Hadoop分散ファイルシステム(HDFS)とは何ですか?
ファイルをクラスターノード全体にレプリケートされたブロックに分割して分散保存し、耐障害性、スケーラブルな容量、および高スループットアクセスを提供
によって Databricks Staff による投稿
- Hadoop分散ファイルシステム(HDFS)は、ファイルをブロックに分割し、スケーラビリティと耐障害性のために多くのマシンに分散するストレージシス�テムです。
- HDFSは、コモディティハードウェアのクラスターに非常に大きなデータセットを保存し、個々のノードが失敗した場合でもデータを利用できるように設計されました。
- 多くの組織が現在、レイクハウスアーキテクチャでクラウドオブジェクトストレージを使用していますが、HDFSを理解することは、初期のビッグデータシステムの基盤を説明するのに役立ちます。
HDFS
HDFS(Hadoop分散ファイルシステム)は、Hadoopアプリケーションで使用される主要なストレージシステムです。このオープンソースフレームワークは、ノード間でデータを高速に転送することで機能します。ビッグデータを処理および保存する必要がある企業によく利用されます。HDFSは、ビッグデータの管理手段を提供し、ビッグデータ分析もサポートするため、多くのHadoopシステムの重要なコンポーネントです。
世界中にはHDFSを使用している企業がたくさんありますが、それは具体的に何であり、なぜ必要なのか?HDFSとは何か、そしてビジネスにとってどのように役立つのかを詳しく見ていきましょう。
HDFSとは?
HDFSはHadoop Distributed File Systemの略です。HDFSは、汎用ハードウェア上で実行できるように設計された分散ファイルシステムとして機能します。
HDFSは耐障害性があり、低コストの汎用ハードウェアに展開できるように設計されています。HDFSはアプリケーションデータへの高スループットデータアクセスを提供し、大規模なデータセットを持つ��アプリケーションに適しており、Apache Hadoopでのファイルシステムデータへのストリーミングアクセスを可能にします。
では、Hadoopとは何でしょうか?そしてHDFSとどう違うのでしょうか?HadoopとHDFSの主な違いは、Hadoopはデータを保存、処理、分析できるオープンソースフレームワークであるのに対し、HDFSはデータへのアクセスを提供するHadoopのファイルシステムであるということです。これは基本的に、HDFSがHadoopのモジュールであることを意味します。
HDFSのアーキテクチャを見てみましょう。
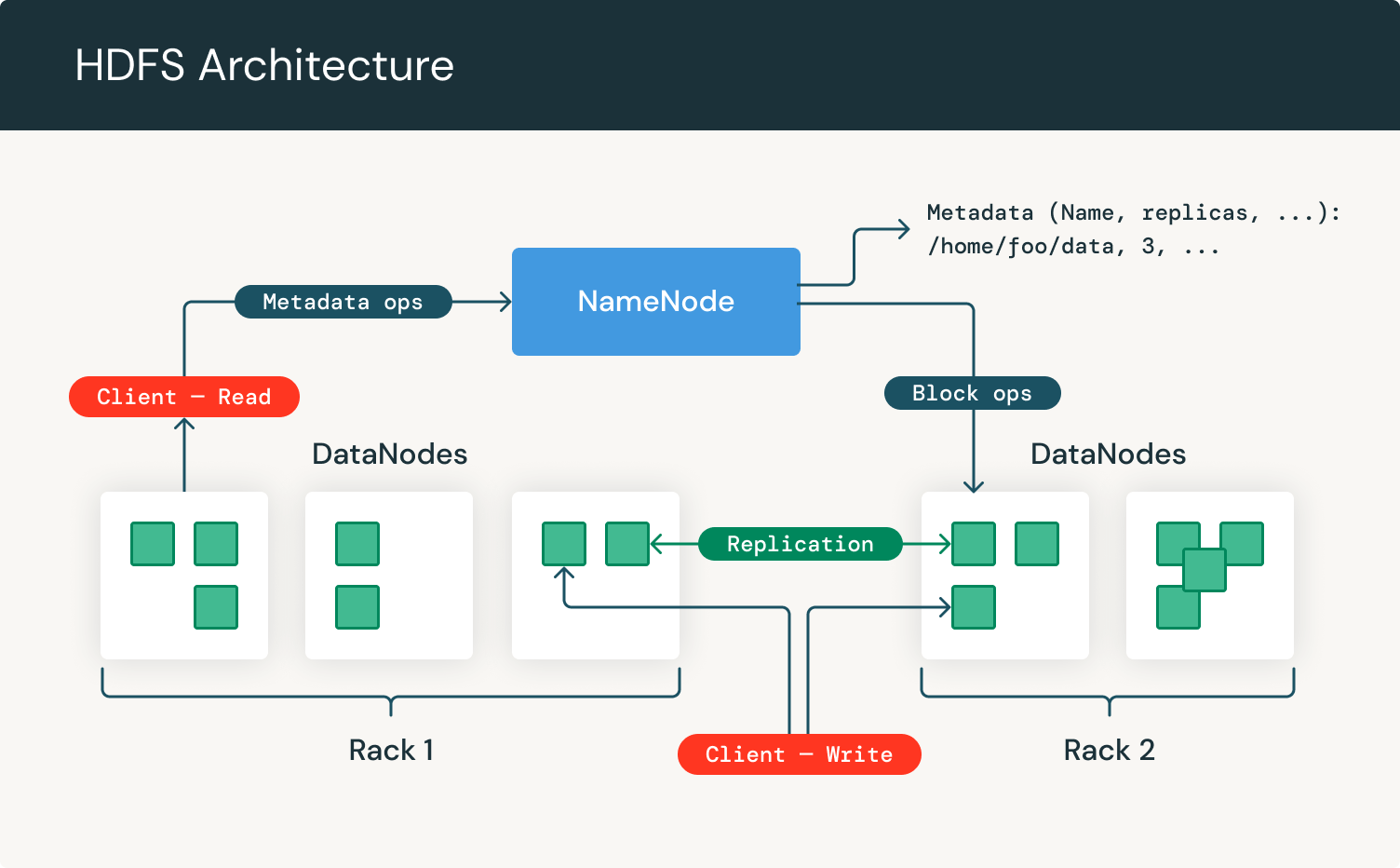
ご覧のとおり、NameNodeとDataNodeに焦点を当てています。NameNodeは、GNU/Linuxオペレーティングシステムとソフトウェアを含むハードウェアです。Hadoop分散ファイルシステムはマスターサーバーとして機能し、ファイルを管理し、ファイルへのクライアントアクセスを制御し、ファイルのリネーム、オープン、クローズなどのファイル操作プロセスを監督します。
DataNodeは、GNU/LinuxオペレーティングシステムとDataNodeソフトウェアを備えたハードウェアです。HDFSクラスタ内の各ノードには、DataNodeが配置されています。これらのノードは、クライアントが要求した場合にファイルシステムに対する操作を実行したり、NameNodeの指示に従ってファイルを作成、複製、ブロックしたりでき��るため、システムのデータストレージを制御するのに役立ちます。
HDFSの意味と目的は、次の目標を達成することです。
- 大規模データセットの管理 - データセットの整理と保存は、困難な作業です。HDFSは、巨大なデータセットを扱う必要があるアプリケーションを管理するために使用されます。これを行うには、HDFSはクラスタあたり数百のノードを持つ必要があります。
- 障害検出 - HDFSは、多数の汎用ハードウェアが含まれているため、障害を迅速かつ効果的にスキャンして検出するためのテクノロジーを備えている必要があります。コンポーネントの障害は一般的な問題です。
- ハードウェア効率 - 大規模データセットが関わる場合、ネットワークトラフィックを削減し、処理速度を向上させることができます。
HDFSの歴史
Hadoopの起源は何でしょうか?HDFSの設計はGoogle File Systemに基づいています。当初はApache Nutchウェブ検索エンジンのインフラストラクチャとして構築されましたが、その後Hadoopエコシステムのメンバーになりました。
インターネットの初期の頃、ウェブクローラーは人々がウェブページ上の情報を検索するための方法として登場しました。これにより、YahooやGoogleのようなさまざまな検索エンジンが生まれました。
また、Nutchという別の検索エンジンも生まれ、データを複数のコンピューターに同時に分散して計算したいと考えていました。Nutchはその後Yahooに移り、2つに分割されました。Apache SparkとHadoopは現在、それぞれ独立したエンティティです。Hadoopはバッチ処理を処理するように設計されているのに対し、Sparkはリアルタイムデータを効率的に処理するように作られています。
現在、Hadoopの構造とフレームワークは、ソフトウェア開発者と貢献者のグローバルコミュニティであるApacheソフトウェア財団によって管理されています。
HDFSはこれに由来し、ハードウェアストレージソリューションを、より優れた、より効率的な方法である仮想ファイルシステムに置き換えるように設計されています。登場した当初は、HDFSを使用できる分散処理エンジンはMapReduceだけでした。最近では、HBaseやSolrなどの代替Hadoopデータサービスコンポーネントもデータを保存するためにHDFSを利用しています。
ビッグデータの世界におけるHDFSとは?
では、ビッグデータとは何でしょうか?そしてHDFSはどのように関わってくるのでしょうか?「ビッグデータ」という用語は、保存、処理、分析が困難なすべてのデータを指します。HDFSビッグデータとは、HDFSファイルシステムに整理されたデータのことです。
ご存知のとおり、Hadoopは並列処理と分散ストレージを使用して機能するフレームワークです。これは、従来の方法では保存できないビッグデータをソートおよび保存するために使用できます。
実際、Netflix、Expedia、British Airwaysなどの企業がデータストレージに関してHadoopとの良好な関係を持っており、ビッグデータを処理するために最も一般的に使用されているソフトウェアです。HDFSはビッグデータにおいて不可欠です。なぜなら、多くの企業が現在データを保存する方法としてこれを選択しているからです。
HDFSサービスによって整理されたビッグデータの5つのコア要素があります。
- Velocity(速度) - データが生成、収集、分析される速さ。
- Volume(量) - 生成されるデータの量。
- Variety(多様性) - データの種類。構造化、非構造化などがあります。
- Veracity(真実性) - データの品質と正確さ。
- Value(価値) - このデータを使用してビジネスプロセスに洞察をもたらす方法。
Hadoop分散ファイルシステムの利点
Hadoop内のオープンソースサブプロジェクトとして、HDFSはビッグデータに対処する際に5つのコアメリットを提供します。
- 耐障害性。HDFSは障害を検出し、自動的に迅速に回復するように設計されており、継続性と信頼性を確保します。
- 速度。クラスタアーキテクチャにより、毎秒2GBのデータを維持できます。
- より多くの種類のデータへのアクセス、特にストリーミングデータ。バッチ処理のために大量のデータを処理するように設計されているため、高いデータスループット率が可能になり、ストリーミングデータのサポートに最適です。
互換性とポータビリティ。HDFSは、さまざまなハードウェア設定に移植可能であり、複数の基盤となるオペレーティングシステムと互換性があるように設計さ�れており、最終的にユーザーは独自のテーラードセットアップでHDFSを使用するオプションを提供します。これらの利点は、ビッグデータに対処する際に特に重要であり、HDFSがデータを処理する特定の方法によって可能になりました。
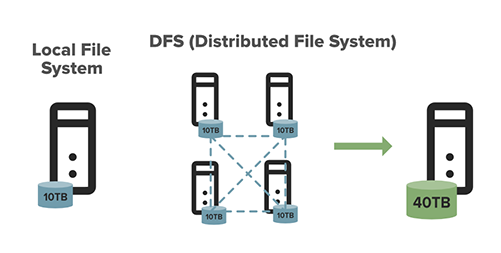
このグラフは、ローカルファイルシステムとHDFSの違いを示しています。
- スケーラブル。ファイルシステムのサイズに応じてリソースをスケーリングできます。HDFSには、垂直および水平スケーラビリティメカニズムが含まれています。
- データローカリティ。Hadoopファイルシステムの場合、データはデータノードに存在し、データが計算ユニットの場所まで移動することはありません。データとコンピューティングプロセスの間の距離を短縮することにより、ネットワークの輻輳を減らし、システムをより効果的かつ効率的にします。
- コスト効率。最初に、データを考えると、高価なハードウェアと帯域幅の占有を考えるかもしれません。ハードウェア障害が発生した場合、修正には非常にコストがかかる可能性があります。HDFSでは、データは仮想であるため安価に保存され、ファイルシステムメタデータとファイルシステム名前空間データのストレージコストを大幅に削減できます。さらに、HDFSはオープンソースであるため、企業はライセンス料金を支払う必要はありません。
- 大量のデータを保存。データストレージはHDFSがすべてです。つまり、あらゆる種類とサイズのデータ、特に保存に苦労している企業からの大量のデータです。これには、構造化データと非構造化データの両方が含まれます。
- 柔軟性。他の従来のストレージデータベースとは異なり、収集したデータを保存する前に処理する必要はありません。保存したい量のデータを保存でき、後で何をしたいか、どのように使用したいかを正確に決定する機会があります。これには、テキスト、ビデオ、画像などの非構造化データも含まれます。
HDFSの使用方法
では、HDFSをどのように使用するのでしょうか?HDFSは、メインのNameNodeと複数の他のDataNodeと連携し、すべて汎用ハードウェアクラスタ上で動作します。これらのノードは、データセンター内の同じ場所に配置されます。次に、ブロックに分割され、保存のために複数のDataNodeに分散されます。データ損失の可能性を減らすために、ブロックはノード間で複製されることがよくあります。これは、データが失われた場合のバックアップシステムです。
NameNodeについて見ていきましょう。NameNodeは、クラスタ内でデータの内容、それが属するブロック、ブロックサイズ、そしてどこに配置されるべきかを知っているノードです。NameNodeは、誰がいつデータを書き込み、読み込み、作成、削除、複製できるかを含む、ファイルへのアクセスを制御するためにも使用されます。
サーバーの容量に応じて、必要に応じてクラスタをリアルタイムで適応させることもできます。これは、データが急増した場合に役立ちます。必要に応じてノードを追加��または削除できます。
次に、DataNodeについて説明します。DataNodeは、タスクを開始および完了する必要があるかどうかを判断するために、NameNodeと常に通信しています。この継続的な連携により、NameNodeは各DataNodeの状態を正確に把握できます。
DataNodeが正常に動作していないと判断された場合、NameNodeはそのタスクを同じデータブロック内の別の機能しているノードに自動的に再割り当てできます。同様に、DataNodeは互いに通信することもできるため、標準的なファイル操作中に連携できます。NameNodeはDataNodeとそのパフォーマンスを認識しているため、システムの維持に不可欠です。
データブロックは複数のデータノードに複製され、NameNodeによってアクセスされます。
HDFSを使用するには、Hadoopクラスタをインストールしてセットアップする必要があります。これは、初めて使用するユーザーに適したシングルノードセットアップ、または大規模な分散クラスタ用のクラスタセットアップにすることができます。その後、システムを操作および管理するために、以下のようなHDFSコマンドに慣れる必要があります。
| コマンド | 説明 |
| -rm | ファイルまたはディレクトリを削除します |
| -ls | 権限などの詳細とともにファイルを一覧表示します |
| -mkdir | HDFSにパスという名前のディレクトリを作成します |
| -cat | ファイルのコンテンツを表示します |
| -rmdir | ディレクトリを削除します |
| -put | ローカルディスクからHDFSにフ�ァイルまたはフォルダをアップロードします |
| -rmr | パスで識別されたファイルまたはフォルダとサブフォルダを削除します |
| -get | HDFSからローカルファイルにファイルまたはフォルダを移動します |
| -count | ファイル数、ディレクトリ数、およびファイルサイズをカウントします |
| -df | 空き容量を表示します |
| -getmerge | HDFS内の複数のファイルをマージします |
| -chmod | ファイル権限を変更します |
| -copyToLocal | ファイルをローカルシステムにコピーします |
| -Stat | ファイルまたはディレクトリに関する統計情報を表示します |
| -head | ファイルの最初のキロバイトを表示します |
| -usage | 個々のコマンドのヘルプを返します |
| -chown | ファイルの新しい所有者とグループを割り当てます |
HDFSはどのように機能しますか?
前述のように、HDFSはNameNodeとDataNodeを使用します。HDFSは、コンピューティングノード間のデータの高速転送を可能にします。HDFSがデータを取り込むと、情報をブロックに分割し、クラスタ内の異なるノードに分散させることができます。
データはブロックに分割され、ストレージのためにDataNodeに分散されます。これらのブロックはノード間で複製することもでき、効率的な並列処理が可能になります。さまざまなコマンドを使用して、データにアクセスしたり、移動したり、表示したりできます。HDFS DFSオプションである"-get"や"-put"を使用��すると、必要に応じてデータを取得および移動できます。
さらに、HDFSは非常に注意深く設計されており、障害を迅速に検出できます。ファイルシステムはデータレプリケーションを使用して、すべてのデータが複数回保存されていることを確認し、それを個々のノードに分散させることで、少なくとも1つのコピーが他のコピーとは異なるラックにあることを保証します。
これは、DataNodeがNameNodeに信号を送信しなくなった場合に、そのDataNodeをクラスタから削除して、それなしで動作することを意味します。このデータノードが後で戻ってきた場合、新しいクラスタに割り当てることができます。さらに、データブロックは複数のDataNodeに複製されているため、1つを削除してもファイルが破損することはありません。
HDFSコンポーネント
Hadoopには3つの主要なコンポーネントがあることを知っておくことが重要です。Hadoop HDFS、Hadoop MapReduce、およびHadoop YARNです。これらのコンポーネントがHadoopにもたらすものを見てみましょう。
- Hadoop HDFS - Hadoop Distributed File System (HDFS) は、Hadoopのストレージユニットです。
- Hadoop MapReduce - Hadoop MapReduce は、Hadoopの処理ユニットです。このソフトウェアフレームワークは、大量のデータを処理するアプリケーションを記述するために使用されます。
- Hadoop YARN - Hadoop YARN は、Hadoopのリソース管理コンポーネントです。HDFSに保存されているバッチ、ストリーム、インタラクティブ、およびグラフ処理のためにデータを処理および実行します。
HDFSファイルシステムの作成方法
HDFSファイルシステムの作�成方法を知りたいですか?以下に、システムを作成、編集し、必要に応じて削除する方法をガイドする手順を示します。
HDFSのリスト表示
HDFSのリストは/user/yourUserNameであるはずです。HDFSホームディレクトリの内容を表示するには、次のように入力します。
始めたばかりなので、この時点では何も表示されません。空でないディレクトリの内容を表示したい場合は、次のように入力します。
これにより、他のすべてのHadoopユーザーのホームディレクトリの名前が表示されます。
HDFSにディレクトリを作成する
テストディレクトリを作成しましょう。名前はtestHDFSとします。これはHDFS内に表示されます。次のように入力するだけです。
これで、HDFSのリスト表示に使用したコマンドを使用して、ディレクトリが存在することを確認する必要があります。testHDFSディレクトリが一覧表示されているはずです。
HDFSのフルパス名を使用して、再度確認してください。次のように入力します。
次のステップに進む前に、これが機能していることを再確認してください。
ファイルのコピー
ローカルファイルシステムからHDFSにファイルをコピーするには、コピーしたいファイルを作成することから始めます。これを行うには、次のように入力します。
これにより、HDFSテストファイルを含むtestFileという名前の新しいファイルが作成され��ます。これを確認するには、次のように入力します。
ls
そして、ファイルが作成されたことを確認するには、次のように入力します。
次に、ファイルをHDFSにコピーする必要があります。LinuxからHDFSにファイルをコピーするには、次を使用する必要があります。
コマンド"-cp"はHDFS内のファイルをコピーするために使用されるため、コマンド"-copyFromLocal"を使用する必要があることに注意してください。
これで、ファイルが正しくコピーされたことを確認するだけです。次のように入力して確認します。
ファイルの移動とコピー
testfileをコピーしたとき、それはホームディレクトリのベースに配置されました。次に、すでに作成したtestHDFSディレクトリに移動できます。次を使用します。
最初の部分は、testFileをHDFSホームディレクトリから作成したテストディレクトリに移動しました。このコマンドの2番目の部分は、HDFSホームディレクトリにtestFileがなくなったことを示しており、3番目の部分は、それがtestHDFSディレクトリに移動されたことを確認しています。
ファイルをコピーするには、次のように入力します。
ディスク使用量の確認
HDFSを使用している場合、ディスクスペースの確認は役立ちます。これを行うには、次のコマンドを入力できます。
これにより、HDFSで使用しているスペースを確認できます。また、次のように入力して、クラスタ全体でHDFSで利用可能なスペースを確認することもできます。
ファイル/ディレクトリの削除
HDFS内のファイルまたはディレクトリを削除する必要がある場合があります。これは、次のコマンドで実現できます。
作成したtestHDFSディレクトリとtestFile2がまだ残っていることがわかります。次のように入力してディレクトリを削除します。
すると、エラーメッセージが表示されますが、慌てないでください。次のようなメッセージが表示されます。"rmdir: testhdfs: Directory is not empty"。ディレクトリを削除するには、空にする必要があります。"rm"コマンドを使用してこれを回避し、ファイルを含むディレクトリを削除できます。次のように入力します。
エンタープライズ向けエージェントAIプレイブック

HDFSのインストール方法
Hadoopをインストールするには、シングルノードとマルチノードがあることを覚えておく必要があります。必要に応じて、シングルノードまたはマルチノードクラスタを使用できます。
シングルノードクラスタは、1つのDataNodeのみが実行されていることを意味します。NameNode、DataNode、リソースマネージャー、およびノードマネージャーが1台のマシンに含まれます。
一部の業界では、これだけで十分です。たとえば、医療分野で研究を行い、データをシーケンスで収集、ソート、処理する必要がある場合、単一ノードクラスターを使用できます。これは、多くの数百台のマシンに分散されたデータと比較して、小規模なデータを簡単に処理できます。単一ノードクラスターをインストールするには、次の手順に従います。
- Java 8パッケージをダウンロードします。このファイルをホームディレクトリに保存します。
- Java Tarファイルを抽出します。
- Hadoop 2.7.3パッケージをダウンロードします。
- Hadoop Tarファイルを抽出します。
- bashファイル(.bashrc)にHadoopとJavaのパスを追加します。
- Hadoop構成ファイルを編集します。
- core-site.xmlを開き、プロパティを編集します。
- hdfs-site.xmlを編集し、プロパティを編集します。
- mapred-site.xmlファイルを編集し、プロパティを編集します。
- yarn-site.xmlを編集し、プロパティを編集します。
- hadoop-env.shを編集し、Javaパスを追加します。
- Hadoopホームディレクトリに移動し、NameNodeをフォーマットします。
- hadoop-2.7.3/sbinディレクトリに移動し、すべてのデーモンを起動します。
- すべてのHadoopサービスが実行されていることを確認します。
これで、HDFSが正常にインストールされたはずです。
HDFSファイルへのアクセス方法
データを取り扱っていることを考えると、HDFSのセキュリティが厳格であることは驚くことではありません。HDFSは技術的には仮想ストレージであるため、クラスター全体にまたがっており、ファイルシステム上のメタデータしか表示できず、実際の特定のデータは表示できません。
HDFSファイルにアクセスするには、HDFSからローカルファイルシステムに"jar"ファイルをダウンロードできます。Webユーザーインターフェイスを使用してHDFSにアクセスすることもできます。ブラウザを開き、検索バーに"localhost:50070"と入力するだけです。そこから、HDFSのWebユーザーインターフェイスを表示し、右側にあるユーティリティタブに移動できます。次に、「ファイルシステムをブラウズ」をクリックすると、HDFSにあるファイルの完全なリストが表示されます。
HDFS DFSの例
ここでは、最も一般的なHadoopコマンドの例をいくつか紹介します。
例 A
ディレクトリを削除するには、次のコマンドを適用する必要があります(注意:これはファイルが空の場合にのみ実行できます)。
または
例 B
HDFSに複数のファイルがある場合、「-getmerge」コマンドを使用できます。これにより、複数のファイルが単一のファイルにマージされ、ローカルファイルシステムにダウンロードできます。次のコマンドで実行できます。
または
例 C
HDFSからローカルにファイルをアップロードしたい場合は、「-put」コマンドを使用できます。コピー元と、HDFSにコピーしたいファイルを指定します。以下を使用してください。
または
例 D
countコマンドは、HDFS上のディレクトリ、ファイル、およびファイルサイズを追跡するために使用されます。次のコマンドを使用できます。
または
例 E
「chown」コマンドは、ファイルの所有者とグループを変更するために使用できます。これをアクティブにするには、以下を使用してください。
または
HDFSストレージとは何ですか?
ご存知のとおり、HDFSデータはブロックと呼ばれるものに格納されます。これらのブロックは、ファイルシステムが格納できる最小単位のデータです。ファイルは処理され、これらのブロックに分割され、クラスター全体に分散され、安全のためにレプリケートされます。通常、各ブロックは3回レプリケートできます。この図は、ビッグデータとHDFSでどのように格納できるかを示しています。
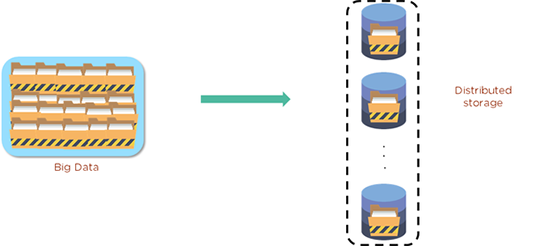
最初のレプリカはDataNodeにあり、2番目はクラスター内の別のDataNodeに格納され、3番目は別のクラスターのDataNodeに格納されます。これはトリプル保護セキュリティステップのようなものです。したがって、最悪の事態が発生して1つのレプリカが失敗した場合でも、データは失われません。
NameNodeは、ブロック数やレプリカの格納場所などの重要な情報を保持します。対照的に、DataNodeは実際のデータを格納し、コマンドに応じてブロックを作成、削除、レプリケートできます。次のようになります。
これにより、DataNodeがブロックをどこに格納すべきかが決まります。
HDFSはどのようにデータを格納しますか?
HDFSファイルシステムは、マスターサービス(NameNode、secondary NameNode、およびDataNodes)のセットで構成されます。NameNodeとsecondary NameNodeはHDFSメタデータを管理します。DataNodesは、基盤となるHDFSデータをホストします。
NameNodeは、特定のHDFSファイルのコンテンツをどのDataNodeが含んでいるかを追跡します。HDFSはファイルをブロックに分割し、各ブロックをDataNodeに格納します。複数のDataNodeがクラスターにリンクされます。NameNodeは、これらのデータブロックのレプリカをクラスター全体に分散します。また、ユーザーまたはアプリケーションに、目的の情報を見つける場所を指示します。
Hadoop分散フ��ァイルシステム(HDFS)は何を処理するように設計されていますか?
簡単に言うと、「Hadoop分散ファイルシステムは何を処理するように設計されていますか?」と尋ねられた場合、答えはまず第一にビッグデータです。これは、そうでなければビジネスや顧客からのデータを管理および格納するのに苦労する大企業にとって非常に価値のあるものになります。
Hadoopを使用すると、トランザクションデータ、科学データ、ソーシャルメディアデータ、広告データ、機械学習データなど、さまざまなデータを格納および統合できます。また、このデータに戻って、ビジネスパフォーマンスと分析に関する貴重な洞察を得ることもできます。
データを格納するように設計されているため、HDFSは、科学者や医療分野でそのようなデータを分析したい人々が一般的に使用する生データも処理できます。これらはデータレイクと呼ばれます。これにより、制約なしにより困難な質問に取り組むことができます。
さらに、Hadoopは主に膨大な量のデータをさまざまな方法で処理するように設計されているため、分析目的のアルゴリズムを実行するためにも使用できます。これは、企業がデータをより効率的に処理および分析するのに役立ち、新しいトレンドや異常を発見できるようにします。一部のデータセットは、データウェアハウスから削除されてHadoopに移動されています。すべてを1つのアクセスしやすい場所に簡単に格納できるようになります。
トランザクショ��ンデータに関しては、Hadoopは数百万のトランザクションを処理する能力も備えています。そのストレージと処理能力のおかげで、顧客データを格納および分析するために使用できます。また、データに深くドリルダウンして、ビジネス目標に役立つ新たなトレンドやパターンを発見することもできます。Hadoopは常に新しいデータで更新されており、新しいデータと古いデータを比較して、何がどのように変化したかを確認できることを忘れないでください。
HDFSに関する考慮事項
デフォルトでは、HDFSは3倍のレプリケーションで構成されており、データセットには2つの追加コピーがあります。これにより、処理中のローカルデータの可能性は高まりますが、オーバーヘッドストレージコストが発生します。
- HDFSは、ローカルに接続されたストレージで構成した場合に最適に機能します。これにより、ファイルシステムの最高のパフォーマンスが保証されます。
- HDFSの容量を増やすには、ストレージメディアだけでなく、新しいサーバー(コンピューティング、メモリ、ディスク)を追加する必要があります。
HDFSとクラウドオブジェクトストレージの比較
前述のように、HDFSの容量はコンピューティングリソースと密接に関連しています。ストレージ容量を増やすには、CPUリソースを増やす必要がありますが、後者は必要ありません。HDFSにデータノードを追加すると、既存のデータを新しく追加されたサーバーに分散するために再バランス操作が必要になります。
この操作には時間がかかる場合があります。オンプレミス環境でHadoopクラスターをスケーリングすることも、コ��ストとスペースの観点から困難になる可能性があります。HDFSはローカルに接続されたストレージを使用しており、YARNが処理対象のデータを格納しているサーバーで処理をプロビジョニングできると仮定すると、IOパフォーマンスのメリットが得られます。
高負荷の環境では、ほとんどのデータの読み書き操作はローカルではなくネットワーク経由で行われる可能性があります。クラウドオブジェクトストレージには、Azure Data Lake Storage、AWS S3、Google Cloud Storageなどのテクノロジーが含まれています。これは、それにアクセスするコンピューティングリソースとは独立しているため、顧客はクラウドにさらに多くのデータを格納できます。
ペタバイト級のデータを保存したい顧客は、クラウドオブジェクトストレージに簡単に保存できます。しかし、クラウドストレージに対するすべての読み書き操作はネットワーク経由で行われます。そのため、データにアクセスするアプリケーションは、可能な限りキャッシュを活用するか、I/O操作を最小限に抑えるロジックを含めることが重要です。
追加リソース
- HadoopからLakehouseへの移行ガイド
- 移行ハブ
- クラウドモダナイゼーションEbook:Hadoopからの移行における隠れた価値に関するビジネスガイド
- Databricks Lakehouse Platformのオンデマンドクイックデモ
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。