Low-risk migration to a fast and open data lakehouse
Legacy data warehouses are expensive — it’s time to move.Reduce cost
Adopt a lower cost curve with a rapid payback period by using a serverless, elastic cloud-native data lakehouse that scales for users and data with world-class price and performance.
Fast and predictable migration
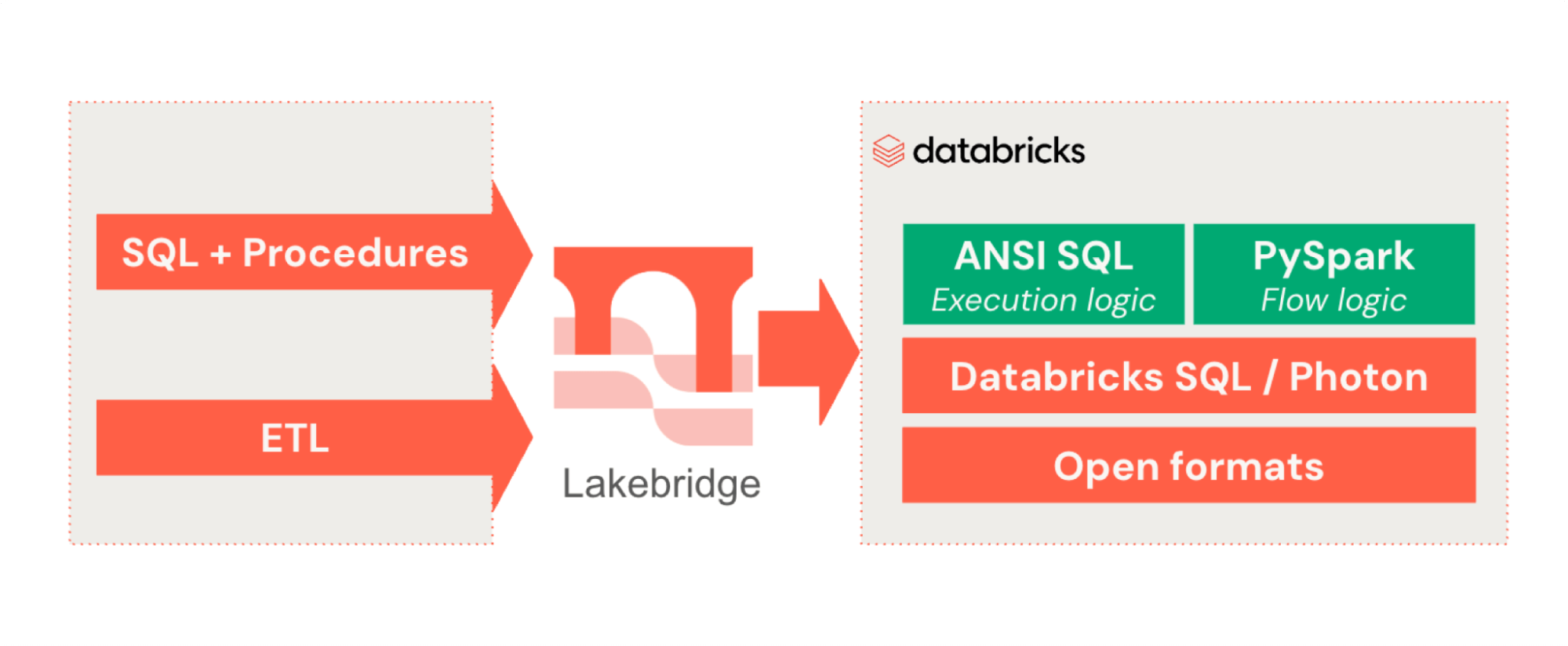
Complete your migration by using tools, blueprints and accelerators in easy phases. Lakebridge, used by 1,000+ customers and partners since its 2025 launch, lowers risk and complexity while improving data quality during migrations and modernizations.
Architect for an open future
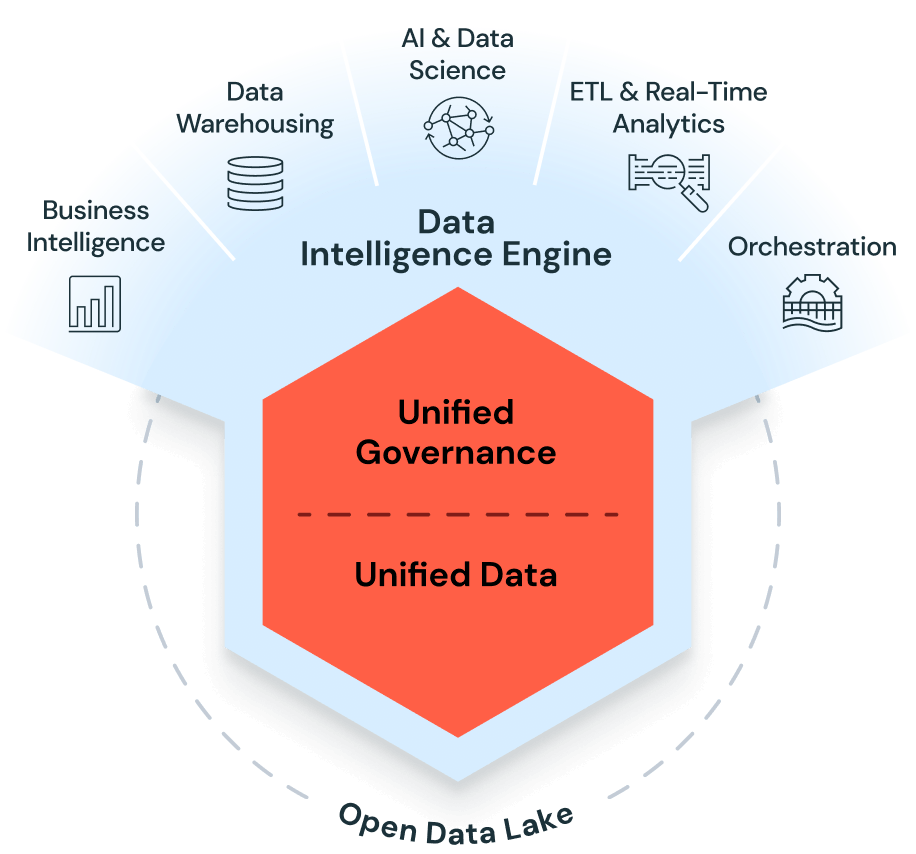
Serve a broader set of business users by choosing a platform that isn’t locked in and is AI-enabled. When your business users have new requirements, you are ready. When you need governance across the entire data estate, you are ready.

Tools and accelerators from Databricks and our partners
Fast, predictable migrations
Join 1,000+ customers and partners in accelerating migration to Databricks with Lakebridge – automate code conversion, validate data, and move from legacy warehouses with speed and confidence.



Proven strategies to help you achieve scalability, cost efficiency and AI innovation
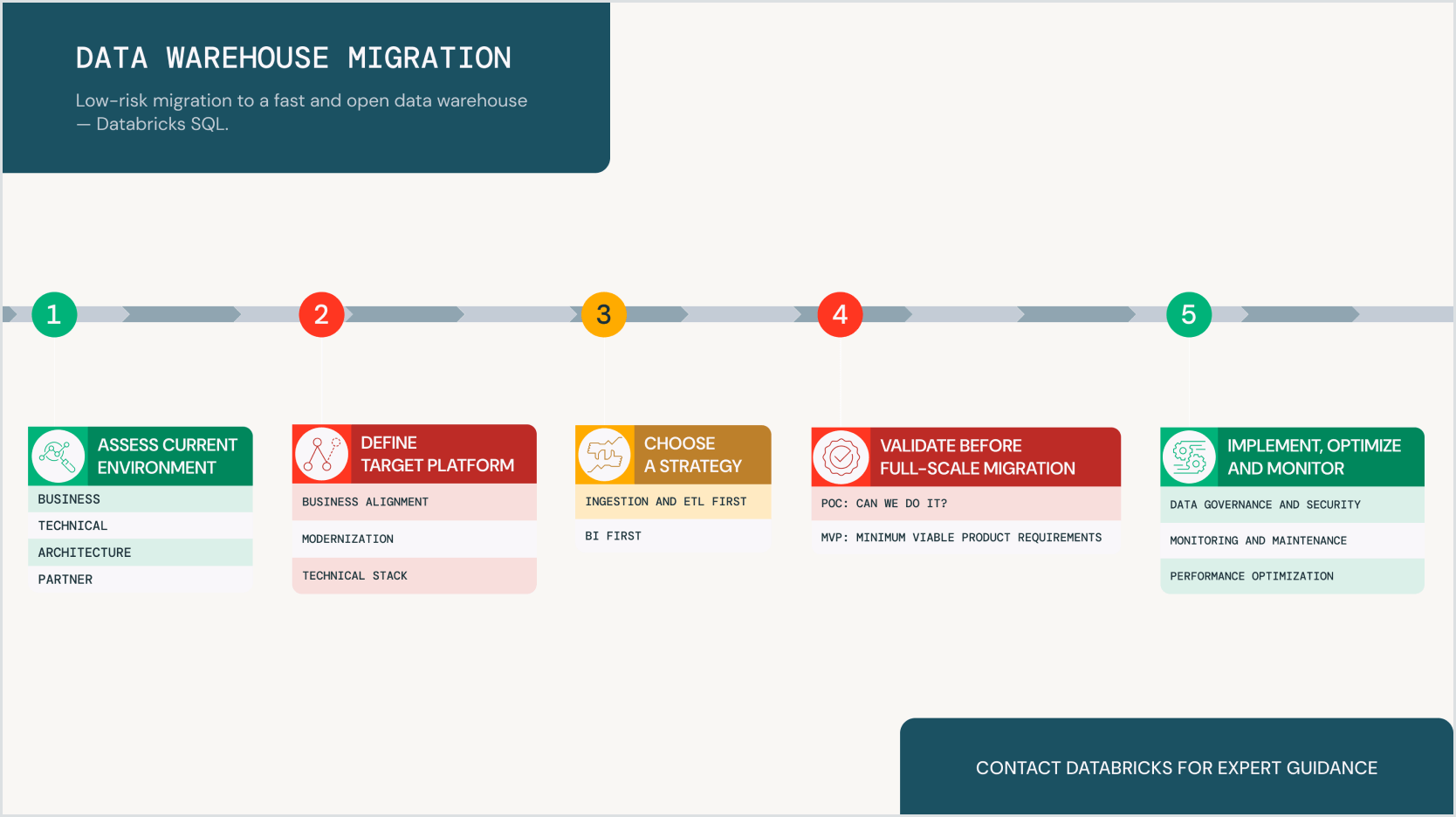
Migrating to a modern platform like the Databricks Lakehouse offers elastic scalability, reduced costs, built-in security and the ability to integrate open source technologies — avoiding vendor lock-in. Follow this proven migration strategy to learn:
- Why modernizing your data warehouse is critical for scalability, cost savings and advanced analytics
- What structured migration strategy Databricks offers for a seamless transition
- How to minimize risks with proofs of concept (POCs), MVPs and Databricks-native tools
Accelerate your migration journey to deliver data and AI-driven outcomes

Reduce TCO and increase operational efficiency
Building ETL pipelines or implementing machine learning on Snowflake requires you to manage and operate additional tools. Over time, your architecture will become more costly and complex. With the Databricks Platform, you get high-performing, cost-effective ETL and native support for AI.






Plan and execute your data and AI journey
Delivering rapid success on projects with world-class data engineering, data science and project management expertise.
As experts on the Databricks Platform, the Databricks Professional Services Migration Team gives you concrete outcomes through a prescriptive approach. The approach maximizes the value of your existing data and pipeline investments, ensuring seamless migration. The Migration Team also supplies best practices to help you reduce risk and cost. Databricks subject matter experts can work as part of your team or your selected SI partners to provide architecture, planning, design, and execution services to ensure success.
Accelerate your data and AI journey
Our offerings and expert services help you in your data and AI journey by providing optimal and tailored acceleration from the initial workspace onboarding to building out DataOps and center of excellence practices at enterprise scale.
Derisk your project with migration assurance
Whether you are migrating from legacy EDW, Hadoop or cloud data warehousing workloads to Databricks, the Databricks Professional Services Migration Team can be your partner and trusted advisor to minimize risk and maximize value at each step of your journey. We can help by providing full migration services or assurance services to you or your SI partners.
Operationalize at scale
Building a data pipeline proof of concept or single-node model development is relatively manageable. The challenge lies in successfully adopting and scaling data and AI practices across the company. Let us help you meet this difficult goal with our prescriptive offerings and expertise.
Customer Stories
Lakebridge
Fast, predictable data warehouse migrations to Databricks
Simplify and accelerate data warehouse migrations to the Databricks Lakehouse from 10+ legacy platforms, including Oracle, Teradata, Snowflake, Amazon Redshift, and Microsoft SQL Server. You can also convert legacy ETL code with confidence.
There’s a reason Lakebridge adoption is growing 20% month over month. Join our 1,000+ customers and partners who trust it for faster, more predictable migrations.