TensorFlow™ on Databricks

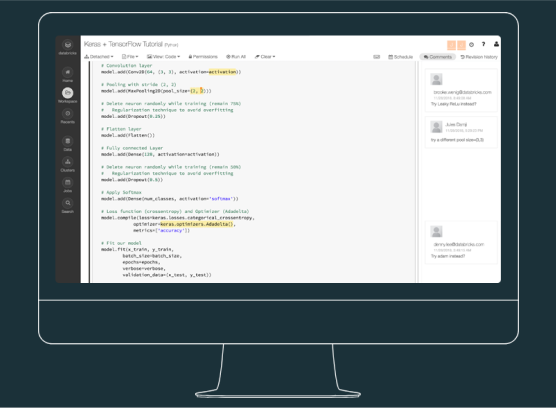
すぐに使用できる TensorFlow
AWS と Azure の CPU および GPU のインスタンスで、クラスタを数秒で起動。柔軟性を最大限に高めます。
Databricks の機械学習ランタイムには、TensorFlow(テンソルフロー)、Keras および、それらが依存する要素が予め統合されており、すぐに使用できます。
また、基礎的なものから高度なものまで多様な API が提供されており、TensorFlow、Keras、Apache Spark の統合による最先端のニューラルネットワークのトレーニングが可能です。
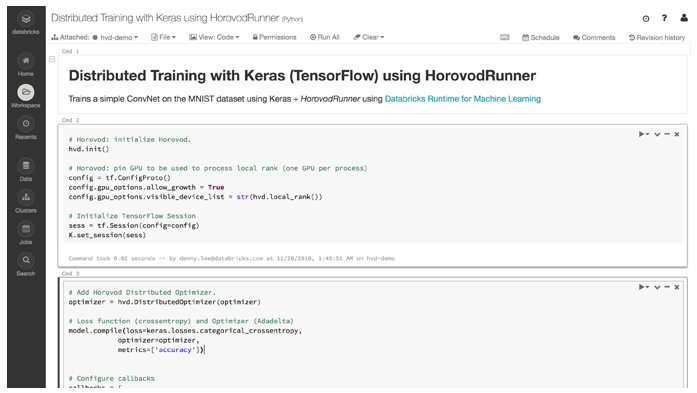
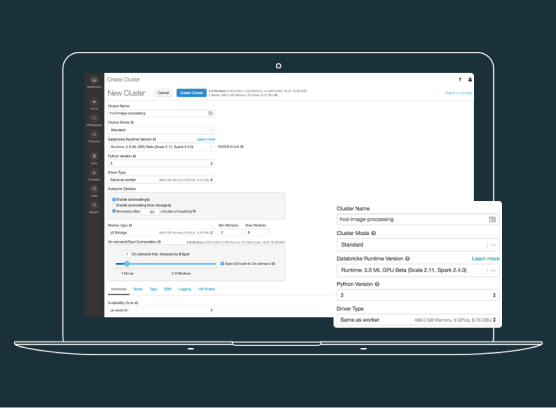
コンピューティングを容易にスケールアウト
Databricks の HorovodRunner は、分散型コンピューティングの容易なスケールアウトを可能にします。
最も要求の厳しいジョブにおいても、ハードウェアサポート(CUDA および cuDNN)の高速化により、パフォーマンスを強化します。
ニーズに基づいてリソースを自動的に拡張し、ストレージをコンピューティングリソースから分離することでコストを管理します。