TensorFlow™ on Databricks

TensorFlow による分散コンピューティング
TensorFlow は分散コンピューティングをサポートしており、グラフの一部を異なるプロセスで(完全に異なるサーバー上にある場合でも)実行できます。さらに、強力な GPU を搭載したサーバーに計算を分散し、他の計算はより多くのメモリを搭載したサーバーで行うといった使い方もできます。インターフェースは少し難しいので、ゼロから構築してみましょう。
以下は、最初のスクリプトです。単一プロセスで実行した後、複数プロセスに移�行します。
もう、このスクリプトを見ても、それほど怖がる必要はありません。定数と 3 つの基本方程式があります。最後に結果(238)が出力されます。
TensorFlow は、サーバー/クライアントモデルのように動作します。これは、力仕事をこなすワーカーを量産するということです。そして、それらのワーカーの 1 つにセッションを作成してグラフを計算、場合によっては、一部をサーバー上の他のクラスタに分散させることもあります。
これを行うためには、メインワーカーであるマスターが他のワーカーについて知る必要があります。これは、ClusterSpec の作成によって行われ、全てのワーカーに渡す必要があります。ClusterSpec は辞書を使用して作成され、キーは「ジョブ名」で、各ジョブには多数のワーカーが含まれます。
以下は、そのイメージ図です。
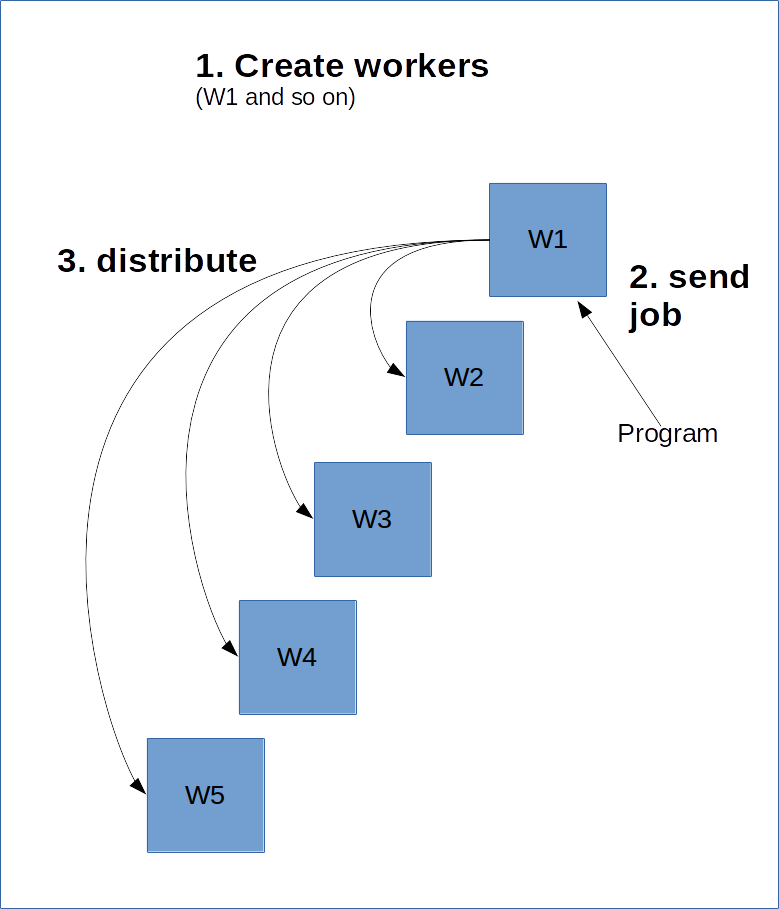
次のコードは、ジョブ名が「local」という 2 つのワーカープロセスを持つ ClusterSpec を作成します。
これらのプロセスはこのコードで開始されるのではなく、開始されるという参照が作成されるだけであることに注意してください。
次に、プロセスを開始します。そのために、これらのワーカーの 1 つをグラフ化して開始します。
上記のコードは、「local」ジョブの下で「localhost:2223」ワーカーを起動します。
以下は、2 つのプロセスを開始するためにコマンドラインから実行できるスクリプトです。コンピュータに create_worker.py としてコードを保存し、Python create_worker.py 0 と、次に Python create_worker.py 1 で実行します。スクリプトはそのままでは終了しない(指示を待機)ため、これを行うには別のターミナルが必要です。
サーバーが 2 つのターミナルで実行されていることがわかるでしょう。分散を行う準備は完了です!
ジョブを「分散」させる最も簡単な方法は、これらのプロセスの 1 つにセッションを作成し、そこでグラフを実行することです。上記の「Session」の行を、次のように変更するだけです。
これは、サーバーにジョブを送信するだけで、実際には分散していません。TensorFlow は、プロセスをクラスタ内の他のリソースに分散させることができますが、分散できないこともあります。デバイスを指定することで強制できます(前回のレッスンで、GPU で行ったことと似ています)。
これで分散を開始します!名前とタスク番号に基づいて、ワーカーにタスクを割り当てることで機能します。フォーマットは、次のとおりです。
/job:JOB_NAME/task:TASK_NUMBER
複数のジョブ(大きな GPU を搭載したコンピュータを特定するため)を使用すると、さまざまな方法でプロセスを分散できます。
Map と Reduce
MapReduce は、大規模な処理を実行するための一般的なパラダイムです。大きく分けて 2 つのステップ(実際には、さらにいくつかのステップがあります)で構成されています。
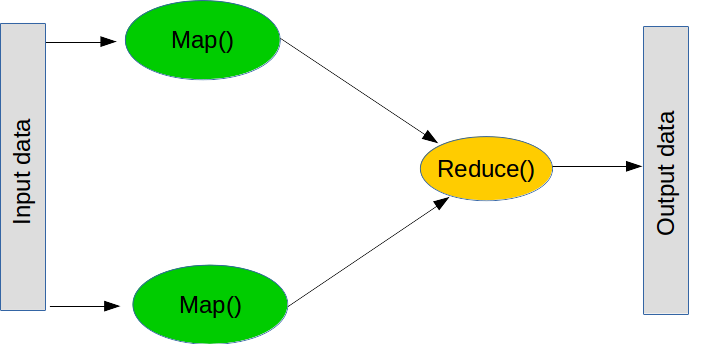
最初のステップは map と呼ばれるもので、「リストを取得し、それぞれに関数を適用する」ことを意味します。通常の Python では、次のように map を作成できます。
次のステップは reduce です。reduce は、「リストを取得し、関数を使用して集約する」ことを意味します。一般的な reduce 処理は sum、つまり「数字のリストを取得して、それらを全て加算して集約する」ことであり、これは 2 つの数字を加算する関数を作成することで実行できます。reduce は、リストの最初の 2 つの値を取得し関数を実行して結果を得たら、その結果と次の値で関数を実行します。sum の場合、最初の 2 つの数字を加算してその結果を取得し、次の数字を加算します。これを、リストの最後に到達するまで繰り返します。reduce もまた、通常の Python の一部です(ただし、分散されません)。
実際には、Pythonのreduce関数を使わなくても、ループ処理などで同様のことが実現できます。
分散 TensorFlow に話を戻すと、map と reduce の処理は、多くの重要なプログラムにおいてカギとなる構成要素です。例えば、アンサンブル学習は、個々の機械学習モデルを複数のワーカーに送信し、分類を組み合わせて最終的な結果を集約します。
こちらも分散の基本的なスクリプトです。
分散バージョンへの変換は、以前の変換を変更するだけです。
map と reduce の観点から考えると、計算を分散させるのははるかに簡単なプロセスだとわかるでしょう。まず、「この問題を単独で解けるように、部分問題に分割するにはどうすればいいか?」を、map で処理します。次に、「答えを集約して最終結果を作成するにはどうすればいいか?」を、reduce で処理します。
機会学習で最も一般的な map の方法は、単純にデータセットを分割することです。線形モデルやニューラルネットワークは、個々にトレーニングしてあとで集約できるため、多くの場合において得意です。
1)ClusterSpec の「local」という単語を別の単語に変更します。スクリプトを動作させるには、他に何を変更する必要がありますか?
2)現在の平均計算スクリプトは、スライスのサイズが等しい前提で動作しています。異なるサイズのスライスで試してエラーを観察してみましょう。修正するには、tf.size とスライスからの平均値を集約する次の式を使用します。
3)デバイス文字列を変更することで、リモートコンピュータ上のデバイスを指定できます。例として、「/job:local/task:0/gpu:0」は、ローカルジョブの GPU をターゲットにします。リモート GPU を使用するジョブを作成します。予備の 2 台目のコンピュータが手元にある場合は、ネットワーク経由�で実行してみましょう。