大規模なデータレイクのための Delta タイムトラベルのご紹介

実験再現、ロールバック、データ監査のためのデータバージョニング
Apache Spark の上に構築された次世代統合分析エンジンである Databricks Delta Lake にタイムトラベル機能を導入し、全てのユーザーの皆様にお届けできることを嬉しく思います。この新機能により、Delta はデータレイクに保存されているビッグデータを自動的にバージョンアップし、そのデータの任意の履歴バージョンにアクセスすることができます。この一時的なデータ管理により、監査、誤った書き込みや削除があった場合のデータのロールバック、実験やレポートの再現が容易になり、データパイプラインを簡素化することができます。お客様の組織では、分析に必要なクリーンで一元化されたバージョン管理されたビッグデータリポジトリを、お客様自身のクラウドストレージで標準化することが可能になります。

データ変更に伴う共通の課題
- データ変更の監査:データの変更を監査することは、データコンプライアンスの観点からも、データが時間とともにどのように変化したかを理解するための単純なデバッグの観点からも、非常に重要です。従来のデータシステムからビッグデ�ータ技術やクラウドに移行する組織は、このようなシナリオで苦労しています。
- 実験・レポートの再現:モデルのトレーニングでは、データサイエンティストは与えられたデータセットに対して異なるパラメータでさまざまな実験を実行します。一定期間後、データサイエンティストがモデルを再現するために実験を再開すると、通常、ソースデータは上流のパイプラインによって変更されています。多くの場合、このような上流データの変更に気づかず、実験を再現するのに苦労しています。データサイエンティストや組織の中には、データのコピーを複数作成することでベストプラクティスを実現し、ストレージコストの増加につなげる人もいます。レポートを作成するアナリストも同様です。
- ロールバック:データパイプラインは時として、下流の消費者に低品質のデータを書き込むことがあります。これは、インフラの不安定さ、データの乱れ、パイプラインのバグなど、さまざまな問題が原因となって起こります。ディレクトリやテーブルへの単純な追加を行うパイプラインの場合、ロールバックは日付ベースのパーティショニングで簡単に対処できます。しかし、更新や削除の場合は非常に複雑になり、データエンジニアは通常、このようなシナリオに対処するために複雑なパイプラインを設計しなければなりません。
タイムトラベルの紹介
Delta のタイムトラベル機能により、上記のようなユースケースにおけるデータパイプラインの構築が簡素化されます。Delta のテーブルやディレクトリに書き込むと、全ての操作は自動的にバージョン管理されます。異なるバージョンのデータには、2 つの異なる方法でアクセスすることができます。
1.タイムスタンプの利用
Scala:
DataFrame reader のオプションとして、タイムスタンプまたは日付文字列を指定することができます。
Python:
SQL:
リーダーコードがアクセスできないライブラリにあり、ライブラリに入力パラメータを渡してデータを読み込む場合でも、yyyyMMddHHmmssSSS 形式のタイムスタンプをパスに渡せば、テーブルを過去に遡ることができます。
2. バージョン番号の使用
Delta では、全ての書き込みにバージョン番号があり、バージョン番号を使って過去にさかのぼることもできます。
Scala:
Python:
ガートナー®: Databricks、クラウドデータベースのリーダー

SQL:
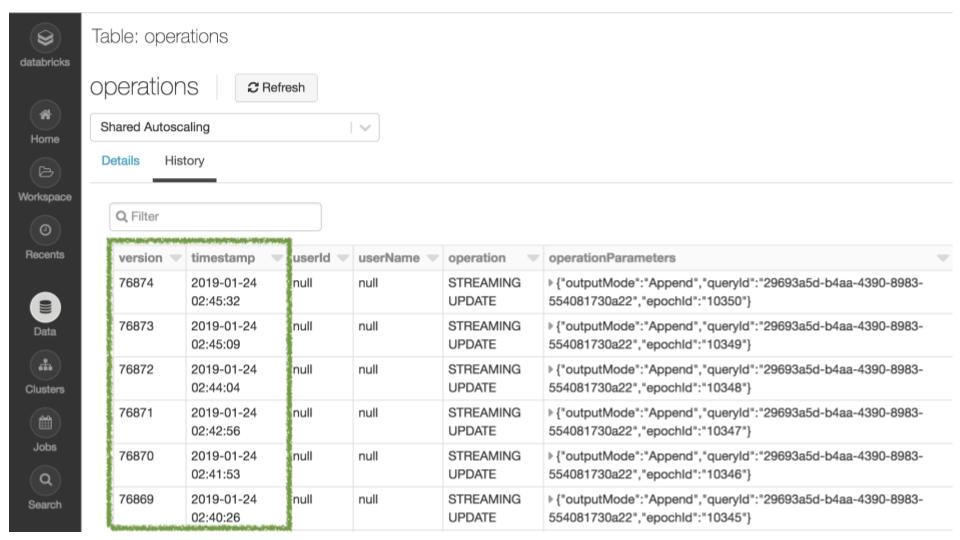
データ変更の監査
DESCRIBE HISTORY コマンドや UI を使って、テーブルの変更履歴を見ることができます。
実験とレポートの再現
タイムトラベルは、機械学習やデータサイエンスにおいても重要な役割を果たします。データサイエンティストにとって、モデルや実験の再現性は重要な検討事項です。データサイエンティストはしばしば、1 つのモデルを本番稼動させる前に 100 ものモデルを作成し、その時間のかかるプロセスの中で以前のモデルに戻りたいと思うからです。しかし、データ管理はデータサイエンス・ツールから切り離されていることが多いため、これを実現するのは実に困難です。
Databricksは、Delta のタイムトラベル機能を、機械学習ライフサイクルのためのオープンソースプラットフォームである MLflow と統合することで、この再現性の問題を解決しています。再現性のある機械学習トレーニングのために、タイムスタンプ付きの URL を MLflow のパラメータとしてパスに記録するだけで、各トレーニングジョブにどのバージョンのデータが使用されたかを追跡することができます。これにより、以前の設定やデータセットにさかのぼって以前のモデル��を再現することができます。データに関して上流のチームと調整したり、異なる実験用にデータをクローンする心配はありません。これこそ、データサイエンスとデータエンジニアリングが密接に連携した統合分析の威力なのです。
ロールバック
タイムトラベルを利用すると、不正な書き込みがあった場合にロールバックを簡単に行うことができます。例えば、GDPR パイプラインのジョブにバグがあり、誤ってユーザー情報を削除してしまった場合、簡単にパイプラインを修正することができます。
また、不正なアップデートを修正する方法は以下のとおりです。
複数のダウンストリームジョブで継続的に更新される Delta テーブルのピン留め表示
AS OF クエリを使用すると、複数の下流ジョブで継続的に更新される Delta テーブルのスナップショットを固定することができるようになりました。Delta テーブルが継続的に更新され、例えば 15 秒ごとに更新される場合、この Delta テーブルから定期的に読み取り、異なる宛先を更新する下流ジョブがあることを考えます。このようなシナリオでは、通常、ソースの Delta テーブルを一貫して表示し、全てのデスティネーションテーブルに同じ状態を反映させたいと考えます。このようなシナリオを、次のように簡単に処理できるようになりました。
時系列分析のためのクエリもシンプルに
タイムトラベルは、時系列分析も簡単にします。例えば、先週何人の新規顧客を獲得したかを知りたい場合、次のような非�常にシンプルなクエリを作成することができます。
https://www.youtube.com/watch?v=rWydTW-RXUk
まとめ
Delta でのタイムトラベルは、開発者の生産性を飛躍的に向上させます。それは、次のようなことに役立ちます。
- データサイエンティストによる実験管理の向上
- データエンジニアがパイプラインを簡素化し、不良書き込みをロールバックする
- データアナリストのレポート作成を容易にする
組織はついに、分析用のクリーンで集中管理された、バージョン管理されたビッグデータリポジトリを、自社のクラウドストレージで標準化できるようになりました。この新機能で何ができるようになるのか、私たちは期待しています。
この機能は、全てのユーザーに対してパブリックプレビューとして提供されています。この機能の詳細については、こちらをご覧ください。Databricks の無料トライアルに申し込むと、実際にこの機能を体験することができます。
Delta Lake のオンラインハブでは、詳細を学び、最新のコードをダウンロードし、Delta Lake コミュニティに参加することができます。