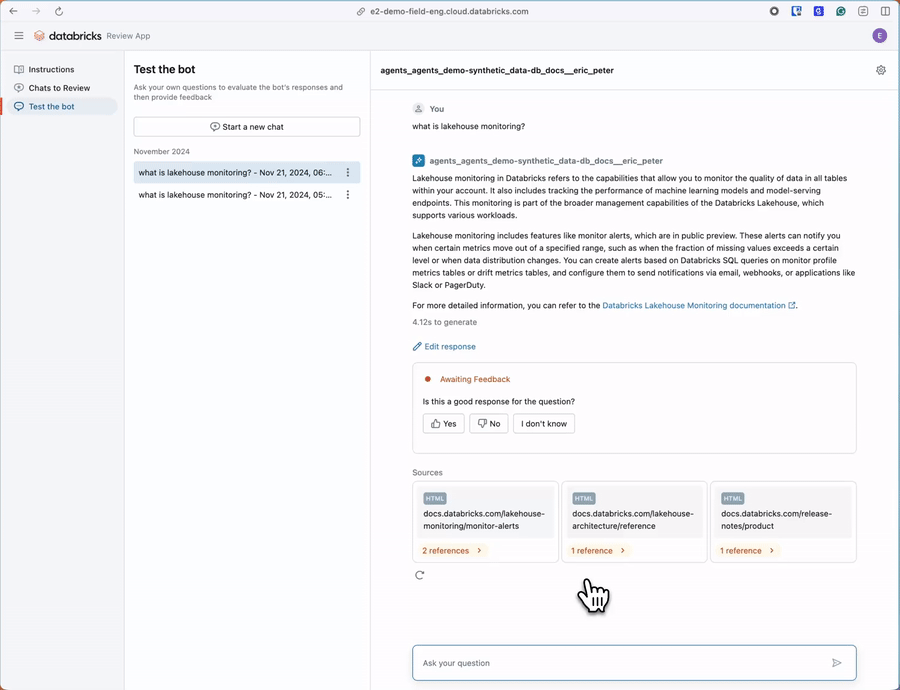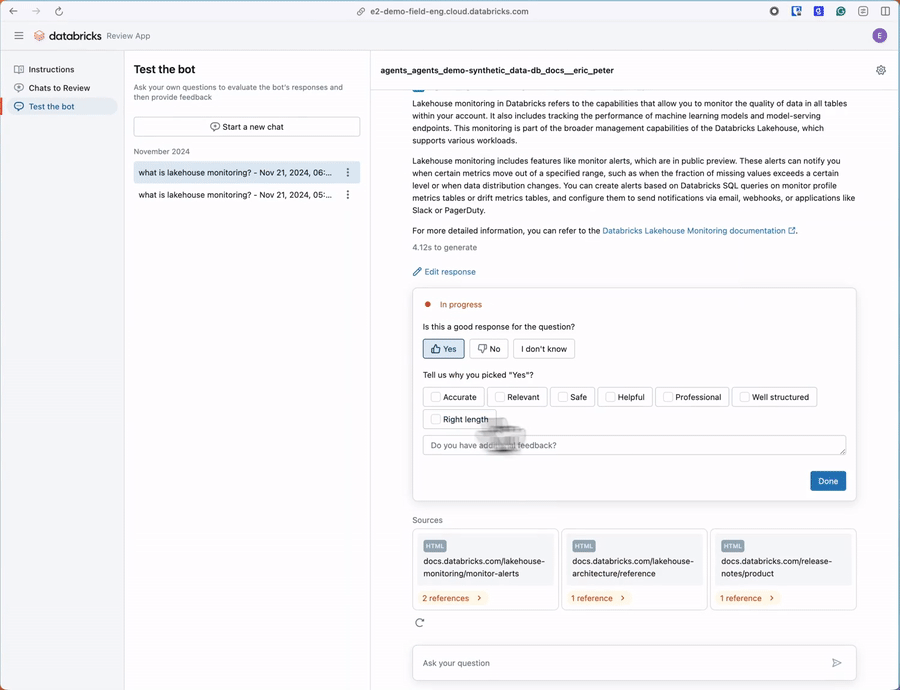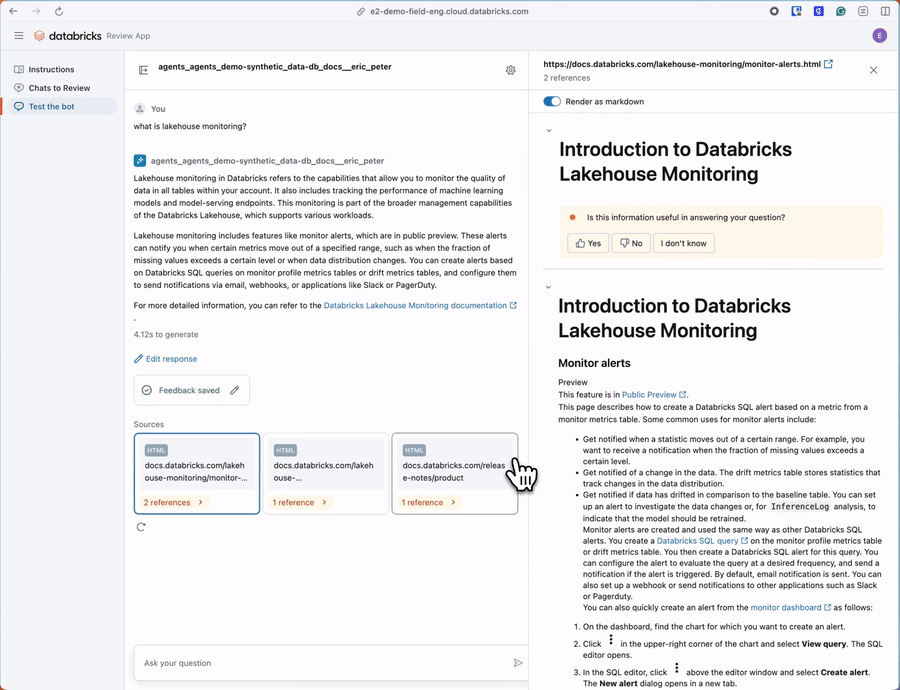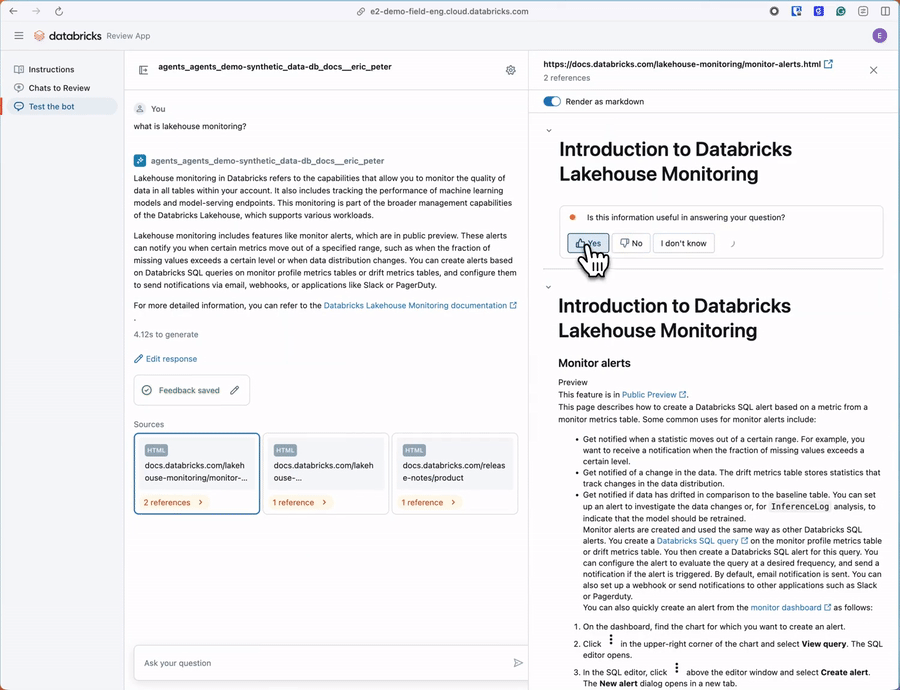
SMEレビューUIは、新たに追加される機能で、専門家が合成的に生成された評価データの正確性を迅速に確認し、必要に応じて追加の質問を加えられるようにします。このUIは、ビジネスエキスパートが効率的にレビューを行えるよう設計されており、本来の業務から離れる時間を最小限に抑えることを目的としています。

マネージド評価データセットは、評価データのライフサイクル管理を支援するために設計されたサービスです。このサービスでは、バージョン管理されたDeltaテーブルを提供し、開発者やSMEが評価記録のバー�ジョン履歴(質問、グラウンドトゥルース、タグなどのメタデータ)を追跡できるようになります。
具体的には、以下のような変更が管理可能です:
- 新しい評価記録の追加
- 評価記録の変更(例:質問やグラウンドトゥルースの修正など)
- 評価記録の削除
一部の顧客には、これらの機能のプレビュー版へのアクセスがすでに提供されています。この機能やその他のAgent EvaluationおよびAgent Frameworkのプレビュー版に登録するには、アカウントチームに相談するか、このフォームに記入してください。