Databricks stellt offiziellen Leistungsrekord für Data Warehousing auf
von Reynold Xin und Mostafa Mokhtar
Heute geben wir mit Stolz bekannt, dass Databricks SQL einen neuen Weltrekord beim 100-TB-TPC-DS aufgestellt hat, dem Goldstandard-Leistungsbenchmark für Data Warehousing. Databricks SQL hat den bisherigen Rekord um das 2,2-fache übertroffen. Im Gegensatz zu den meisten anderen Benchmark-Nachrichten wurde dieses Ergebnis vom TPC-Rat formal geprüft und überprüft.
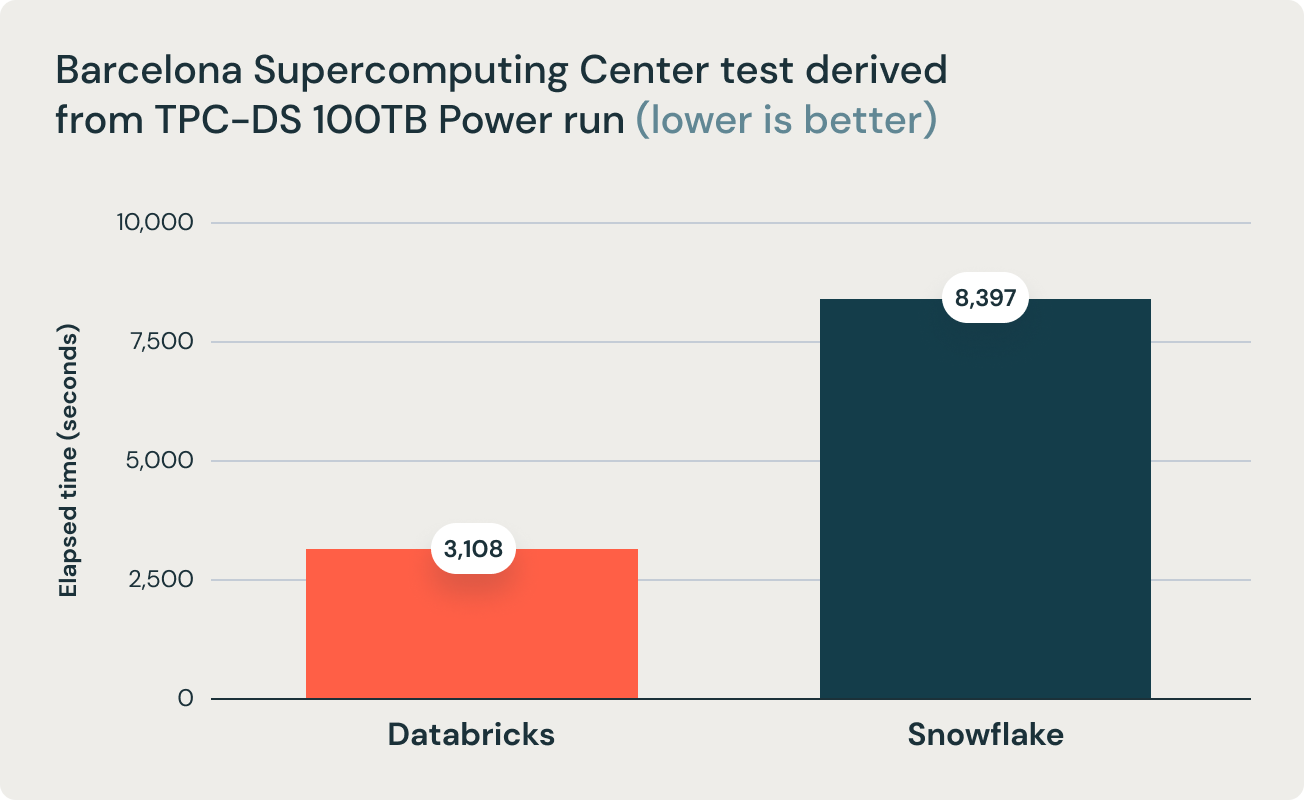
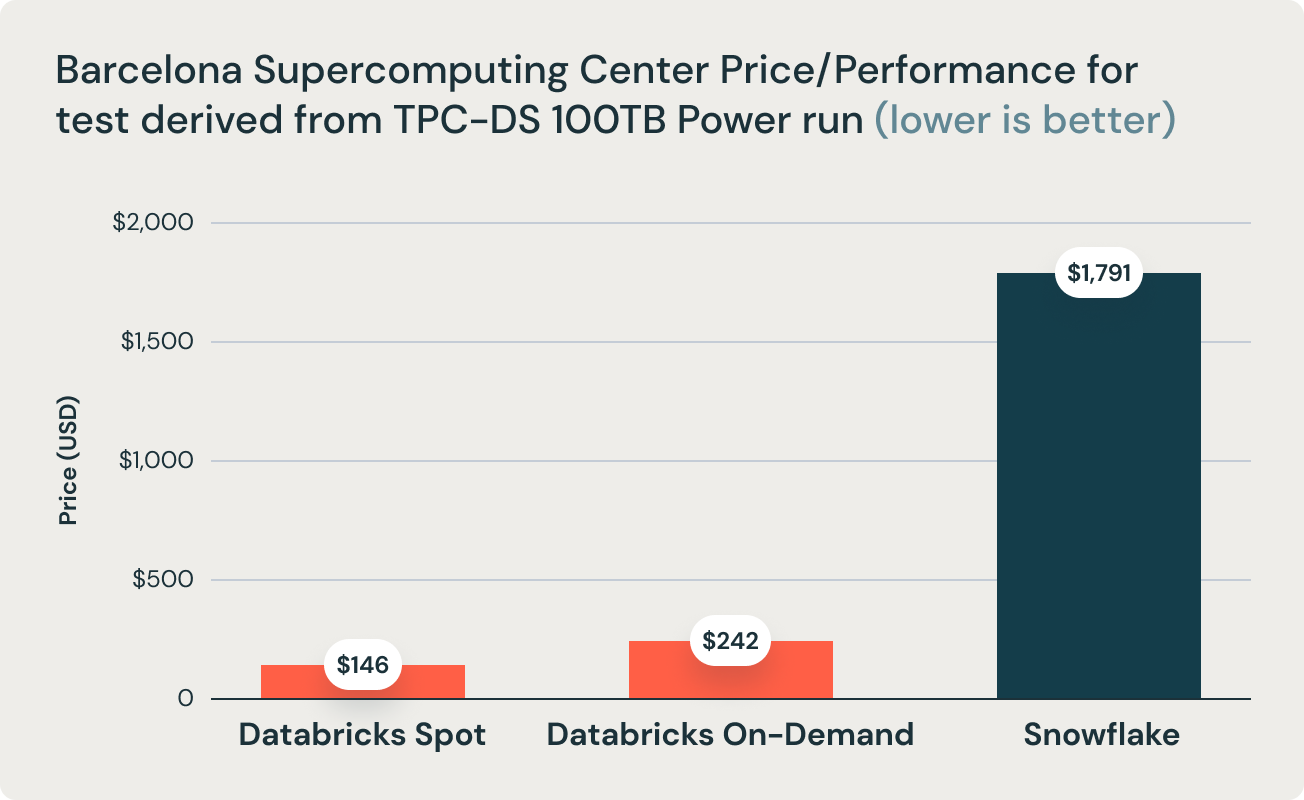
Diese Ergebnisse wurden durch Forschungen des Barcelona Supercomputing Center bestätigt, das häufig Benchmarks auf Basis von TPC-DS auf gängigen Data Warehouses durchführt. Ihre jüngste Studie hat Databricks und Snowflake einem Benchmark unterzogen und festgestellt, dass Databricks 2,7-mal schneller ist und eine 12-mal bessere Preis-Performance bietet. Dieses Ergebnis bestätigte die These, dass Data Warehouses wie Snowflake bei zunehmender Datenmenge im Produktionsbetrieb unerschwinglich teuer werden.
Databricks hat in rasantem Tempo umfassende Data-Warehousing-Funktionen direkt auf Data Lakes entwickelt und vereint so das Beste aus beiden Welten in einer einzigen Datenarchitektur, die als Data Lakehouse bezeichnet wird. Wir haben unser komplettes Angebot an Data-Warehousing-Funktionen im November 2020 als Databricks SQL angekündigt. Die offene Frage war seither, ob eine offene, auf einem lakehouse basierende Architektur die Performance, Geschwindigkeit und Kosten klassischer Data Warehouse bieten kann. Dieses Ergebnis beweist zweifelsfrei, dass dies mit der Lakehouse-Architektur möglich und realisierbar ist.
Wir möchten diese Gelegenheit nicht nur nutzen, um die Ergebnisse zu teilen, sondern auch um Ihnen zu erzählen, wie wir dieses Performance erreicht haben und welcher Aufwand dahintersteckt. Aber wir starten mit den Ergebnissen:
TPC-DS-Weltrekord
Databricks SQL erreichte 32.941.245 QphDS bei 100 TB. Dies übertrifft den bisherigen Weltrekord von Alibabas maßgeschneidertem System, das 14.861.137 QphDS @ 100TB erreichte, um das 2,2-fache. (Alibaba verfügte über ein beeindruckendes System, das die größte E-Commerce-Plattform der Welt unterstützte). Databricks SQL hat nicht nur den bisherigen Rekord deutlich übertroffen, sondern dabei auch die Gesamtkosten des Systems um 10 % gesenkt (basierend auf den veröffentlichten Listenpreise ohne Rabatte).
Es ist vollkommen normal, wenn Sie nicht wissen, was die Einheit QphDS bedeutet. (Wir auch nicht, ohne einen Blick auf die Formel zu werfen.) QphDS ist die primäre Metrik für TPC-DS. Sie stellt die Performance einer Kombination von Arbeitslasten dar, die Folgendes umfasst: (1) das Laden des Datensatzes, (2) die Verarbeitung einer Abfragesequenz (Leistungstest), (3) die Verarbeitung mehrerer gleichzeitiger Abfrageströme (Durchsatztest) und (4) die Ausführung von Datenwartungsfunktionen, die Daten einfügen und löschen.
Diese Schlussfolgerung wird außerdem durch das Forschungsteam des Barcelona Supercomputing Center (BSC) gestützt, das kürzlich einen anderen, von TPC-DS abgeleiteten Benchmark durchführte, in dem Databricks SQL und Snowflake verglichen wurden. Dabei wurde festgestellt, dass Databricks SQL 2,7-mal schneller war als ein ähnlich dimensioniertes Snowflake-Setup.
Was ist TPC-DS?
TPC-DS ist ein Data-Warehousing-Benchmark, der vom Transaction Processing Performance Council (TPC) definiert wurde. Das TPC ist eine gemeinnützige Organisation, die in den späten 80er Jahren von der Datenbank-Community gegründet wurde. Sie konzentriert sich auf die Erstellung von Benchmarks, die reale Szenarien emulieren und somit objektiv zur Performance von Datenbanksystemen verwendet werden können. TPC hatte einen tiefgreifenden Einfluss auf den Bereich der Datenbanken, mit jahrzehntelangen "Benchmarking-Kriegen" zwischen etablierten Anbietern wie Oracle, Microsoft und IBM, die den Bereich vorangebracht haben.
Das "DS" in TPC-DS steht für "Decision Support". Er umfasst 99 Abfragen unterschiedlicher Komplexität, von sehr einfachen Aggregationen bis hin zu komplexem Pattern Mining. Es ist ein relativ neuer Benchmark (die Arbeiten daran begannen Mitte der 2000er-Jahre), der die wachsende Komplexität der Analytics widerspiegelt. In den letzten rund zehn Jahren hat sich TPC-DS zum De-facto-Standard für Data-Warehousing-Benchmarks entwickelt, der von praktisch allen Anbietern übernommen wird.
Aufgrund ihrer Komplexität haben jedoch viele Data-Warehouse-Systeme, selbst die der etabliertesten Anbieter, den offiziellen Benchmark so angepasst, dass ihre eigenen Systeme gut abschneiden. (Zu den üblichen Anpassungen gehören das Entfernen bestimmter SQL-Features wie Rollups oder das Ändern der Datenverteilung, um Schiefe zu beseitigen). Dies ist einer der Gründe, warum es nur sehr wenige Einreichungen für den offiziellen TPC-DS-Benchmark gab, obwohl es im Internet mehr als 4 Millionen Seiten über TPC-DS gibt. Diese Anpassungen erklären scheinbar auch, warum die meisten Anbieter laut ihren eigenen Benchmarks alle anderen Anbieter zu übertreffen scheinen.
Wie haben wir das gemacht?
Wie bereits erwähnt, war es eine offene Frage, ob Databricks SQL in der Lage ist, Data Warehouses in puncto SQL-Performance zu übertreffen. Die meisten Herausforderungen lassen sich auf die folgenden vier Punkte reduzieren:
- Data Warehouses nutzen proprietäre Datenformate und können diese daher schnell weiterentwickeln, während Databricks (basierend auf Lakehouse) auf offene Formate (wie Apache Parquet und Delta Lake) setzt, die sich nicht so schnell ändern. Daher hätten EDWs einen inhärenten Vorteil.
- Eine hervorragende SQL-Performance erfordert die MPP-Architektur (Massively Parallel Processing), und Databricks und Apache Spark waren keine MPP-Systeme.
- Der klassische Zielkonflikt zwischen Durchsatz und Latenz besagt, dass ein System entweder für große Abfragen (durchsatzorientiert) oder für kleine Abfragen (latenzorientiert) hervorragend geeignet sein kann, aber nicht für beides. Da der Fokus von Databricks auf großen Abfragen lag, war die Leistung bei kleinen Abfragen zwangsläufig schlecht.
- Selbst wenn es möglich ist, geht man gemeinhin davon aus, dass es ein Jahrzehnt oder länger dauern würde, ein Data-Warehouse-System zu entwickeln. So schnelle Fortschritte sind unmöglich.
Im weiteren Verlauf des Blogposts werden wir sie einzeln besprechen.
Proprietäre vs. offene Datenformate
Einer der wichtigsten Grundsätze der Lakehouse-Architektur ist das offene Speicherformat. "Offenheit" vermeidet nicht nur die Herstellerbindung, sondern ermöglicht auch die Entwicklung eines herstellerunabhängigen Tool-Ökosystems. Einer der Hauptvorteile offener Formate ist die Standardisierung. Als Ergebnis dieser Standardisierung befindet sich der Großteil der Unternehmensdaten in offenen Data Lakes, und Apache Parquet hat sich zum De-facto-Standard für die Datenspeicherung entwickelt. Indem wir Performance auf Data-Warehouse-Niveau für offene Formate bereitstellen, hoffen wir, Datenbewegungen zu minimieren und die Datenarchitektur für BI- und KI-Workloads zu vereinfachen.
Ein naheliegender Kritikpunkt an "offen" ist, dass offene Formate schwer zu ändern und infolgedessen schwer zu verbessern sind. Obwohl dieses Argument in der Theorie Sinn ergibt, ist es in der Praxis nicht zutreffend.
Erstens ist es durchaus möglich, dass sich offene Formate weiterentwickeln. Parquet, das beliebteste offene Format für die Speicherung großer Datenmengen, hat mehrere Verbesserungsiterationen durchlaufen. Eine der Hauptmotivationen für die Einführung von Delta Lake war es, zusätzliche Funktionen einzuführen, die auf der Parquet-Ebene schwer umzusetzen waren. Delta Lake fügte Parquet zusätzliche Indizierung und Statistiken hinzu.
Zweitens transkodiert das Databricks-System Rohdaten von Delta Lake und Parquet beim Laden von Daten aus Objektspeichern auf lokale NVMe-SSDs automatisch in ein effizienteres Format (ohne Benutzereingriff). Dies ermöglicht weitere Optimierungsmöglichkeiten.
Allerdings bieten Delta Lake und Parquet für die meisten Data-Warehousing-Workloads bereits ausreichende Optimierungen im Vergleich zu den proprietären Formaten, die von Data Warehouses verwendet werden. Bei diesen Workloads ergeben sich Optimierungsmöglichkeiten hauptsächlich aus der Fähigkeit, die Abfragen schneller zu verarbeiten, anstatt mehr Daten schneller zu scannen. Tatsächlich ist die Abfrage von Daten, die in einem optimierteren internen Format zwischengespeichert sind, für TPC-DS nur 10 % schneller als die Abfrage von Cold Data in S3 (wir haben festgestellt, dass dies sowohl für die von uns getesteten Data Warehouses als auch für Databricks zutrifft).
MPP-Architektur
Ein häufiges Missverständnis ist, dass Data Warehouses die MPP-Architektur verwenden, die sich hervorragend für die SQL-Performance eignet, während Databricks dies nicht tut. Die MPP-Architektur ermöglicht es, mehrere Knoten zur Verarbeitung einer einzigen Abfrage zu nutzen. Genau so ist Databricks SQL aufgebaut. Es basiert nicht auf Apache Spark, sondern auf Photon, einer komplett neu geschriebenen Engine, die von Grund auf in C++ für moderne SIMD-Hardware entwickelt wurde und eine stark parallelisierte Abfrageverarbeitung durchführt. Photon ist somit eine MPP-Engine.
Trade-off zwischen Durchsatz und Latenz
Der Kompromiss zwischen Durchsatz und Latenz ist der klassische Trade-off in Computersystemen, was bedeutet, dass ein System nicht gleichzeitig einen hohen Durchsatz und eine niedrige Latenz erzielen kann. Wenn ein Design auf Durchsatz ausgelegt ist (z. B. durch die Batch-Verarbeitung von Daten), geht dies zulasten der Latenz. Im Kontext von Datensystemen bedeutet dies, dass ein System nicht gleichzeitig große und kleine Abfragen effizient verarbeiten kann.
Wir bestreiten nicht, dass dieser Kompromiss existiert. Tatsächlich besprechen wir dies oft in unseren technischen Designdokumenten. Allerdings sind die derzeit modernsten Systeme, einschließlich unseres eigenen und aller gängigen warehouse, sowohl beim Durchsatz als auch bei der Latenz weit von der optimalen Grenze entfernt.
Folglich ist es durchaus möglich, ein neues Design und eine neue Implementierung zu entwickeln, die gleichzeitig den Durchsatz und die Latenz verbessern. Genau so haben wir in den letzten zwei Jahren fast alle unsere wichtigsten Key Basistechnologien entwickelt: Photon, Delta Lake und viele andere Spitzentechnologien haben die Performance sowohl großer als auch kleiner Abfragen verbessert und die Performancegrenze auf einen neuen Rekord verschoben.
Zeit und Fokus
Schließlich besagt die gängige Meinung, dass es mindestens ein Jahrzehnt dauert, bis ein Datenbanksystem ausgereift ist. Angesichts des jüngsten Fokus von Databricks auf Lakehouse (zur Unterstützung von SQL-Workloads) wäre zusätzlicher Aufwand erforderlich, um SQL leistungsfähig zu machen. Das ist ein valider Punkt, aber lassen Sie uns erklären, wie wir es viel schneller geschafft haben, als man vielleicht erwartet.
Zuallererst hat diese Investition nicht erst vor ein oder zwei Jahren gestartet. Seit der Gründung von Databricks haben wir in verschiedene grundlegende Technologien investiert, um SQL-Workloads zu unterstützen, die auch KI-Workloads auf Databricks zugutekommen. Dazu gehören ein vollwertiger kostenbasierter Abfrageoptimierer, eine native vektorisierte Ausführungs-Engine und verschiedene Funktionen wie Fensterfunktionen. Die große Mehrheit der Workloads auf Databricks läuft dank der DataFrame API von Spark, die in dessen SQL-Engine abgebildet wird, über diese Komponenten, sodass diese über Jahre getestet und optimiert wurden. Was wir bisher weniger getan haben, war, den Schwerpunkt auf SQL-Workloads zu legen. Die Neupositionierung in Richtung Lakehouse ist eine kürzliche Entwicklung, angetrieben vom Wunsch unserer Kunden, ihre Datenarchitekturen zu vereinfachen.
Zweitens hat das SaaS-Modell die Zyklen der Softwareentwicklung beschleunigt. Früher hatten die meisten Anbieter jährliche Release-Zyklen und anschließend einen weiteren, mehrjährigen Zyklus für die Kunden zur Installation und Einführung der Software. Bei SaaS kann unser Engineering-Team in nur wenigen Tagen ein neues Design entwerfen, implementieren und für eine Teilmenge von Kunden veröffentlichen. Dieser verkürzte Entwicklungszyklus ermöglichte es den Teams, schnell Feedback zu erhalten und schneller Innovationen zu entwickeln.
Drittens konnte Databricks diesem Problem deutlich mehr Aufmerksamkeit widmen, sowohl in Bezug auf die Führungskapazitäten als auch auf das Kapital. Frühere Versuche, ein neues Data Warehouse-System aufzubauen, wurden entweder von Startups oder von einem neuen Team innerhalb eines großen Unternehmens unternommen. Es gab noch nie ein so gut finanziertes Datenbank-startup wie Databricks (mit über 3,5 Mrd. $ an eingeworbenen Mitteln), um die für den Aufbau erforderlichen Talente zu gewinnen. Eine neue Initiative in einem großen Unternehmen wäre nur noch eine weitere Initiative und würde nicht die volle Aufmerksamkeit der Führung erhalten.
Wir hatten hier eine einzigartige Situation: Wir haben uns anfangs darauf konzentriert, unser Geschäft nicht auf Data Warehousing, sondern auf verwandte Bereiche (Data Science und KI) auszurichten, die viele der gemeinsamen technologischen Probleme teilten. Dieser anfängliche Erfolg ermöglichte es uns dann, den aggressivsten Aufbau eines SQL-Teams in der Geschichte zu finanzieren. Innerhalb kurzer Zeit haben wir ein Team mit umfassendem Data Warehouse-Hintergrund zusammengestellt – eine Leistung, für die viele andere Unternehmen rund ein Jahrzehnt benötigen würden. Unter ihnen sind leitende Ingenieure und Designer einiger der erfolgreichsten Datensysteme, darunter Amazon Redshift, Googles BigQuery, F1 (Googles internes Data-Warehouse-System) und Procella (Youtubes internes Data-Warehouse-System), Oracle, IBM DB2 und Microsoft SQL Server.
Zusammenfassend lässt sich sagen, dass es mehrere Jahre dauert, eine hervorragende SQL-Performance aufzubauen. Wir haben dies nicht nur durch die Nutzung unserer einzigartigen Umstände beschleunigt, sondern auch schon vor Jahren gestartet, obwohl wir den Plan nicht an die große Glocke gehängt haben.
Kunden-Workloads aus der Praxis
Wir sind begeistert, dass diese Benchmark-Ergebnisse von unseren Kunden validiert wurden. Mehr als 5.000 Unternehmen weltweit nutzen die Databricks Lakehouse Platform, um einige der schwierigsten Probleme der Welt zu lösen. Zum Beispiel:
- Bread Finance ist eine Technologie-gestützte Zahlungsplattform mit Big-Data-Anwendungsfällen wie Finanzberichterstattung, Betrugserkennung, Kreditrisiko, Verlustschätzung und einer Full-Funnel-Recommendation-Engine. Auf der Databricks Lakehouse Platform können sie von nächtlichen Batchjobs auf eine Erfassung in nahezu Echtzeit umstellen und die Datenverarbeitungszeit um 90 % reduzieren. Darüber hinaus lässt sich die Datenplattform bei nur den 1,5-fachen Kosten auf das 140-fache Datenvolumen skalieren.
- Shell nutzt unsere Lakehouse-Plattform, um Hunderten von Datenanalysten die Ausführung schneller Abfragen auf Datasets im Petabyte-Bereich mithilfe von Standard-BI-Tools zu ermöglichen, was sie als „bahnbrechend“ bezeichnen.
- Regeneron beschleunigt die Identifizierung von Wirkstoffzielen und verschafft Bioinformatikern schnellere Einblicke, indem die Zeit für Abfragen des gesamten Datasets von 30 Minuten auf 3 Sekunden reduziert wird – eine 600-fache Verbesserung.
Übersicht
Databricks SQL, das auf der Lakehouse-Architektur aufbaut, ist das schnellste Data Warehouse auf dem Markt und bietet das beste Preis-Leistungs-Verhältnis. Jetzt können Sie für all Ihre Daten eine hervorragende Performance bei niedriger Latenz erzielen, sobald neue Daten erfasst werden, ohne sie in ein anderes System exportieren zu müssen.
Dies ist ein Beweis für die Lakehouse-Vision, erstklassige Data-Warehousing-Performance für Data Lakes bereitzustellen. Natürlich haben wir nicht nur ein Data Warehouse entwickelt. Die Lakehouse-Architektur bietet die Möglichkeit, alle Daten-Workloads abzudecken, vom Warehousing bis hin zu Data Science und Machine Learning.
Aber wir sind noch nicht fertig. Wir haben das beste Team auf dem Markt zusammengestellt, und es arbeitet hart daran, den nächsten Performancedurchbruch zu erzielen. Zusätzlich zur Performance arbeiten wir auch an einer Vielzahl von Verbesserungen bei der Benutzerfreundlichkeit und Governance. Erwarten Sie im kommenden Jahr weitere Neuigkeiten von uns.
Das TPC prüft oder validiert keine Ergebnisse von Benchmarks, die vom TPC-DS abgeleitet wurden, und erachtet die Ergebnisse abgeleiteter Benchmarks nicht als mit veröffentlichten TPC-DS-Ergebnissen vergleichbar.
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.